Apache Doris 在搜狐智能媒体的应用
2020.03.09 19:17浏览量:5456简介:分享者: 搜狐智能媒体研发中心资深研发 翟东波 / Apache Doris Contributor 前言 搜狐智能媒体研发中心支撑了整个搜狐主站文章的底层
分享者: 搜狐智能媒体研发中心资深研发 翟东波 / Apache Doris Contributor
前言
搜狐智能媒体研发中心支撑了整个搜狐主站文章的底层数据管理,包括庞大繁杂的数据整理、分析、挖掘、展示以及推送策略。如何能够找到一个工具,可以同时满足交互式查询和实时数据统计的需求,是摆在搜狐面前的难题。
本文详细介绍了搜狐智能媒体研发中心是如何在众多技术选型中最终选定了Doris,以及搜狐的各位Contributor对Doris重要的代码贡献。
1.背景介绍

搜狐智能媒体研发中心的主要任务是对搜狐主站的文章进行管理、展示、推荐等。他们的数据业务主要分为两部分,一是传统的BI业务,包括数据报表、多维分析、数据挖掘等等,还有一部分主要是和文章相关,包括文章搜索、DMP、打标签等。

根据业务场景,数据处理计算范型主要分为两大部分,Batch层和实时处理层,实际上就是目前典型的Lambda架构。
Batch又分为批量数据处理和交互式查询功。批量数据处理,主要是ETL、数据挖掘,目前公司有大数据部门专门维护Hadoop,提供Hive和Spark,可以很好满足批量数据处理的需求了。交互式查询功能,满足报表和多维分析,目前公司主要提供Impala、MySQL、Mongo,查询稳定性和响应延迟等,不能满足要求,影响用户体验。
实时层分为流式处理和实时数据统计。流式处理,主要是实时ETL,复杂事件处理,目前公司提供的Spark Streaming完全可以满足需求。实时数据统计,主要是把实时处理和批处理的计算统一起来,可以理解为Kappa架构,目前主要应用MySQL、Mongo,数据量大的时候处理不了。
因此,搜狐团队希望找到一个开源工具可以满足交互式查询和实时数据统计。

搜狐在选择产品的时候也做了大量的开源竞品分析。对以下五个产品的优缺点都有详细的说明。
- Impala+HDFS/KUDU
优点:可以实时导入、查询功能非常完善
缺点:部署依赖多,其实相当于要把整个Hadoop全部搭一遍,KUDU只支持Unique Key,在一些场景下速率不能满足要求
- Presto/Hawq/……
优点:SQL查询功能完善
缺点:依赖HDFS作为存储层
- Druid
优点:查询很快,底层是Bitmap索引、支持Rollup
缺点:Scatter/Gather计算模型比较弱,对于join很难解决
- Kylin
优点:Cube=>Cuboid转成KV存储,速度快
缺点:数据膨胀太厉害
- ElasticSearch
优点:Bitmap索引、schema-free
缺点:查询功能不完善,对join支持弱

最终,之所以选择了Doris,是因为这些显著的亮点。
- 首先是元信息管理和存储,部署简单,自依赖。
- 对于存储层,数据分区比较完善,支持Range分区和Hash分区,有强大的rollup功能,支持Stream load和Batch load,可以针对实时和离线数据场景,可对接Mysql、HDFS。
- 对于查询层,支持MySQL协议,可以说是使用零成本,方便迁移,查询功能也很完善。
- 还有很重要的一点是百度人肉在线支持,半夜12点还能在线回答问题。
但是相对而言也有一些小小的不足,比如OLAP查询性能和文档不够丰富等。
2.实用案例
搜狐团队分享了两个使用案例,通过新旧方案的对比给大家带来直观上的感受。
2.1实时数据分析案例

首先搜狐罗列了他们的业务需求:统计每5分钟粒度的PV UV汇总数据;统计每个5分钟时间点的当日累计PV UV;查询当日及历史30天内数据,作为对比;查询需要秒级响应;数据延迟要求控制在5分钟内;原始数据约2000万/5分钟;业务需求特点-统计分析维度固定:a/b/c/d ; a/b/c。
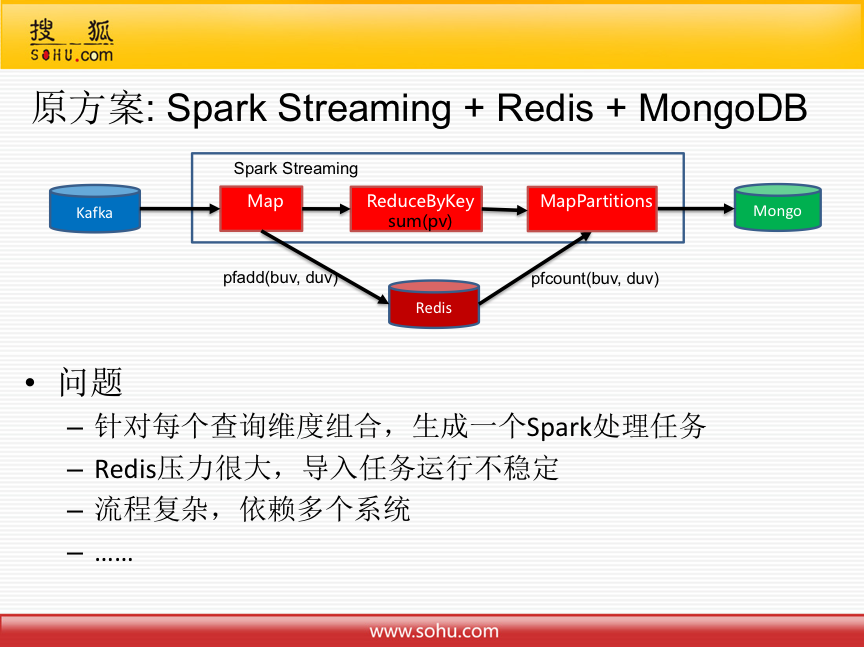
因为统计分析维度固定,所以原始方案就是通过Spark Streaming + Redis + MongoDB 去实现的。但是原方案存在诸多问题,比如针对每个查询维度组合,生成一个Spark处理任务,对用户后续的需求不能很好满足;Redis压力很大,导入任务运行不稳定,经常延迟;流程复杂,依赖多个系统,调了很长时间都不能稳定下来;时间维度只能使用Processing Time,无法使用实践真实发生的时间Event Time,数据计算无法保证准确性等等。
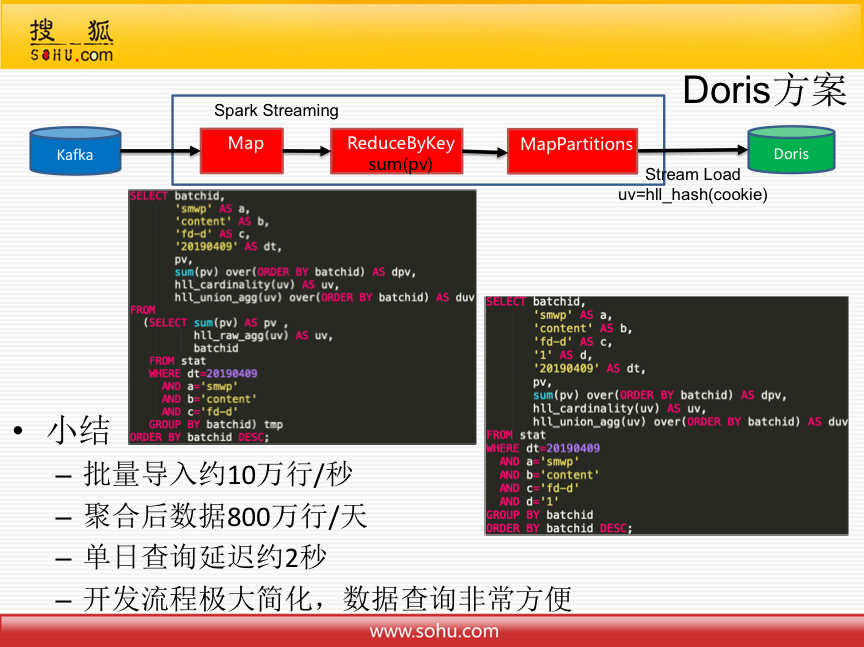
因此,后续就将其迁移到Doris。这样查询的时候就很简单,只需要导入一份数据,就可以支持多种维度组合查询。
目前,根据业务情况,批量导入约10万行/秒,总共两千万行数据可以快速导入,线上使用以来未遇到延迟问题;聚合后数据800万行/天,单日查询延迟约2秒。
总之,开发流程极大简化,数据查询非常方便!
2.2历史数据分析

目前业务痛点是客户每新增需求,就要相应的新增表,没有统一的表元信息管理。系统负担重,现在Hive上已有数千张表,数据延迟比较严重,每天还新增数十T的数据。数据开发人员负担重,由于有新增的表,需要花费大量时间补历史数据,并且由于数据查询口径多,细节上稍有出入就会导致数据不一致,业务方体验非常不好。
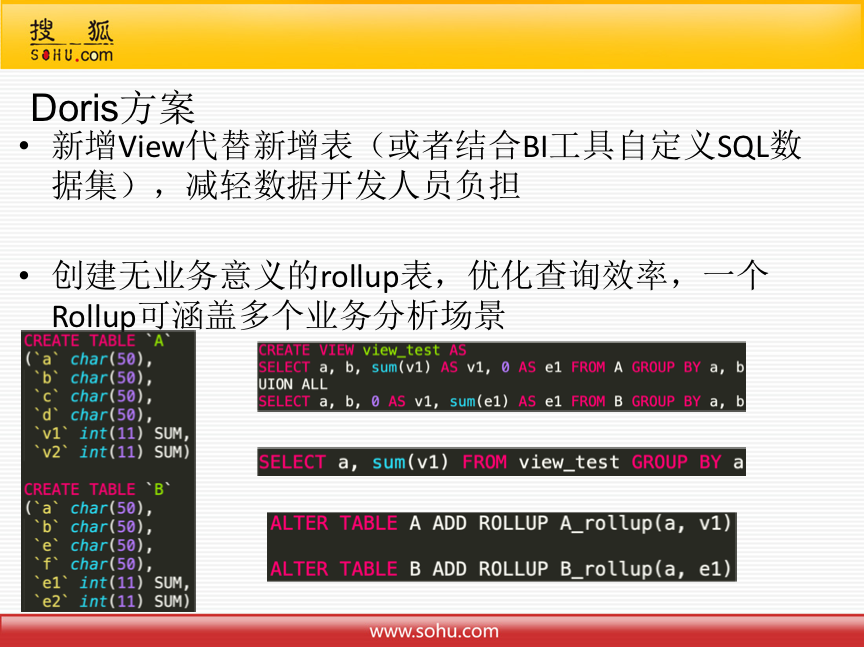
目前针对这个问题,只是规划了Doris方案,还未具体实施。
方案主要是将新增表改为新增View,或者结合BI工具自定义SQL数据集,所有新增需求从表里提出来做视图,数据开发人员只需要写简单SQL,减轻了负担。这样有可能会导致查询比较慢,但是由搜狐的Doris运维人员根据每天的查询统计,创建无业务意义的rollup表,优化查询效率,一个Rollup可涵盖多个业务分析场景。
3.代码贡献

第一是Docker环境搭建。
这样可以很方便的在Mac和Windows上开发调试Doris,可以在Docker容器中进行编译。比如可以在Docker容器里起一个BE进程,在IDE里起一个FE进程,就可以生成一个单实例的FE-BE。最多一天,就可以搭建起环境。

第二是根据实时数据统计需求开发了HyperLogLog Aggregation计算函数。
不仅支持窗口函数,还支持聚合函数返回HLL。其中第二个功能点是很有必要的,以前Doris不会产生中间的HLL,写带嵌套子查询的复杂SQL时会带来很大困难。现在把String类型变成HLL类型,HLL类型字段是带有聚合计算语义的,对后续建表和数据建模来说都可以提升效率。

第三是搜狐希望可以把Parquet数据直接导入Doris。
目前Doris只支持csv格式,每天有大量数据需要做格式化处理,很耗费资源性能。搜狐希望日后Parquet作为大数据计算中统一的数据格式。目前设计的流程用hive或spark做离线的数据处理,把表在hive上生成出来,再refresh到Impala里面,Impala用来支持高吞吐量的交互式查询,Hive中产生的数据直接load到Doris中,Doris就作为一个高并发交互式查询的引擎,做为业务系统统一的查询接口。
总之,搜狐希望针对不同的业务场景提供合适的工具,提升整体数据的研发效率。

发表评论
登录后可评论,请前往 登录 或 注册