百度智能云向量数据库 VectorDB 性能测试报告
2024.04.09 16:20浏览量:9495简介:本章节说明性能测试所需的环境与数据集。
百度智能云向量数据库 VectorDB是一款纯自研高性能、高性价比、生态丰富且即开即用的向量数据库服务,提供高效的向量索引和相似度查询服务。为了让用户更好地了解 VectorDB 的性能表现,VectorDB 性能白皮书详细描述了性能测试环境、测试方法和测试结果。本章节说明性能测试所需的环境与数据集。
欢迎大家了解向量数据库 VectorDB
数据库规格
测试实例规格如下表格所示: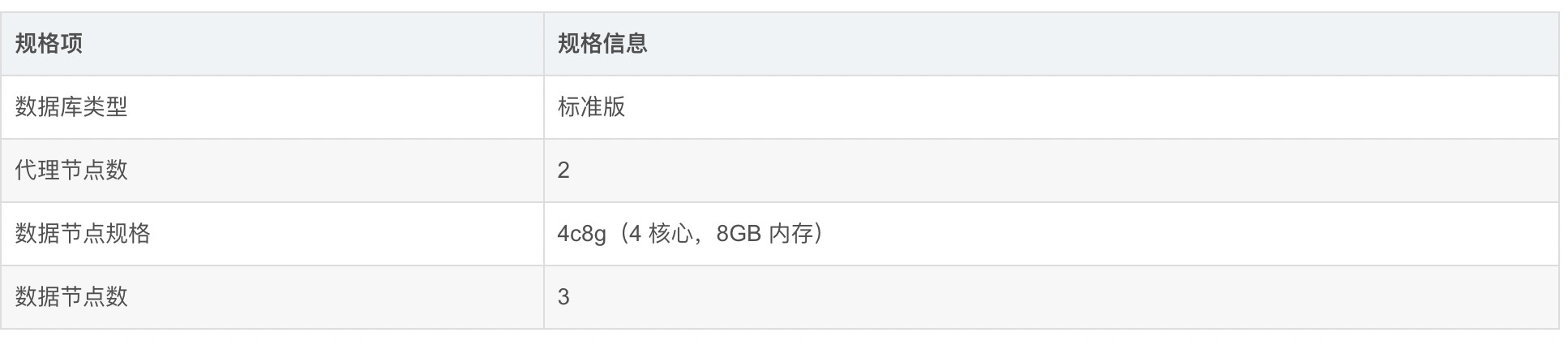
该规格所支持的最大向量规模,请参见产品规格,并按照以上规格新建向量数据库实例,具体操作的流程,请参见文档快速指南-创建实例。
客户端测试环境
与百度智能云向量数据库实例为同一地域同一 VPC 内的云服务器,其环境要求如下:
操作系统:CentOS / 8.4 x86_64 (64bit)
规格:8c16g(8核心,16GB内存)
说明: 在使用 BCC 连接 VectorDB 实例时,需要在 BCC 关联的安全组中配置出站规则,把百度智能云 VectorDB 实例的 IP 及端口添加到出站规则中,避免因为安全组的问题导致连接失败。
测试工具
我们基于 Go 语言自研了性能测试工具 ann-benchamrk,用于评估近似最近邻(ANN)检索库的性能测试工具,能够避免客户自行解决客户端依赖,快速进行性能测试和对比。它提供了一套标准的测试数据集和评估指标,可以用于比较不同量级数据集下向量数据库的性能表现。
本测试基于该 ann-benchmark 进行,以下是测试工具的运行方法:
./bin/ann-benchmark -conf ./conf/conf.toml

数据集
测试过程使用的官方数据集都需要提前下载,测试工具在运行时会检查./dataset 目录(ann-benchmark 工具的根目录)下是否存在数据集文件,为了确保在使用测试工具时无需另外单独安装环境依赖,百度云向量数据库团队转换提供了 parquet 文件格式的 ann 数据集,并制作了Cohere 768 维度数据集。具体数据集信息,如下表所示:

测试方法
百度智能云 VectorDB 采用自研的性能测试工具 ann-benchmark 进行测试比对,该工具不依赖外部组件,并提供了官方的标准数据集和自制的数据集。本文详细介绍下基于 ann-benchmark 工具进行数据库性能测试的方法。
准备测试环境
- 下载测试工具。下载链接:linux-ann-benchmark-1.0.1.tar.gz
- 下载百度智能云 VectorDB 提供的数据集文件,下载链接见测试环境小节。
- 登录百度智能云 BCC 测试客户端环境(BCC 的规格要求,请参见测试环境)。
- 执行 tar -zxvf linux-ann-benchmark-1.0.1.tar.gz 命令解压测试工具压缩包。
- 下载数据集,并放在测试工具目录 dataset 文件夹下。
修改配置文件
进入测试工具目录,打开配置文件,配置相关参数 执行如下命令,拷贝配置文件,根据需要修改参数:
vim conf/conf.toml
样例配置文件的内容如下所示:
logDir = "./log"
# Config for ann benchmark dataset
[Dataset]
path = "./dataset"
name = "SIFT_1M"
# Config for vector store
[VectorStore]
name = "Mochow"
endpoint = "http://127.0.0.1:5378"
user = "root"
password = "test_password"
database = "benchmark_db"
table = "benchmark_table"
dropExistingTable = true
# Common Config for Test Case
[TestCase]
vectorIndex = "HNSW"
topK = 10
concurrency = [24, 36, 48]
duration = 120
recallRangeForQPSBench = [0.8, 0.995]
# Config for hnsw index build
[TestCase.HNSW.Index]
M = [16, 32]
efConstruction = 200
# Config for hnsw search
[TestCase.HNSW.Search]
ef = [20, 40, 60, 80, 100, 120, 140, 160, 180, 200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000]
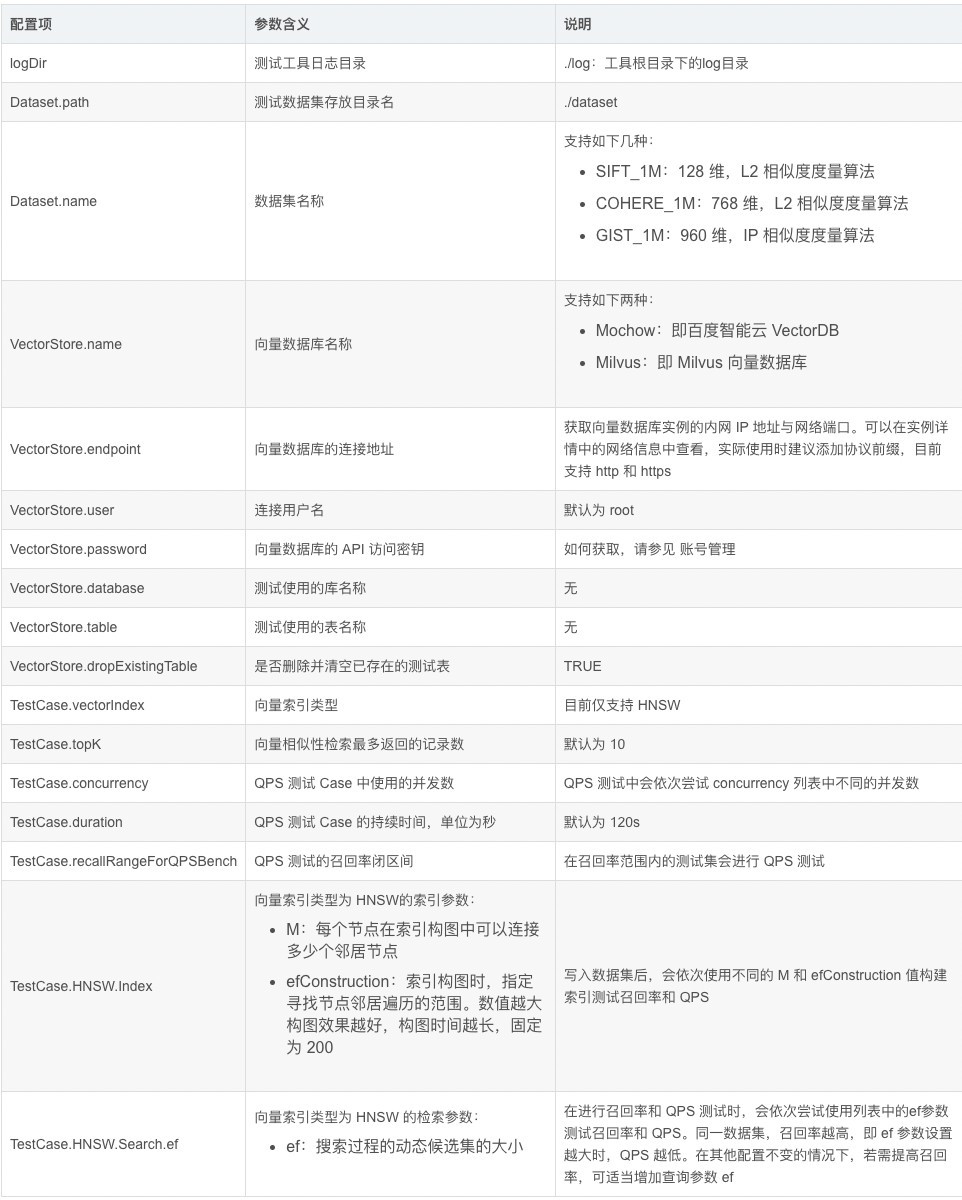
配置项参数含义如下:
运行测试工具
执行如下命令,运行测试工具。其中,-conf 指明配置文件路径,配置文件中配置项的含义,请参见上一小节。
cd linux-ann-benchmark-1.0.1
./bin/ann-benchmark -conf ./conf/conf.toml
查看测试结果
测试结果
测试结束后,结果会写入到工具根目录的 result/benchmarkresult{测试开始时间}格式文件中,内容样例如下:
Mochow {M:16, efc:200} {ef:100} 82.76% 2431.7927
其中每一行为一组测试参数下的测试结果,以空格分割开,每一部分的含义如下:
Mochow:本次测试采用的向量数据库类型;
{M:16, efc:200}:向量索引的构建参数;
{ef:100}:向量检索参数;
82.76%:召回率;
2431.7927:最大 QPS;
实例状态
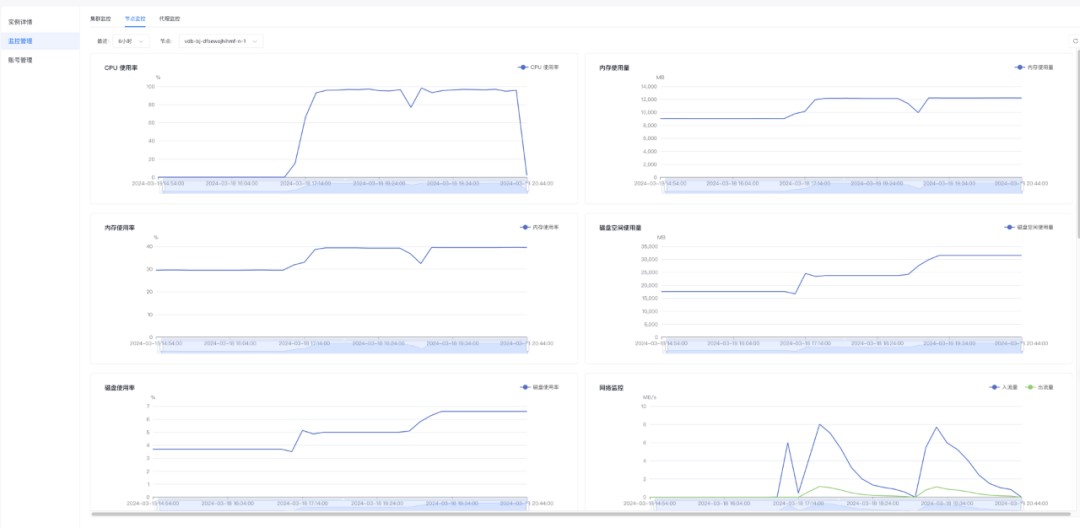
百度智能云 VectorDB 控制台提供了实例的 CPU、内存、QPS、时延等关键性能指标监控,可以在测试过程中观察上述指标的状态,具体观察方法,请参见 查看监控数据。
测试方法
百度智能云 VectorDB 采用自研的性能测试工具 ann-benchmark 进行测试比对,该工具不依赖外部组件,并提供了官方的标准数据集和自制的数据集。本文详细介绍下基于 ann-benchmark 工具进行数据库性能测试的方法。
准备测试环境
下载测试工具。下载链接:linux-ann-benchmark-1.0.1.tar.gz
下载百度智能云 VectorDB 提供的数据集文件,下载链接见测试环境小节。
登录百度智能云 BCC 测试客户端环境( BCC 的规格要求,请参见测试环境)。
执行 tar -zxvf linux-ann-benchmark-1.0.1.tar.gz 命令解压测试工具压缩包。
下载数据集,并放在测试工具目录 dataset 文件夹下。
修改配置文件
进入测试工具目录,打开配置文件,配置相关参数 执行如下命令,拷贝配置文件,根据需要修改参数:
vim conf/conf.toml
样例配置文件的内容如下所示:
logDir = "./log"
# Config for ann benchmark dataset
[Dataset]
path = "./dataset"
name = "SIFT_1M"
# Config for vector store
[VectorStore]
name = "Mochow"
endpoint = "http://127.0.0.1:5378"
user = "root"
password = "test_password"
database = "benchmark_db"
table = "benchmark_table"
dropExistingTable = true
# Common Config for Test Case
[TestCase]
vectorIndex = "HNSW"
topK = 10
concurrency = [24, 36, 48]
duration = 120
recallRangeForQPSBench = [0.8, 0.995]
# Config for hnsw index build
[TestCase.HNSW.Index]
M = [16, 32]
efConstruction = 200
# Config for hnsw search
[TestCase.HNSW.Search]
ef = [20, 40, 60, 80, 100, 120, 140, 160, 180, 200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000]
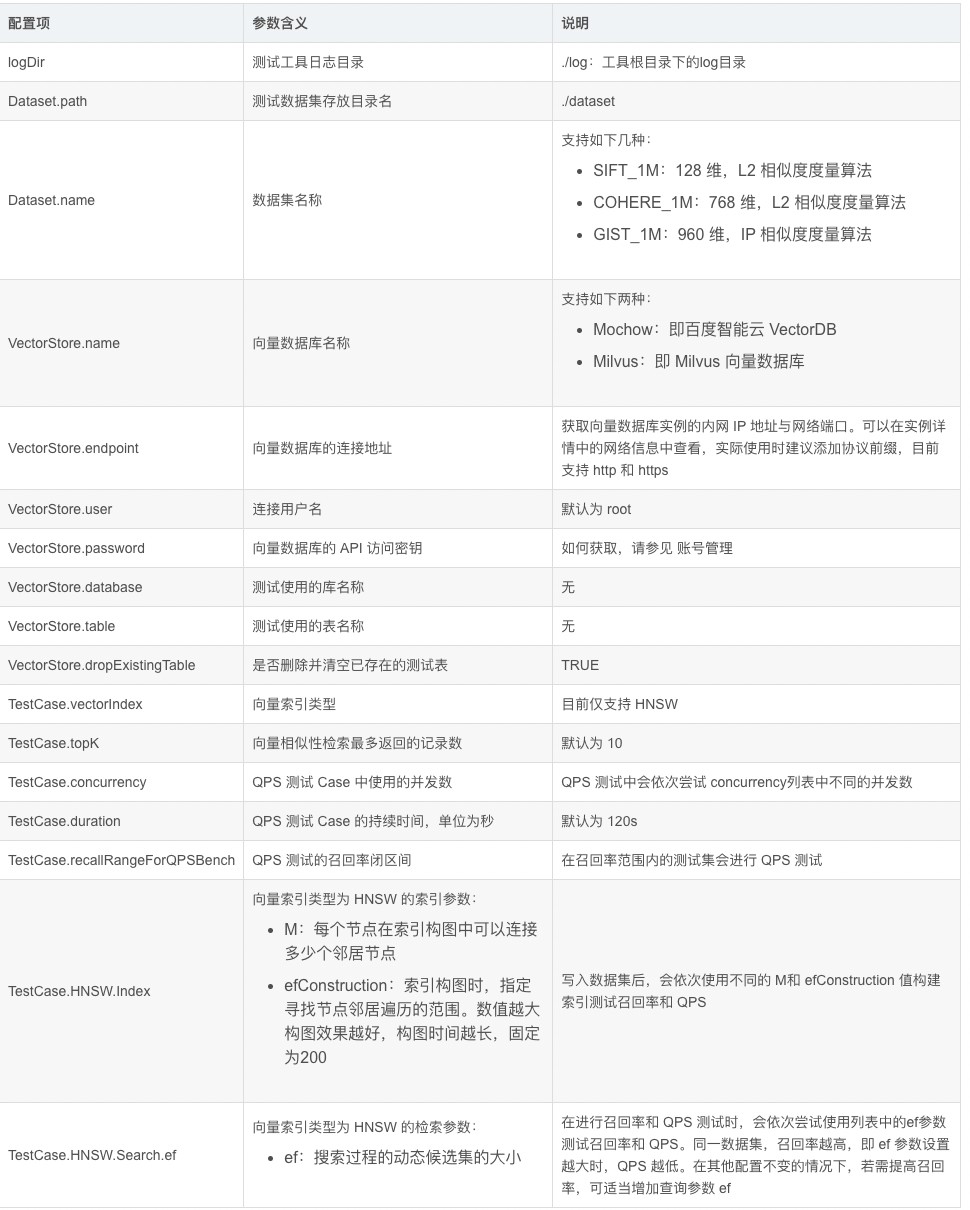
配置项参数含义如下:
运行测试工具
执行如下命令,运行测试工具。其中,-conf 指明配置文件路径,配置文件中配置项的含义,请参见上一小节。
cd linux-ann-benchmark-1.0.1
./bin/ann-benchmark -conf ./conf/conf.toml
查看测试结果
测试结果
测试结束后,结果会写入到工具根目录的 result/benchmarkresult{测试开始时间} 格式文件中,内容样例如下:
Mochow {M:16, efc:200} {ef:100} 82.76% 2431.7927
其中每一行为一组测试参数下的测试结果,以空格分割开,每一部分的含义如下:
Mochow:本次测试采用的向量数据库类型;
{M:16, efc:200}:向量索引的构建参数;
{ef:100}:向量检索参数;
82.76%:召回率;
2431.7927:最大 QPS;
实例状态
百度智能云 VectorDB 控制台提供了实例的 CPU、内存、QPS、时延等关键性能指标监控,可以在测试过程中观察上述指标的状态,具体观察方法,请参见 查看监控数据。
测试结果说明
本文提供了百度智能云 VectorDB 和某开源系统的对比测试结果报告。性能报告主要主要关注以下两个指标:
检索 QPS 或吞吐:系统在单位时间内能够处理的检索请求数量,是衡量检索性能的关键指标。
召回率:检索的 TopK 结果中,满足真实情况(KNN 检索)的 TopK 集合的比例,是衡量向量检索精度的关键指标。
本文的所有测试都是在相同规格的实例下进行的,测试配置如下:
测试方法:向量索引选择 HNSW,检索最相似 Top10 的向量,对比百度智能云向量数据库与某开源向量数据库的 QPS 表现。
测试规格:数据节点规格均为 4 核+ 8GB 内存的配置,数据节点数量均为 3 个。
数据集:测试 SIFT128、COHERE768、GIST960 三种维度的数据集,数据集大小均为 100 万。
数据表配置:数据表均为 1 个分区/分片,分片副本数(含主副本)均为 3。
测试结果
SIFT(128 维)
128 维数据集下,百度智能云 VectorDB 与某开源向量数据库的 QPS 对比结果如下图所示:
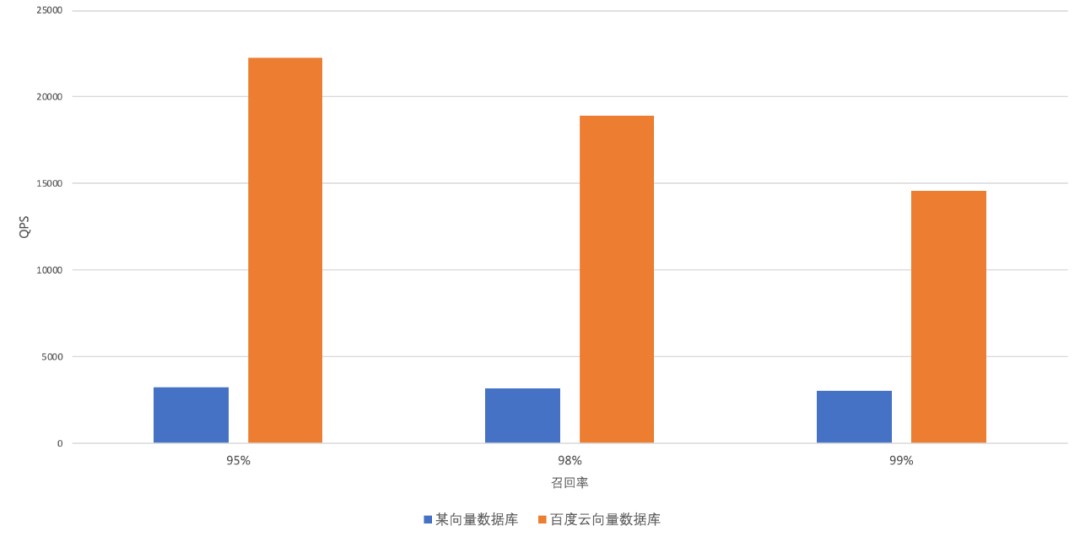
详细测试结果如下表所示: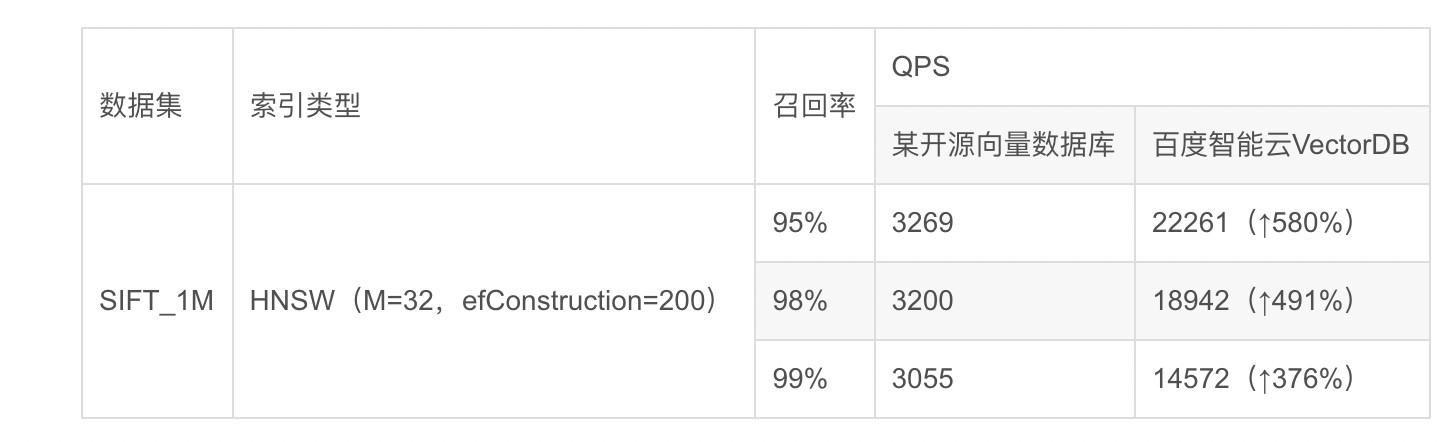
COHERE(768 维)
768 维数据集下,百度智能云 VectorDB 与某开源向量数据库的 QPS 对比结果如下图所示:
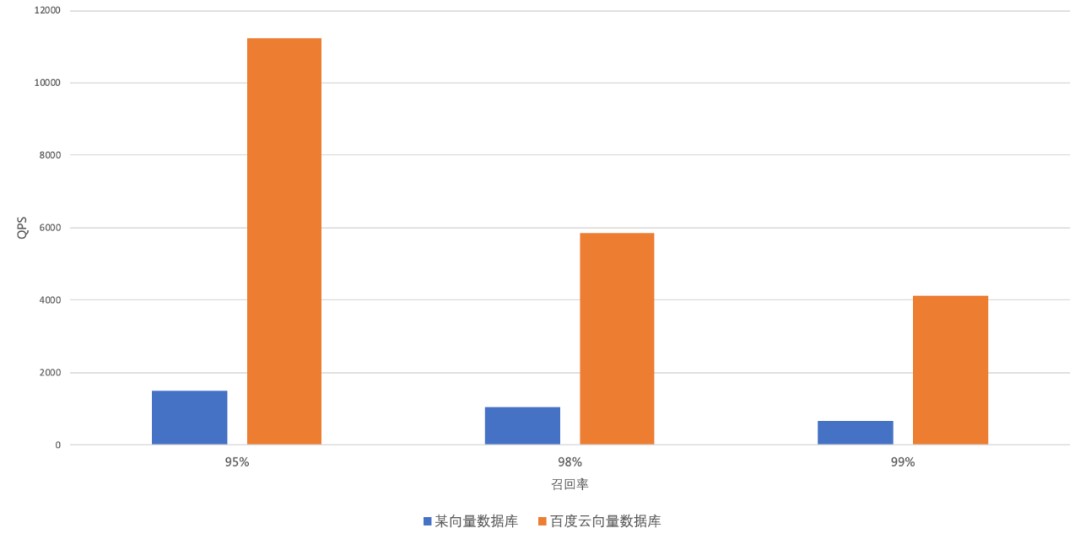
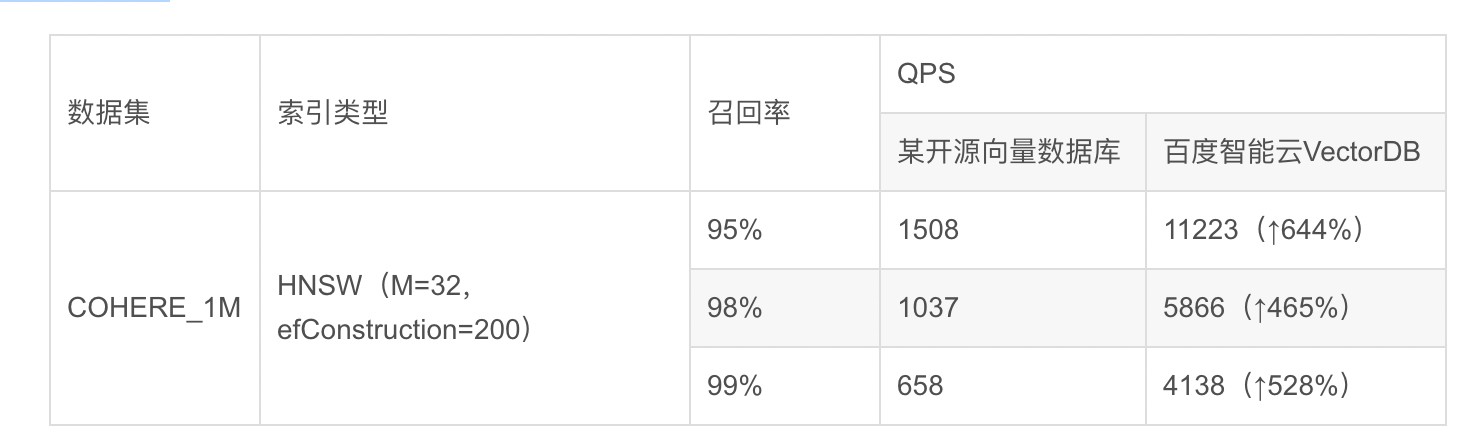
详细测试结果如下图所示:
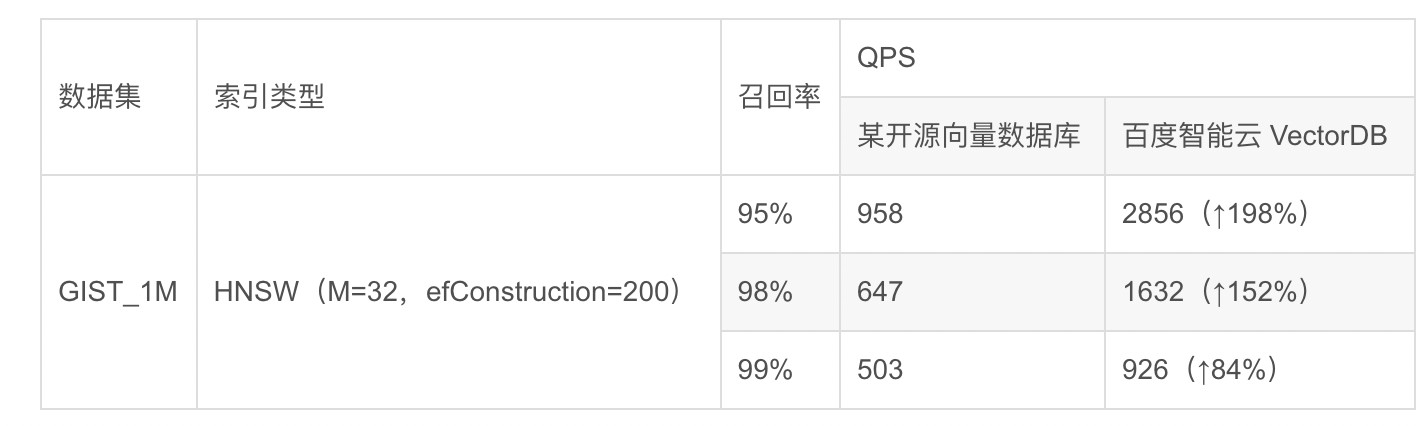
GIST(960维)
768维数据集下,百度智能云 VectorDB 与某开源向量数据库的 QPS 对比结果如下图所示:
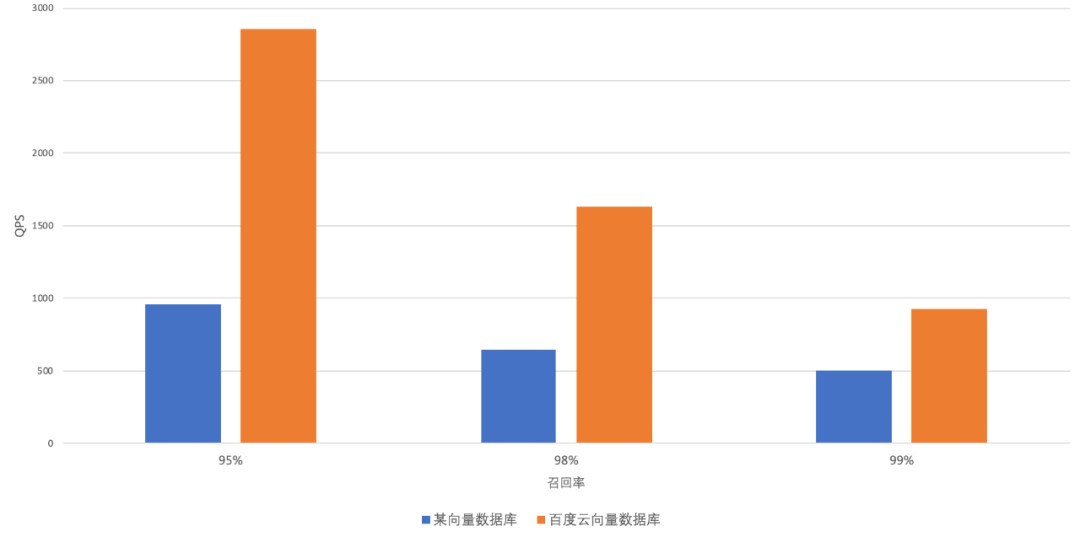
详细测试结果如下图所示:

发表评论
登录后可评论,请前往 登录 或 注册