大数据
文章回答
- 最热
- 最新
- 待解答
开发者无法注册,请修复
百度智能云开发者中心:查看详情您是从哪个页面进到这个链接的,辛苦提供下上游路径
 赞
赞- 踩
 收藏
收藏 评论
评论
3回答Kettle如何实现每秒限制查询速度
千魔啸夜:查看详情对kettle进行每秒查询条数的限制,可以用转换和作业两者结合进行操作。使用两个表输入,第一个表输入查询上次查询的最大可读标识。例如当主键是id的时候就先用表输入查询上一次结果的最大id,在where后面拼接id大于该最大id的数值。第二个表输入查询需要查询的语句,使用limit操作限制每次查询的条数。最后再用作业对该转换实行每秒的执行循环。
- 赞
- 踩
- 收藏
- 评论
1回答Kettle如何对不存在主键的数据库表进行增量更新
千魔啸夜:查看详情对增量更新到新表的数据进行行数统计,在mysql中使用limit语句进行查询(limit 新增数据库总行数,总行数加需要查询的条数)。Kettle中因为前后一共有两个变量,可以先用表输入查询出被插入数据的总行数,limit后一个字段用查询数量表示。如果查询中增加了查询条件不是对全表数据进行增量更新,如何对查询出的数据进行批量插入数据库呢?例如日期字段可以先进行排序,然后例如当日期条件大于A,小于B。新增数据将大于A作为固定条件,每次进行增量更新时候直接修改小于B的值。
- 赞
- 踩
- 收藏
- 评论
1回答Sugar BI页面展示可以设置查看权限么,还是通过链接所有人都可以访问
快去debug:查看详情1.公开分享
2.加密公开分享
3.通过Token验证
详细文档:https://cloud.baidu.com/doc/SUGAR/s/Uk6z5xo1o- 赞
- 踩
- 收藏
- 评论
1回答如何理解star-cubing算法?
php是最好的:查看详情也并不清楚你是哪里不理解。。利用星数的计算过程,也就是star-cubing算法思想。总体过程深度优先遍历星树,通过自底向上聚集,在聚集过程中,利用共享维的概念(相当于自顶向下)剪枝。
- 赞
- 踩
- 收藏
- 评论
1回答1. Sugar和tablebu、powerbi、FineBI、WynEnterprise的区别
智能云大数据架构师:查看详情图表丰富、拖拽式编辑、交互设计、与第三方系统无缝集成
- 赞
- 踩
- 收藏
- 评论
1回答求助大神,实时大数据存储及查询分析解决方案
桃子:查看详情你这种情况就非常适合使用基于Hadoop的HBase来存储数据,HBase不仅仅适合于做大数据的存储和处理,它的一个突出的性能优势就是写数据, 你的系统每隔10s就要写一次数据,Hbase就比较适合,最好不要使用传统的关系型数据库(例如MySql),这会让你的系统在后期出现许多性能瓶颈, 另外,HBase在数据查询上面也有提供了一些快速的优化方法,使用Hbase对数据进行读写,使用map/reduce对数据进行处理,你可以查阅相关资料看看。
- 赞
- 踩
- 收藏
- 评论
1回答大数据和云计算的关系是什么?
热心市民鹿先生:查看详情首先答主得问自己,什么是大数据?什么是云计算?思考清楚了这个问题,其实很好想明白。 也就是相互依赖的关系。通俗点说大数据和云计算之间的关系就像容器和水的关系,云计算就像一个容器,而大数据则正是存放在这个容器中的水,大数据要依靠云计算技术来进行存储和计算。 大数据必然无法用单台的计算机进行处理,必须采用分布式计算架构。它的特色在于对海量数据的挖掘,但它必须依托云计算的分布式处理、分布式数据库、云存储和虚拟化技术。而云计算的关键词在于“整合”,无论你是通过现在已经很成熟的传统的虚拟机切分型技术,还是通过Google后来所使用的海量节点聚合型技术,他都是通过将海量的服务器资源通过网络进行整合,调度分配给用户,从而解决用户因为存储计算资源不足所带来的问题。“如何存储如今互联网时代所产生的海量数据,如何有效的利用分析这些数据等等”也正是大数据时代数据的爆发式增长所带来的新的研究课题。
- 赞
- 踩
- 收藏
- 评论
1回答奇瑞瑞虎8pro如何连接百度CarLife+?
查看详情- 赞
- 踩
- 收藏
- 评论
0回答什么数据可视化工具比较好用?
xxinjiang:查看详情推荐有免费试用机会、并且简单好用的数据可视化Sugar BI
新手闭眼入,操作简单,5分钟就可以上手制作可视化页面。哪怕你是零代码基础也能做出你想要的可视化图片!效果可以参考下图:
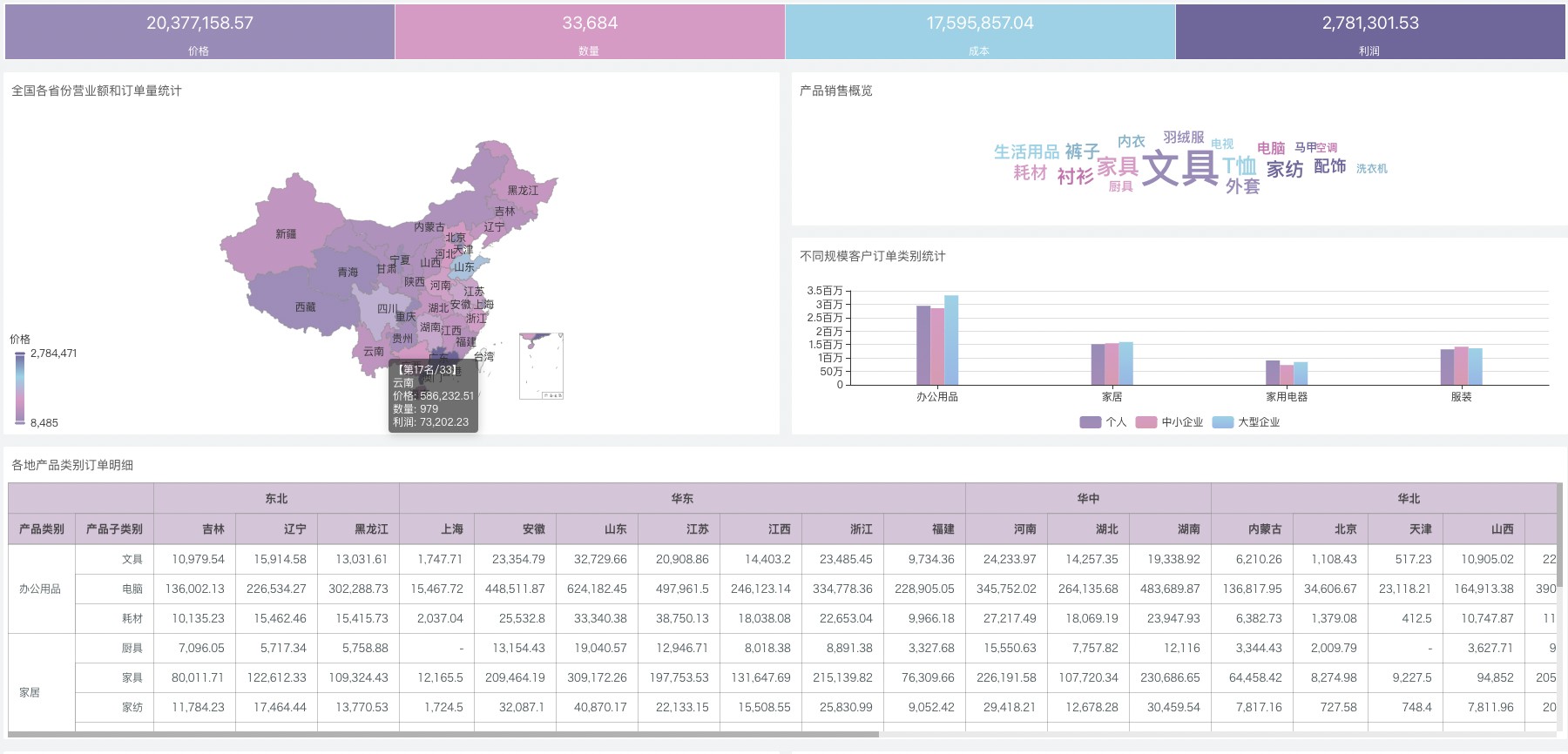
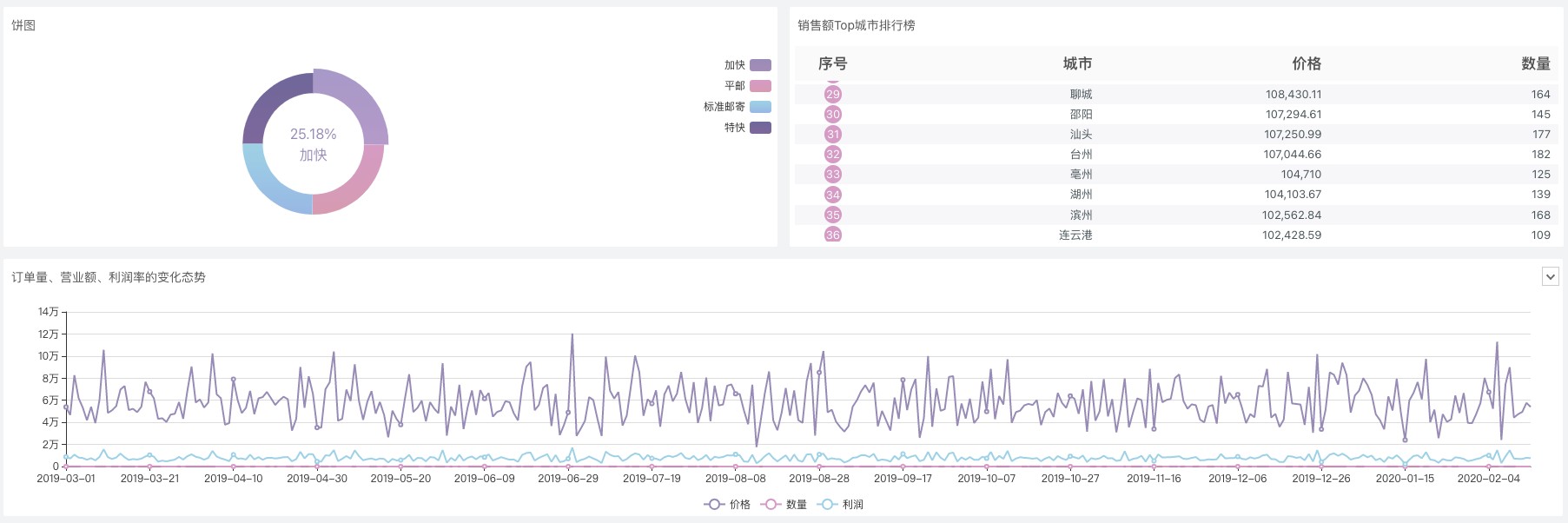
数据可视化Sugar BI是百度旗下的BI产品,而且他是基于百度Echarts(我想做数据可视化的朋友们应该都听过Echarts的大名吧),拥有100多种图表组件可以供你选择。开箱即用、零代码操作、无需SQL,5分钟即可完成数据可视化页面的搭建,降低开发成本的同时,提高业务对数据的使用效率,助力企业精准快速决策!
并且操作过程非常简单,你只需要选好图表组件,然后将想要分析的数据拖拽至组件里,系统会自动帮你生成!
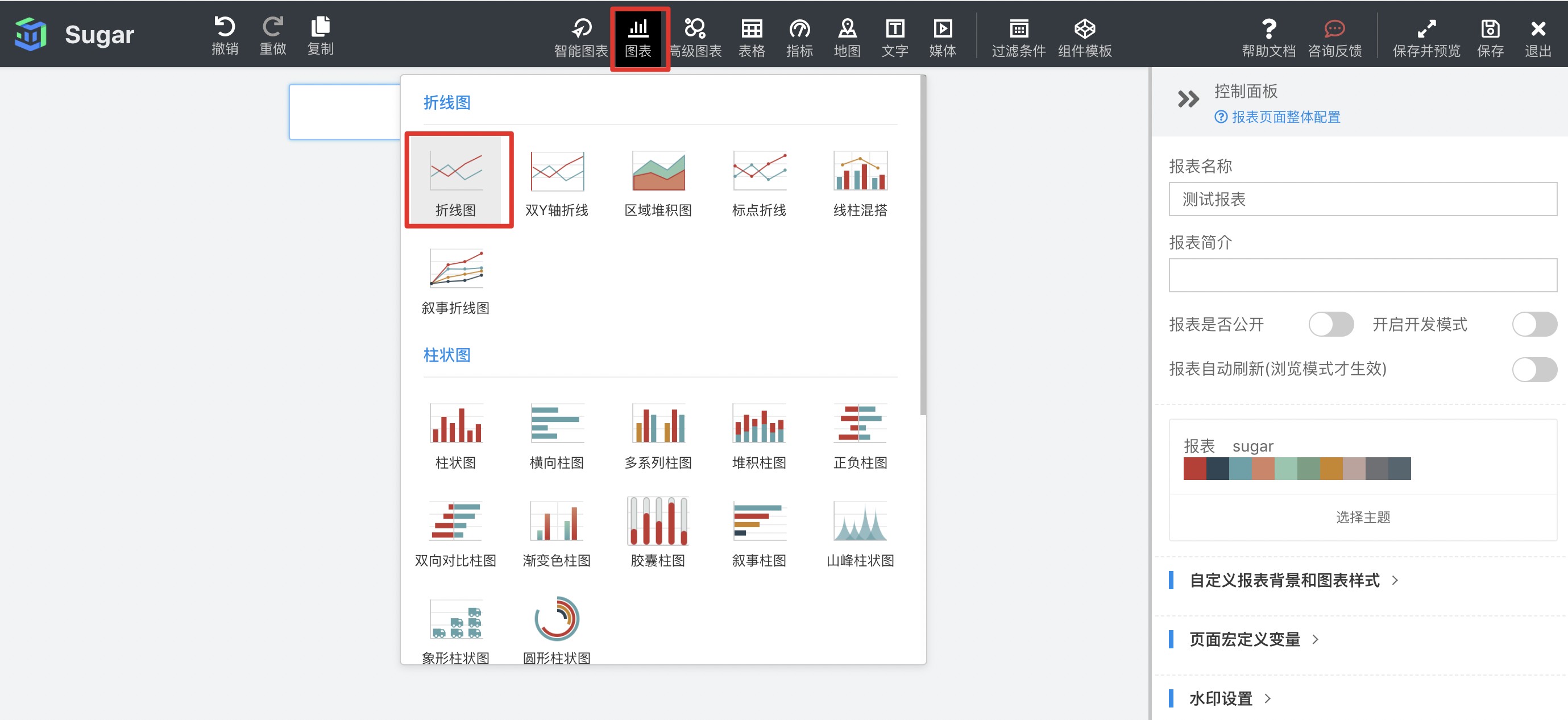
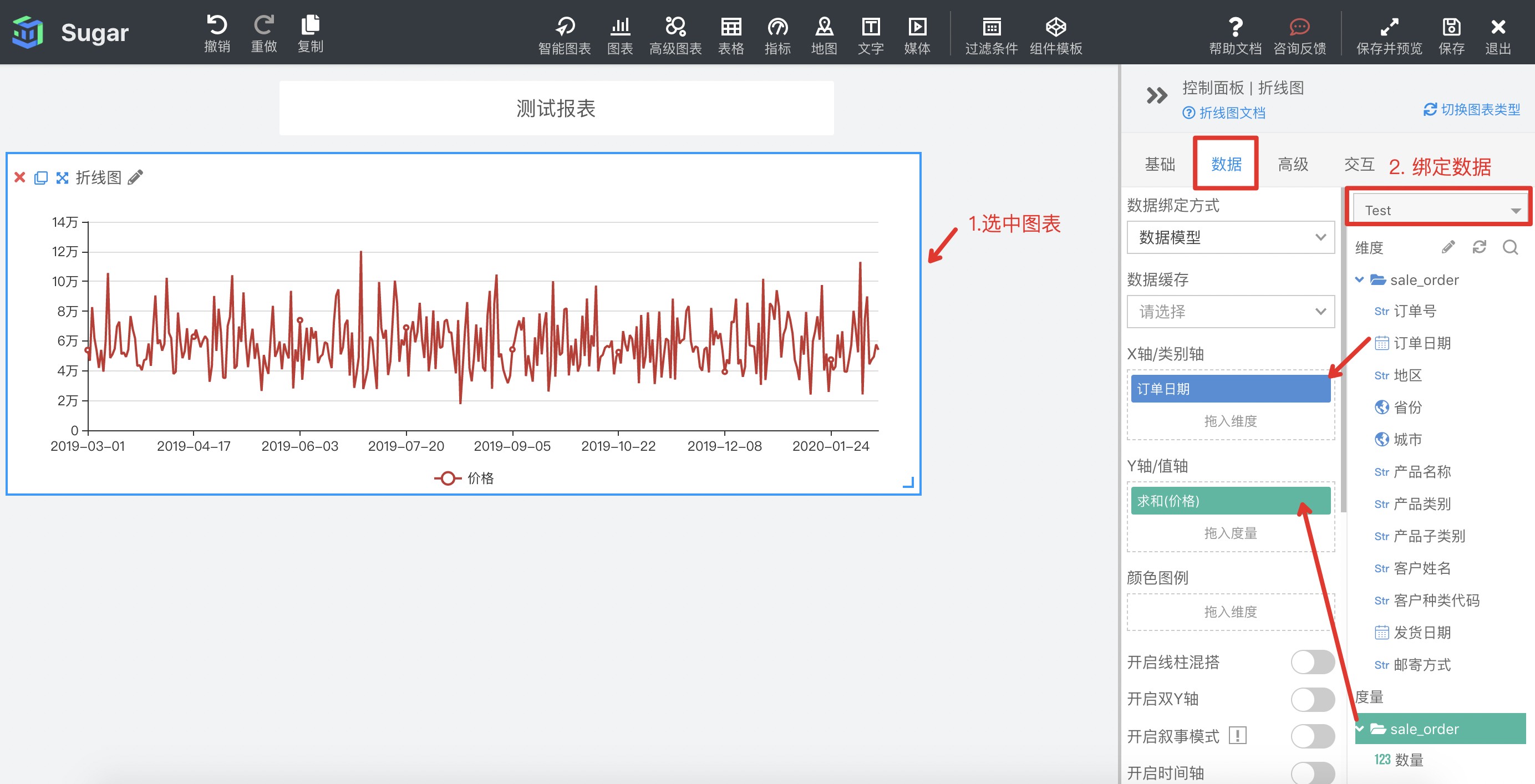
百度数据可视化Sugar BI还给用户准备了超多种大屏的模板(PC端、移动端),创建后我们自己修改数据就可以生成一个超级完美高级的大屏啦!
Sugar BI官网现在还有30天免费试用的活动,欢迎大家试用!
数据可视化Sugar BI- 赞
- 踩
- 收藏
- 评论
1回答
 写文章
写文章 提问题
提问题最新活动
