Apache Doris在微博平台的应用
作者:Apache Doris (incubating)2019.09.02 08:57浏览量:6482简介:分享者:马骎 微博平台研发部资深系统研发 前言 微博的工程业务团队是来自微博平台研发的feed组,微博平台的关注流和转评赞互动都来自工程业务团队的技术支持。
分享者:马骎 微博平台研发部资深系统研发
前言
微博的工程业务团队是来自微博平台研发的feed组,微博平台的关注流和转评赞互动都来自工程业务团队的技术支持。
基于对业务数据关注的希望,微博从17年初开始做数据方面的建设。目前系统已经应用了Kafka、HDFS、Spark等,同时,Doris也在其中起到了重要的作用。
1.背景介绍

微博团队在2018年1月开始调研Doris,进行功能、性能方面的评估;2019年初正式引入生产环境。微博目前总共部署两个Doris集群,部署规模在40+节点。上图展示了Doris在微博部署的具体规模,可以看到服务器除了磁盘容量上的差别外,配置基本同构。
部署方法上,微博团队采用Docker容器的方式部署Doris,同时也给Doris建立了服务池,保持其他业务运维管理的一致。
Doris目前在微博主要承接了阅读互动相关方面的数据支持的需求,单天写入规模大致维持在4~5亿条这个量级。
2.Doris应用场景

Doris在微博的应用场景主要分为3类。
- 首先存储微博阅读数等历史数据。微博上实时展示的阅读数据,经常面临来自不同媒体的质疑。为消除质疑,需按分钟存储各条微博的互动状态以及阅读量等数据,以便查询审计之用。引入Doris存储此类数据,可大大提高查询效率。
- 应用于多维分析和监控。之前的业务监控使用graphite,但是想做一些多维分析的时候比较困难。后来应用Doris做存储,可以实时看到数据上的刷新和变化,对掌握业务的情况有许多的帮助。
- 热点内容的实时统计。每分钟导入评论最多的2000条微博进入Doris,实时统计一段时间区间内的微博热点。
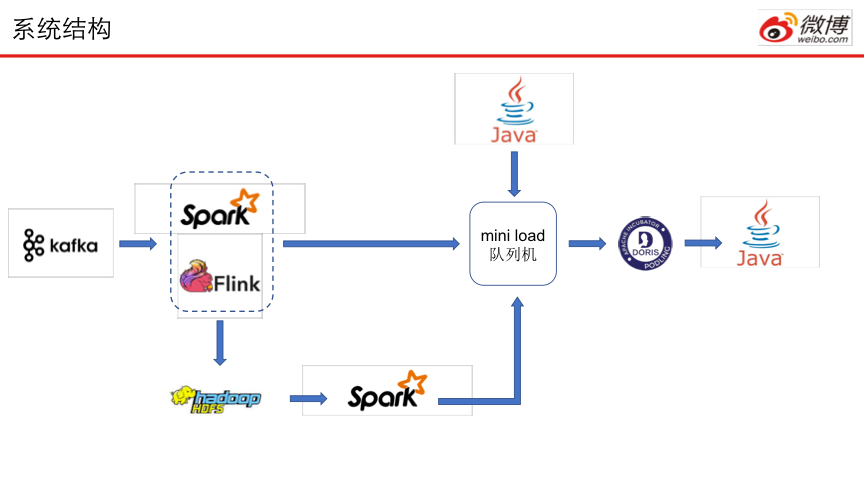
微博数据流可以分为实时和离线两条处理方向。实时和离线数据流的起点皆是Kafka,实时数据流经过Spark/Flink的流处理,实时灌入Doris,以供查询;离线数据流经Spark/Flink计算之后,写入分布式文件系统HDFS,再以例行任务的形式经Spark写入Doris。
至于A/B Test的计算数据也可以通过类似方式随时导入Doris中,为后续评估提供数据。
2.1微博阅读数
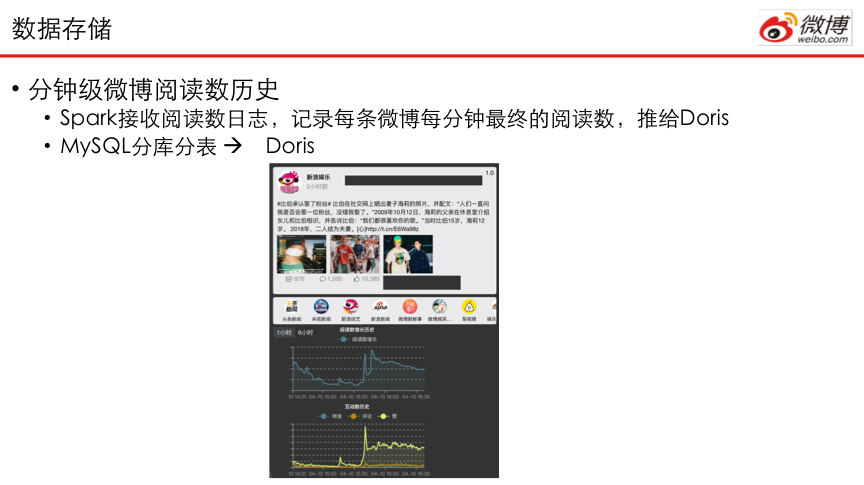
微博互动日志以分钟粒度现在Spark中进行计算,而后以Mini Load任务的方式推送到Doris中,进行实时的微博阅读数据展示。这种追踪粒度也可以为热点应对提供数据支持。
2.2多维分析

在业务中需要支持多维分析,恰巧这也是Doris最擅长的。于是微博团队开发了一个基于Doris的多维分析工具。把日志导入到Doris,定义一个表,将多个维度作为key并预留多个value列,应对不同维度数量需求,然后在外部维护。通过这个工具,不论是离线分析的还是实时的分析都非常方便,这都依赖于Doris快速查询的性能。
2.3简单计算

想了解当前一段时间区间内,评论互动最多的微博,就需要倚赖此项计算功能。图中的事例就是5分钟内,受到评论最多的微博列表。每分钟将评论最多的2000条微博导入Doris中,再辅以SQL查询,即可轻松得到相关信息。分钟级别时效性分析也能有效帮助平台方监控微博的实时流量动态。
3.Mini Load队列机

Mini Load队列机的由来
微博引入Doris的时间比较早了,之前版本在导入时总会遇到一些问题,稳定性差、主要任务卡死、不便于导入太多任务,因此便开发了Mini Load队列机来增强导入性能。
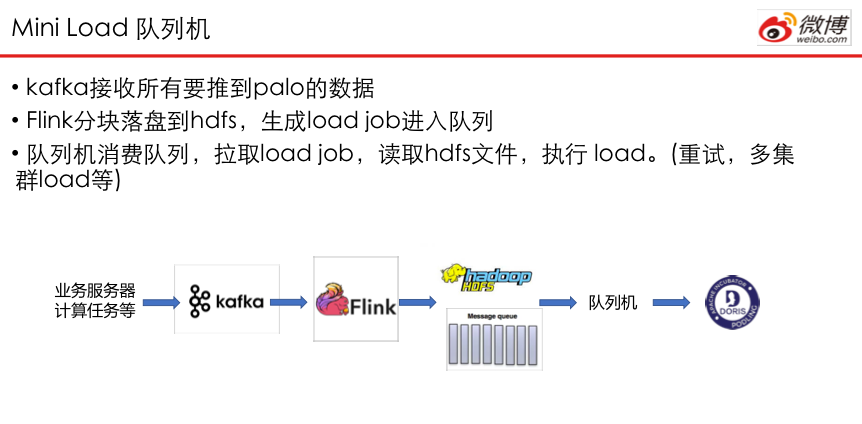
Doris 0.9的开源版本中提供Broker Load和Mini Load两种导入方式。Broker Load用以解决大批量离线文件的导入,Mini Load针对小批量文件的快速加载需求。微博数据分析对时效性比较敏感,数据写入都采用Mini Load方式予以进行。
微博平台计算采用的Spark/Flink都是纯流式接口,为了弥补Spark/Flink的streaming和Doris Mini Batch之间的差异,平台方特别提供了Mini Load队列机的机制。通过Mini Load队列机,大幅减少Doris的扇入扇出,提高整体吞吐。
微博数据先落到Kakfa中,随后Flink逐段读取kakfa,并写入到HDFS中。当文件按分钟粒度进行合并之后,写入相应任务到队列机中,进行调度、消费数据。
Doris在0.10.0版本中,会发布Streaming Load的功能,届时即可使用此功能接收Spark/Flink的数据流。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册