Apache Doris在京东广告平台的应用
2020.03.21 11:53浏览量:4433简介:分享者:京东广告平台/刘航源/Apache Doris Contributor 前言: 京东的广告平台致力于为每一位广告主提供最准确、丰富的报表服务。在今年
分享者:京东广告平台/刘航源/Apache Doris Contributor
前言:
京东的广告平台致力于为每一位广告主提供最准确、丰富的报表服务。在今年(2019年)的618年中大促中,Doris更是凭借着稳定、高效的表现得到了京东团队的认可。
- 背景介绍
- 查询效率与实时性:京东广告平台有上百张报表,每日百亿级别的聚合结果增量,需要保证查询效率与实时性的统一。
- 低延迟:区别于分析师的ad-hoc分析需求,报表场景对于延迟要满足毫秒级别。
- 高QPS:每日有几千万的查询调用量,日常峰值QPS达到四千以上,SQL on Hadoop的方案难以满足。
- 方案简单:既能满足报表查询,又能满足OLAP分析型需求,作为数据的统一出口。
为了解决目前存在的问题,京东急需一套完整的、简单已运维且稳定的报表存储方案。
- Why Doris ?
目前开源的解决方案主要是SQL on Hadoop 的生态。但是Hadoop方案整体上依赖模块过多,对于业务团队来说,运维成本高。
如果使用公司大数据平台提供的Hadoop环境,难免与其他团队共用,查询效率与稳定性难以保证,对于对查询延迟要控制在毫秒级的报表需求更是无法满足。如果自建Hadoop环境,自己维护,又会出现运维压力太大的问题。比如使用Kylin,就需要维护多个Hadoop生态模块,任何一个模块的不稳定都可能导致报表系统的异常。
所以我们选择了Apache Doris作为我们的报表存储与查询模块,主要考虑到其几个关键优点。
- 谷歌Mesa理论支持,百度工程实践。并且已经进入Apache基金会孵化,未来可期,并且后续开发维护有保障。
- 完善的功能支持,标准MySQL协议。因为Apache Doris支持MySQL协议,现存的很多外围MySQL功能模块都可以使用,整体使用都很方便。并且原有的MySQL数据库的用户迁移成本很低。
- 高并发、高QPS支持。因为核心代码全部使用C++实现,性能方面要优于其他语言。另一方面良好设计也保证Apache Doris在应对高并发时性能要优于其他开源产品。
- 方便运维,架构清晰。只有FE和BE两个模块,外部依赖少。可以专心维护Doris系统,其他ETL的工作可以交给业务部门处理,解放了人力。
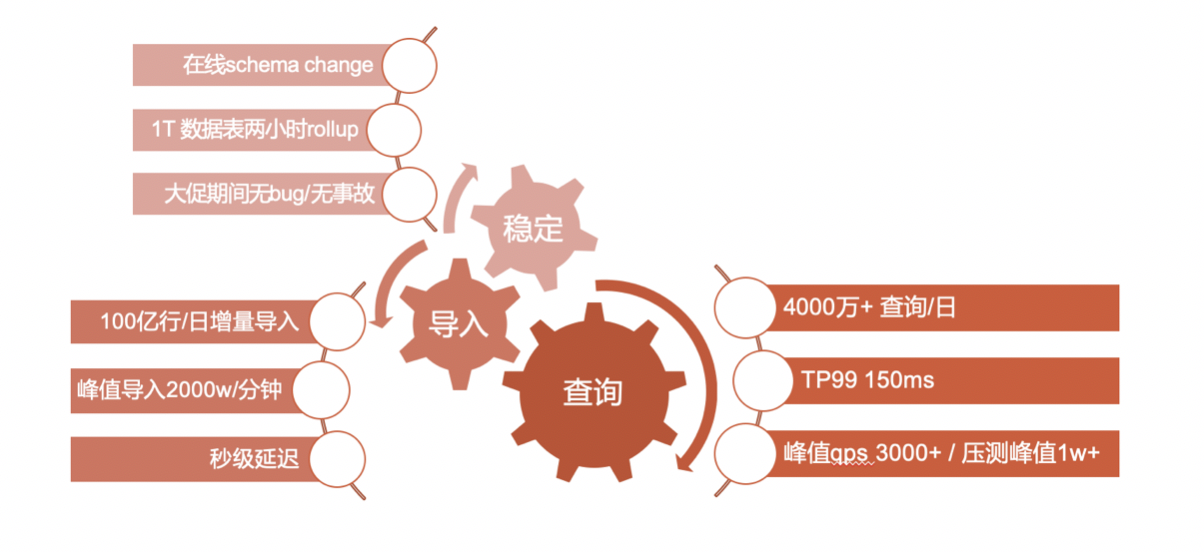
- 618战绩
618大促期间,Doris提供了非常稳定的线上服务。在线进行了稳定的schema change,全程无事故。
在导入方面,支撑100亿行/日的增量,导入峰值达到2000w/分钟,秒级导入延迟。
在查询方面,支撑了4000w+的每日查询,TP99仅为150ms。大促期间QPS峰值3000+,压测阶段峰值达到1w+。
- 在京东广告平台的应用
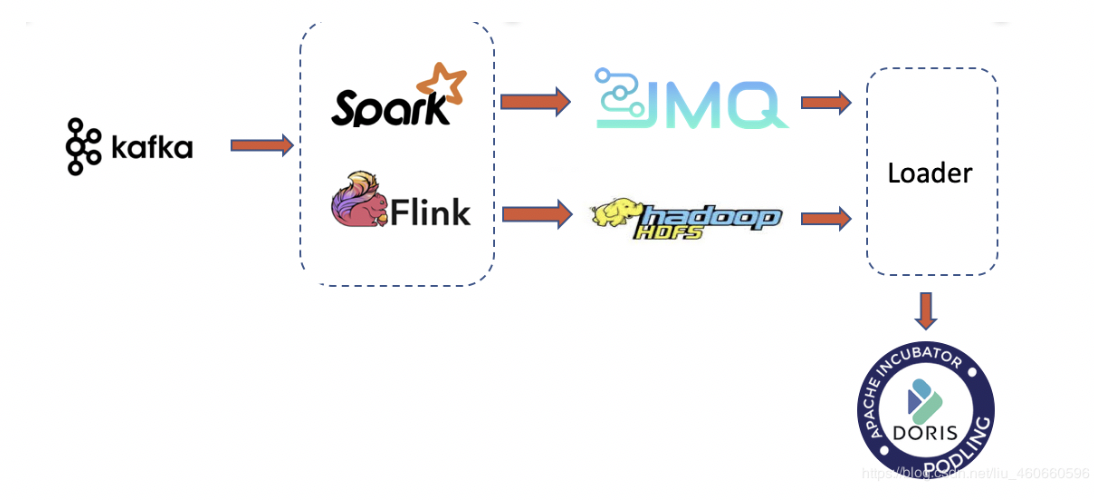
上图介绍了数据从产生到入库的过程所有的点击流。订单流消息会进入Kafka消息队列,然后经由Spark/Flink的计算,生成一个批次数据,这个批次数据产生的频率由业务端控制。产生数据文件后,向JMQ(京东内部消息队列)中录入一个。任务。后面的Loader模块会根据任务中的批次路径拉取数据,导入Doris中。
JMQ内存储的并不是原始的消息,而是经过Spark/Flink生成的批次文件的路径。同时会有一个自定义的Label标签值,来保证入库任务的不重不丢。因为同一个批次任务使用相同的Label值,而Doris中一个Label值只能被导入一次。而真正业务去重逻辑则放在Spark/Flink这一层,由业务方控制,这样就可以使业务与存储解耦开,同时又可以保证Doris中的增量频率不会太快,保证了查询的性能。
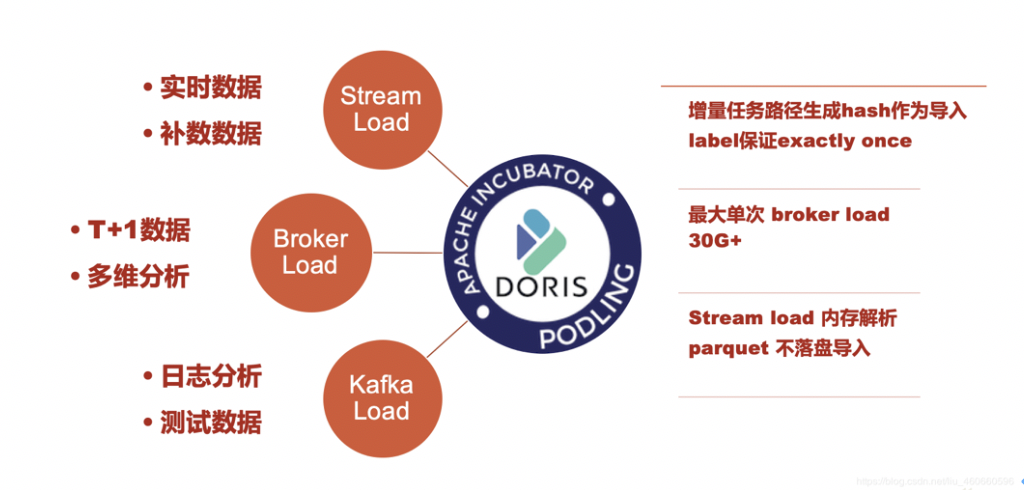
在内部我们使用了三种导入方式,下面分别介绍下使用的场景:
- Stream Load:主要使用在导入实时数据方面,当前内部数十张表,每张表一分钟一更新。保证了业务数据的准实时。并且因为Stream Load 的同步任务,内存传输数据的特性,Stream Loader不需要拉取数据到本地磁盘,可以实现直接读取hdfs上的增量数据,内存解析,内存导入的功能。
- Broker Load:主要用在单次更新数据量较大的多维分析型报表和T+1更新的离线表的业务上。目前最大单次更新在30G+,性能稳定良好,一般可在20分钟以内完成入库。
- KafkaLoad:因为Kafka的原因,以及业务方有重复发送消息的情况。Apache Doris 直接对接Kafka 的 Kafka Load方式无法实现消息去重的功能,所以我们目前并没有将其使用在广告效果报表方面。而我们在一些日志分析的需求上使用Kafka Load。因为日志分析对数据准确性没有要求非常高,那么使用KafkaLoad就可以省去中间的ETL的工作,简化了整体架构。
5. 查询心得
- 设置合理的分区分桶列:因为Doris会根据分区分桶实现过滤,所以建表时应该谨慎选择分区列和分桶列。能否命中分区分桶列,对查询的影响非常大。
- 建立合理的Rollup表:可以说物化rollup的功能是Doris查询效率高的关键因素,因此建立合理的rollup表非常重要。那么实际使用中如何选择rollup呢?一般是将Doris fe的日志导入Doris中,分析慢查询,Scan bytes等指标,找到消耗资源大的查询,针对这些实际的查询建立Rollup表。
- 设置doris_max_scan_key_num:oris会将可枚举的类型拆分查询,比如id=5 and date>='2019-01-01' and date<='2019-01-31'的查询,doris会将其拆分成31个小查询分别查询[5,2019-01-01]...[5,2019-01-31],但是会有一个阈值(doris_max_scan_key_num),超过这个阈值后不再拆分,可根据业务调整

发表评论
登录后可评论,请前往 登录 或 注册