Apache Doris (incubating) 0.12.0版本预览
作者:Apache Doris (incubating)2020.01.07 01:38浏览量:3586简介:What’s Doris? Doris是一款基于Mesa模型的MPP、列式数据仓库,具有兼容MySQL协议,方便用户使用,在线运维等特点。 Doris的
What’s Doris?
Doris是一款基于Mesa模型的MPP、列式数据仓库,具有兼容MySQL协议,方便用户使用,在线运维等特点。
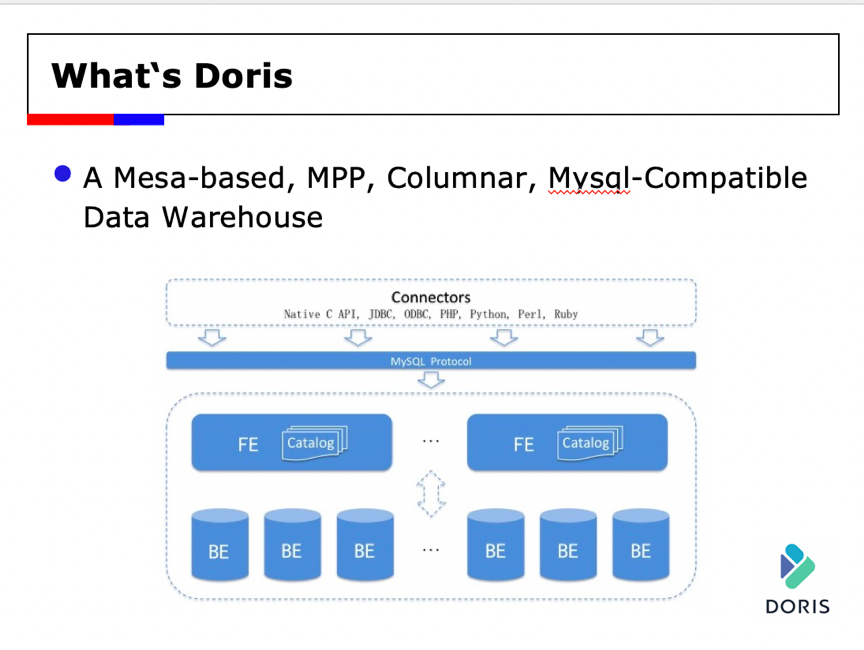
Doris的架构中主要包含两个模块:FE和BE。 FE模块主要用来进行元数据管理、事务管理、查询规划和任务调度,Doris支持多个FE,实现了在线的高可用;BE负责数据的存储、查询计划的执行。BE能够按需进行动态的伸缩,在线扩展,方便部署和运维。
我们已经发布了0.11.0版本,在下一个版本0.12.0中,主要包含Segment v2这个新的功能,用新的存储格式来解决原来的一些问题。
What’s Segment?
Doris之前的存储格式被称为Segment V1,如下图所示,BE中的存储引擎会将数据存成Segment文件。Segment V1是一种跟orcfile类似的存储文件,实现了纯列式的存储,并且加上short key index,在其中还支持了zone map/bloom filter索引,并支持了谓词下推和向量化执行等优化。

但V1版本的Segment中,存在以下问题
1、按照字节流的方式进行读取和解析,效率不高
2、存在随机Seek的问题,在解析流的时候,需要先读8字节的头部信息,然后在读取一个压缩块信息
3、String类型按照Plain方式存储,效率比较低
4、对Cache不友好,只有Column Stream粒度的Cache
5、只缓存压缩之后的数据,对数据的多次读取,会解压多次数据
6、难以扩展新的索引,比如Bitmap索引
7、读取的逻辑比较复杂,难以理解
Segment V2,存储效率性能提升
由于Segment V1的种种问题,Doris设计了Segment V2以提升存储的效率和性能。
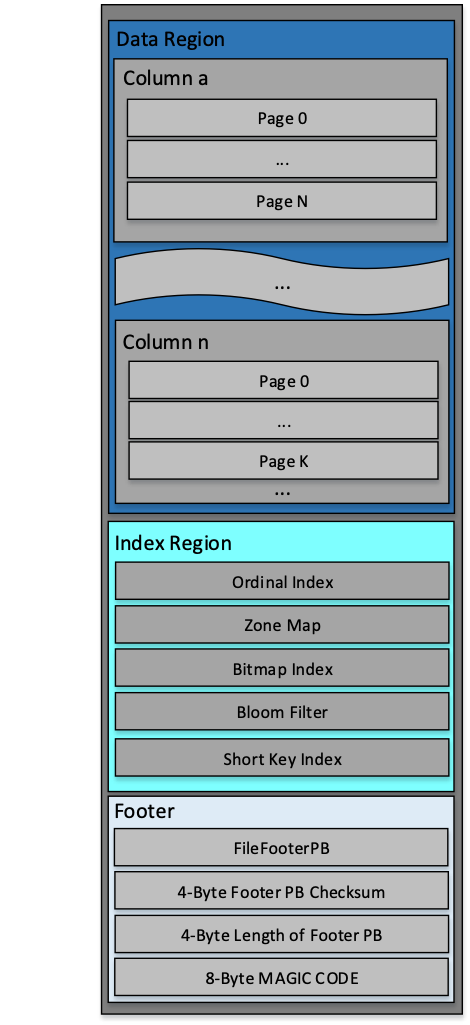
如上图所示,Segment V2也是一种纯列存的存储格式,分为三个部分:数据区,索引区和元数据区。数据是按照Page为粒度进行组织的,能够解决原来按照字节处理的问题。Page是编码和压缩的单位,并且我们在Page粒度实现了Cache,Cache解压缩之后的数据,对同一份数据的反复读取,只会解压缩一遍。

并且,我们实现了原来的Short Key、Bloom Filter、Zone Map的索引,同时我们增加了行号索引和Bitmap索引。在优化方面,我们实现了谓词下推和向量化执行,延迟物化的优化目前也在开发之中。
Segment V2——Page
首先来介绍一下最基本的概念:Page。在V2上,Page是编码和压缩的基本单位,而且索引的粒度基本也都是Page的,也是Cache的基本单位。
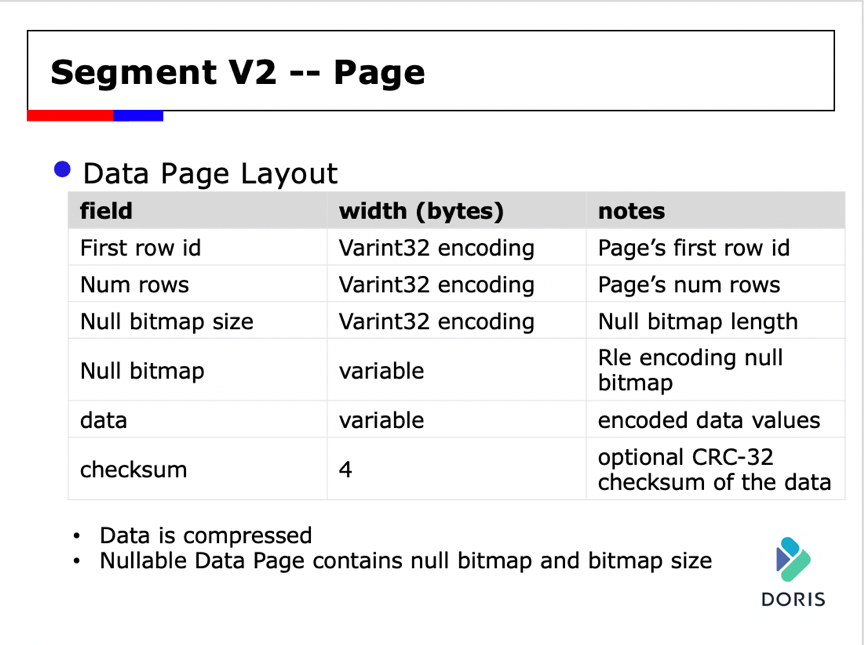
Page的格式分为头部信息,数据信息和Checksum。其中头部信息包含Page的第一行行号及Page中包含的行数。如果Column是Nullable,则还会存储NullBitmap的长度和NullBitmap信息。Data就是经过编码和压缩的数据信息。最后会在Page的末位存储Page的Checksum信息,用于校验数据的正确性。
Segment V2——Index Page

除了Data Page,我们还引入了另外一个概念:Index Page,用来存储索引信息,支持行号索引和Value索引,主要用于带索引数据列的实现,比如Bitmap索引和Bloom Filter索引。具体内容就是存储行号到Page Pointer的信息或者Value到Page Pointer的信息。
Segment V2——Index

上图是V2中索引的实现大概示意图。目前我们实现了Shortkey索引、行号索引、Zonemap索引、Bloomfilter索引和Bitmap索引,其中Short Key索引是构建在Row Block粒度的;行号、Zonemap、Bloomfilter索引是构建在Page粒度的,Bitmap索引是在行号上的。我们实现行号索引,能够比较简单的将各种索引组合在一起,以提升查询的性能;并且能够方便扩展新的二级索引。
Segment V2——Write
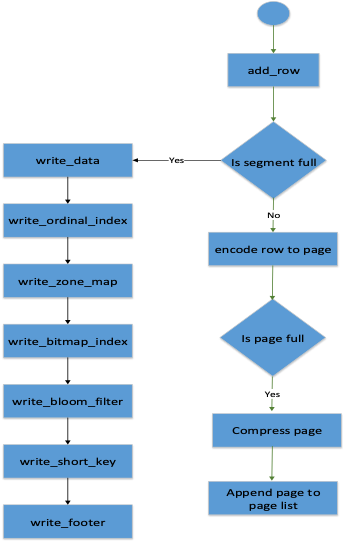
关于V2的写入流程:
1、Add Row,数据是一行一行添加在Segment中,但是是保存在内存中
2、当Segment文件大小达到阈值,就会将Segment文件刷到磁盘,整个刷数据的顺序就是按照前面Segment图中描述的顺序写入的,先写数据,然后写索引,然后再写Footer
3、如果segment文件大小没有满,就会将数据添加到当前的Page中,进行编码;如果Page满了就会进行压缩,将Page添加Page List中,保存在内存中。
整个过程具有以下的特点:
1、Segment文件是缓存在内存中,等到阈值时一次性写入到磁盘。一方面是为了实现控制文件的组织结构,另外一方面是为了顺序I/O
2、Segment Size阈值可以配置
3、各个列的同一种类型的索引是写到一起的。
Segment V2——Read
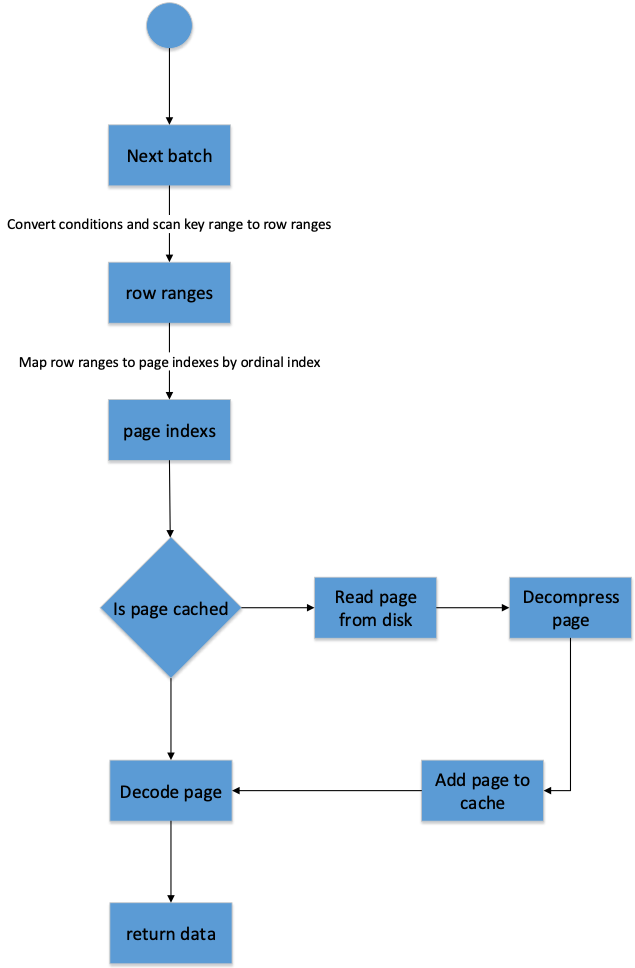
下面是Segment读取的流程
1、在Doris中,数据是按照Batch方式读取的,不是一条一条读取。调用next_batch读取下一个批次的数据,Batch大小是1024行,在调用这个接口的时候会传入Predicate信息。
2、获取要读取的行号范围,该过程会利用Predicate信息和索引信息,过滤掉一些不需要的行号范围
3、将行号范围映射到各个列的Page Ids范围
4、在各个列中查询该列的Page是否被缓存,如果缓存在内存中,就Decode Page信息,填充到返回结果的Batch内存中
5、如果该列的该Page没有被缓存,就会进行I/O操作,将Page加载到内存中,进行解压缩,然后加到Page Cache中,然后Decode该Page的数据,填充到Batch中
6、最后会拼装各个列的数据,进行向量化执行Predicate过滤,之后返回给调用方。
Segment V2——Predicate Pushdown

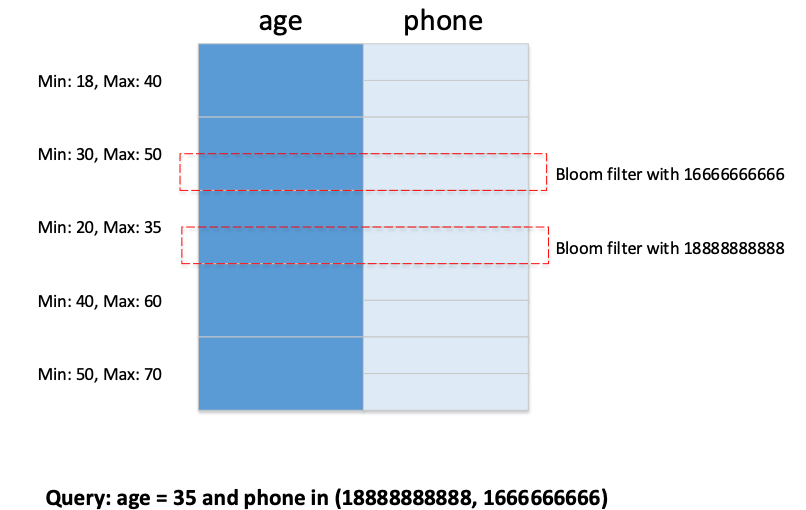
这里大概介绍一下,在读取过程中谓词下推是怎么实现的。在V2中,暂时支持的Predicate还比较简单,后续打算会进行扩展。下图是一个例子,如果用户查询age = 35 and phone in 的语句,那么在Zone Map和Bloomfilter索引过滤之后,就会只剩下红框中的数据需要读取,降低读取的数据量
Segment V2——Encoding & Compression Framework
在V2中,为了实现高效的在Page粒度的编码,我们目前已经支持了多种方式的编码:
- Run Length Encoding
- Bitshuffle encoding
- Plain encoding
- Frame of reference encoding
- Dict encoding
- Prefix encoding
未来也会在此基础上增加新的编码,如PageBuilder/PageDecoder以及EncodingInfo Factory
现在也支持了多种压缩的框架:
- Zlib
- Snappy
- Lz4
- lz4f
未来也会支持更多压缩框架,如BlockCompressionCodec,Compression Codec Factory等
Segment V2——String Encoding

相对V1做了字典压缩的功能,原有V1版本中用的是Plain Encoding的方式,效率比较低。Dict Encoding主要是用来解决低基列的字符串类型的存储。最终实现的例子如下:会建一份词典,并存储词典对应的编码来对应原始数据。同时Prefix Encoding也已经实现了,后续会进行一些优化。
性能数据

下面是一些性能测试。用随机构造的不同基数下的数据进行测试,V2的词典压缩效果在低基数要明显优于v1。用TPCH的Part表进行测试,效果会更加明。同时,从业务数据上看,词典压缩效果也比较明显,能够节省达50%的存储空间。
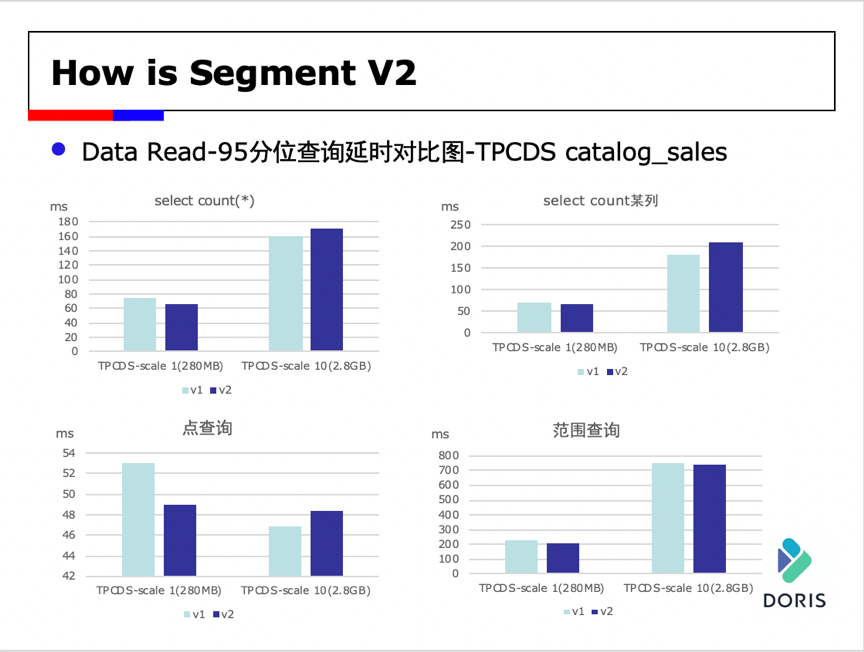
数据导入在不同的情况下也有不同程度的提升。
我们使用TPCDS catalog_sales进行了测试,从上面的数据来看,目前相对于v1,v2的性能有所提升,但是有进一步的优化空间,我们正在努力进一步提升v2的效率和性能。
RoadMap

未来Doris的主要工作包括:继续优化Segment V2,并在下一个版本中发布Bitmap索引的功能,并持续探索复杂类型的支持和云原生的设计。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册