PostgreSQL 的复制和自动故障转移
作者:pger2023.11.13 10:58浏览量:745简介:PG中设置和配置物理流复制后,如果服务器的master发送故障,则可以进行故障转移。
什么是 PostgreSQL 复制
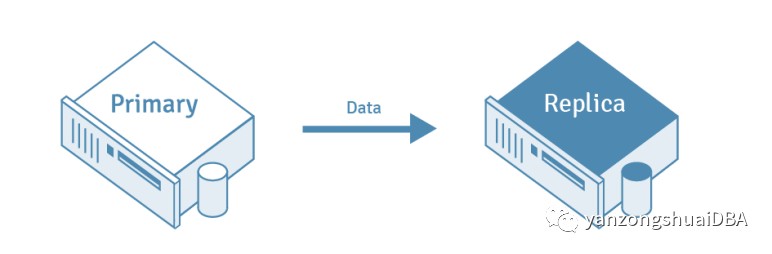
将数据从一个服务器复制到另一个服务器的过程就是PG复制。源数据库服务器通常称为Master,而接收复制数据的数据库服务器称为Replica服务器。
PostgreSQL 中的自动故障转移是什么
PostgreSQL 中设置和配置物理流复制后,如果服务器的master发送故障,则可以进行故障转移。故障转移是描述恢复过程的属于。PostgreSQL 中可能需要一些实际,特别是因为 PostgreSQL 本身不提供用于检测服务器故障的内置工具。幸运的是,有一些工具可以实现自动故障转移,可帮助检测故障并自动切换到备,从而最大限度地减少数据库停机时间。
Patroni 和 repmgr 可以自动检测故障并将最新的备提升为新主,从而帮助避免代价高昂的数据库停机时间。Patroni 甚至提供快速、自动的故障检测。
高可用性与故障转移复制
高可用性是指数据库系统的设置,以便在主服务器或主服务器发生故障时备用服务器可以快速接管。为了实现高可用性,数据库系统应该满足一些关键要求:它应该具有冗余以防止单点故障、可靠的切换机制以及主动监控以检测可能发生的任何故障。设置故障转移复制提供了所需的冗余,通过确保在主服务器或主服务器出现故障时备用服务器可用,从而实现高可用性。
为啥使用 PostgreSQL 复制
数据复制有很多用途:OLTP 性能、容错、数据迁移、并行测试系统
OLTP 性能:从联机事务处理 (OLTP) 系统中移除报告查询负载可以提高报告查询时间和事务处理性能。
容错:如果主数据库服务器发生故障,副本服务器可以接管,因为它已经包含主服务器的数据。在此配置中,副本服务器也称为备用服务器。此配置还可用于主服务器的定期维护。
数据迁移:升级数据库服务器硬件,或为另一个客户部署相同的系统。
并行测试系统:将应用程序从一个 DBMS 移植到另一个 DBMS 时,必须比较来自新旧系统的相同数据的结果,以确保新系统按预期工作。
Patroni 和 repmgr 使管理 Postgres 复制变得容易,提供复制提供的所有好处。
PostgreSQL 复制模型
在单主复制 (SMR)中,对指定主数据库服务器中表行的更改被复制到一个或多个副本服务器。副本数据库中的复制表不允许接受任何更改(来自 master 的除外)。但即使他们这样做了,更改也不会复制回主服务器。
在多主复制 (MMR)中,对多个指定主数据库中表行的更改会复制到每个其他主数据库中的对应表。在此模型中,通常采用冲突解决方案来避免重复主键等问题。
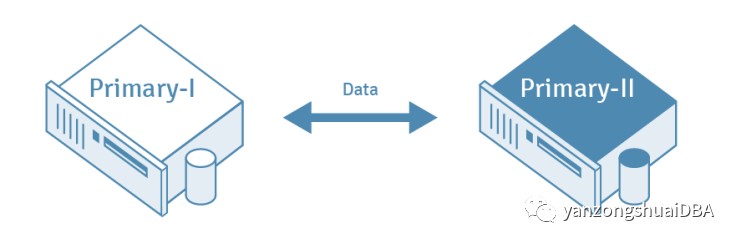
多主复制 (MMR)增加了复制的用途:
写入可用性和可扩展性。
能够使用主数据库的广域网 (WAN),该数据库在地理位置上可以靠近客户端组,同时保持整个网络的数据一致性。
PostgreSQL 复制种类
单主复制也称为单向复制,因为复制数据仅在一个方向上流动,从主副本到副本。
另一方面,多主复制数据是双向流动的,因此称为双向复制。
复制模式
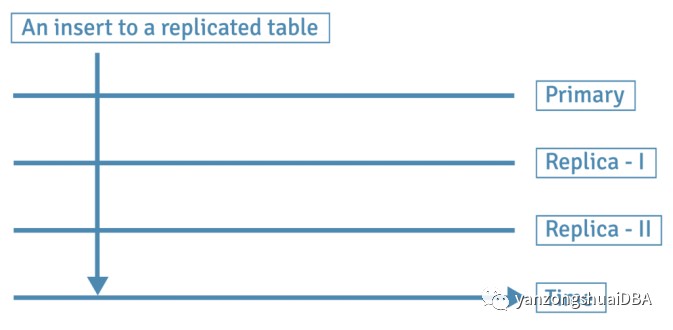
在同步模式复制中,只有当这些更改已复制到所有副本时,主数据库上的事务才被声明为完成。副本服务器必须始终可用,以便事务在主服务器上完成。
在异步模式下,当仅在主服务器上完成更改时,可以声明主服务器上的事务完成。这些更改随后会及时复制到副本中。副本服务器可以在一定时间内保持不同步,这称为复制滞后。
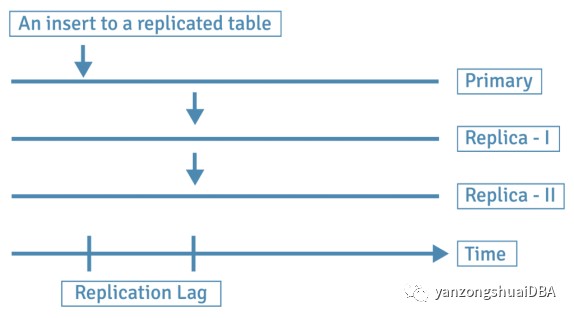
同步和异步模式都有其成本和优势,用户在配置复制设置时会希望考虑安全性和性能。
复制类型
PostgreSQL 数据库的物理复制 与 PostgreSQL 数据库的逻辑复制
在我们讨论物理和逻辑复制类型之前,让我们回顾一下术语“物理”和“逻辑”的上下文。

比如:
ramp=# create table sample_tbl(a int, b varchar(255));
CREATE TABLE
ramp=# SELECT pg_relation_filepath('sample_tbl');
pg_relation_filepath
----------------------
base/34740/706736
(1 row)
ramp=# SELECT datname, oid FROM pg_database WHERE datname = 'ramp';
datname | oid
---------+-------
ramp | 34740
(1 row)
ramp=# SELECT relname, oid FROM pg_class WHERE relname = 'sample_tbl';
relname | oid
------------+--------
sample_tbl | 706736
(1 row)
物理复制处理文件和目录。它不知道这些文件和目录代表什么。物理复制在文件系统级别或磁盘级别完成。
另一方面,逻辑复制处理数据库、表和 DML 操作。因此,在逻辑复制中可以只复制特定的一组表。逻辑复制在数据库集群级别完成。
WAL简介
什么是 PostgreSQL 中的预写日志 (WAL),为什么需要它?
在 PostgreSQL 中,事务所做的所有更改首先保存在日志文件中,然后将事务的结果发送到发起客户端。数据文件本身不会在每个事务中更改。这是在操作系统崩溃、硬件故障或 PostgreSQL 崩溃等情况下防止数据丢失的标准机制。这种机制称为预写日志(WAL),日志文件称为预写日志。
事务执行的每个更改(INSERT、UPDATE、DELETE、COMMIT)都作为WAL 记录写入日志。WAL 记录首先写入内存中的WAL 缓冲区。当事务提交时,记录被写入磁盘上的WAL 段文件中。
WAL 记录的日志序列号 (LSN)表示记录在日志文件中保存的位置/位置。LSN 用作 WAL 记录的唯一 id。从逻辑上讲,事务日志是一个大小为 2^64 字节的文件。因此,LSN 是一个 64 位数字,表示为两个用 / 分隔的 32 位十六进制数字。例如:
select pg_current_wal_lsn();
pg_current_wal_lsn
--------------------
0/2BDBBD0
(1 row)
如果发生系统崩溃,数据库可以从 WAL 中恢复已提交的事务。恢复从最后一个REDO 点或检查点开始。检查点是事务日志中的一个点,这个点之前的日志可以删除掉,因为该检查点之前的数据都已刷些到磁盘。将 WAL 记录从日志文件保存到实际数据文件的过程称为检查点。实际的工作就是刷写数据,并将检查点之前的日志删除。
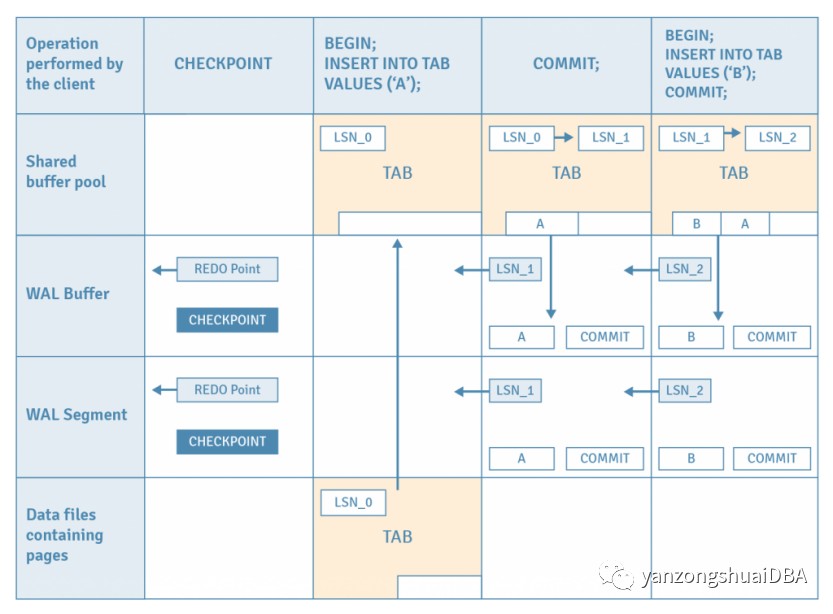
让我们考虑这样一种情况,即数据库在两个事务都执行一次插入后崩溃并且使用 WAL 进行恢复。
1) 假设已经执行一个检查点,它存储了当前 WAL 段中最新的 REDO 点的位置。这也将共享缓冲池中的所有脏页刷新到磁盘。这个动作保证了REDO点之前的 WAL 记录不再需要恢复,因为所有数据都已刷新到磁盘页面。
2) 发出第一个 INSERT 语句。表的页面从磁盘加载到缓冲池。
3) 一个元组被插入到加载的页面中。
4) 此插入的 WAL 记录保存到位置 LSN_1 的 WAL 缓冲区中。
5) 页面的 LSN 从 LSN_0 更新到 LSN_1,它标识了该页面最后一次更改的 WAL 记录。
6) 发出第一个 COMMIT 语句。
7) 这个提交动作的 WAL 记录被写入 WAL 缓冲区,然后 WAL 缓冲区中直到这个页面的 LSN 的所有 WAL 记录都被刷新到 WAL 段文件中。
8) 对于第二次 INSERT 和提交,重复步骤 2 到 7。
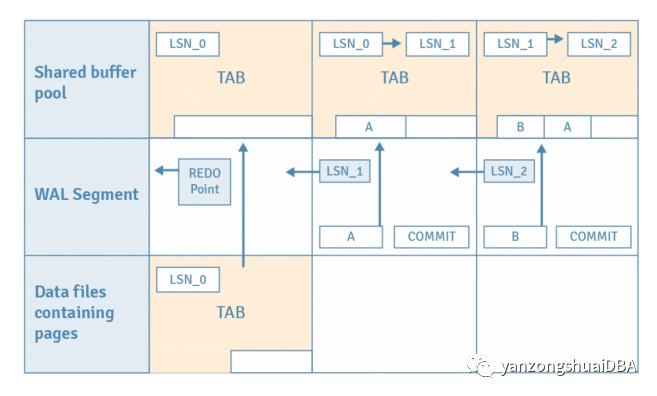
如果出现操作系统崩溃,共享缓冲池上的所有数据都会丢失。然而,对页面的所有修改都已作为历史数据写入 WAL 段文件。以下步骤展示了如何使用 WAL 记录将我们的数据库集群恢复到崩溃前的状态。没有什么特别需要做的——PostgreSQL 会在重启后自动进入恢复模式。
1) PostgreSQL 从适当的 WAL 段文件中读取第一个 INSERT 语句的 WAL 记录。
2) PostgreSQL 将表的页面从数据库集群加载到共享缓冲池中。
3) PostgreSQL 将 WAL 记录的 LSN (LSN_1) 与页面 LSN (LSN_0) 进行比较。由于 LSN_1 大于 LSN_0,因此将 WAL 记录中的元组插入到页面中,并将页面的 LSN 更新为 LSN_1。
其余的 WAL 记录以类似的方式重放。
PostgreSQL 中的事务日志和 WAL 段文件是什么?
PostgreSQL 事务日志是一个容量为 8 字节长度的虚拟文件。在物理上,日志被分成 16 MB 的文件,每个文件称为一个 WAL 段。
WAL 段文件名是一个 24 位的数字,其命名规则如下:

假设当前时间线 ID 为 0x00000001,第一个 WAL 段文件名将是:
00000001 00000000 0000000
00000001 00000000 0000001
00000001 00000000 0000002
……….
00000001 00000001 0000000
00000001 00000001 0000001
00000001 00000001 0000002
…………
00000001 FFFFFFFF FFFFFFFD
00000001 FFFFFFFF FFFFFFFE
00000001 FFFFFFFF FFFFFFFF
例如:
select pg_walfile_name('0/2BDBBD0');
pg_walfile_name
--------------------------
000000010000000000000002
PostgreSQL 中的 WAL Writer 是什么?
WAL writer 是一个后台进程,它定期检查 WAL 缓冲区并将任何未写入的 WAL 记录写入 WAL 段。WAL writer 避免了 IO 活动的爆发,而是在几乎没有 IO 活动的情况下跨越其进程。配置参数 wal_writer_delay 控制 WAL writer 刷新 WAL 的频率,默认值为 200 ms。
WAL 段文件管理
WAL段文件存放在哪里?
WAL 段文件存储在 pg_wal 子目录中。
PostgreSQL切换到新的WAL段文件的条件是什么?
PostgreSQL 在以下情况下切换到一个新的 WAL 段文件:
1) WAL 段已被填满。
2) 执行了函数 pg_switch_wal。
3) archive_mode 已启用,并且已超过设置为 archive_timeout 的时间。
在它们被switched out后,WAL文件可以被删除或回收——即,重命名并为将来重用。服务器在任何时间点保留的WAL文件的数量取决于服务器配置和服务器活动。
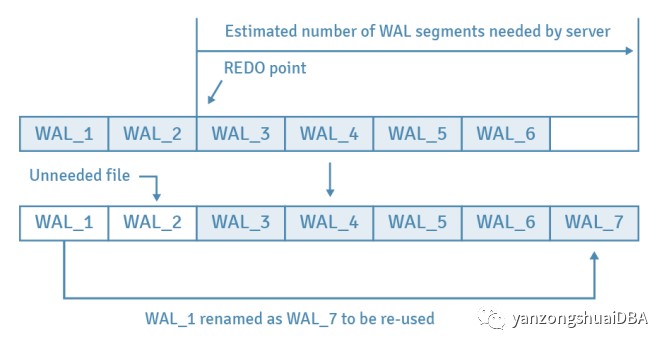
每当检查点开始时,PostgreSQL 都会估计并准备此检查点周期所需的 WAL 段文件的数量。这样的估计是基于先前检查点周期中消耗的文件数进行的。它们从包含先前 REDO 点的段开始计算,值介于 min_wal_size(默认情况下,80 MB,或 5 个文件)和 max_wal_size(1 GB,或 64 个文件)之间。如果检查点启动,必要的文件将被保存并回收,而不必要的文件将被删除。
下图中提供了一个示例。假设checkpoint开始前有6个文件,之前的REDO点包含在文件WAL_3中,PostgreSQL估计要保留5个文件。在这种情况下,WAL_1 将被重命名为 WAL_7 以便回收,而 WAL_2 将被删除。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册