自然语言处理之词向量
作者:云****院2019.09.20 04:14浏览量:2801简介:在自然语言处理里面,最细粒度的是“词语”,词语可以组成句子,句子再组成段落、篇章、文档等等。所以处理 NLP 的问题,首先就要从词语入手。词的向量表征,也称为w
在自然语言处理里面,最细粒度的是“词语”,词语可以组成句子,句子再组成段落、篇章、文档等等。所以处理 NLP 的问题,首先就要从词语入手。词的向量表征,也称为word embedding。词向量是自然语言处理中常见的一个操作,是搜索引擎、广告系统、推荐系统等互联网服务背后常见的基础技术。词向量直白讲就是把词语转化为向量形式。
在这些互联网服务里,我们经常要比较两个词或者两段文本之间的相关性。为了做这样的比较,我们往往先要把词表示成计算机适合处理的方式。最自然的方式恐怕莫过于向量空间模型(vector space model)。 在这种方式里,每个词被表示成一个实数向量(one-hot vector),其长度为字典大小,每个维度对应一个字典里的每个词,除了这个词对应维度上的值是1,其他元素都是0。
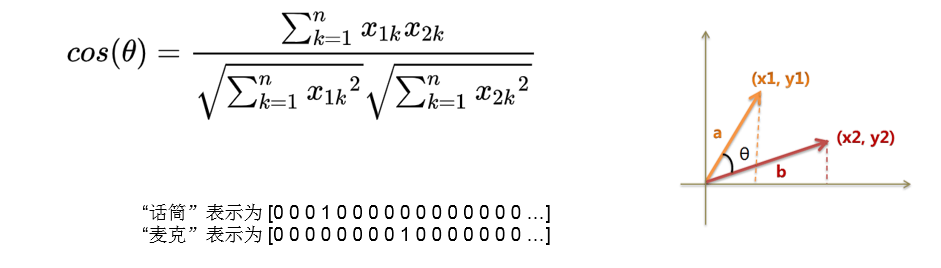
One-hot方法本质上是用一个只含一个1,其他都是 0 的向量来唯一表示词语。另一方面,我们知道两个向量的余弦值在[−1,1][−1,1]的区间内:两个完全相同的向量余弦值为1, 两个相互垂直的向量之间余弦值为0,两个方向完全相反的向量余弦值为-1,即相关性和余弦值大小成正比。One-hot方法虽然可以很方便的表示词语,但是,失去了词语间的关系信息。比如用户输入的query是“求婚”,而有一个广告的关键词是“钻戒”。虽然通常来说,这两个词之间是有联系的——送给求婚对象一枚钻戒;但是这两个词对应的one-hot vectors之间的距离度量,无论是欧氏距离还是余弦相似度,由于其向量正交,都认为这两个词毫无相关性。每个词本身的信息量都太小,无法解决数据稀疏性和维度灾难的问题。
所以,一个自然而然的解决思路是降维,将词转化为更低维度的向量,使语义关联的词更加靠近。传统的做法是统计一个词语的共生矩阵X 。X是一个|V|×|V| 大小的矩阵,Xij表示在所有语料中,词汇表V中第i个词和第j个词同时出现的词数,|V|为词汇表的大小。对X做矩阵分解(如奇异值分解,Singular Value Decomposition)得到矩阵正交矩阵U,对U进行归一化得到矩阵,即视为所有词的词向量:
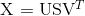
共生矩阵X中词语变得更加稠密,该矩阵具有很多良好的性质:语义相近的词在向量空间相近,甚至在一定程度反映词语之间的线性关系。
但是这种传统方法有着十分明显的缺点:
- 1) 由于很多词没有出现,导致矩阵极其稀疏,需要对词频做额外的处理以求达到更好的效果
- 2) 矩阵非常大,维度太高(通常达到106×106的数量级)
- 3) 需要手动去掉停用词(如although, a,...),不然这些频繁出现的词也会影响矩阵分解的效果。
因此要想精确计算相关性,我们还需要获取更多的信息。在机器学习领域里,各种“知识”可以被各种模型表示,词向量模型(word embedding model)就是其中的一类。基于神经网络形式表示的模型,跟共生矩阵分解模型,虽然有理论上的相通性,但是不需要计算和存储一个在全语料上统计产生的大表,而是通过学习语义信息得到词向量,因此能很好地解决以上问题。在下一篇里,我们将展示基于神经网络训练词向量的细节,以及如何用PaddlePaddle训练一个词向量模型。
【AI实战营】第三期开启招募啦!!!
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册