San 为什么会这么快
作者:百度App技术2019.09.17 03:39浏览量:3967简介:本文作者: errorrik 前言 一个 MVVM 框架的性能进化之路https://github.com/baidu/
本文作者:
errorrik
前言
一个 MVVM 框架的性能进化之路 https://github.com/baidu/san/
性能一直是 框架选型 最重要的考虑因素之一。San 从设计之初就希望不要因为自身的短板(性能、体积、兼容性等)而成为开发者为难的理由,所以我们在性能上投入了很多的关注和精力,效果至少从 benchmark 看来,还不错。 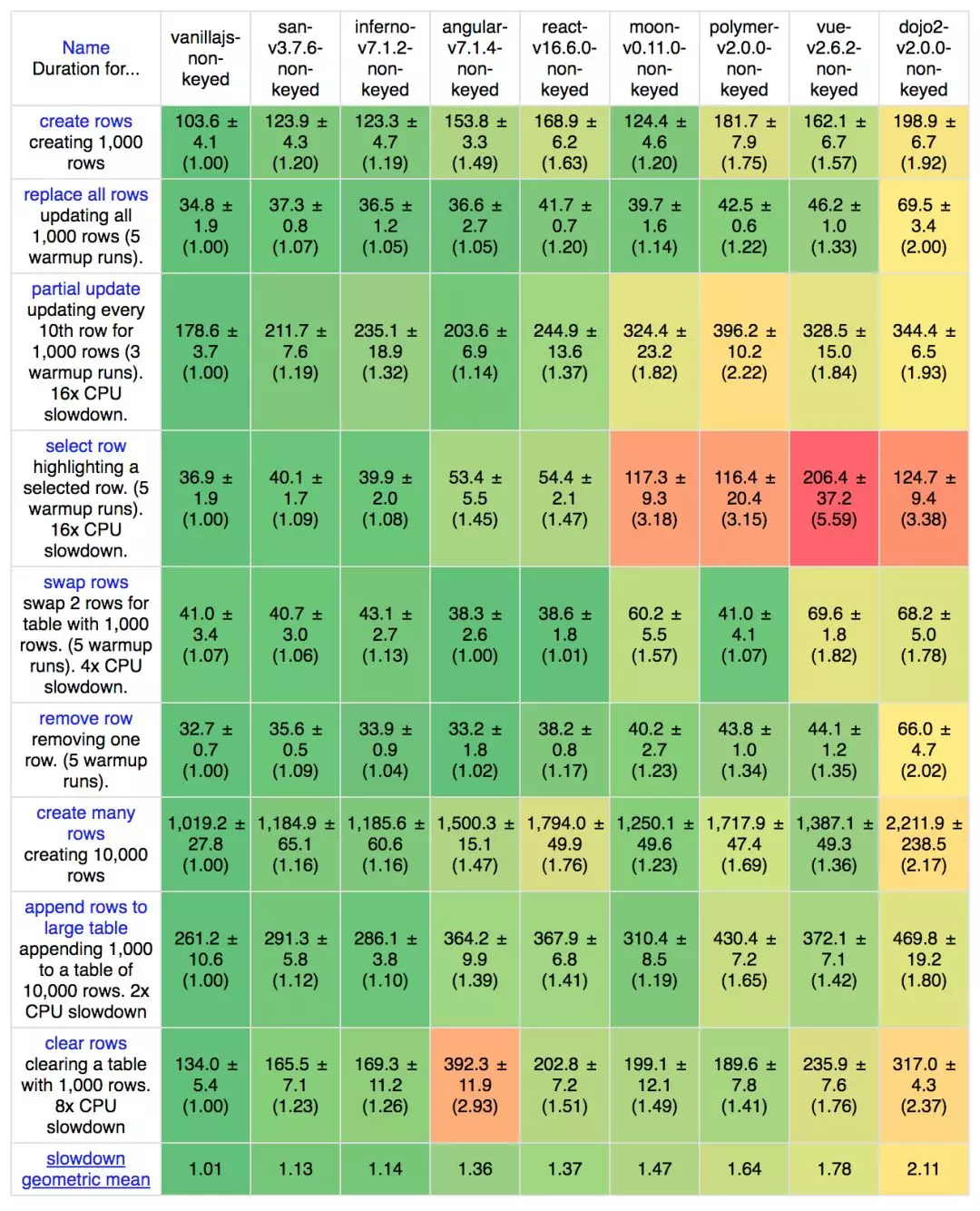
近 2 年以前,我发了一篇 San - 一个传统的MVVM组件框架。对 San 设计初衷感兴趣的同学可以翻翻。我一直觉得框架选型的时候,了解它的调性是非常关键的一点。
不过其实,大多数应用场景的框架选型中,知名度 是最主要的考虑因素,因为 知名度 意味着你可以找到更多的人探讨、可以找到更多周边、可以更容易招聘熟手或者以后自己找工作更有优势。所以本文的目的并不是将你从三大阵营(React、Vue、Angular)拉出来,而是想把 San 的性能经验分享给你。这些经验无论在应用开发,还是写一些基础的东西,都会有所帮助。
在正式开始之前,惯性先厚脸皮求下 Star。https://github.com/baidu/san/
视图创建
考虑下面这个还算简单的组件:
const MyApp = san.defineComponent({
template: `
<div>
<h3>{{title}}</h3>
<ul>
<li s-for="item,i in list">{{item}} <a on-click="removeItem(i)">x</a></li>
</ul>
<h4>Operation</h4>
<div>
Name:
<input type="text" value="{=value=}">
<button on-click="addItem">add</button>
</div>
<div>
<button on-click="reset">reset</button>
</div>
</div>
`,
initData() {
return {
title: 'List',
list: []
};
},
addItem() {
this.data.push('list', this.data.get('value'));
this.data.set('value', '');
},
removeItem(index) {
this.data.removeAt('list', index);
},
reset() {
this.data.set('list', []);
}
});在视图初次渲染完成后,San 会生成一棵这样子的树:
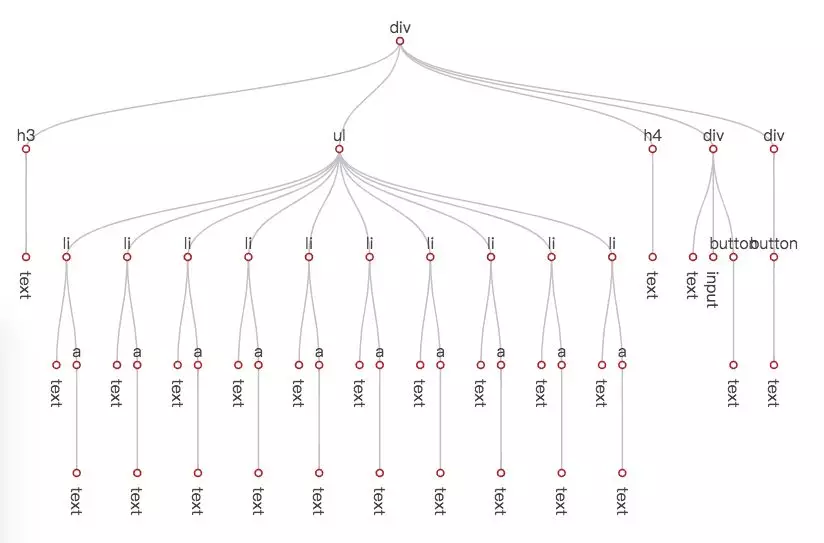
那么,在这个过程里,San 都做了哪些事情呢?
模板解析
在组件第一个实例被创建时,template 属性会被解析成 ANode。

ANode 的含义是抽象节点树,包含了模板声明的所有信息,包括标签、文本、插值、数据绑定、条件、循环、事件等信息。对每个数据引用的声明,也会解析出具体的表达式对象。
{
"directives": {},
"props": [],
"events": [],
"children": [
{
"directives": {
"for": {
"item": "item",
"value": {
"type": 4,
"paths": [
{
"type": 1,
"value": "list"
}
]
},
"index": "i",
"raw": "item,i in list"
}
},
"props": [],
"events": [],
"children": [
{
"textExpr": {
"type": 7,
"segs": [
{
"type": 5,
"expr": {
"type": 4,
"paths": [
{
"type": 1,
"value": "item"
}
]
},
"filters": [],
"raw": "item"
}
]
}
},
{
"directives": {},
"props": [],
"events": [
{
"name": "click",
"modifier": {},
"expr": {
"type": 6,
"name": {
"type": 4,
"paths": [
{
"type": 1,
"value": "removeItem"
}
]
},
"args": [
{
"type": 4,
"paths": [
{
"type": 1,
"value": "i"
}
]
}
],
"raw": "removeItem(i)"
}
}
],
"children": [
{
"textExpr": {
"type": 7,
"segs": [
{
"type": 1,
"literal": "x",
"value": "x"
}
],
"value": "x"
}
}
],
"tagName": "a"
}
],
"tagName": "li"
}
],
"tagName": "ul"
}ANode 保存着视图声明的数据引用与事件绑定信息,在视图的初次渲染与后续的视图更新中,都扮演着不可或缺的作用。
无论一个组件被创建了多少个实例,template 的解析都只会进行一次。当然,预编译是可以做的。但因为 template 是用才解析,没有被使用的组件不会解析,所以就看实际使用中值不值,有没有必要了。
preheat
在组件第一个实例被创建时,ANode 会进行一个 预热 操作。看起来, 预热 和 template解析 都是发生在第一个实例创建时,那他们有什么区别呢?
- template解析 生成的 ANode 是一个可以被 JSON stringify 的对象。
- 由于 1,所以 ANode 可以进行预编译。这种情况下,template解析 过程会被省略。而 预热 是必然会发生的。
接下来,让我们看看预热到底生成了什么?
aNode.hotspot = {
data: {},
dynamicProps: [],
xProps: [],
props: {},
sourceNode: sourceNode
};上面这个来自 preheat-a-node.js 的简单代码节选不包含细节,但是可以看出, 预热 过程生成了一个 hotspot 对象,其包含这样的一些属性:
- data - 节点数据引用的摘要信息
- dynamicProps - 节点上的动态属性
- xProps - 节点上的双向绑定属性
- props - 节点的属性索引
- sourceNode - 用于节点生成的 HTMLElement
预热 的主要目的非常简单,就是把在模板信息中就能确定的事情提前,只做一遍,避免在 渲染/更新 过程中重复去做,从而节省时间。预热 过程更多的细节见 preheat-a-node.js。在接下来的部分,对 hotspot 发挥作用的地方也会进行详细说明。
视图创建过程
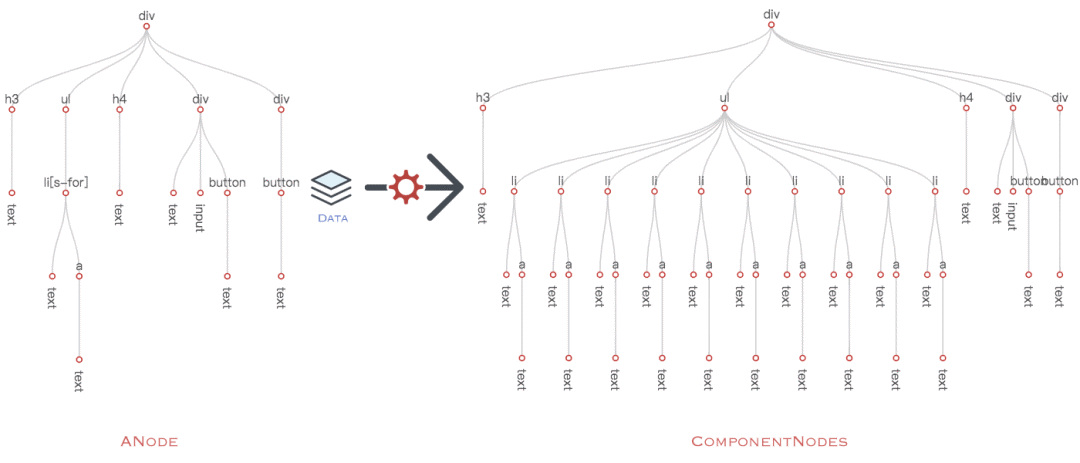
视图创建是个很常规的过程:基于初始的 数据 和 ANode,创建一棵对象树,树中的每个节点负责自身在 DOM 树上节点的操作(创建、更新、删除)行为。对一个组件框架来说,创建对象树的操作无法省略,所以这个过程一定比原始地 createElement + appendChild 慢。
因为这个过程比较常规,所以接下来不会描述整个过程,而是提一些有价值的优化点。
cloneNode
在 预热 阶段,我们根据 tagName 创建了 sourceNode。
if (isBrowser && aNode.tagName
&& !/^(template|slot|select|input|option|button)$/i.test(aNode.tagName)
) {
sourceNode = createEl(aNode.tagName);
}ANode 中包含了所有的属性声明,我们知道哪些属性是动态的,哪些属性是静态的。对于静态属性,我们可以在 预热 阶段就直接设置好。See preheat-a-node.js
each(aNode.props, function (prop, index) {
aNode.hotspot.props[prop.name] = index;
prop.handler = getPropHandler(aNode.tagName, prop.name);
// ......
if (prop.expr.value != null) {
if (sourceNode) {
prop.handler(sourceNode, prop.expr.value, prop.name, aNode);
}
}
else {
if (prop.x) {
aNode.hotspot.xProps.push(prop);
}
aNode.hotspot.dynamicProps.push(prop);
}
});在 视图创建过程 中,就可以从 sourceNode clone,并且只对动态属性进行设置。See element.js#L115-L150
var sourceNode = this.aNode.hotspot.sourceNode;
var props = this.aNode.props;
if (sourceNode) {
this.el = sourceNode.cloneNode(false);
props = this.aNode.hotspot.dynamicProps;
}
else {
this.el = createEl(this.tagName);
}
// ...
for (var i = 0, l = props.length; i < l; i++) {
var prop = props[i];
var propName = prop.name;
var value = isComponent
? evalExpr(prop.expr, this.data, this)
: evalExpr(prop.expr, this.scope, this.owner);
// ...
prop.handler(this.el, value, propName, this, prop);
// ...
}属性操作
不同属性对应 DOM 的操作方式是不同的,属性的 预热 提前保存了属性操作函数(preheat-a-node.js#L133),属性初始化或更新时就无需每次都重复获取。
prop.handler = getPropHandler(aNode.tagName, prop.name);对于 s-bind,对应的数据是 预热 阶段无法预知的,所以属性操作函数只能在具体操作时决定。See element.js#L128-L137
for (var key in this._sbindData) {
if (this._sbindData.hasOwnProperty(key)) {
getPropHandler(this.tagName, key)( // 看这里看这里
this.el,
this._sbindData[key],
key,
this
);
}
}所以,getPropHandler 函数的实现也进行了相应的结果缓存。See get-prop-handler.js
var tagPropHandlers = elementPropHandlers[tagName];
if (!tagPropHandlers) {
tagPropHandlers = elementPropHandlers[tagName] = {};
}
var propHandler = tagPropHandlers[attrName];
if (!propHandler) {
propHandler = defaultElementPropHandlers[attrName] || defaultElementPropHandler;
tagPropHandlers[attrName] = propHandler;
}
return propHandler;创建节点
视图创建过程中,San 通过 createNode 工厂方法,根据 ANode 上每个节点的信息,创建组件的每个节点。
ANode 上与节点创建相关的信息有:
- if 声明
- for 声明
- 标签名
- 文本表达式
节点类型有:
- IfNode
- ForNode
- TextNode
- Element
- Component
- SlotNode
- TemplateNode
因为每个节点都通过 createNode 方法创建,所以它的性能是极其重要的。那这个过程的实现,有哪些性能相关的考虑呢?
首先,预热 过程提前选择好 ANode 节点对应的实际类型。See preheat-a-node.js#L58 preheat-a-node.js#L170 preheat-a-node.jsL185 preheat-a-node.jsL190
在 createNode 一开始就可以直接知道对应的节点类型。See create-node.js#L24-L26
if (aNode.Clazz) {
return new aNode.Clazz(aNode, parent, scope, owner);
}另外,我们可以看到,除了 Component 之外,其他节点类型的构造函数参数签名都是 (aNode, parent, scope, owner, reverseWalker),并没有使用一个 Object 包起来,就是为了在节点创建过程避免创建无用的中间对象,浪费创建和回收的时间。
function IfNode(aNode, parent, scope, owner, reverseWalker) {}
function ForNode(aNode, parent, scope, owner, reverseWalker) {}
function TextNode(aNode, parent, scope, owner, reverseWalker) {}
function Element(aNode, parent, scope, owner, reverseWalker) {}
function SlotNode(aNode, parent, scope, owner, reverseWalker) {}
function TemplateNode(aNode, parent, scope, owner, reverseWalker) {}
function Component(options) {}而 Component 由于使用者可直接接触到,初始化参数的便利性就更重要些,所以初始化参数是一个 options 对象。
视图更新
从数据变更到遍历更新
考虑上文中展示过的组件:
const MyApp = san.defineComponent({
template: `
<div>
<h3>{{title}}</h3>
<ul>
<li s-for="item,i in list">{{item}} <a on-click="removeItem(i)">x</a></li>
</ul>
<h4>Operation</h4>
<div>
Name:
<input type="text" value="{=value=}">
<button on-click="addItem">add</button>
</div>
<div>
<button on-click="reset">reset</button>
</div>
</div>
`,
initData() {
return {
title: 'List',
list: []
};
},
addItem() {
this.data.push('list', this.data.get('value'));
this.data.set('value', '');
},
removeItem(index) {
this.data.removeAt('list', index);
},
reset() {
this.data.set('list', []);
}
});
let myApp = new MyApp();
myApp.attach(document.body);当我们更改了数据,视图就会自动刷新。
myApp.data.set('title', 'SampleList');data
我们可以很容易的发现,data 是:
- 组件上的一个属性,组件的数据状态容器
- 一个对象,提供了数据读取和操作的方法。See 数据操作文档
- Observable。每次数据的变更都会
fire,可以通过listen方法监听数据变更。See data.js
data 是变化可监听的,所以组件的视图变更就有了基础出发点。
视图更新过程
San 最初设计的时候想法很简单:模板声明包含了对数据的引用,当数据变更时可以精准地只更新需要更新的节点,性能应该是很高的。从上面组件例子的模板中,一眼就能看出,title 数据的修改,只需要更新一个节点。但是,我们如何去找到它并执行视图更新动作呢?这就是组件的视图更新机制了。其中,有几个关键的要素:
- 组件在初始化的过程中,创建了
data实例并监听其数据变化。See component.js#L255 - 视图更新是异步的。数据变化会被保存在一个数组里,在
nextTick时批量更新。See component.js#L782 - 组件是个
children属性串联的节点树,视图更新是个自上而下遍历的过程。
在节点树更新的遍历过程中,每个节点通过 _update({Array}changes) 方法接收数据变化信息,更新自身的视图,并向子节点传递数据变化信息。component.js#L688 是组件向下遍历的起始,但从最典型的 Element的_update方法 可以看得更清晰些:
- 先看自身的属性有没有需要更新的
- 然后把数据变化信息通过
children往下传递。
// 节选
Element.prototype._update = function (changes) {
// ......
// 先看自身的属性有没有需要更新的
var dynamicProps = this.aNode.hotspot.dynamicProps;
for (var i = 0, l = dynamicProps.length; i < l; i++) {
var prop = dynamicProps[i];
var propName = prop.name;
for (var j = 0, changeLen = changes.length; j < changeLen; j++) {
var change = changes[j];
if (!isDataChangeByElement(change, this, propName)
&& changeExprCompare(change.expr, prop.hintExpr, this.scope)
) {
prop.handler(this.el, evalExpr(prop.expr, this.scope, this.owner), propName, this, prop);
break;
}
}
}
// ......
// 然后把数据变化信息通过 children 往下传递
for (var i = 0, l = this.children.length; i < l; i++) {
this.children[i]._update(changes);
}
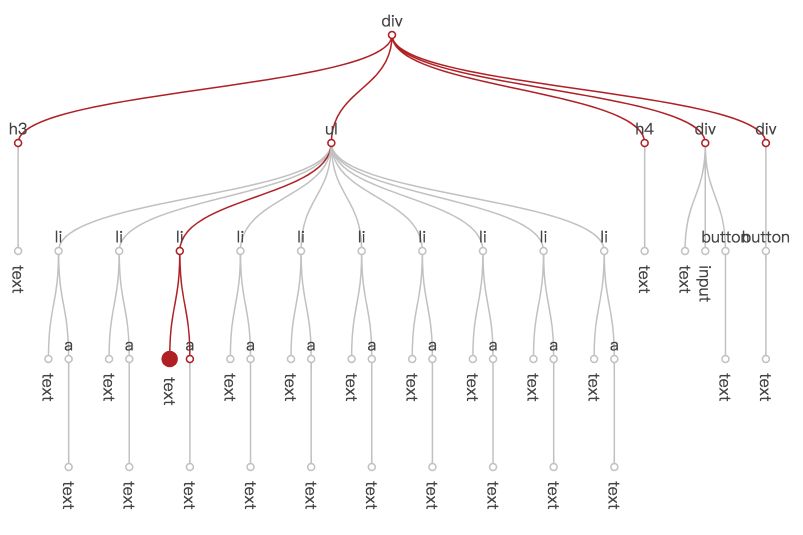
};下面这张图说明了在节点树中,this.data.set('title', 'hello') 带来的视图刷新,遍历过程与数据变化信息的传递经过了哪些节点。左侧最大的点是实际需要更新的节点,红色的线代表遍历过程经过的路径,红色的小圆点代表遍历到的节点。可以看出,虽然需要进行视图更新的节点只有一个,但所有的节点都被遍历到了。
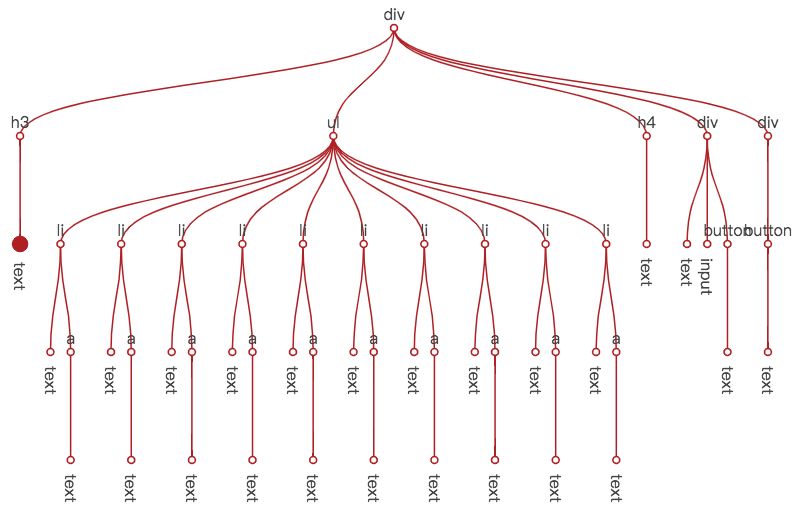
节点遍历中断
从上图中不难发现,与实际的更新行为相比,遍历确定更新节点的消耗要大得多。所以为遍历过程减负,是一个必要的事情。San 在这方面是怎么做的呢?
首先,预热 过程生成的 hotspot 对象中,有一项 data,包含了节点及其子节点对数据引用的摘要信息。See preheat-a-node.js
然后,在视图更新的节点树遍历过程中,使用 hotspot.data 与数据变化信息进行比对。结果为 false 时意味着数据的变化不会影响当前节点及其子节点的视图,就不会执行自身属性的更新,也不会继续向下遍历。遍历过程在更高层的节点被中断,节省了下层子树的遍历开销。See element.js#241 changes-is-in-data-ref.js
Element.prototype._update = function (changes) {
var dataHotspot = this.aNode.hotspot.data;
if (dataHotspot && changesIsInDataRef(changes, dataHotspot)) {
// ...
}
};有了节点遍历中断的机制,title 数据修改引起视图变更的遍历过程如下。可以看到,灰色的部分都是由于中断,无需到达的节点。
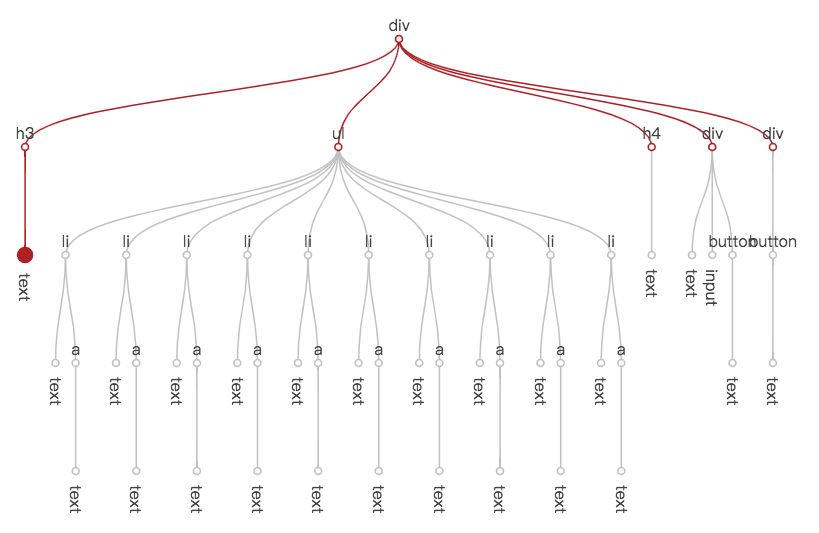
有没有似曾相识的感觉?是不是很像 React 中的 shouldComponentUpdate?不过不同的是,由于模板声明包含了对数据的引用,San 可以在框架层面自动做到这一点,组件开发者不需要人工去干这件事了。
属性更新
在视图创建过程的章节中,提到过在 预热 过程中,我们得到了:
- dynamicProps:哪些属性是动态的。See preheat-a-node.js#L117
- prop.handler:属性的设置操作函数。See preheat-a-node.jsL119
<input type="text" value="{=value=}">在上面这个例子中,dynamicProps 只包含 value,不包含 type。
所以在节点的属性更新时,我们只需要遍历 hotspot.dynamicProps,并且直接使用 prop.handler 来执行属性更新。See element.js#L259-L277
Element.prototype._update = function (changes) {
// ......
// 先看自身的属性有没有需要更新的
var dynamicProps = this.aNode.hotspot.dynamicProps;
for (var i = 0, l = dynamicProps.length; i < l; i++) {
var prop = dynamicProps[i];
var propName = prop.name;
for (var j = 0, changeLen = changes.length; j < changeLen; j++) {
var change = changes[j];
if (!isDataChangeByElement(change, this, propName)
&& changeExprCompare(change.expr, prop.hintExpr, this.scope)
) {
prop.handler(this.el, evalExpr(prop.expr, this.scope, this.owner), propName, this, prop);
break;
}
}
}
// ......
};Immutable
Immutable 在视图更新中最大的意义是,可以无脑认为 === 时,数据是没有变化的。在很多场景下,对视图是否需要更新的判断变得简单很多。否则判断的成本对应用来说是不可接受的。
但是,Immutable 可能会导致开发过程的更多成本。如果开发者不借助任何库,只使用原始的 JavaScript,一个对象的赋值会写的有些麻烦。
var obj = {
a: 1,
b: {
b1: 2,
b2: 3
},
c: 2
};
// mutable
obj.b.b1 = 5;
// immutable
obj = Object.assign({}, obj, {b: Object.assign({}, obj.b, {b1: 5})});San 的数据操作是通过 data 上的方法提供的,所以内部实现可以天然 immutable,这利于视图更新操作中的一些判断。See data.js#L209
由于视图刷新是根据数据变化信息进行的,所以判断当数据没有变化时,不产生数据变化信息就行了。See data.js#L204 for-node.jsL570 L595 L679 L731
San 期望开发者对数据操作细粒度的使用数据操作方法。否则,不熟悉 immutable 的开发者可能会碰到如下情况。
// 假设初始数据如下
/*
{
a: 1,
b: {
b1: 2,
b2: 3
}
}
*/
var b = this.data.get('b');
b.b1 = 5;
// 由于 b 对象引用不变,会导致视图不刷新
this.data.set('b', b);
// 正确做法。set 操作在 san 内部是 immutable 的
this.data.set('b.b1', 5);列表更新
列表数据操作方法
上文中我们提到,San 的视图更新机制是基于数据变化信息的。数据操作方法 提供了一系列方法,会 fire changeObj。changeObj 只有两种类型: SET 和 SPLICE。See data-change-type.js data.js#L211 data.js#L352
// SET
changeObj = {
type: DataChangeType.SET,
expr,
value,
option
};
// SPLICE
changeObj = {
type: DataChangeType.SPLICE,
expr,
index,
deleteCount,
value,
insertions,
option
};San 提供的数据操作方法里,很多是针对数组的,并且大部分与 JavaScript 原生的数组方法是一致的。从 changeObj 的类型可以容易看出,最基础的方法只有 splice 一个,其他方法都是 splice 之上的封装。
- push
- pop
- shift
- unshift
- remove
- removeAt
- splice
基于数据变化信息的视图更新机制,意味着数据操作的粒度越细越精准,视图更新的负担越小性能越高。
// bad performance
this.data.set('list[0]', {
name: 'san',
id: this.data.get('list[0].id')
});
// good performance
this.data.set('list[0].name', 'san');更新过程
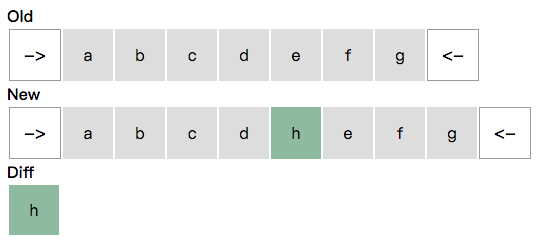
我们看个简单的例子:下图中,我们要把第一行的列表更新成第二行,需要插入绿色部分,更新黄色部分,删除红色部分。
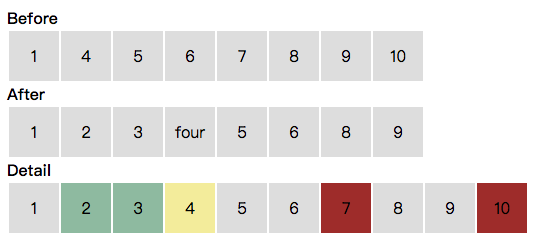
San 的 ForNode 负责列表的渲染和更新。在更新过程里:
- _update 方法接收数据变化信息后,根据类型进行分发
- _updateArray 负责处理数组类型的更新。其遍历数据变化信息,计算得到更新动作,最后执行更新行为。
假设数据变化信息为:
[
// insert [2, 3], pos 1
// update 4
// remove 7
// remove 10
]在遍历数据变化信息前,我们先初始化一个和当前 children 等长的数组:childrenChanges。其用于存储 children 里每个子节点的数据变化信息。See for-node.js#L352
同时,我们初始化一个 disposeChildren 数组,用于存储需要被删除的节点。See for-node.js#L362
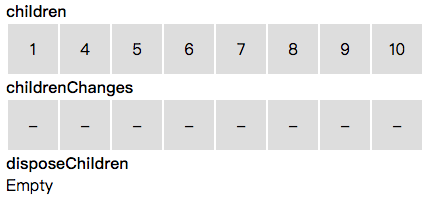
接下来,_updateArray 循环处理数据变化信息。当遇到插入时,同时扩充 children 和 childrenChanges 数组。
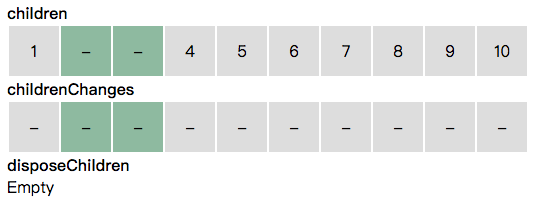
当遇到更新时,如果更新对应的是某一项,则对应该项的 childrenChanges 添加更新信息。
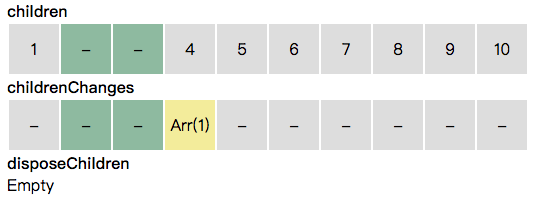
当遇到删除时,我们把要删除的子节点从 children 移除,放入 disposeChildren。同时,childrenChanges 里相应位置的项也被移除。

遍历数据变化信息结束后,执行更新行为分成两步:See for-node.js#L772-L823
- 先执行删除 disposeChildren
- 遍历 children,对标记全新的子节点执行创建与插入,对存在的节点根据 childrenChanges 相应位置的信息执行更新
this._disposeChildren(disposeChildren, function () {
doCreateAndUpdate();
});下面,我们看看常见的列表更新场景下, San 都有哪些性能优化的手段。
添加项
在遍历数据变化信息时,遇到添加项,往 children 和 childrenChanges 中填充的只是 undefined 或 0 的占位值,不初始化新节点。See for-node.js#L518-L520
var spliceArgs = [changeStart + deleteCount, 0].concat(new Array(newCount));
this.children.splice.apply(this.children, spliceArgs);
childrenChanges.splice.apply(childrenChanges, spliceArgs);由于 San 的视图是异步更新的,当前更新周期可能包含多个数据操作。如果这些数据操作中创建了一个项又删除了的话,在遍历数据变化信息过程中初始化新节点就是没有必要的浪费。所以创建节点的操作放到后面 执行更新 的阶段。
删除项
前文中提过,视图创建的过程,对于 DOM 的创建是挨个 createElement 并 appendChild 到 parentNode 中的。但是在删除的时候,我们并不需要把整棵子树上的节点都挨个删除,只需要把要删除子树的根元素从 parentNode 中 removeChild。
所以,对于 Element、TextNode、ForNode、IfNode 等节点的 dispose 方法,都包含一个隐藏参数:noDetach。当接收到的值为 true 时,节点只做必要的清除操作(移除 DOM 上挂载的事件、清理节点树的引用关系),不执行其对应 DOM 元素的删除操作。See text-node.js#L118 node-own-simple-dispose.js#L22 element.js#L211 etc...
if (!noDetach) {
removeEl(this.el);
}另外,在很多情况下,一次视图更新周期中如果有数组项的删除,是不会有对其他项的更新操作的。所以我们增加了 isOnlyDispose 变量用于记录是否只包含数组项删除操作。在 执行更新 阶段,如果该项为 true,则完成删除动作后不再遍历 children 进行子项更新。See for-node.js#L787
if (isOnlyDispose) {
return;
}
// 对相应的项进行更新
// 如果不attached则直接创建,如果存在则调用更新函数
for (var i = 0; i < newLen; i++) {
}length
数据变化(添加项、删除项等)可能会导致数组长度变化,数组长度也可能会被数据引用。
<li s-for="item, index in list">{{index + 1}}/{{list.length}} item</li>
在这种场景下,即使只添加或删除一项,整个列表视图都需要被刷新。由于子节点的更新是在 执行更新 阶段通过 _update 方法传递数据变化信息的,所以在 执行更新 前,我们根据以下两个条件,判断是否需要为子节点增加 length 变更信息。See for-node.js#L752-L767
- 数组长度是否发生变化
- 通过数据摘要判断子项视图是否依赖 length 数据。这个判断逻辑上是多余的,但是可以减少子项更新的成本
清空
首先,当数组长度为 0 时,显然整个列表项直接清空就行了,数据变化信息可以完全忽略,不需要进行多余的遍历。See for-node.js#L248-L251
其次,如果一个元素里的所有元素都是由列表项组成的,那么元素的删除可以暴力清除:通过一次 parentNode.textContent = '' 完成,无需逐项从父元素中移除。See for-node.js#L316-L332
// 代码节选
var violentClear = !this.aNode.directives.transition
&& !children
// 是否 parent 的唯一 child
&& len && parentFirstChild === this.children[0].el && parentLastChild === this.el
;
// ......
if (violentClear) {
parentEl.textContent = '';
}子项更新
想象下面这个列表数据子项的变更:
myApp.data.set('list[2]', 'two');对于 ForNode 的更新:
- 首先使用 changeExprCompare 方法判断数据变化对象与列表引用数据声明之间的关系。See change-expr-compare.js
- 如果属于子项更新,则转换成对应子项的数据变更信息,其他子项对该信息无感知。See for-node.js#L426
从上图的更新过程可以看出,子项更新的更新过程能精确处理最少的节点。数据变更时精准地更新节点是 San 的优势。
整列表变更
对于整列表变更,San 的处理原则是:尽可能重用当前存在的节点。原列表与新列表数据相比:
- 原列表项更多
- 新列表项更多
- 一样多
我们采用了如下的处理过程,保证原列表与新列表重叠部分节点执行更新操作,无需删除再创建:
- 如果原列表项更多,从尾部开始把多余的部分标记清除。See for-node.js#L717-L721
- 从起始遍历新列表。如果在旧列表长度范围内,标记更新(See for-node.js#L730-L740);如果是新列表多出的部分,标记新建(See for-node.js#L742)。
San 鼓励开发者细粒度的使用数据操作方法,但总有无法精准进行数据操作,只能直接 set 整个数组。举一个最常见的例子:数据是从服务端返回的 JSON。在这种场景下,就是 trackBy 发挥作用的时候了。
trackBy
我就是我,是颜色不一样的烟火。 -- 张国荣《我》
<ul>
<li s-for="p in persons trackBy p.name">{{p.name}} - {{p.email}}</li>
</ul>trackBy 也叫 keyed,其作用就是当列表数据 无法进行引用比较 时,告诉框架一个依据,框架就可以判断出新列表中的项是原列表中的哪一项。上文提到的:服务端返回的数据,是 无法进行引用比较 的典型例子。
这里我们不说 trackBy 的整个更新细节,只提一个优化手段。这个优化手段不是 San 独有的,而是经典的优化手段。
可以看到,我们从新老列表的头部和尾部进行分别遍历,找出新老列表头部和尾部的相同项,并把他们排除。这样剩下需要进行 trackBy 的项可能就少多了。对应到常见的视图变更场景,该优化手段都能发挥较好的作用。
- 添加:无论在什么位置添加几项,该优化都能发挥较大作用
- 删除:无论在什么位置删除几项,该优化都能发挥较大作用
- 更新部分项:头尾都有更新时,该优化无法发挥作用。也就是说,对于长度固定的列表有少量新增项时,该优化无用。不过 trackBy 过程在该场景下,性能消耗不高
- 更新全部项:trackBy 过程在该场景下,性能消耗很低
- 交换:相邻元素的交换,该优化都能发挥较大作用。交换的元素间隔越小,该优化发挥作用越大
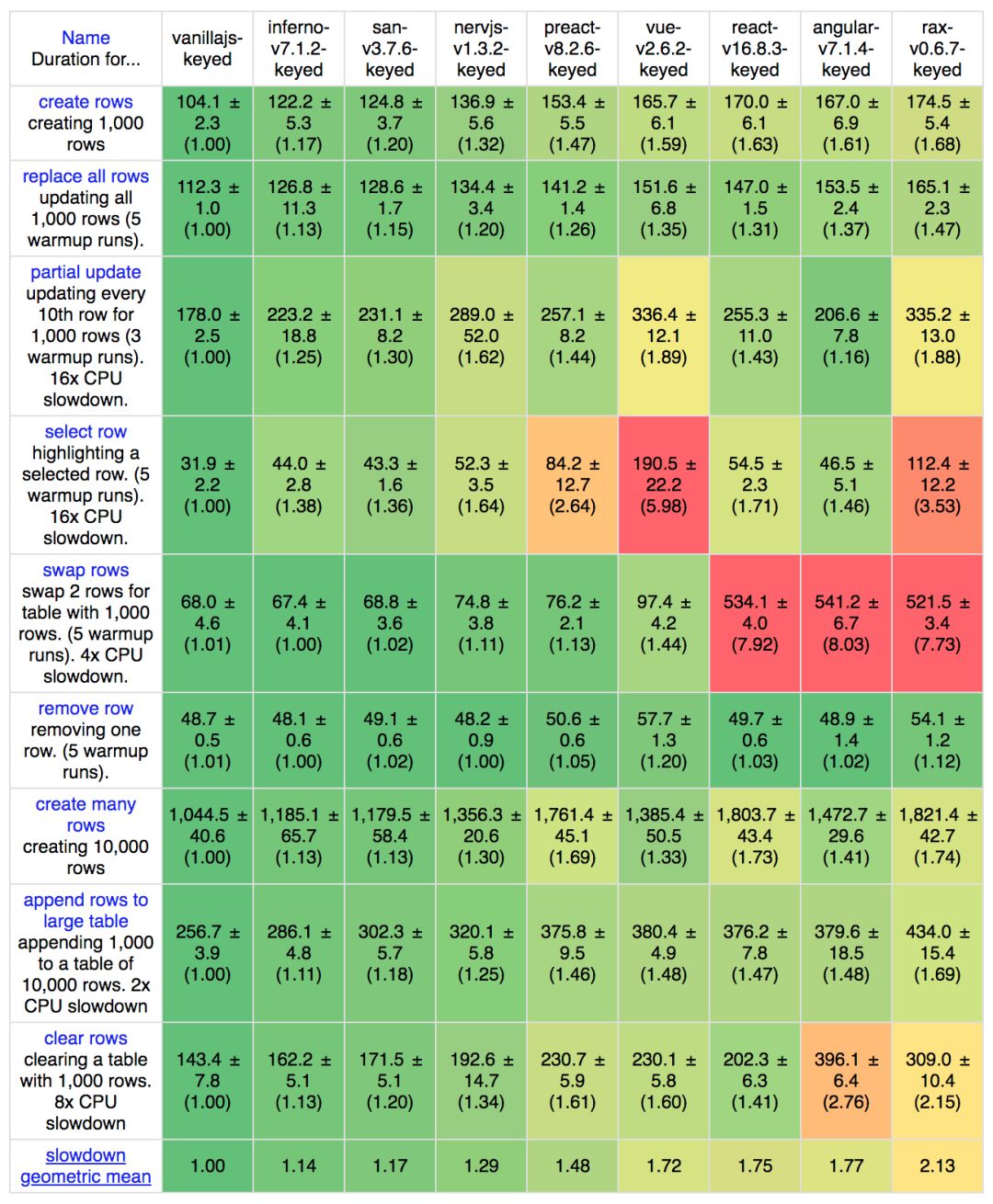
从 benchmark 的结果能看出来,San 在 trackBy 下也有较好的性能。
吹毛求疵
在这个部分,我会列举一些大多数人觉得知道、但又不会这么去做的优化写法。这些优化写法貌似对性能没什么帮助,但是积少成多,带来的性能增益还是不可忽略的。
避免 call 和 apply
call 和 apply 是 JavaScript 中的魔法,也是性能的大包袱。在 San 中,我们尽可能减少 call 和 apply 的使用。下面列两个点:
比如,对 filter 的处理中,内置的 filter 由于都是 pure function,我们明确知道运行结果不依赖 this,并且参数个数都是确定的,所以无需使用 call。See eval-expr.js#L164-L172
if (owner.filters[filterName]) {
value = owner.filters[filterName].apply(
owner,
[value].concat(evalArgs(filter.args, data, owner))
);
}
else if (DEFAULT_FILTERS[filterName]) {
value = DEFAULT_FILTERS[filterName](value);
}再比如,Component 和 Element 之间应该是继承关系,create、attach、dispose、toPhase 等方法有很多可以复用的逻辑。基于性能的考虑,实现中并没有让 Component 和 Element 发生关系。对于复用的部分:
- 复用逻辑较少的直接再写一遍(See component.js#L355)
- 复用逻辑多的,部分通过函数直接调用的形式复用(See element-get-transition.js etc...),部分通过函数挂载到 prototype 成为实例方法的形式复用(See element-own-dispose.js etc...)。场景和例子比较多,就不一一列举了。
减少中间对象
看到这里的你不知是否记得,在 创建节点 章节中,提到节点的函数签名不合并成一个数组,就是为了防止中间对象的创建。中间对象不止是创建时有开销,触发 GC 回收内存也是有开销的。在 San 的实现中,我们尽可能避免中间对象的创建。下面列两个点:
数据操作的过程,直接传递表达式层级数组,以及当前指针位置。不使用 slice 创建表达式子层级数组。See data.js#L138
function immutableSet(source, exprPaths, pathsStart, pathsLen, value, data) {
if (pathsStart >= pathsLen) {
return value;
}
// ......
}data 创建时如果传入初始数据对象,以此为准,避免 extend 使初始数据对象变成中间对象。See data.js#L23
function Data(data, parent) {
this.parent = parent;
this.raw = data || {};
this.listeners = [];
}减少函数调用
函数调用本身的开销是很小的,但是调用本身也会初始化环境对象,调用结束后环境对象也需要被回收。San 对函数调用较为频繁的地方,做了避免调用的条件判断。下面列两个点:
element 在创建子元素时,判断子元素构造器是否存在,如果存在则无需调用 createNode 函数。See element.js#L167-L169
var child = childANode.Clazz
? new childANode.Clazz(childANode, this, this.scope, this.owner)
: createNode(childANode, this, this.scope, this.owner);ANode 中对定值表达式(数字、bool、字符串字面量)的值保存在对象的 value 属性中。evalExpr 方法开始时根据 expr.value != null 返回。不过在调用频繁的场景(比如文本的拼接、表达式变化比对、等等),会提前进行一次判断,减少 evalExpr 的调用。See eval-expr.js#L203 change-expr-compare.js#L77
buf += seg.value || evalExpr(seg, data, owner);另外,还有很重要的一点:San 里虽然实现了 each 方法,但是在视图创建、视图更新、变更判断、表达式取值等关键性的过程中,还是直接使用 for 进行遍历,就是为了减少不必要的函数调用开销。See each.js eval-expr.js etc...
// bad performance
each(expr.segs.length, function (seg) {
buf += seg.value || evalExpr(seg, data, owner);
});
// good performance
for (var i = 0, l = expr.segs.length; i < l; i++) {
var seg = expr.segs[i];
buf += seg.value || evalExpr(seg, data, owner);
}减少对象遍历
使用 for...in 进行对象的遍历是非常耗时的操作,San 在视图创建、视图更新等过程中,当运行过程明确时,尽可能不使用 for...in 进行对象的遍历。一个比较容易被忽略的场景是对象的 extend,其隐藏了 for...in 遍历过程。
function extend(target, source) {
for (var key in source) {
if (source.hasOwnProperty(key)) {
var value = source[key];
if (typeof value !== 'undefined') {
target[key] = value;
}
}
}
return target;
}从一个对象创建一个大部分成员都一样的新对象时,避免使用 extend。See for-node.jsL404
// bad performance
change = extend(
extend({}, change),
{
expr: createAccessor(this.itemPaths.concat(changePaths.slice(forLen + 1)))
}
);
// good performance
change = change.type === DataChangeType.SET
? {
type: change.type,
expr: createAccessor(
this.itemPaths.concat(changePaths.slice(forLen + 1))
),
value: change.value,
option: change.option
}
: {
index: change.index,
deleteCount: change.deleteCount,
insertions: change.insertions,
type: change.type,
expr: createAccessor(
this.itemPaths.concat(changePaths.slice(forLen + 1))
),
value: change.value,
option: change.option
};将一个对象的成员赋予另一个对象时,避免使用 extend。See component.jsL113
// bad performance
extend(this, options);
// good performance
this.owner = options.owner;
this.scope = options.scope;
this.el = options.el;最后
性能对于一个框架来说,是非常重要的事情。应用开发的过程通常很少会关注框架的实现;而如果框架实现有瓶颈,应用开发工程师其实是很难解决的。开发一时爽,调优火葬场的故事,发生得太多了。
San 在性能方面做了很多工作,但是看下来,其实没有什么非常深奥难以理解的技术。我们仅仅是觉得性能很重要,并且尽可能细致的考虑和实现。因为我们不希望自己成为应用上的瓶颈,也不希望性能成为开发者在选型时犹豫的理由。
如果你看到这里,觉得 San 还算有诚意,或者觉得有收获,给个 Star 呗。
---------------------------------
在微信-搜索页面中输入“百度App技术”,即可关注微信官方账号;
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册