还记得概率课本中的二项分布吗?在我们的网络判障中发挥了大作用!
作者:沐小媛2020.06.25 07:17浏览量:6087简介:在之前的系列文章《百度网络监控实战:NetRadar横空出世》中,我们介绍了百度内网质量监测平台NetRadar的原理和架构,其中,判障算法是内网监测系统的重要
在之前的系列文章《百度网络监控实战:NetRadar横空出世》中,我们介绍了百度内网质量监测平台NetRadar的原理和架构,其中,判障算法是内网监测系统的重要一环,今天我们将详细介绍在NetRadar中实际使用的一种判障算法——基于二项分布的网络判障算法。
业务场景
我们的内网监测系统NetRadar实时对百度内网连通性进行探测并根据探测数据判断是否存在网络故障。以探测机房A到机房B的连通性为例,如下图所示,首先从机房A和B中选择n个服务器对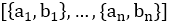 ,机房A中的服务器
,机房A中的服务器 去探测机房B中的服务器
去探测机房B中的服务器 ,每次探测有成功/失败两种结果。在每个探测周期内,我们会收到n个探测数据,其中m个数据探测成功,(n-m)个数据探测失败。
,每次探测有成功/失败两种结果。在每个探测周期内,我们会收到n个探测数据,其中m个数据探测成功,(n-m)个数据探测失败。

理论上,在网络状态正常的情况下,m/n=100%。但实际中,由于服务器自身问题(发起探测的服务器负载过高、被探测的服务器重启等)以及一些偶然因素,少量的探测失败是不可避免的,所以需要设定一个判断网络是否故障的阈值。
阈值设定
在实际设定阈值的过程中,我们遇到两个问题:
-
单服务器故障导致产生探测数据的噪声
如前面所述,当服务器a探测服务器b时,如果服务器b自身故障(负载过高或者遇到机器重装、重启等)或遇到其他偶然因素,探测也可能失败,但并不能说明此时存在网络问题,这种情况我们称为数据噪声。
虽然单台服务器故障的概率不高,但在大量服务器参与的网络探测中,服务器故障产生数据噪声几乎是常态。
-
不同探测任务样本数差距大,受噪声影响,小样本的探测任务更难进行准确判障
由于网络结构的多样性,不同探测任务的样本数差距很大。例如在机房A到机房B的探测中,样本数与机房内服务器数量相关,如果A机房内服务器数量少,则探测样本也少。实际中,不同任务的样本数变化范围从几十到几千。
对样本量大的探测任务,数据噪声对判障结果影响不大,但小样本的探测任务却非常容易受噪声影响。
例如某探测任务有100个样本,某个周期收到60条成功数据,40条失败数据,成功率只有60%,显然,此刻的网络存在故障。但如果另一个探测任务只有5个样本,在某个周期收到3个成功样本,2个失败样本,成功率同样为60%,但我们很难判断这2条数据是探测数据噪声还是真的存在网络问题,所以不能直接使用固定的阈值判断网络故障。
另外,如之前的文章《百度网络监控实战:NetRadar横空出世》所述,NetRadar的探测任务数量很大,判障算法要求是通用的、低开销的、高鲁棒性的。因此,也不能针对具体的探测任务训练专门的阈值,这样会给系统的后期维护增加很大成本。
基于二项分布的网络判障算法
在本文描述的网络判障场景中,每个探测任务每周期收到相互独立的n个成功/失败样本,其中在网络正常的情况下每次探测以一定的概率p返回成功,这正符合概率统计中二项分布的定义。
1、二项分布
首先,简单回顾一下概率统计中的二项分布。
二项分布是n个独立的伯努利试验中成功次数的离散概率分布,其中每次试验成功的概率为p。
如果随机变量X服从二项分布,那么在n次试验中,恰好得到m次成功的概率为:
其中,
累积分布函数可以表示为:

2、二项分布在判障中的应用
回到我们的场景中,对于一个探测任务来说,在一个周期内收到n个样本,其中m个成功样本,同时,根据历史数据可以确定在网络正常的情况下,一次探测成功的概率为p(由于服务器本身的问题和其他客观原因,在网络正常的情况下也有可能得到探测失败的样本,p值就是描述在网络正常的情况下探测成功的概率)。一个周期内的样本相互独立。很显然探测样本X服从参数为n和p的二项分布。
当一个周期内收到的n个样本中包含m个成功样本,如何判断此时网络是正常还是异常呢?我们实际上是通过判断m是否太小了来确定是否有网络故障。也就是,可以通过计算累积分布函数判断:

如果
过低(
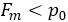
,其中
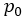 是我们预先设定的一个概率阈值),说明在正常的网络状态下,n个样本中收到小于等于m个正常样本的概率很低,可以判断这时网络是异常的。
是我们预先设定的一个概率阈值),说明在正常的网络状态下,n个样本中收到小于等于m个正常样本的概率很低,可以判断这时网络是异常的。
然而当n很大时,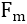
需要多次计算
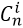 ,在每个周期有上百万数据需要计算的情况下,对CPU资源消耗很大。
,在每个周期有上百万数据需要计算的情况下,对CPU资源消耗很大。
不过根据中心极限定理,我们知道:
二项分布当n足够大时,

近似服从期望为0,方差为1的正态分布,即标准正态分布。
以此为依据,计算Z-score:
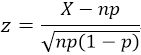
根据对历史数据的标注和训练可以得到z的阈值,使用阈值进行网络判障。
3、实际效果
实际运行中的一组网络正常和异常时成功率和Z-score分别如下图所示,可以看到,如果在成功率上设置阈值,很难找到一个较好区分网络正常和异常的阈值,但使用二项分布则可以很容易确定区分正常与异常的阈值。
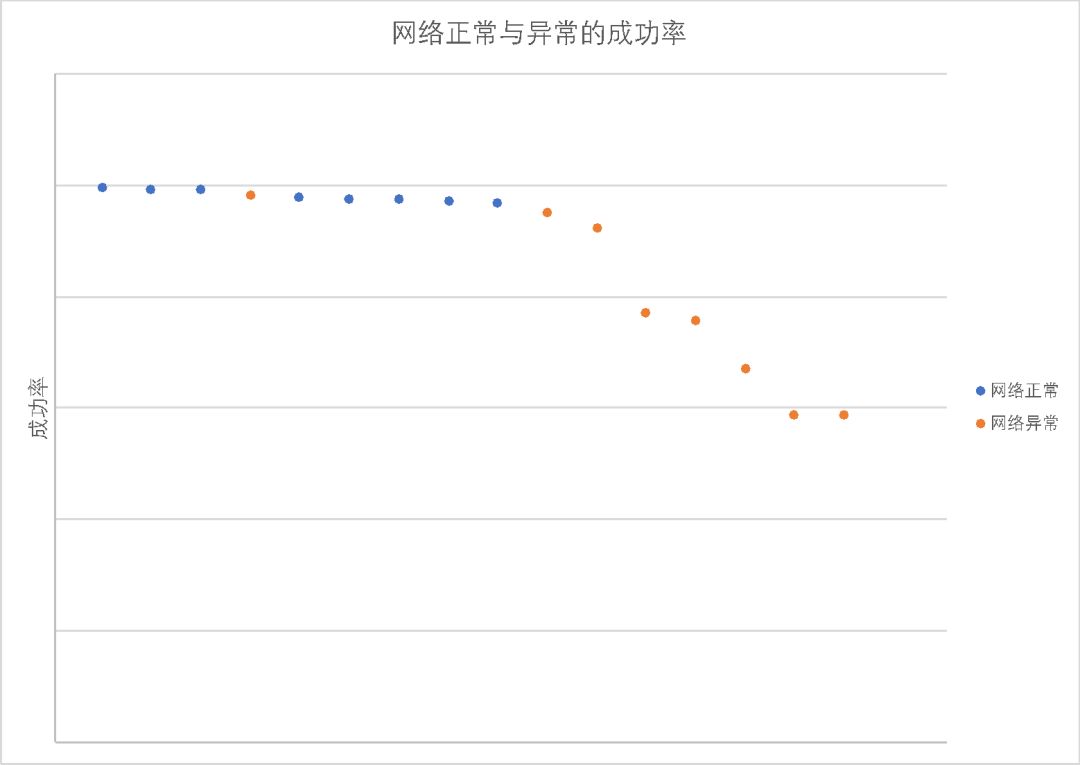

算法的扩展和应用:本文介绍的基于二项分布的判障算法,应用场景并不仅限于网络监控,实际上这个算法可以应用于所有的成功率检测,只需针对固定场景确定参数p和阈值。
总结
本文从网络监测中遇到的实际问题出发,介绍了基于二项分布的判障算法,在内网监测系统中有效地解决了不同探测任务样本数差异大且可能存在数据噪声等实际问题,尤其在小样本的判障中表现优异。
若您想进一步了解内网监测问题,欢迎给我们留言!
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册