面对海量事件数据,我来告诉你怎么办!
作者:沐小媛2019.10.27 06:28浏览量:2306简介:作者简介 运小军 百度云资深研发工程师 负责百度智能运维方向大规模日志处理、海量事件数据存储相关设计研发工作,在分
作者简介
运小军 百度云资深研发工程师
负责百度智能运维方向大规模日志处理、海量事件数据存储相关设计研发工作,在分布式系统架构、大数据存储计算、高性能网络服务和即时通讯服务有广泛实践经验。
干货概览
百度线上业务运维场景下会产生海量数据,这些数据大体可分成两类:一类是时序数据,例如:CPU、内存、磁盘、网络状态等数据,主要用于反映系统当前及历史运行状态;另一类是事件数据,例如:报警、异常、上线、变更事件,主要用于记录发生事件的详细信息。
如何存储这些海量数据,并提供灵活高效的查询分析能力,一直是我们面临的主要挑战。基于这两种不同类型数据,我们提供了两种不同存储方案:
-
TSDB作为时序数据存储平台提供了多维度时序数据存储及按维度聚合计算查询能力;
-
EventDB作为事件存储平台提供了事件/日志数据(半结构、无结构)存储、查询、统计分析功能,是百度智能运维大数据平台核心组成部分,以其海量存储能力及灵活分析能力在故障定位、故障诊断、根因分析、关联分析中发挥着不可替代的作用。
本文主要介绍EventDB系统架构、集群规划以及未来发展方向,希望跟业界同行一起交流学习。
系统架构
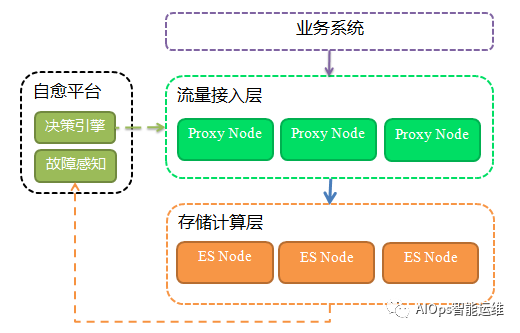
EventDB是百度智能运维团队基于ElasticSearch构建的一套海量事件数据存储计算平台,整个平台由两部分组成:流量接入层、存储计算层;通过分层将平台核心功能与辅助功能进行隔离,架构上更加便于功能扩展和维护。
流量接入层
一个高可用数据存储平台,需要流量管控能力,单机房容灾能力以及流量统计分析能力,因此我们引入了统一流量接入层,统一流量接入层基于OpenResty开发,负责接收、转发所有请求和响应,主要包括如下几个部分:
流量管控
平台通过HTTP接口对外提供服务,为了保证平台稳定性和安全性,需要对非法请求进行拒绝,对流量异常突增进行限流,以及对访问接口进行规范统一,具体提供以下几个功能:
-
流量鉴权:每个接入业务方需要申请访问Token,只有带合法Token的请求才会被允许访问,能有效防止平台被乱用;
-
配额限流:基于Token分配流量配额,当业务访问流量超过最大配额,该业务后续请求将被拒绝,主要是防止平台被超额使用以及异常流量突增造成平台不稳定;
-
统一API:对ElasticSearch提供原生API进行屏蔽封装,提供更加易用的API,降低使用成本和不规范操作带来的稳定性风险。
服务容灾
为了提升平台容灾能力,我们在存储层构建了主备集群,通过流量接入层提供的主备双写和流量快速切换能力,能达到单机房故障时对上层业务无损。
-
主备双写:对于写入请求支持自动主备双写;
-
流量切换:对于查询请求,支持自动主备切换,能根据关键指标异常快速切换查询流量到备集群,大幅降低故障恢复时间。
以上功能实现不需要业务接入方做任何特殊处理,所有处理对业务方完全透明。
流量分析
作为存储平台我们需要各种统计指标来衡量当前集群状态、流量分成、平响以及请求成功/失败率,而存储层无法提供这些指标,需要在流量接入层来实现。
-
流量统计分析:提供基于Token的流量统计、平均响应时间、成功/失败请求等指标统计。
存储计算层
作为最终事件数据存储计算引擎,我们选择使用ElasticSearch来满足海量数据存储及复杂统计分析需求,主要使用ElasticSearch如下功能:
-
海量存储:支持TB级海量数据存储;
-
查询统计:支持基于属性、关键字模糊查询等多种查询方式;
-
分布式/水平扩展:支持将数据进行分片后存储到多个节点上,并支持水平扩展;
-
数据高可用:支持数据分片副本,同一个分片可以有多个副本保存到不同节点上。
平台架构图
集群规划
作为百度智能运维大数据核心存储平台,其可用性高低直接决定了上游业务系统可用性高低,为了保证高可用性,平台需要具备有效应对不同故障场景的能力:单机故障场景下,平台依赖ElasticSearch自身容错能力,自动移除故障节点并将故障节点上的数据迁移到其他节点;单机房故障场景下,我们通过主备集群切换来最大程度保证平台可用性。
双集群
我们建立了两套ElasticSearch集群作为互备集群,由接入层负责主备双写并保证数据最终一致性。当一个集群发生故障,也是由接入层来负责查询流量切换,对终端用户而言就像使用一个集群。
-
主备双写:为了不影响写性能,我们采取同步写主集群异步写备集群的方式,主集群写入成功即代表写入成功,请求立即返回,无需等待备集群也写入成功;
-
主备一致性:上述主备双写策略会导致主备数据不一致,为了降低这种数据不一致对业务造成的影响,前期我们主要通过主备数据不一致监控来发现问题并通过工具来修复,后期我们通过程序进行备集群失败重试,重试多次依然失败的情况下会记录日志,然后程序会定期加载错误日志重试,保证主备数据最终一致性;
-
流量切换:为了降低平均故障恢复时间到达快速止损目的,平台会依据失败请求、平均响应时间等指标是否异常来判断集群是否发生故障,当连续几个决策周期都发现指标异常,会将查询流量自动切到备集群。
部署模式
单个ElasticSearch集群由如下三种不同功能节点构成:
-
Coordinator Node:协调节点,请求解析/转发,不存储数据;
-
Master Node:集群管理节点,维护集群节点信息,索引元信息;
-
Data Node:数据存储节点,处理读写请求。
该部署模式各节点职责清晰,非常便于有针对性地优化扩容:存储容量不足扩容Data Node,读写流量增长扩容Coordinator Node,Master Node只负责管理集群;这种部署模式也是ElasticSearch官方推荐的模式。
平台建设初期因为数据量和流量规模不大,我们ElasticSearch集群没有Coordinator Node,由Master Node充当Coordinator Node角色既负责整个集群的管理又负责解析转发用户的读写请求。随着数据量和访问量规模越来越大,Master Node压力越来越大,尤其是当集群中有节点重启时,因为涉及到分片再分配,整个过程耗时一个小时以上,后来调整部署模式加入Coordinator Node之后,Master Node压力骤减整个节点重启恢复耗时不到十分钟。
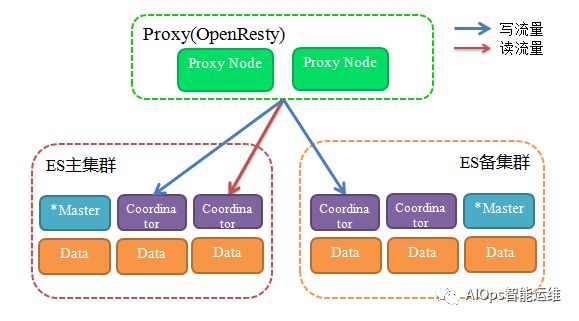
部署架构图
未来展望
当前我们主要使用ElasticSearch海量存储和简单查询功能,大部分计算分析工作是由各个业务端实现,其实ElasticSearch除了海量存储能力,其在数值聚合计算、关联查询、模糊匹配方面都有非常好的支持,未来我们期望能更进一步挖掘ElasticSearch在计算分析上的潜力,将大数据存储和分析功能进行整合形成一套统一的大数据存储分析平台,对终端用户而言只需要通过接口表达需求就能直接获得分析结果。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册