日志监控实践 | 多维度数据采集
2019.09.13 02:46浏览量:2494简介:作者简介 赵朋川 百度高级研发工程师 负责百度智能运维产品(Noah)数据采集Agent程序的设计研发工作,在运维
作者简介
赵朋川 百度高级研发工程师
负责百度智能运维产品(Noah)数据采集Agent程序的设计研发工作,在运维数据采集方向有着丰富的实践经验。
干货概览
前期文章《监控数据从哪来?(入门篇)》介绍采集程序的架构和不同场景下数据的采集方式。本文我们将针对日志监控,介绍一下多维度数据采集方面的思考和实践。
多维度数据
多维度数据目前已经成为大数据分析和处理领域的基本模型,与维度打平的单维度数据相比,多维度数据具有监控配置管理简单、处理灵活、快速的优点,多维度数据监控在百度智能运维平台中具有广泛的应用。图1为运维系统使用的一个典型多维度数据:

图1 多维度数据
-
“name”:监控项名称,监控数据的唯一标识
-
“timestamp”:数据的时间戳
-
“dimensions”:数据的维度信息
-
“value”:监控项值
日志多维度采集面临的问题
日志中保存了系统运行的大量信息,对智能运维产品来说,日志就是这个复杂系统未加工的粮食,如何准确提取和利用日志中的有用信息,就像把小麦加工成面粉甚至面包,是智能运维产品应该具备的基本能力。
百度线上业务日志种类数以万计,一些业务日志能达到每秒几十MB的生产速度,要从日志中筛选出用户关注的数据和指标,面临着几个关键问题。
-
线上日志种类多,如何实现采集的灵活配置
-
在平均每秒几十MB的日志量下,如何保证采集的效率和准确性
-
采集出来的信息怎样满足用户二次处理的需求
带着这几个问题,我们将深入到百度智能运维系统的日志多维度数据采集模块,介绍一下我们在实践中证明行之有效的方案和措施。
采集任务灵活配置
为了方便用户配置日志多维度采集任务,我们把多维度采集任务以JSON文件的形式进行配置和分发,用户可以通过Web界面填写或直接修改JSON文件的方式设置采集日志路径、采集规则以及采集项内容等信息,图2为一个典型的日志多维度采集配置示例:
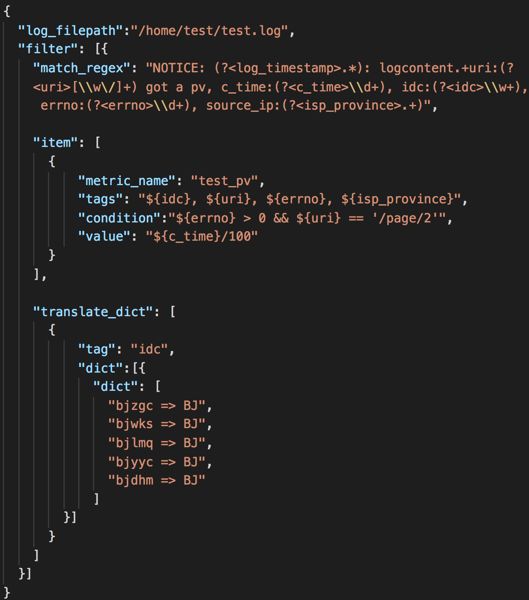
图2 多维度采集配置
-
“log_filepath”:为待采集日志的文件路径
-
“match_regex”:日志多维度采集匹配的正则表达式,采用分组命名正则
-
“item”:多维度数据信息
-
“translate_dict”:信息转换相关配置
由于日志切分的需要,目前百度线上存在许多以时间命名的日志,日志文件名称随着时间的变化而改变。对于这种情况,“log_filepath”支持配置带有时间格式符的日志路径。例如日志以天切割,日志名形如“/home/test/test.log.20190331”,则可将日志路径配置为“/home/test/test.log.`%Y%m%d`”,采集程序会实时检查日志路径的变化,确保采集最新的日志。
日志快速读取和匹配
针对日志量大的场景,为保证多维度采集的及时性和准确性,我们采用了下面几种方法处理。
-
采集程序采用多线程,充分利用机器的计算资源,一个采集任务由一个线程独立执行,提升采集效率的同时也可以保持任务的独立,避免采集过程异常情况的扩散,影响其它采集任务;
-
采集任务设定周期,对采集到的数据在周期内进行规整和聚合,并支持在配置中设定日志读取速率,对于因达到采集处理极限未能在周期内采集完的数据,生成专门的监控项来进行报警,提醒用户对采集任务进行优化调整;
-
增加前置匹配,加快日志的处理速度。在数据采集和处理过程CPU资源消耗最多的环节是正则的匹配和维度提取,为了加快匹配速度,我们增加了前置匹配功能,在前置匹配字段中可以配置简单的特征字符串或者正则表达式,对通过预处理的数据再进行多维度数据的匹配和提取,提高数据的处理速度。
采集信息的二次处理
通过命名正则从日志中提取出来的维度信息一般需要进行进一步处理才能满足计算、存储和展示的要求,我们提供了公式计算、IP转换、信息映射等手段实现对数据的二次处理,使用户能更能聚焦关心的指标和数据,也能够减少数据量及其维度,减轻下游数据计算和存储模块的压力。
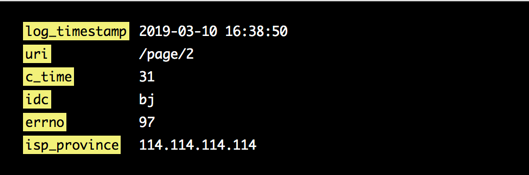
图3 多维度提取
举例说明,如图3所示,通过命名正则从日志中提取出来的6个维度,下边通过公式计算、IP地址转换、字典映射的方式对维度内容进行处理。
1公式计算
公式计算目前支持double、string、int三种数据类型,支持+、-、*、/四则运算以及<、<=、==、!=、>=、>、&&、||等逻辑运算。
如果用户只想采集uri维度为“/page/2”,c_time大于30的数据,则可通过图4公式对数据进行过滤。

图4 公式计算
2IP转换
有些线上日志中会写入请求的IP地址,我们需要根据源IP来从IP所属国家、省份、城市或者运营商的维度进行统计,为了支持这种场景,我们在采集程序内置了IP地址库和保留配置,可以将采集到的IP地址(包括IPv4和IPv6)转换成运营商、城市、省份、国家信息,同时支持四种信息任意组合的转换。
通过“isp_province”这个默认配置则可将图3中的IP地址 114.114.114.114转换成IP地址所属的运营商和身份信息,“CT”代表电信,“JIANGSU”代表江苏省,如图5所示。

图5 IP地址转换
3信息映射
对于采集到的信息,我们通过映射表的形式对字符串和数据进行进一步转换,拿机房信息为例,假如从日志中采集到的机房信息为“bjzgc”,我们需要将所有在北京的机房全部转换为“BJ”,可通过如下的映射表实现。
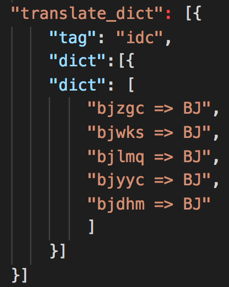
图6 映射表
通过映射表我们可以只提取关心的机房信息,不在映射表中的机房信息采集程序可以自动过滤或者默认映射为“UNKNOWN”。
4日志时间采集
为了保证采集速率,我们将采集任务设置了周期,在同一周期内的数据采用规整后的时间戳,对于那些时间精度要求高的运维场景这种处理无法满足要求,我们提供了默认配置支持从日志中提取时间作为监控数据的时间戳。
如图3所示,通过默认配置log_timestamp将日志中的时间信息“2019-03-10 16:38:50”提取出来,并转换成时间戳“1552207130”作为多维度数据的timestamp。
总 结
本文主要介绍了我们在日志多维度采集方面的实践经验,上述方案和措施可以基本满足百度内网用户对日志多维度数据的采集需求,但是在某些特殊情况下,如单纯使用正则无法采集到完整的维度信息、采集到的维度信息需要外部数据进行转化或者正则表达式特别复杂导致处理超时等情况,就需要对日志进行特殊的处理,在《日志监控实践 - 监控Agent集成Lua引擎实现多维度日志采集》文章中给出了解决方案。

发表评论
登录后可评论,请前往 登录 或 注册