知了 | 基于NLP的智能问答推荐系统
2020.01.16 18:52浏览量:2595简介:本文作者苗贝贝,百度高级研发工程师,负责百度智能运维客服平台ChatOps,在时序数据异常检测、文本模式识别、相似度网络等方向也有广泛的实践经验。 &nbs
本文作者苗贝贝,百度高级研发工程师,负责百度智能运维客服平台ChatOps,在时序数据异常检测、文本模式识别、相似度网络等方向也有广泛的实践经验。
干货概览
通常,客服系统主要有两种应答模式:机器人自动应答和人工应答。当用户提出问题后,客服系统首先启动机器人自动应答模式,如果用户认为机器人推荐的结果不准确,会进一步请求进入人工问答模式,由专门的客服人员跟进答疑。
据相关机构统计,国内客服的市场规模超过千亿,然而,目前机器人应答模式使用率并不高,人工客服仍然是企业使用率最高的应答模式,其原因主要包括两点:一方面,机器人客服系统实现准确推荐比较困难:由于自然语言本身是模糊的、问题表述方式多样、问题与答案的词汇可能存在差异等原因,导致实现准确推荐比较困难。例如:域名转出、域名怎么转出、域名转出流程等问题其实都在咨询域名转出操作;又例如,百度云虚拟主机的英文缩写为BCH,两种表述都可能被用户在提问时使用。另一方面,为机器人客服系统准备知识库比较困难。首先,为问题准备答案有比较高的技术门槛,只有具备一定经验的客服人员才能胜任。其次,客服人员一般是根据最近用户的提问来扩充整理知识库的。在这个过程中,很难知道某一问题是否在知识库中已经存在,容易导致问题的重复整理。重复整理问题不但浪费人力,还可能导致相同目标的问题在知识库中的答案不一致,降低客服质量。
基于上述背景,本文研究了一种基于自然语言理解的客服QA推荐系统,该系统目前已应用在百度云客服团队,在提升百度云用户体验、减轻客服压力等方面取得了不错的成效。
现有技术及其缺点
现有客服系统通常将一个Q(问题)A(答案)对看作一个文档,将整个知识库看作一个文档库,然后利用搜索引擎的关键词匹配技术为用户推荐相似问题以及答案。
该技术主要有以下缺点:
-
关键词匹配技术不擅长处理用户在问题表述上的差异,无法将用户问题与知识库中的QA对进行有效匹配,导致推荐结果不理想。
-
在整理知识库时,无法将目标相同的问题聚集起来统一整理,从而导致
-
整理工作量大,耗时长;
-
答案只针对单个问题,使得内容局限,质量较低;
-
相似问题分别整理,答案很容易不一致,容易导致用户困惑。
问题分析
我们发现,问题中的词汇与答案的词汇之间常常存在比较大的差异,例如:
问题:网站无法打开
答案:使用临时域名访问一下是否是用户解析或者是域名绑定的问题,访问报什么错误,常见访问报404,检查一下访问的路径或者是路径下是否有此文件。访问报502,需要客户提供下BCH控制面板-网站监控和网站访问的截图,确认下是否是内存不够用或者请求量过大导致的,如果是配置不够用,建议客户升级配置;如果是请求量过大导致,建议客户确认下是否正常,可以通过FTP的weblogs目录下的access.log日志看下是否被攻击,可以通过配置IP黑名单进行处理。
以上是百度云客服部门整理的一个真实QA对。可以看出,问题和答案在词汇上差异巨大。问题中网站无法打开,在答案中表现为用户解析有问题、域名绑定有问题、访问报404、访问报502等多种不同原因所导致的具体现象。所以,直接根据问题来查找答案很难得到理想的结果。
此外,关于网站无法打开还有如下提问方式:主机无法打开网页、官网打开不了、无法打开网页等等其他真实的Q,可以看出,知识库中的问题之间可能还存在一定的相似性。基于此特征,如果可以在查询问题时首先利用问题本身之间的相似度找到知识库中相似的问题,那么就可以通过知识库中的相似问题找到答案,此时,知识库需要建立问题与答案的映射关系。进一步地,如果可以找到具有同一目标的所有问题,就可以针对这些问题批量整理一个答案,在知识库中建立问题集与答案的映射关系。那么,当用户的问题与某个类别的问题相似时,就能根据这类相似问题集找到目标答案。客服知识库中问题集与答案的关系可以参见图1。
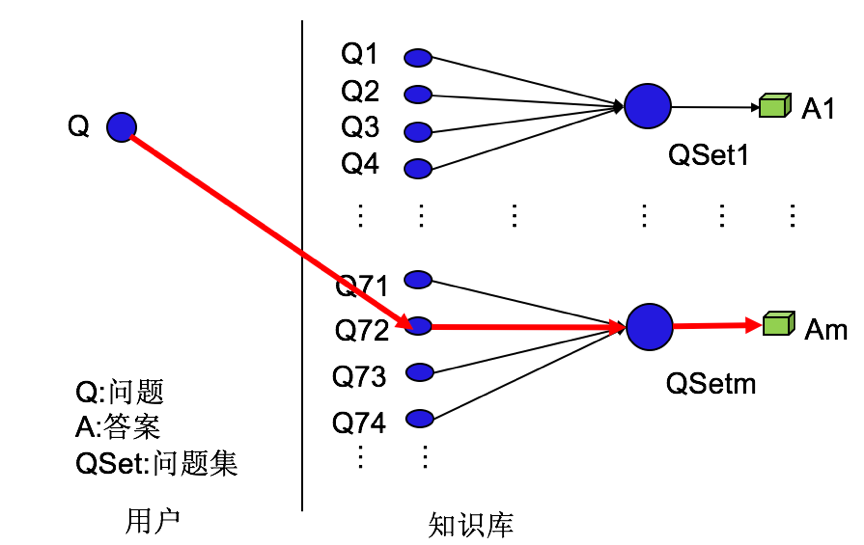
图1 客服知识库中问题集与答案映射关系
因此,客服系统主要包括两部分:知识库管理和推荐系统,其处理流程为:
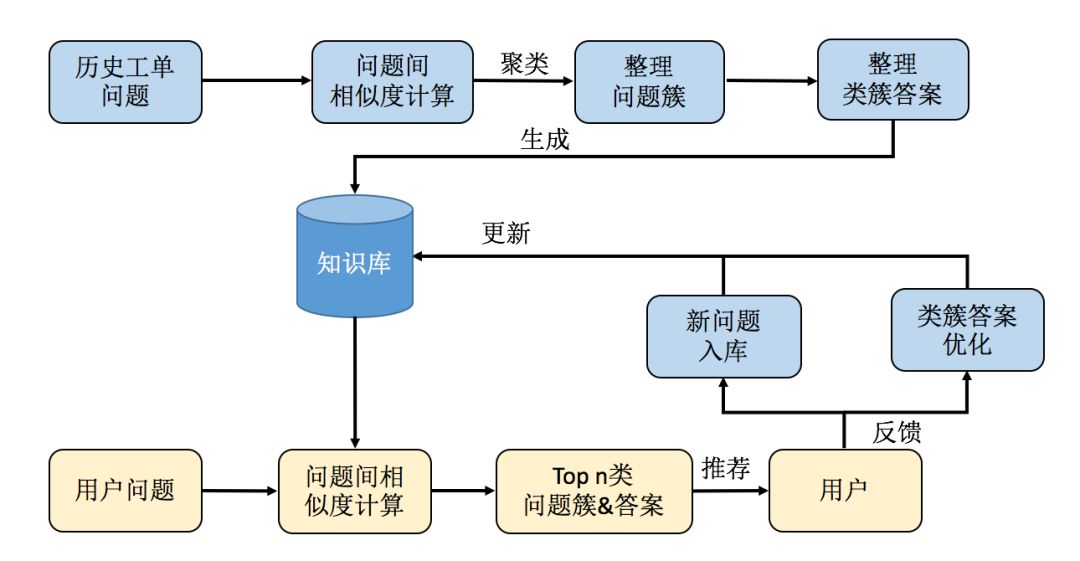
图2 知了系统数据处理流程
在图2中,蓝色的部分对应知识库管理系统,黄色的部分对应推荐系统。首先,我们利用历史工单中的问题建立一个初始知识库。推荐系统利用这个初始知识库就可以为用户提供服务。在提供服务的过程当中,推荐系统将用户反馈收集起来,并根据这些反馈更新知识库的内容,从而实现了知识库的不断进化。
智能客服系统介绍
1、知识库生成百度云客服团队拥有大量历史工单问题,为了找到具有同一目标的所有问题,可以先对历史问题进行聚类,将相似问题聚到同一类簇,再针对问题簇中的所有问题统一准备答案,建立问题簇和答案之间的联系。此时,所准备的答案能够解决类簇所代表的一整类问题。
可以采用密度聚类、层次聚类等聚类方法对大量问题进行聚类,并设置距离值为两两问题之间的相似度值。相似度值可以基于SimNet等自然语言处理方法来获取。聚类完成后,每个问题都会被归入一个类簇,然后再由客服专家对类簇进行人工检查,尝试将算法生成的类簇进一步合并。这样做是因为:对于表述不同的相似问题,例如,什么是BCC与什么是云计算服务器,由于基础语料的局限性,自然语言处理方法未必能够为它们计算出足够高的相似度,从而导致聚类算法不能将他们聚入同一类簇。所以,就需要通过专家经验将这些问题联系起来。最终,经过聚类以及人工校验,知识库中所有相似的问题都被整理到同一个类簇中,然后由客服专家针对整个类簇问题整理答案。
通过聚类操作可以辅助专家实现问题的批量整理,大大降低知识生成成本。并且,相比针对单一问题整理的答案,通过问题集编写的答案内容更充分,质量也就更好。
2、推荐系统知识库建立后,就可以用来回答用户的提问了。在用户将问题提交到系统之后,知了系统首先计算用户问题与知识库中所有问题的相似度,并选择相似度值大于某阈值(我们用query_threshold代表这个阈值)的N个问题作为候选集。然后,系统获取候选集中每个问题所属的类簇,N个候选问题一共可以得到n(n<=N)个类簇。最终,系统将这n个类簇对应的答案返回给用户。
为了持续优化推荐效果,知了系统保留了用户的查询结果并统计线上使用情况,同时还增加了标注反馈功能,用户在每次查询完毕后可以对推荐结果进行反馈。
总体来说,我们将用户的反馈结果分为三类:
-
已解决:用户认为推荐结果准确,所查询问题得到了有效解答;
-
A待更新:用户认为所推荐的答案不够准确,但在一定程度上有助于解决问题,后续对答案进行优化就能够进一步提高推荐效果;
-
Q待添加:查询结果为空,或者用户认为所推荐内容与自己的问题没有关系。这说明知识库很有可能尚未覆盖到这个用户问题,因此系统会自动把这个问题记录在案,后续通过知识库更新的流程将问题添加到知识库中。
知识库更新操作需要解决两部分问题:
-
对标注为A待更新状态的类簇答案进行优化;
-
将标注为Q待添加的新问题入库。
其中,问题 1 比较简单,通过人工方式由专家完善答案即可,而问题 2 所阐述的问题则可以通过如下描述的离线流程来处理。
首先,计算新问题与知识库中所有问题之间的相似度,获取相似度值大于一定阈值(我们用update_threshold代表这个阈值)的Top M个相似问题,这些问题分别属于m(m<=M)个类簇。需要指出的是,如果知识库中已经存在新问题所属的类簇,但因为该类簇中的所有问题与新问题的相似度都小于query_threshold,那么该类簇就不会被推荐。因此,update_threshold的值要比query_threshold小一些,以召回知识库中已存在的相似类簇。倘若人工检查确认新问题确实应当归于m个类簇的某一个,那么将新问题添加到该类簇的问题集即可。如果人工审查发现新问题不属于任何召回的类簇,则该问题疑似属于新类簇。我们将所有疑似属于新类簇的问题集中起来,采用知识库生成中描述的方法进行处理,就可以生成新的问题集&答案组合。
通过上述的知识库更新流程,我们不仅解决了新问题进入知识库的问题,还避免了对这些问题以及答案的重复整理,减少了人工开销。
总 结知了系统采用了问题集与答案的形式来管理QA知识库,这种管理形式具有以下几个优势。
首先,在用户提交了问题之后,推荐系统先匹配知识库中语义相同的问题,然后展示问题所属类簇的答案。由于一个问题类簇可以包含表述上差异很大的多个问题,匹配的准确率显著上升,并使得推荐结果对目标答案的召回率提升到90%以上。
第二,通过对问题进行自然语言分析和聚类,知了系统大大降低了问题整理的工作量。知识库整理的效率提升到原来的3倍以上。
第三,人工撰写答案时不再针对单个问题,而是综合考虑一组目标相同的问题,答案的内容更加全面,质量也更高。
最后,知了系统提供了完善的知识库进化机制,保证了知识库能够紧密跟随用户需求与知识的变化,从而避免了推荐效果的退化。
温馨提示
如果你喜欢本文,请分享到朋友圈,想要获得更多信息,请关注我们!
如果你有任何问题欢迎留言咨询~
如果想试用我们的企业级运维平台NoahEE,请联系邮箱:noah_bd@baidu.com

发表评论
登录后可评论,请前往 登录 或 注册