VGG、ResNet、GoogleNet网络理论
作者:馬立2020.06.25 07:17浏览量:8421简介:本篇文章讲述三个经典的CNN结构,分别是VGG、GoogLeNet、ResNet。通过讲解原理,希望大家掌握三种网络
分享嘉宾:白浩杰
文章整理:马立辉
内容来源:百度教育合作与共建
导读:
计算机视觉领域涉及许多不同任务,对于图像分类任务,人类一直在追求更高的分类精度,期间衍生了许多有代表性的经典网络结构,今天就来做个探讨。
本篇文章主要包含以下内容:
1.计算机视觉任务
2 图像分类应用案例
3.经典网络结构
1.计算机视觉任务
计算机视觉通常涉及以下几个任务:图像分类、目标检测、语义分割/实例分割、场景文字识别、图像生成、人体关键点检测、视频分类、度量学习。相对而言,前四个任务已经有比较成熟的技术,工业应用比较广泛。
① 图像分类
图像分类任务,需要根据在图像信息中所反映的不同特征,把不同类别的目标区分开来。例如,在给定的不同图片中,分类任务需要能够把图片主体识别出来,如给定下面两张图,经过图像分类程序的识别,能够识别出图1是猫,图2是狗。

图1

图2
② 目标检测
目标检测任务不仅仅要识别图片主体,还要把主体所在的位置用最小包围矩形进行标记。如图3,图中的主体是一位小朋友和他手中拿的小锤子,通过目标检测,把主体所在的位置用最小包围矩形标记了出来。

图3
③ 语义分割/实例分割
语义分割是指我们按照像素级别的精度,把图片的每一个像素属于哪一个类别标注出来。比如图4(c),黄色区域归于背景,蓝色归于瓶子。
实例分割相比语义分割更加复杂,不仅要求把哪一个像素属于哪一个类别标注出来,还要求把每一个像素属于哪一个物体标注出来。
在下图所示的四个视觉任务中,图像分类任务是所有视觉任务的基础,在完成图像分类任务后就可以进行目标检测任务,目标检测任务掌握后即可研究语义分割任务以及实例分割任务。
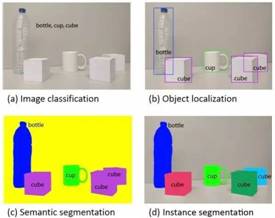
图4
④ 场景文字识别
场景文字识别通常称为OCR(光学字符识别),是在图像背景复杂、分辨率低下、字体多样、分布随意等情况下,将图像信息转化为文字序列的过程,可认为是一种特别的翻译过程:将图像输入翻译为自然语言输出。

图 5 场景文字识别示例
⑤ 图像生成
图像生成是指根据用户的输入,生成一张非常逼真的目标图像。如图6,输入一张街景照片,通过图像生成任务,生成一张和输入图像相似度很高的图像。
图 6图像生成示例
⑥ 人体关键点检测
人体关键点检测是指输入一张人体图片,计算机能够识别出人体的关键点并且标注(如图7)。

图 7人体关键点检测
⑦ 视频分类
视频分类任务就是对由一帧一帧图片组成的视频进行分类,把每一帧图像输入到神经网络当中,最终输出该视频所属的类别(如图8)。

图 8视频分类任务
⑧ 度量学习
度量学习的对象通常是样本特征向量的距离,度量学习的目的是通过训练和学习,减小或限制同类样本之间的距离,同时增大不同类别样本之间的距离。
比如在人脸识别领域经常会用到度量学习。

图 9度量学习
2.图像分类应用案例
我们以百度AI开放平台的图像识别模块为例。
当输入一张蒲公英的图片,通过平台API中的图像识别模块,最终会在图像右上角输出这张图片不同的识别结果。观察这些结果,发现属于蒲公英的概率最高,据此可判断这张图片是蒲公英。

图 10蒲公英图片识别
该平台的图像识别模块是怎么工作的呢?其实当我们把图片上传之后,后台通过图像分类算法预测出结果,并且以JSON格式把结果返回(如图11)。
后台会返回前五条概率最高的结果,开发人员也可以据此进行后续的再利用。

图 11识别返回结果
3.经典网络结构
近几年,通过技术人员的不断努力,图像分类(图像识别)技术的准确率不断提高,甚至已经超过了人类。
提到图像分类,自然会联想到ImageNet大赛。
ImageNet大赛对计算机视觉领域的发展起了巨大的推动作用。在比赛中,举办方提供了优质的数据集,每位参赛的技术开发者,把自己的算法应用到该数据集上,以竞赛的形式角逐各奖项。
通过一个柱状图(图12)直观体验一下ImageNet大赛的top-5错误率。在2010、2011年,大部分的参赛者普遍选择使用浅层的神经网络来进行比赛,其错误率分别是28.2%和25.8%;在2012年的ImageNet大赛中,第一次使用深度学习来解决图像分类任务,提出了AlexNet神经网络。AlexNet神经网络一共有8层,该网络的出现,使得ImageNet大赛整体的错误率从2011年的25.8%降低到2012年的16.4%;2013年同样提出了一个8层的神经网络,但是其错误率下降为11.7%;2014年提出VGG神经网络以及GoogleNet神经网络,其错误率分别是7.3%和6.7%,但是其网络结构已经从2012年的8层分别增长为现在的19层和22层;在2015年的ImageNet大赛上,提出的ResNet神经网络,错误率下降为3.57%,但是其网络结构已经达到了152层。

图 12ImageNet大赛错误率
在相同的数据集上,人类的错误率是5.1%,而在2015年提出的ResNet神经网络结构,其错误率已经远远低于人类。也就是说2015年ResNet网络的提出,已经让计算机在图像识别任务上超越了人类。
我们一起来讨论下VGG、GoogleNet、ResNet的网络结构。
①VGG网络
在ImageNet大赛中,VGG网络的表现非常出色,它在神经网络的深度方面进行了很好的探索。VGG完全沿用了卷积加池化堆叠的设计思路(如图13)。
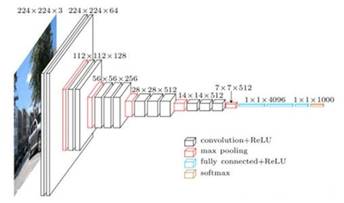
图 13 VGG网络结构
和AlexNet网络结构相比,VGG和AlexNet一样都是对卷积池化操作的堆叠。但两者最大的区别是卷积池化的层数不同,无论是VGG16还是VGG19,其卷积池化的层数要远远高于AlexNet网络。
VGG网络给我们呈现了图片在经过不停卷积池化时会发生什么。在学习过程中,VGG网络是一个非常好的教学材料。
在VGG论文中,实现了6个由浅到深的VGG网络结构(如图14),分别是A、A-LRN、B、C、D、E。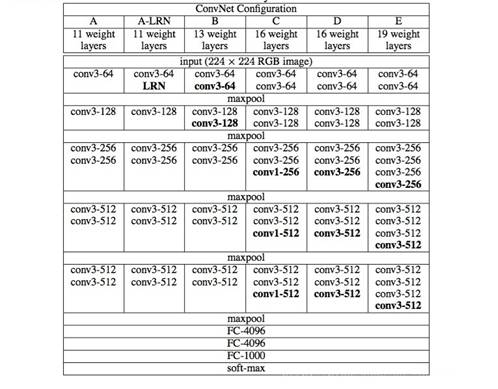
图 14VGG网络结构
VGG主要由输入层、卷积层、池化层以及全连接层组成。对应的输入是224×224彩色图像
- 卷积层:卷积核大小为3×3,步长设置为1,填充(padding)设置为1,并且所有隐藏层都使用ReLu作为激活函数。
- 池化层:六个VGG网络全部使用了5层的最大池化(maxpool),5层池化层正好把VGG网络划分成五段。每经过一次池化,图片面积变为原来的四分之一。每个池化层的池化核大小是2×2,步长为2,填充设置为0。
- 全连接层:VGG网络最后是三个全连接层,其中前两个全连接层均有4096个通道,第三个全连接层有1000个通道。
VGG网络中的A结构和AlexNet一样,具有8层卷积,但是其效果不如深度更深的网络。经过探索,发现16层和19层的结构效果是比较好的。所以我们现在使用最多的是VGG16和VGG19。这好像给我们一个感觉:深度越深效果越好。因为16层或者19层确实比8层的网络效果好。但真是这样吗?
②GoogLeNet网络
GoogLeNet是2014年ImageNet比赛的冠军,它的主要特点是网络不仅有深度,还在横向上具有“宽度”。由于图像信息在空间尺寸上的巨大差异,如何选择合适的卷积核大小来提取特征就显得比较困难了。空间分布范围更广的图像信息适合用较大的卷积核来提取其特征,而空间分布范围较小的图像信息则适合用较小的卷积核来提取其特征。为了解决这个问题,GoogLeNet提出了一种被称为Inception模块的方案。
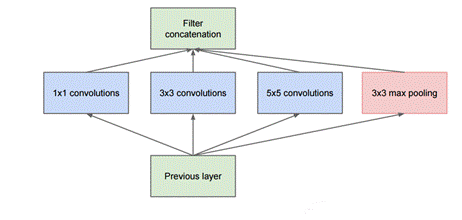
图 15原始的Inception
图15是Inception模块的原始设计思想,使用3个不同大小的卷积核对输入图片进行卷积操作,并附加最大池化,将这4个操作的输出沿着通道这一维度进行拼接,构成的输出特征图将会包含经过不同大小的卷积核提取出来的特征。Inception模块采用多通路(multi-path)的设计形式,每个支路使用不同大小的卷积核,最终输出特征图的通道数是每个支路输出通道数的总和,这将会导致输出通道数变得很大,尤其是使用多个Inception模块串联操作的时候,模型参数量会变得非常巨大。为了减小参数量,Inception模块使用了图16中的设计方式,在每个3x3和5x5的卷积层之前,增加1x1的卷积层来控制输出通道数;在最大池化层后面增加1x1卷积层减小输出通道数。基于这一设计思想,形成了上图16中所示的结构。
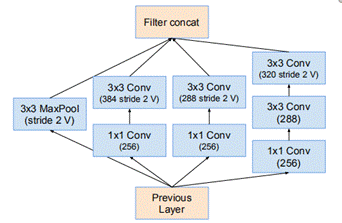
图 16Inception V1
1×1的卷积核是如何工作的?
1×1卷积的主要目的是为了减少维度,还用于提高非线性(例如ReLU)。为什么通过1×1的卷积后维度会下降呢?通过一个例子感受一下。
举个例子:
比如上一层的输入为100×100×128,经过具有256个通道的5×5卷基层之后(Stride=1,pad=2),输出数据为100×100×256,其中卷积层参数为128×5×5×256=819200。
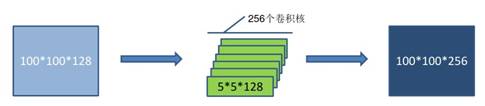
图 17
而假如上一层输出先经过具有32个通道的1×1卷积层,再经过具有256个输出的5×5卷积层,那么输出数据仍为100×100×256,但卷积参数已经减少为(128×1×1×32)+(32×5×5×256)=204800,其参数数量大约变为上面参数的四分之一。

图 18
以上是GoogLeNet的结构,和VGG网络相比,除了要在网络深度方向进行探索外,同时在网络宽度方向做了探索。
③ResNet网络
ResNet要解决什么问题?
首先通过一个图表来回顾一下深度学习网络的发展历程。
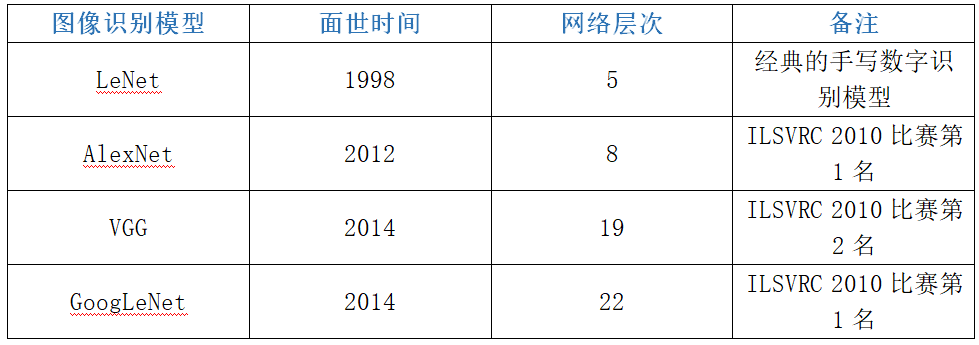
图表 1
通过观察发现,网络越深,“特征”的等级也就越高,也就越能解决更加抽象复杂的问题。然而,我们要思考一个问题,为什么网络深度到22层就没有再继续往更深的网络探索?为什么不设计一个32层、78层的网络呢?
有人做过一个有趣的实验,如果单纯的堆叠更深的网络(比如不断的加深VGG)会怎样?通过图19我们直观的感受一下。
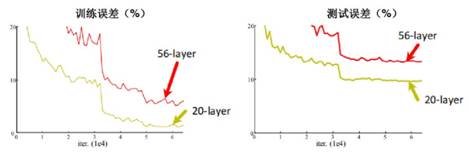
图 19训练效果
在训练误差比较中,20层网络的误差率低于56层网络的误差率;在测试误差比较中,20层网络的误差率比56层的误差率低,也就是20层网络的测试效果优于56层网络的测试效果。
通过这个实验,大家应该能够发现,其训练结果并不是一定随着卷积层数的增多而越来越好的。出现这种现象的原因是什么?原因就是网络深度超过20层之后就会出现网络难以训练的问题。而出现这种现象的根本原因就是梯度消失和梯度爆炸。整个深度学习是建立在反向传播算法之上的,而反向传播天然的缺陷就是梯度消失于梯度爆炸。为了解决这个弊端,科学家提出了ResNet网络。
ResNet如何解决这个弊端?
科学家通过研究,加入Shortcut的连接方式就可以解决。
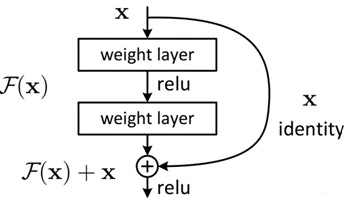
图 20 Shortcut连接
通过图20,可以看到X是这一层残差块的输入,F(X)是经过第一层线性变化并激活后的输出,在第二层进行线性变化之后激活之前,F(x)加入了这一层输入值X,然后再进行激活后输出。在第二层输出值激活前加入X,这条路径称作shortcut连接。
ResNet克服梯度消失的数学解释如下图21:

图 21 ResNet数学解释
通过图21我们可以观察到ResNet网络结构把链式法则连乘的问题变成了连加,而且有一个信号能够一直跳过N多个Shorcut结构而不衰减,使得我们并不会因为反向传播而衰减信息。
总结
本篇文章梳理了计算机视觉领域的不同任务,并针对图像分类(识别),和大家一起探讨了三个经典CNN结构。限于文章篇幅,有一些细节未做深入讨论,期待大家后续不断发掘。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册