探秘计算机视觉中的注意力机制
作者:云****院2020.08.05 22:41浏览量:2718简介:近年来,越来越多的工作专注于将注意力机制融入计算机视觉任务中。本文重点介绍注意力机制的基本原理和利用飞桨实现注意力机制的基本方法。
近年来,越来越多的工作专注于将注意力机制融入计算机视觉任务中。本文重点介绍注意力机制的基本原理和利用飞桨实现注意力机制的基本方法。
注意力机制大多数手段采用掩码进行实现。掩码往往指使用一层全新的注意力机制权重,将特征数据中每个部分的关键程度表示出来,并加以学习训练。从通俗的意义上解释,注意力机制的本质是利用相关特征图进行学习的权重,再将学习的权重施加在原特征图上进行加权求和,进而得到增强的特征。 一般来说,加权的过程可以分为soft attention和hard attention,前者保留所有权重分量进行加权求和,后者根据一定的策略选择性保留权重,因为不可微的特性,一般采用强化学习的方法进行学习。 根据注意力域的不同,可以将CV中的注意力机制分为三类,分别为:空间域(spatial domain),通道域(channel domain),混合域(mixed domain)。- 空间域:将图片中的空间域信息做对应的空间变换,从而将关键的信息提取出来。对空间进行掩码的生成和打分,代表作是Spatial Attention Module。
- 通道域:类似于给每个通道上的信号都增加一个权重,来代表该通道与关键信息的相关度,权重越大,表示相关度越高。对通道生成掩码mask并进行打分,代表作是SENet、Channel Attention Module。
- 混合域:空间域的注意力是忽略了通道域中的信息,将每个通道中的图片特征同等处理,这种做法会将空间域变换方法局限在原始图片特征提取阶段,应用在神经网络层其他层的可解释性不强。代表作是:BAM、CBAM。
SENet
压缩-激励网络(Squeeze-and-Excitation Networks, SENet),拿到了ImageNet2017分类比赛冠军,其效果得到了认可,其提出的压缩-激励模块,思想简单,易于实现,并且很容易加载到现有的网络模型框架中。SENet主要是学习卷积过程中通道之间的相关性,筛选出基于通道的注意力,虽然稍微增加了一点计算量,但是效果比较好。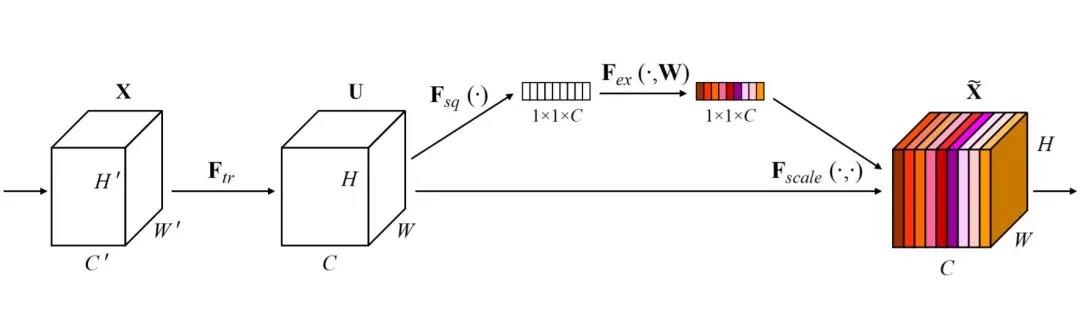
上图展示了一个压缩-激励模块的实现过程,通过对卷积得到的特征图进行处理,得到一个和通道数一样的一维向量作为每个通道的评价分数,然后将该分数分别施加到对应的通道上,得到其结果,相当于在原有的基础上只添加了一个模块。其详细过程可分为三个阶段:压缩、激励、特征重标定。 设输入特征图为。在压缩阶段,对的特征图进行全局平均池化:
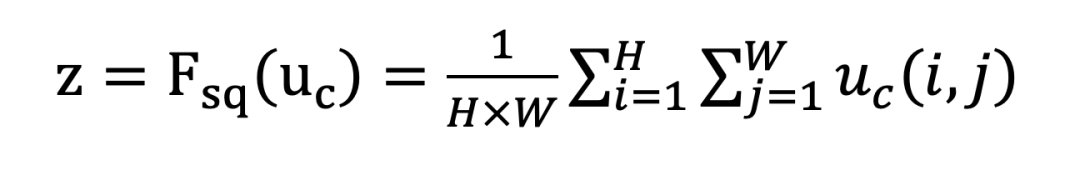 得到1 ×1 ×C大小的特征图,该特征图可理解为具有全局感受野。在激励阶段,首先使用W1和z进行一个全连接操作,W1的维度是C / r × C。r为一个放缩参数,目的为减少通道个数从而降低计算量。W1z的结果为1 × 1 × C / r,随后加一个ReLU层,然后和W2经过一个全连接层,W2维度为C × C / r,因此输出维度为1 ×1 ×C。最后再经过Sigmoid函数,得到S,即:
得到1 ×1 ×C大小的特征图,该特征图可理解为具有全局感受野。在激励阶段,首先使用W1和z进行一个全连接操作,W1的维度是C / r × C。r为一个放缩参数,目的为减少通道个数从而降低计算量。W1z的结果为1 × 1 × C / r,随后加一个ReLU层,然后和W2经过一个全连接层,W2维度为C × C / r,因此输出维度为1 ×1 ×C。最后再经过Sigmoid函数,得到S,即:
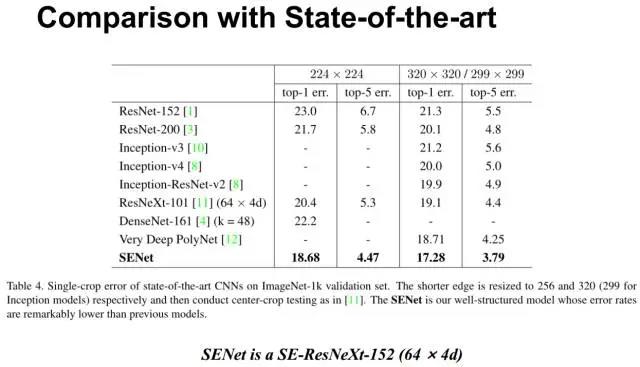
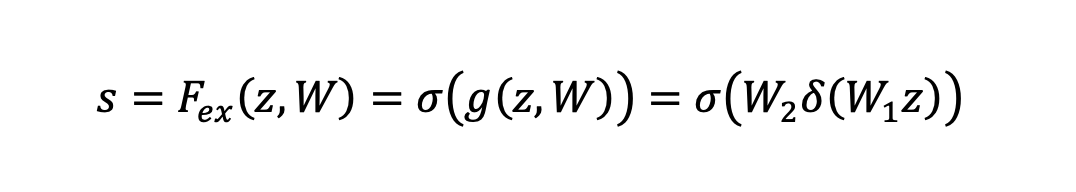 在特征重标定阶段,使用激励阶段得到的结果作为通道注意力权重,乘到输入特征上。 压缩-激励模块一般放在一个卷积模块之后,作为一个信息改善的手段,在前人的实验中已证明了其有效性。SE模块可以嵌入到几乎所有的网络结构中,通过在经典backbone的block中嵌入SE模块,我们可以得到各式各样的SENet,诸如SE-BN-Inception、SE-ResNet 、SE-ReNeXt、SE-Inception-ResNet-v2等等。 上图为原论文所列的一些在ImageNet分类上的网络的结果对比,其中的SENet使用的是SE-ResNeXt-152(64x4d),即在ResNeXt-152上嵌入SE模块,并做了一些相应的修改和优化。该网络取得了当时single-crop上最好的性能。 最近的一些研究并不单单把Squeeze-and-Excitation局限在图片分类上,也会尝试将其应用在一些不同任务的中间特征图上,以提升不同通道特征的信息利用。 一个Squeeze-and-Excitation函数的飞桨实现 (https://github.com/c8241998/CV_attention/blob/master/SEnet/senet-paddle.py):
在特征重标定阶段,使用激励阶段得到的结果作为通道注意力权重,乘到输入特征上。 压缩-激励模块一般放在一个卷积模块之后,作为一个信息改善的手段,在前人的实验中已证明了其有效性。SE模块可以嵌入到几乎所有的网络结构中,通过在经典backbone的block中嵌入SE模块,我们可以得到各式各样的SENet,诸如SE-BN-Inception、SE-ResNet 、SE-ReNeXt、SE-Inception-ResNet-v2等等。 上图为原论文所列的一些在ImageNet分类上的网络的结果对比,其中的SENet使用的是SE-ResNeXt-152(64x4d),即在ResNeXt-152上嵌入SE模块,并做了一些相应的修改和优化。该网络取得了当时single-crop上最好的性能。 最近的一些研究并不单单把Squeeze-and-Excitation局限在图片分类上,也会尝试将其应用在一些不同任务的中间特征图上,以提升不同通道特征的信息利用。 一个Squeeze-and-Excitation函数的飞桨实现 (https://github.com/c8241998/CV_attention/blob/master/SEnet/senet-paddle.py):
 def _squeeze_excitation(self, input, num_channels, name=None):
def _squeeze_excitation(self, input, num_channels, name=None):
mixed_precision_enabled = mixed_precision_global_state() is not None
pool = fluid.layers.pool2d(
input=input,
pool_size=0,
pool_type='avg',
global_pooling=True,
use_cudnn=mixed_precision_enabled)
stdv = 1.0 / math.sqrt(pool.shape[1] * 1.0)
squeeze = fluid.layers.fc(
input=pool,
size=int(num_channels / self.reduction_ratio),
act='relu',
param_attr=fluid.param_attr.ParamAttr(
initializer=fluid.initializer.Uniform(-stdv, stdv),
name=name + '_sqz_weights'),
bias_attr=ParamAttr(name=name + '_sqz_offset'))
stdv = 1.0 / math.sqrt(squeeze.shape[1] * 1.0)
excitation = fluid.layers.fc(
input=squeeze,
size=num_channels,
act='sigmoid',
param_attr=fluid.param_attr.ParamAttr(
initializer=fluid.initializer.Uniform(-stdv, stdv),
name=name + '_exc_weights'),
bias_attr=ParamAttr(name=name + '_exc_offset'))
scale = fluid.layers.elementwise_mul(x=input, y=excitation, axis=0)
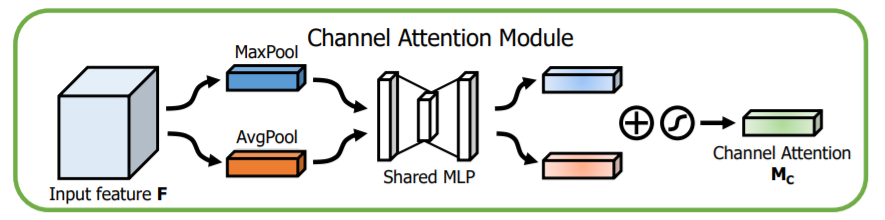
CBAM是一个简单但有效的注意力模块。对于一个中间特征图,可以沿着空间和通道两个维度依次推断出注意力权重,然后与原特征图相乘来对特征进行自适应调整。作者将整个过程分为两个独立的模块:通道注意力模块和空间注意力模块。这样不仅可以节约参数和计算量,还保证了其可以作为即插即用的模块集成到现有的网络架构中去。 图2展示的是一个通道注意力模块。给定H×W×C 的特征 F,作者分别采用了两种池化方式对中间特征进行不同的处理:即分别对空间进行全局平均池化和最大池化得到两个 1×1×C 的通道特征。随后将它们送入一个共享的两层神经网络,第一层神经元个数为 C/r,激活函数为 Relu,第二层神经元个数为 C。再将得到的两个特征相加后经过一个 Sigmoid 激活函数得到权重系数 Mc。最后拿权重系数和原特征相乘即可得到新特征。
 return scale
图3展示的是一个空间注意力模块。给定H×W×C 的特征 F,作者先后采用两种池化方式对中间特征进行不同处理,即先后对通道进行平均池化和最大池化,得到两个 H×W×1 的通道特征。将两层特征拼接在一起,经过一个7×7 的卷积层,激活函数为 Sigmoid,得到权重系数 Ms。最后,拿权重将数和特征 F 相乘即可得到新特征。
return scale
图3展示的是一个空间注意力模块。给定H×W×C 的特征 F,作者先后采用两种池化方式对中间特征进行不同处理,即先后对通道进行平均池化和最大池化,得到两个 H×W×1 的通道特征。将两层特征拼接在一起,经过一个7×7 的卷积层,激活函数为 Sigmoid,得到权重系数 Ms。最后,拿权重将数和特征 F 相乘即可得到新特征。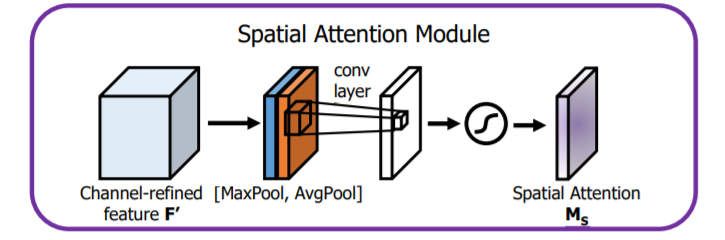 图4即为一个完整的CBAM模块,将两种注意力模块顺序组合即可。
图4即为一个完整的CBAM模块,将两种注意力模块顺序组合即可。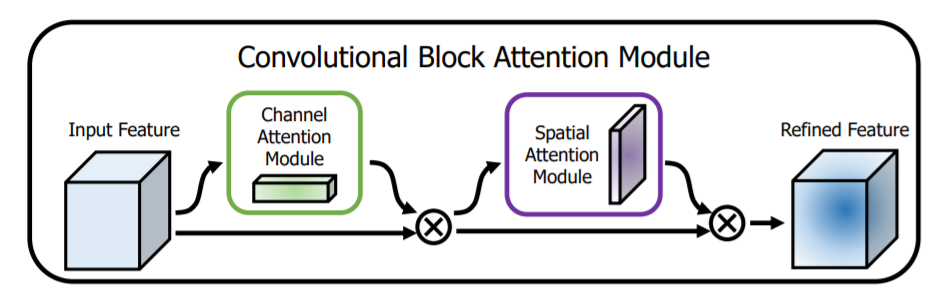
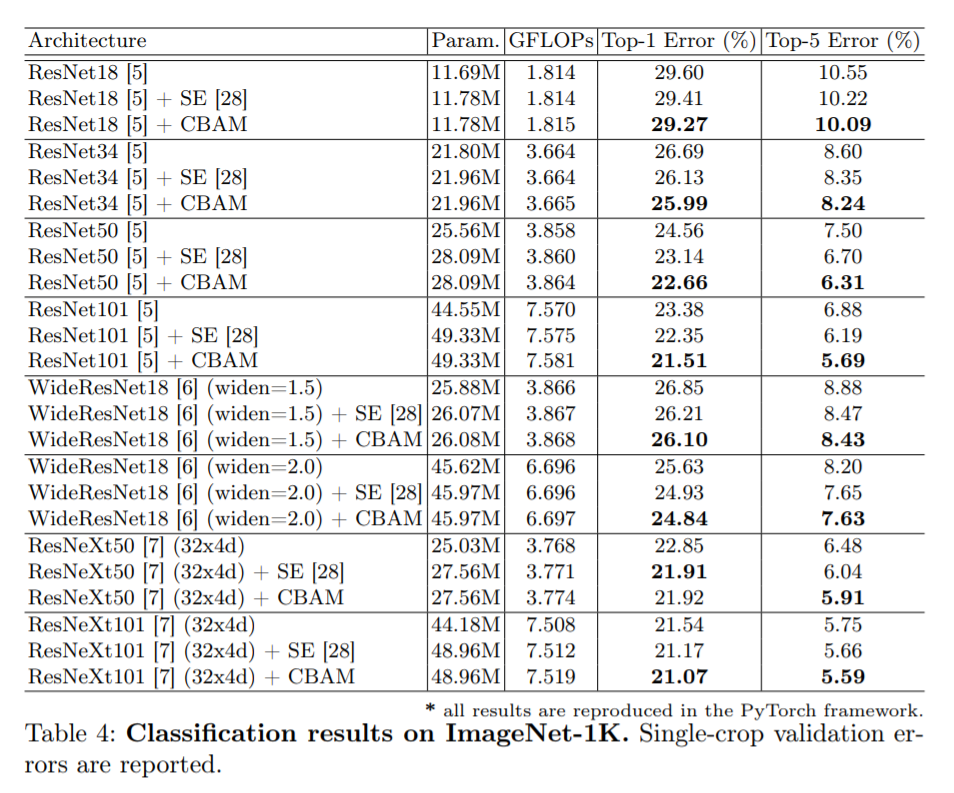 上表展示的是原论文的实验数据,在ImageNet分类实验中,将 CBAM 集成到所有的 ResNet 系列网络中去,都可以降低最终的分类错误率。CBAM 是一个轻量级的通用模块,与SENet类似,它被认为同样可以集成到任何 CNN 经典backbone中,并且可以与backbone一起进行端到端的训练。在原论文中的不同的分类和检测数据集上,集成CBAM后的模型的表现都有了一致的提升,体现了其广泛的可适用性。 一个CBAM模块的飞桨实现。 (https://github.com/c8241998/CV_attention/blob/master/CBAM/cbam-paddle.py): class CBAM_Module(fluid.dygraph.Layer):
上表展示的是原论文的实验数据,在ImageNet分类实验中,将 CBAM 集成到所有的 ResNet 系列网络中去,都可以降低最终的分类错误率。CBAM 是一个轻量级的通用模块,与SENet类似,它被认为同样可以集成到任何 CNN 经典backbone中,并且可以与backbone一起进行端到端的训练。在原论文中的不同的分类和检测数据集上,集成CBAM后的模型的表现都有了一致的提升,体现了其广泛的可适用性。 一个CBAM模块的飞桨实现。 (https://github.com/c8241998/CV_attention/blob/master/CBAM/cbam-paddle.py): class CBAM_Module(fluid.dygraph.Layer):
def __init__(self, channels, reduction):
super(CBAM_Module, self).__init__()
self.avg_pool = AdaptiveAvgPool2d(pool_size=1, pool_type="avg")
self.max_pool = AdaptiveAvgPool2d(pool_size=1, pool_type="max")
self.fc1 = fluid.dygraph.Conv2D(num_channels=channels, num_filters=channels // reduction, filter_size=1, padding=0)
self.relu = ReLU()
self.fc2 = fluid.dygraph.Conv2D(num_channels=channels // reduction, num_filters=channels, filter_size=1, padding=0)
self.sigmoid_channel = Sigmoid()
self.conv_after_concat = fluid.dygraph.Conv2D(num_channels=2, num_filters=1, filter_size=7, stride=1, padding=3)
self.sigmoid_spatial = Sigmoid()
def forward(self, x):
# Channel Attention Module
module_input = x
avg = self.relu(self.fc1(self.avg_pool(x)))
avg = self.fc2(avg)
mx = self.relu(self.fc1(self.max_pool(x)))
mx = self.fc2(mx)
x = avg + mx
x = self.sigmoid_channel(x)
# Spatial Attention Module
x = module_input * x
module_input = x
avg = fluid.layers.mean(x)
mx = fluid.layers.argmax(x, axis=1)
print(avg.shape, mx.shape)
x = fluid.layers.concat([avg, mx], axis=1)
x = self.conv_after_concat(x)
x = self.sigmoid_spatial(x)
x = module_input * x
return x
总结
注意力机制是一个很宽泛的概念,随着针对它的研究越来越多,其操作方式也越来越多样。但它们都有一个共同的核心思想:对特征中更感兴趣的层面施加更大的注意力权重,而这个过程与人类观察物体的方式非常相似,期待在该领域有更多高质量的工作出现。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
活动
登录后可评论,请前往 登录 或 注册