初学神经网络(一)
作者:奋斗的_蝼蚁2020.09.22 08:16浏览量:1883简介:此文章以一个典型神经网络为例,帮助深度学习初学者快速掌握卷积神经网络的概念与相关基础,对神经网络进行快速地入门。
1.单个神经元网络模型:
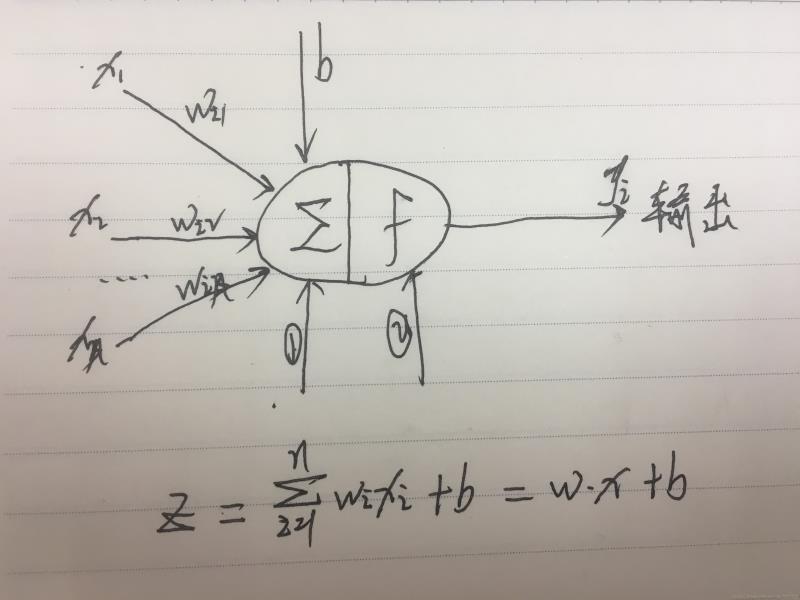
其中 xi 表示输入,wi 和 b 表示参数。函数①是图中下方的公式,是一个线性模型。函数②是一个激活函数/激励函数。
2.两层神经网络
理论上两层神经网络已经可以拟合任意函数,结构如下:
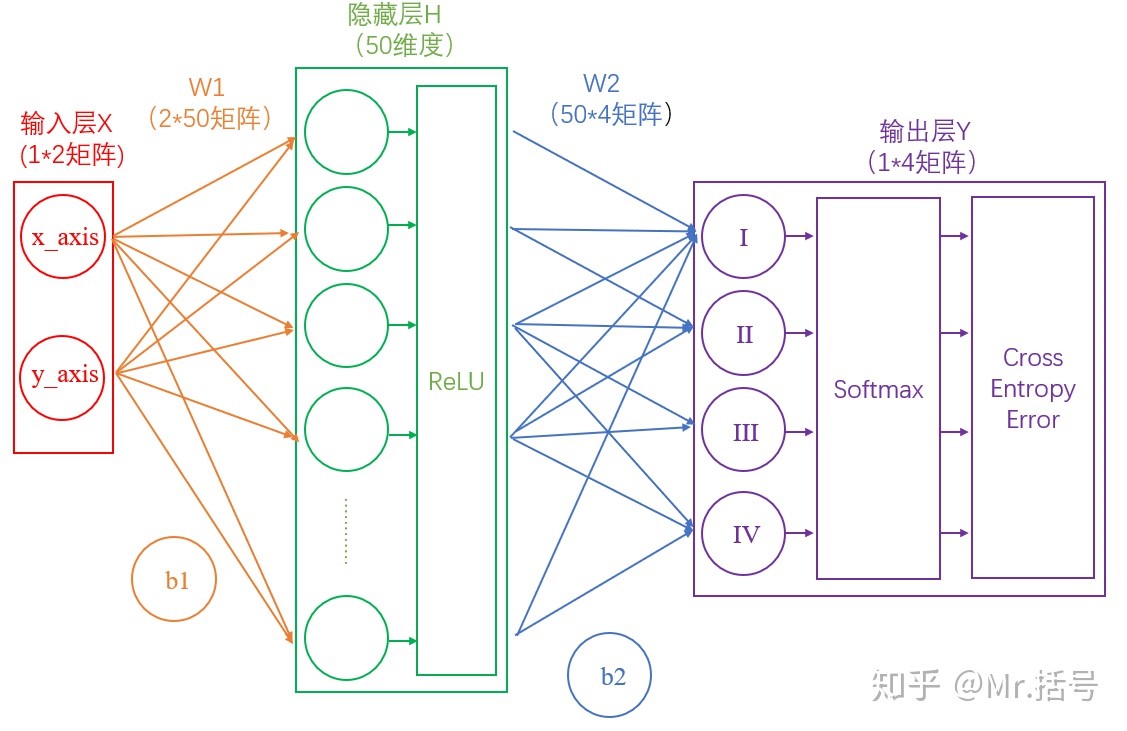
简化的两层神经网络:
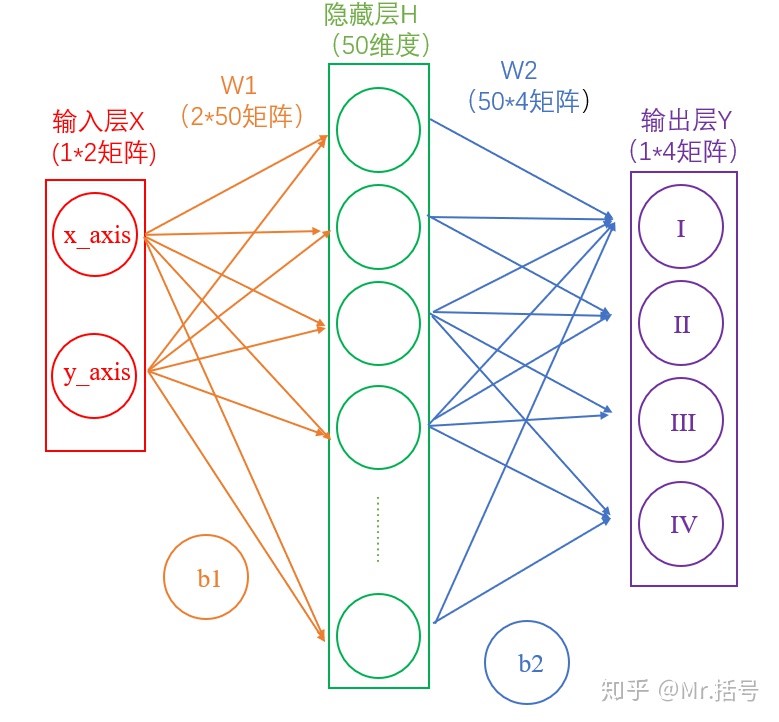
输入层是坐标值,例如(1,1),这是一个包含两个元素的数组,也可以看作是一个1*2的矩阵。输入层的元素维度与输入量的特征息息相关,如果输入的是一张32*32像素的灰度图像,那么输入层的维度就是32*32。
从输入层到隐藏层,设定隐藏层为50维(也可以理解成50个神经元)之后,得到(1*50)的矩阵H:
连接隐藏层和输出层的是W2和b2,同样是通过矩阵运算进行的:
一系列线性方程的运算最终都可以用一个线性方程表示。也就是说,上述两个式子联立后可以用一个线性方程表达。对于两次神经网络是这样,就算网络深度加到100层,也依然是这样。这样的话神经网络就失去了意义。
所以这里要对网络注入灵魂:激活层。
2.激活函数
激活函数的主要作用就是用来加入非线性因素的,以解决线性模型表达能力不足的缺陷,在整个神经网络里起到至关重要的作用。
因为神经网络的数学基础是处处可微的,所以选取的激活函数要能保证数据输入与输出也是可微的,常用的有三种,分别是阶跃函数、Sigmoid和ReLU。
阶跃函数:当输入小于等于0时,输出0;当输入大于0时,输出1。
Sigmoid:当输入趋近于正无穷/负无穷时,输出无限接近于1/0。
ReLU:当输入小于0时,输出0;当输入大于0时,输出等于输入。
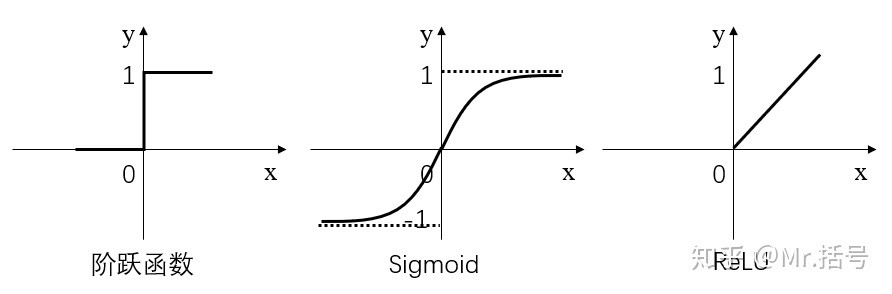
其中,阶跃函数输出值是跳变的,且只有二值,较少使用;Sigmoid函数在当x的绝对值较大时,曲线的斜率变化很小(梯度消失),并且计算较复杂;ReLU是当前较为常用的激活函数。
假如经过公式H=X*W1+b1计算得到的H值为:(1,-2,3,-4,7...),那么经过阶跃函数激活层后就会变为(1,0,1,0,1...),经过ReLU激活层之后会变为(1,0,3,0,7...),数值最大的就代表着当前分类,此时神经网络变成了下图:
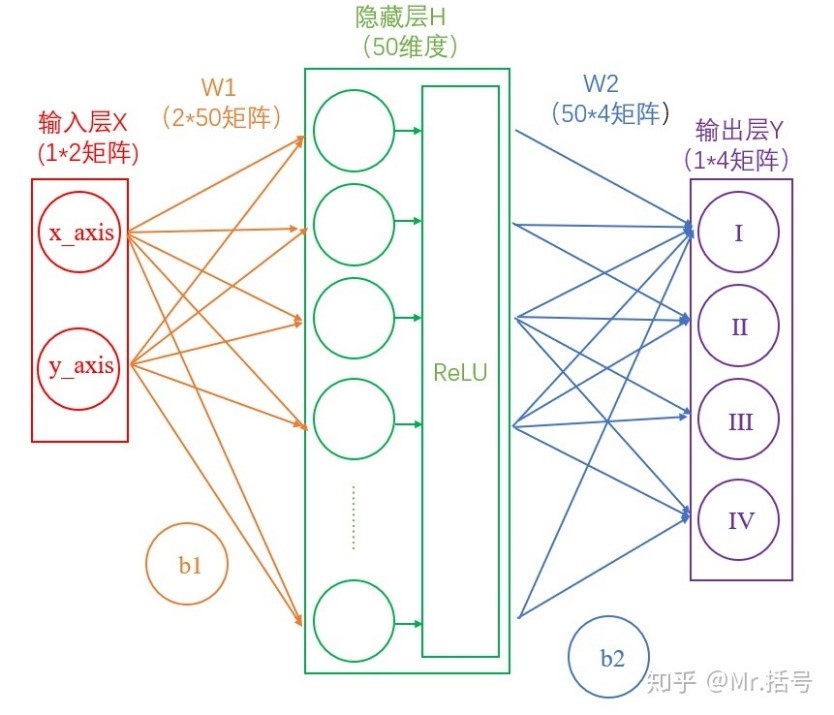
注:每个隐藏层计算(矩阵线性运算)之后,都需要加一层激活层,要不然该层线性计算是没有意义的。
3.输出的正规化
上图输出Y的值可能会是(3,1,0.1,0.5)这样的矩阵,诚然我们可以找到里边的最大值“3”,从而找到对应的分类为I,但是这并不直观。我们想让最终的输出为概率,也就是说可以生成像(90%,5%,2%,3%)这样的结果,这样做不仅可以找到最大概率的分类,而且可以知道各个分类计算的概率值。计算公式如下:
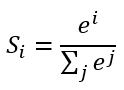
简单来说分三步进行:(1)以e为底对所有元素求指数幂;(2)将所有指数幂求和;(3)分别将这些指数幂与该和做商。
这样求出的结果中,所有元素的和一定为1,而每个元素可以代表概率值。
我们将使用这个计算公式做输出结果正规化处理的层叫做“Softmax”层。此时的神经网络将变成如下图所示:
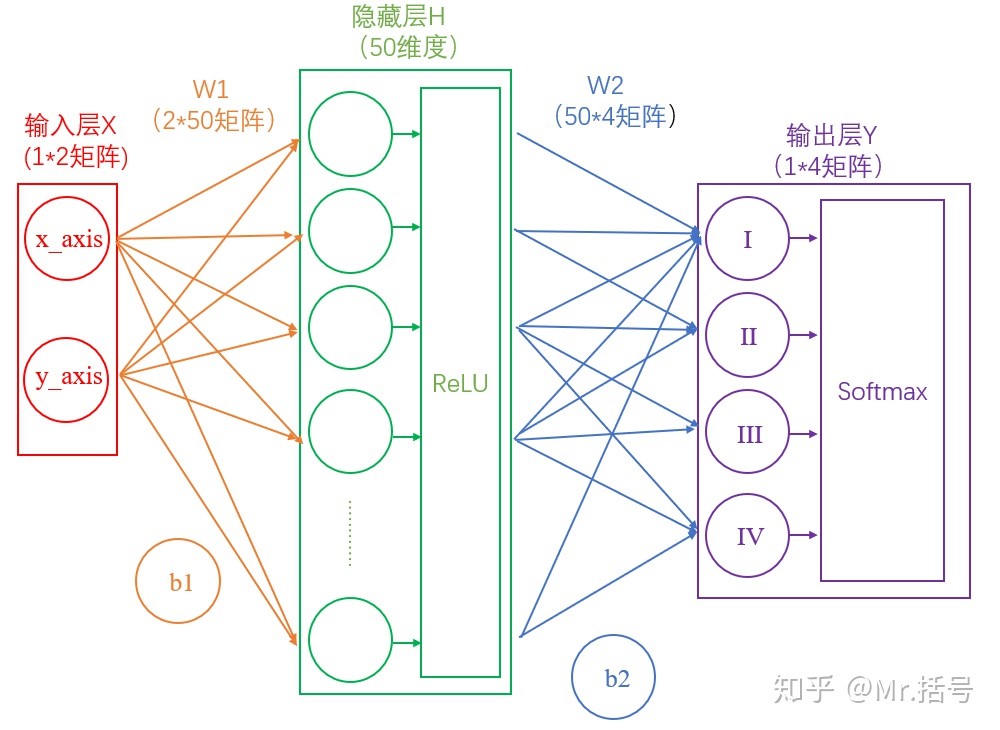
4.如何衡量输出的好坏
Softmax输出的结果是(90%,5%,3%,2%),真实的结果是(100%,0,0,0)。虽然输出的结果可以正确分类,但是与真实结果之间是有差距的,一个优秀的网络对结果的预测要无限接近于100%,为此,我们需要将Softmax输出结果的好坏程度做一个“量化”。
一种直观的解决方法,是用1减去Softmax输出的概率,比如1-90%=0.1。不过更为常用且巧妙的方法是,求对数的负数。
还是用90%举例,对数的负数就是:-log0.9=0.046
可以想见,概率越接近100%,该计算结果值越接近于0,说明结果越准确,该输出叫做“交叉熵损失(Cross Entropy Error)”。
我们训练神经网络的目的,就是尽可能地减少这个“交叉熵损失”。
此时的网络如下图:
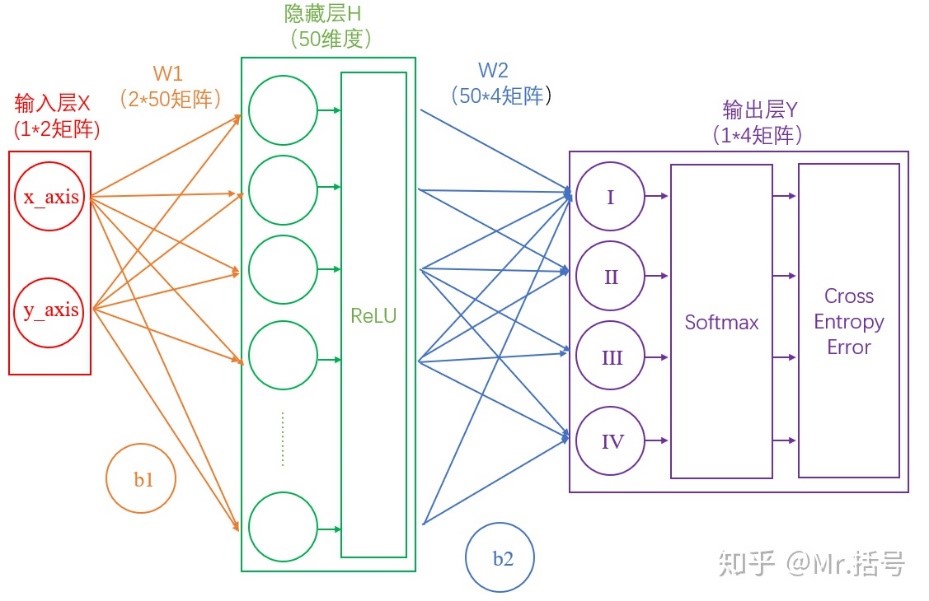
5.反向传播与参数优化
上边的1~4节,讲述了神经网络的正向传播过程。一句话复习一下:神经网络的传播都是形如Y=WX+b的矩阵运算;为了给矩阵运算加入非线性,需要在隐藏层中加入激活层;输出层结果需要经过Softmax层处理为概率值,并通过交叉熵损失来量化当前网络的优劣。
算出交叉熵损失后,就要开始反向传播了。其实反向传播就是一个参数优化的过程,优化对象就是网络中的所有W和b(因为其他所有参数都是确定的)。
神经网络的神奇之处,就在于它可以自动做W和b的优化,在深度学习中,参数的数量有时会上亿,不过其优化的原理和我们这个两层神经网络是一样的。
好比操纵着一个球型机器行走在沙漠中,我们在机器中操纵着四个旋钮,分别叫做W1,b1,W2,b2。当我们旋转其中的某个旋钮时,球形机器会发生移动,但是旋转旋钮大小和机器运动方向之间的对应关系是不知道的。而我们的目的就是走到沙漠的最低点。
如果增大W1后,球向上走了,那就减小W1。
如果增大b1后,球向下走了,那就继续增大b1。
如果增大W2后,球向下走了一大截,那就多增大些W2。等等
这就是进行参数优化的形象解释(有没有想到求导?),这个方法叫做梯度下降法。
当我们的球形机器走到最低点时,也就代表着我们的交叉熵损失达到最小(接近于0)。
6.迭代
神经网络需要反复迭代。
如上述例子中,第一次计算得到的概率是90%,交叉熵损失值是0.046;将该损失值反向传播,使W1,b1,W2,b2做相应微调;再做第二次运算,此时的概率可能就会提高到92%,相应地,损失值也会下降,然后再反向传播损失值,微调参数W1,b1,W2,b2。依次类推,损失值越来越小,直到我们满意为止。
此时我们就得到了理想的W1,b1,W2,b2。
此时如果将任意一组坐标作为输入,利用图4或图5的流程,就能得到分类结果。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册