基于飞桨复现强化学习进阶算法SAC,让月球着陆器顺利着陆
2020.10.16 01:24浏览量:2233简介:今天我们一起来了解一下进阶算法SAC,并且看一看如何利用飞桨的PARL强化学习框架方便地把SAC应用到GYM Box2D的月球着陆器环境当中去。
 本文主要包括以下三部分内容:
本文主要包括以下三部分内容:
- SAC算法论文简介
- SAC算法样例代码简介
- 介绍如何用SAC算法玩转月球着陆器
SAC算法论文
SAC是Soft Actor-Critic的缩写,由伯克利人工智能研究实验室(BAIR)的Tuomas Haarnoja等人,提出于2018年。原文链接:https://arxiv.org/abs/1801.01290
不知道读完了论文的同学有没有同感,就是SAC可以大致看成是DDPG的增强版。那么论文为什么想要去增强DDPG呢? 问题一:为什么需要增强DDPG? 论文认为,有两大因素使深度强化学习的实际应用变得困难:- 非常高的采样复杂度(very high sample complexity)
- 脆弱的收敛性质(brittle convergence properties)
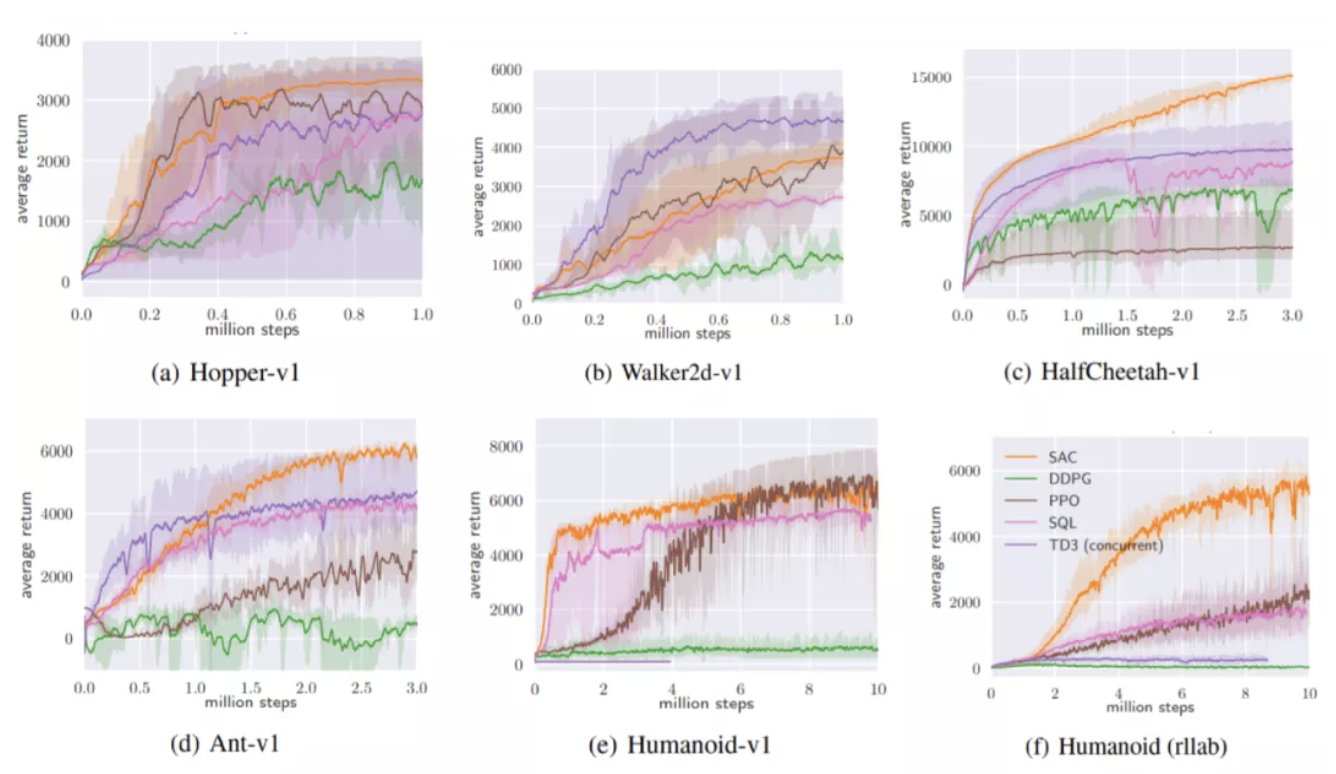 从图中的训练曲线来看,SAC在难度各异的几个任务中都表现出了良好的稳定性(黄色阴影部分较窄,且集中于实线附近)。在Hopper-v1,HalfCheetah-v1,Ant-v1,Humanoid(rllab)中,SAC最终的return明显高于其他算法,尤其是在最为复杂的控制空间多达21维的Humanoid (rllab) 中,一骑绝尘,表现出了明显的优势。
从图中的训练曲线来看,SAC在难度各异的几个任务中都表现出了良好的稳定性(黄色阴影部分较窄,且集中于实线附近)。在Hopper-v1,HalfCheetah-v1,Ant-v1,Humanoid(rllab)中,SAC最终的return明显高于其他算法,尤其是在最为复杂的控制空间多达21维的Humanoid (rllab) 中,一骑绝尘,表现出了明显的优势。
SAC算法样例
SAC算法这么好,实现起来会不会很麻烦呢?一起看一看百度飞桨开源深度学习平台PaddlePaddle的飞桨深度强化学习框架PARL中的SAC样例。样例代码链接,GitHub中基于PARL的SAC样例:https://github.com/PaddlePaddle/PARL/tree/develop/examples/SAC
(GitHub访问困难的同学可以自己搜索一下Gitee,也可以在example目录下找到的)
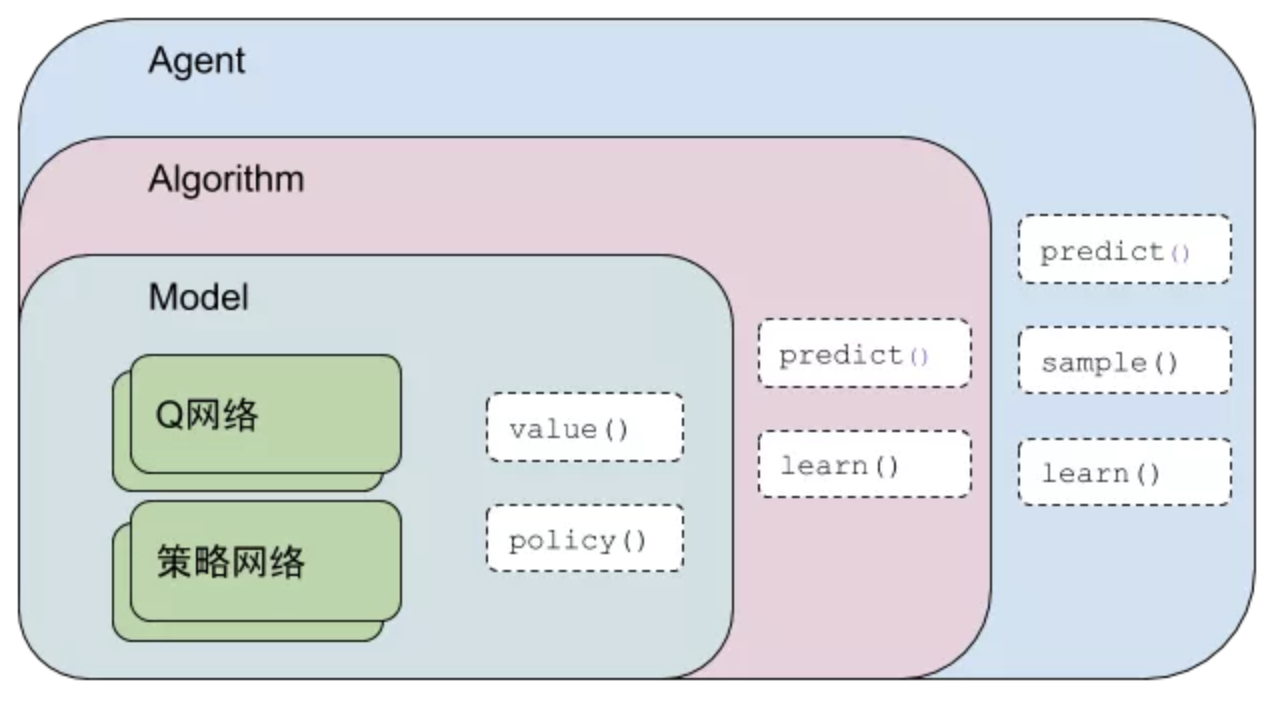
PARL框架的结构大致如上图所示,采用了层层嵌套的结构,适用于绝大多数强化学习算法。具体到SAC算法的话,最内层Model封装了Q网络与策略网络的网络结构,通过value()与policy()两个方法输出Q值和动作值。向外一层,Algorithm主要封装了损失函数,通过predict()向外输出动作值,通过learn()向内更新Model的网络权重。最外层的Agent主要负责与环境的交互并把从环境得到的数据喂给Algorithm。
具体实现上,因为使用了PARL框架的结构和封装好的算法,整个实现显得很整洁。共分为三个文件:
-
mujoco_agent.py
-
mujoco_model.py
-
train.py
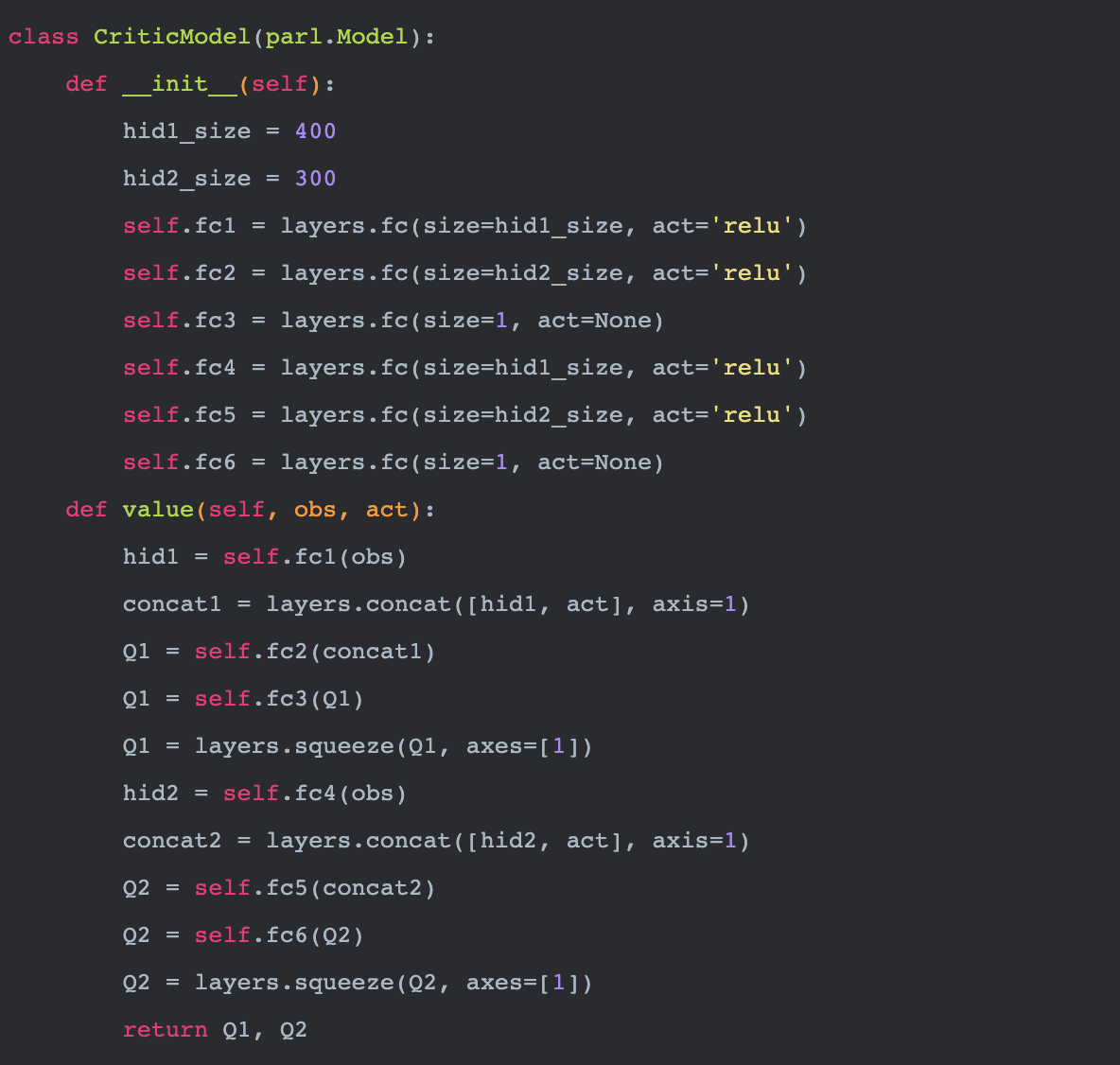
先看看mujoco_model.py,这里封装了两个Model类,来实现策略网络和Q网络,也就是SAC中的A与C(Actor与Critic)。两个类都继承了PARL的Model。ActorModel中定义了Actor的网络结构(策略网络),实现了policy方法。这个方法根据输入obs也就是当前外部环境状态,通过内部的策略网络,来输出动作值。

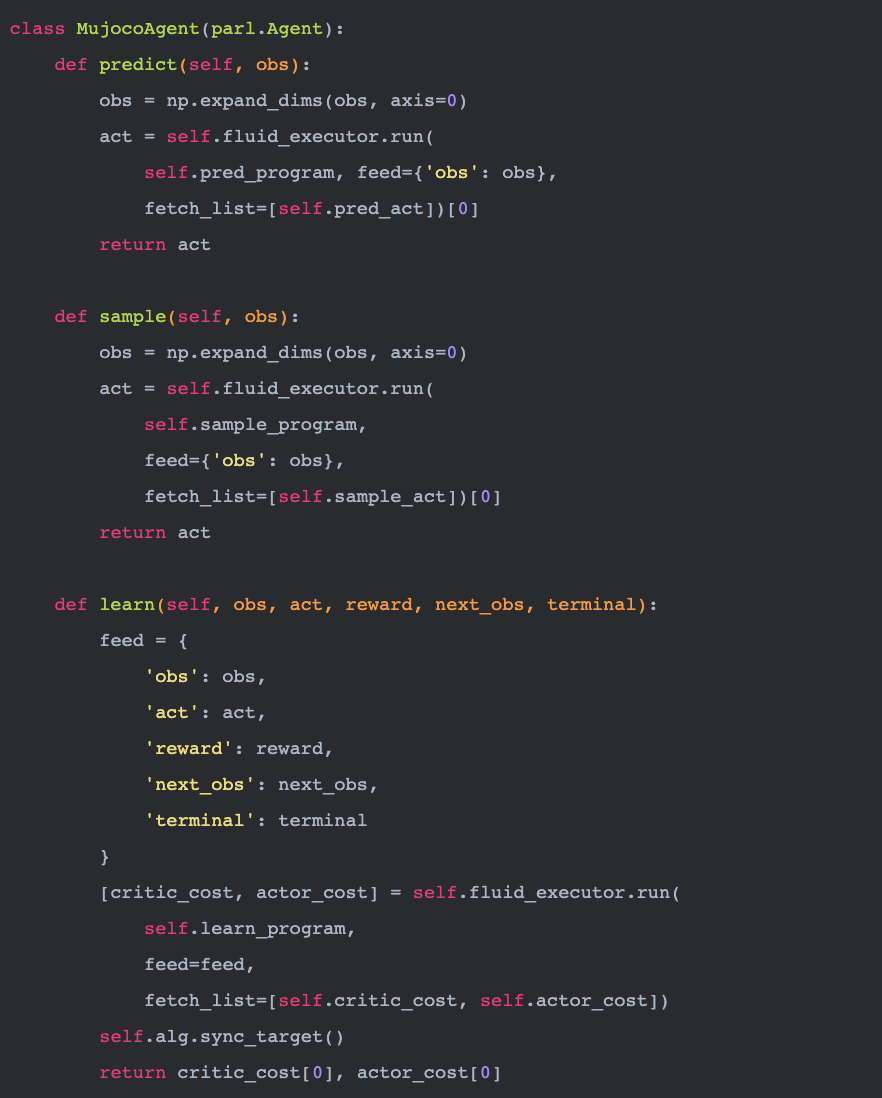
再看看mujoco_agent.py,这里封装了MujocoAgent类,这个类继承了PARL的Agent。主要实现了predict,sample,learn三大功能。predict用来根据从环境取得的数据也就是环境状态来输出一个动作值。sample也同样根据环境状态输出动作值,不同的是,这个方法还有一定的概率输出一个随机的动作值,用来探索新的动作。learn则实现了根据环境状态、动作值和回报值等数据来优化model内部网络参数的功能。
最后看看train.py,这里就是训练脚本了。实例化actor和critic后,使用PARL封装好的SAC算法,层层嵌套最后得到一个可以和环境交互的agent实例:

可以直接用PARL内置的ReplayMemory类实现经验回放,并且给从PARL导入的ReplayMemory设置参数。

SAC算法实践
最后,我们通过实践,来看一看SAC算法在GYM Box2D的LunarLanderContinuous-v2任务中的表现。
同样基于PARL框架,代码也十分简洁。与样例相比,主要在训练脚本中改动了两处。
首先引入gym库 在Notebook文件中加入下面语句,输出可视化就做好了。
在Notebook文件中加入下面语句,输出可视化就做好了。
 在GPU上经过几个小时的训练,我们就可以得到可视化输出如下所示。
在GPU上经过几个小时的训练,我们就可以得到可视化输出如下所示。
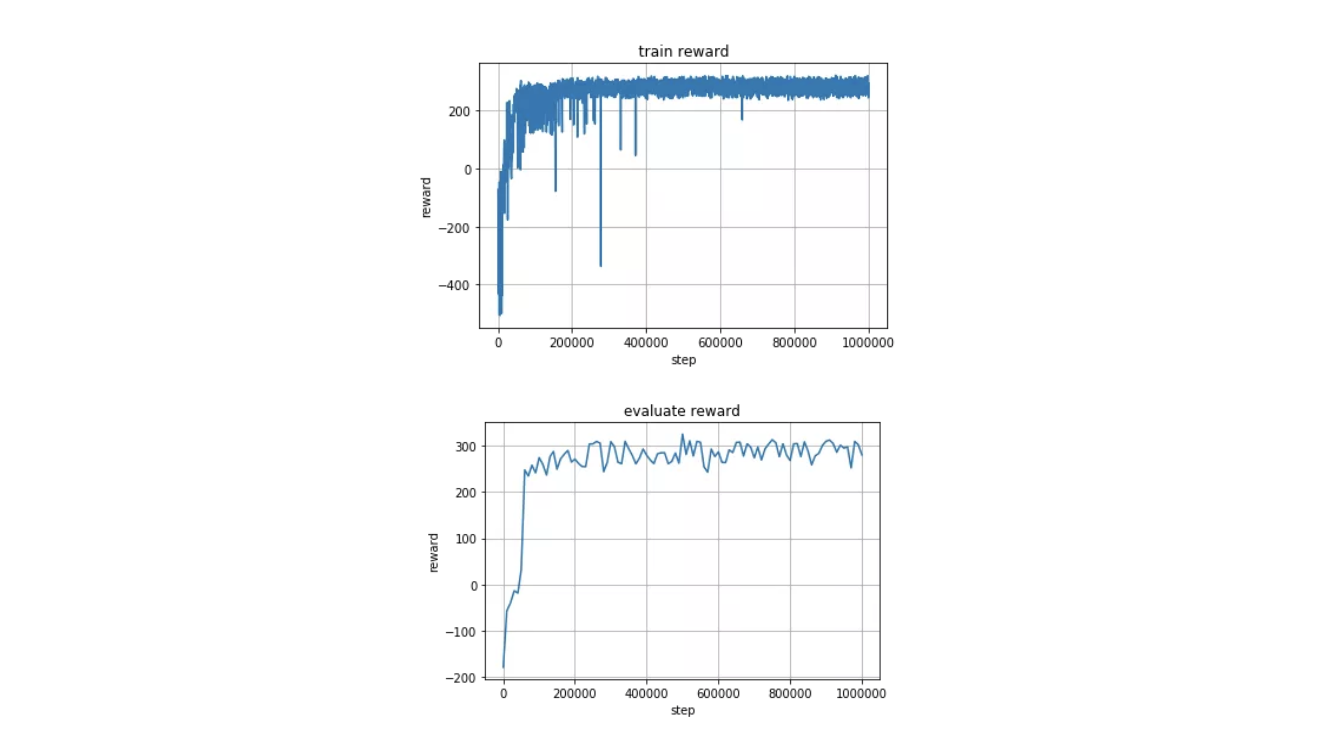 从训练与评估的输出来看,收敛良好,SAC算法的优势在这个实践中得以完美体现。
从训练与评估的输出来看,收敛良好,SAC算法的优势在这个实践中得以完美体现。
全文回顾
首先,我们总结了论文的主要内容,分析了SAC算法提出的目的,原理和作用。算法通过引入最大熵使得决策分布趋于多样化,从而适应于更为复杂的实际应用,并取得更好的应用效果。
其次,介绍了PARL框架给出的SAC算法样例概要。得益于PARL框架的强大,样例代码显得简洁明晰,易读易上手。 最后,实践环节,了解了这个框架在LunarLanderContinuous-v2环境中的应用。在SAC算法的帮助下,我们的登月舱得以平稳准确地着陆于指定位置。并且在训练过程中表现出了快速收敛和稳定输出的良好性能。 实践代码链接: https://aistudio.baidu.com/aistudio/projectdetail/888258 想具体了解如何简洁地实现SAC算法吗?想亲手训练并玩转月球着陆器吗?那就点击上面的链接查看开源代码,然后Fork并运行一下吧。
发表评论
登录后可评论,请前往 登录 或 注册