解决重重障碍——看百度云数据仓库Palo如何赋能小程序精细运营
2021.01.22 20:56浏览量:5153简介:百度APP小程序目前使用百度云 Palo(Apache Doris 企业版)承载其精细化运营业务。 本文的主要内容:小程序私域精细化运营能力介绍、用户分层技术难点和用户分层的架构和解决方案。
百度云数据仓库Palo是一款基于Apache Doris(百度自研分析型数据库引擎)构建的企业级MPP云数据仓库。全面兼容MySQL协议,提供快捷查询UI,支持高并发低延时,支持PB级以上的超大数据集,可有效地支持在线实时数据分析。
现有新用户免费试用3个月优惠活动,详情请看:https://cloud.baidu.com/product/palo.html
作为Palo的用户,我们认为Palo运维简单、架构优雅,非常推荐各位开发者来免费试用。以下是我们从开发者视角为大家带来的试用经验分享~
1 小程序私域精细化运营能力介绍
1.1 能力介绍
首先,作为小程序的开发者,我们做私域精细化运营是因为两个痛点
-
私域用户价值不突出。比如,我是个目前有100万用户的开发者,想推一款奢侈品包包给用户里面的高收入人群。但是我不知道这100万人中,有多少人是高收入人群,是很难将他们找出来的。
-
缺乏主动触达能力,也就是触达通路比较少。
针对这两个问题,我们产品上提出了一个解决方案——分层运营。
分层运营分成两部分,运营触达和精细化人群。
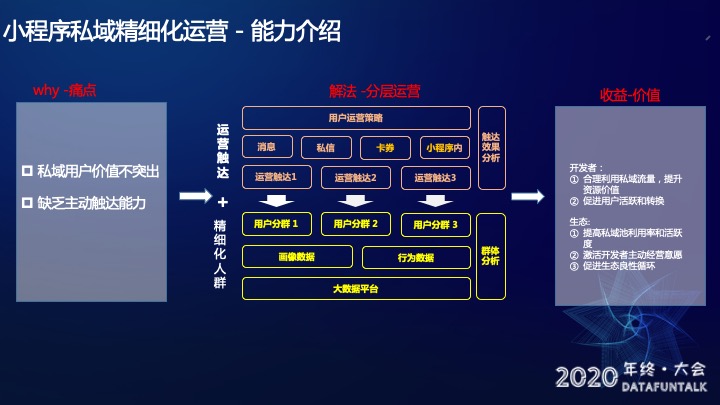
如图所示,从上往下看,比如我现在要推一个活动,运营同学会在消息、私信、卡券和小程序内这四个通路中选择一个进行推送。选完通路之后,就要选择人群。
精细化人群筛选是基于百度的大数据平台提供的画像数据和行为数据去筛选特定的人群。
整个流程完成之后,我们会提供一个触达效果的分析(主要包括下发量,点展和到达分析等),和一个群体分析(对整个用户群的更细致化的分析)。
作为开发者,我们获得的收益和价值是:
-
合理利用私域流量,提升资源价值
-
促进用户活跃和转换
对于整个生态,获得的收益和价值是:
-
提高私域池利用率和活跃度
-
激活开发者主动经营意愿
-
促进生态良性循环
以上主要讲了整个产品的方案,下面讲一下具体的功能。
1.2 分层运营——B端视角
作为开发者,我要如何去创建用户分分层?
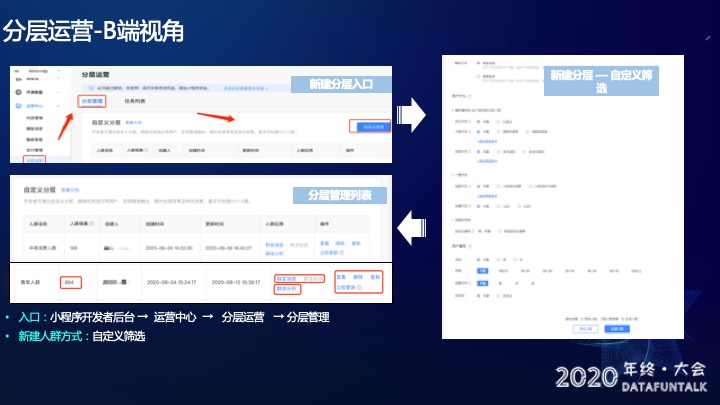
入口在小程序开发者后台——运营中心——分层运营——分层管理——自定义筛选。点击自定义筛选后会进入自定义筛选页面,在这个页面用户可以选择关注行为、卡券行为、交易行为等维度。选择完成之后,可以使用“预估人数”功能,实时计算一下圈选的人群人数有多少,如果觉得所选的人群人数比较合适就点击“生成人群”。生成人群之后将会进入分层管理列表,在这里可以发送消息或私信,还可以进行群体分析。
1.3 分层运营——C端视角
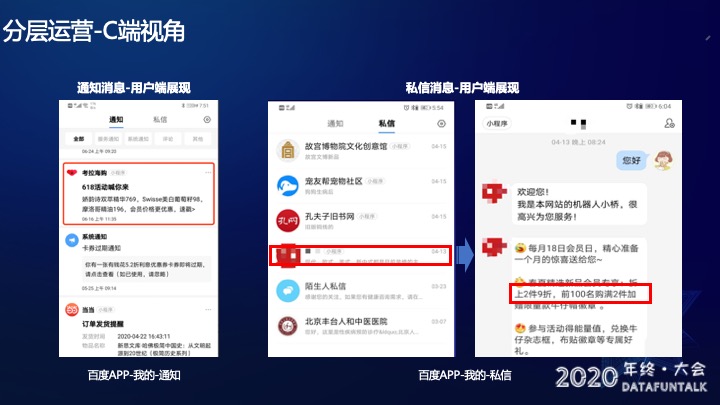
下图是从C端视角来分层运营的功能,这里截取了百度App的通知和私信的样式。
1.4 分层运营经典案例
百度App在跟汽车大师合作的时候,汽车大师选择近一周付费且活跃用户开展“评价送券”活动。
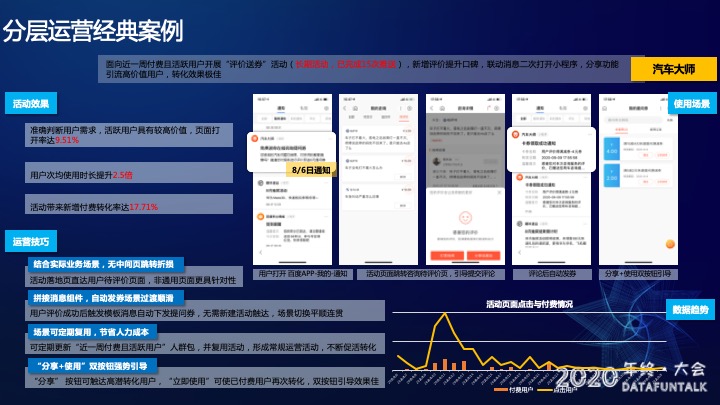
如图所示,使用场景是在百度App中向用户推送一个通知,用户在“我的”里面打开,填写评价之后可以领券。
这次活动的效果是:
- 准确判断用户需求,活跃用户具有较高价值,页面打开率达9.51%
- 用户次均使用时长提升2.5倍
- 活动带来新增付费转化率达17.71%
这里面有几个运营技巧:
- 结合实际业务场景,无中间页跳转折损
- 拼接消息组件,自动发券场景过渡顺滑
- 场景可定期复用,节省人力成本。也就是创建完人群之后,可以一直使用这个人群。
- “分享+使用”双按钮强势引导
从上面分享给大家的案例可以看出,私域流量的用户分层运营其实可以给开发者带来运营效率和转化效果的提升,进而促进用户增长。
但是实现起来有很大的技术难点。
2 用户分层难点
难点主要有四个:
首先,TB级数据,数据量特别大。我们基于画像和行为做用户分层,每天的数据量大概有1T+。
第二,查询的频响要求极高,要求毫秒到秒级的响应时间。比如刚刚提到的“预估人数”的功能,用户在点击之后,我们需要在毫秒到秒的时间内,从TB级的数据中计算这个选定的人群数量结果。
第三,计算复杂,需要动态静态组合查询。很多维度的数据无法进行预聚合,必须要实时计算明细数据,所以计算是很复杂的,这点后面会详细展开。
第四,产出用户包要求实效性高。
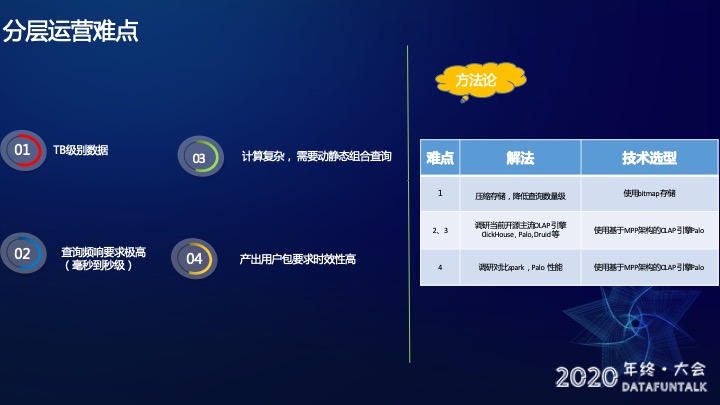
针对上面的四个难点,我们的方法论如下:
难点1: 压缩存储,降低查询数量级,选择使用Bitmap存储。无论目前市场上主流的OLAP引擎有多厉害,数据量越大,查询速度就一定越慢,所以我们要降低存储。
难点2、3: 我们调研了当前开源主流OLAP引擎ClickHouse, Palo(Apache Doris), Druid等,最后选择使用基于MPP架构的OLAP引擎Palo。在性能上其实ClickHouse, Palo(Apache Doris), Druid都差不多。但是Palo有几个优点,第一,Palo兼容MySQL协议,学习成本非常低,基本上RD都会用。第二,Palo的运维成本很低,基本上是自动化运维,所以我们最后选择了Palo。
难点4: 我们调研对比了Spark,Palo 性能,最终也是选择使用基于MPP架构的OLAP引擎Palo,这点在后面会详细讲。
3 用户分层的架构和解决方案
下面我将会从架构和解决方案上讲解上面这些难点是如何解决的。
3.1 分层运营架构
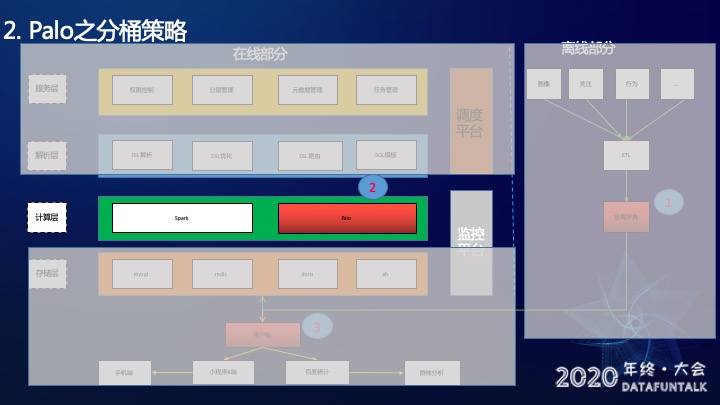
首先介绍一下分层运营的架构,分为在线部分和离线部分。
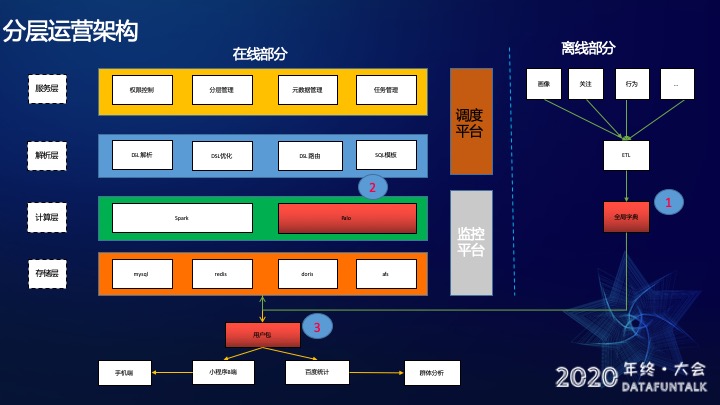
在线部分分为四层,服务层、解析层、计算层和存储层,还有一个调度平台和一个监控平台。
服务层包含了权限控制(用户权限和接口权限),分层管理(是对用户筛选分层的增删改查的管理),元数据管理(对页面元素和ID Mapping的管理)和任务管理(对调度平台任务的增删改查的管理)
解析层主要是对DSL的解析。比如,用户要在线预估人数。走到解析层时,首先要进行DSL解析。然后对DSL优化,比如我想找到近7天活跃的用户和近7天不活跃的用户求一个交集,显然结果是0,那么在优化层被优化掉,返还给用户结果为0,不会再往下走到计算引擎。优化之后会有DSL路由,这个路由的功能主要是判断查询的维度,路由到SQL模版进行模版的拼接。
计算引擎层主要有Spark和Palo。Spark主要用来做离线任务的计算,Palo用来做实时计算。
存储层有MySQL(用来存用户分层的信息),Redis(主要用来缓存),Palo(存画像数据和行为数据)和afs(存产出的用户包信息)。
调度平台用来管理离线任务的调度,监控平台用来对整体服务稳定性监控。
离线部分主要是对需要的数据源,比如画像、关注、行为等数据进行ETL清洗,然后做一个全局字典,完成之后会写入Palo。
在产出用户包之后,会分发给小程序B端和百度统计。小程序B端会将消息推送到这些用户的手机端;百度统计会用这个用户包做群体分析。
以上就是整体的架构,图中标红的部分是针对之前的难点做的重点改造,下面我将针对这几个重点模块,依次展开讲解。
3.1.1 全局字典
全局字典主要是用来解决难点一——数据量大,压缩存储的同时保证查询性能。
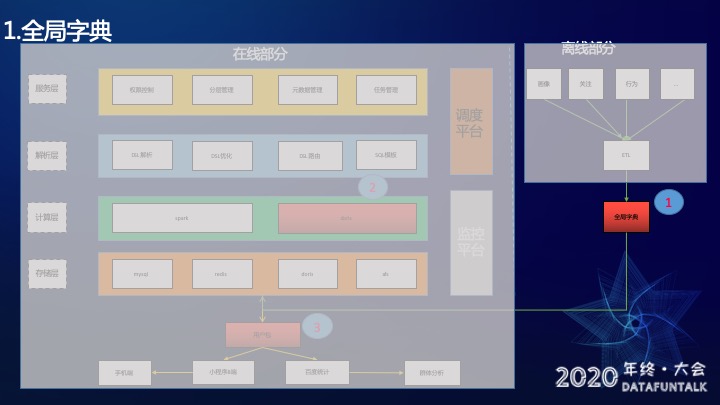
这里大家可能会有疑问,既然用Bitmap存,为什么还需要全局字典?
因为Palo的bitmap功能基于RoaringBitmap实现的。因此当用户id 过于离散的时候,RoaringBitmap 底层存储结构用的是Array Container, 而没有用到Bitmap Container。Array Container性能远远差于Bitmap Container,因此我们使用了全局字典将用户id转换成连续递增id。
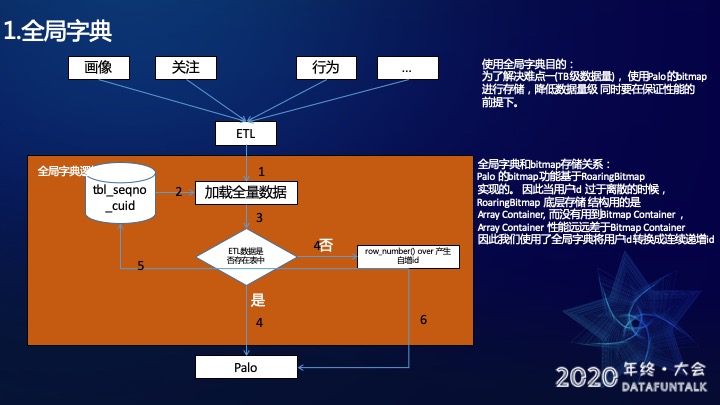
下面介绍一下全局字典的逻辑。
画像、关注、行为等数据源经过ETL处理之后会进入Spark中。Spark首先会加载全局字典表,这张表主要用来维护用户ID和自增ID的映射关系,会做一次全量的加载。加载完成后会判断用户ID是否在这个全量的字典表中,如果存在则直接将ETL之后的数据写入Palo,如果不存在则说明这是个新用户,使用row_numebr()over产生一个自增ID与用户ID做一次映射,映射完成后会写入这张表中,同时将ETL之后的数据写入Palo。
3.1.2 百度Palo
Palo之分桶策略
首先讲一下分桶策略,分桶策略主要用来解决难点二——查询频响要求高。
之前做全局字典是要保证用户的连续递增,但我们发现做完全局字典之后Bitmap的查询性能并没有达到我们预期中的速度。后来我们发现Doris是一个分布式的集群,它会按照某些Key进行分桶,也就是说分桶之后用户ID在桶内又是离散的了。

如图中的例子所示,原始数据userid是连续的,在按照appkey和channel进行分桶之后,在桶内的userid就不是连续的了。但是不连续的话,Bitmap的性能不能很好的发挥出来。
那么在这种情况下如何保证桶内的连续呢?
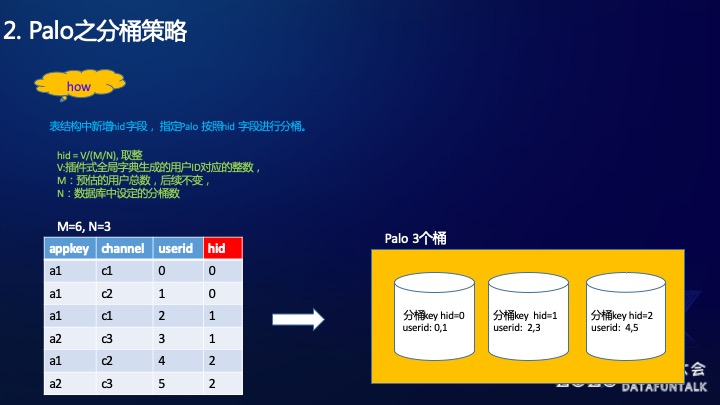
我们的方案如下:
首先我们在表中增加了hid的字段,并且让Palo用hid进行分桶。
hid有一个算法:
hid = V/(M/N), 取整
V: 插件式全局字典生成的用户ID对应的整数
M:预估的用户总数,后续不变
N:数据库中设定的分桶数如图,用户总数为6,M=6。分桶数为3,N=3。
这样就将userid和hid做了对应,在用hid做分桶的时候,就可以保证桶内的连续。
Palo之用户画像标签优化
以上讲到的全局字典和分桶策略是通用的策略,是在做Bitmap时必须要考虑到的。但是只考虑这两点还不能达到性能的最优,还要结合实际的业务对业务进行优化。以下就是我们的具体业务——画像标签的存储优化。
画像标签优化也是用来解决难点二——查询频响要求高。
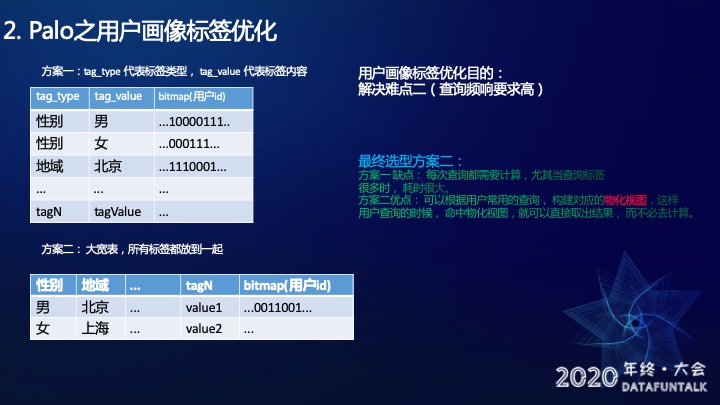
当时有两个方案,方案一是用tag_type和tag_value。tag_value用来记录标签的类型,tag_value用来记录标签的内容。方案二是将所有标签放入一个宽表中。
我们选择了方案二。因为方案一是一个标签对应一个用户,如果我想选取“性别男”,地域在“北京”的用户,就需要把两部分用户做一个union,有一定的计算量,会更耗时。如果用方案二,可以根据用户常用的查询,构建对应的物化视图,这样用户查询的时候,命中物化视图,就可以直接取出结果,而不必去计算,可以减少耗时。
在使用Palo的时候,大家要尽量命中前缀索引和物化视图,这样会大大提升查询效率。
Palo之动静组合查询
动静组合查询主要是解决难点三——计算复杂。
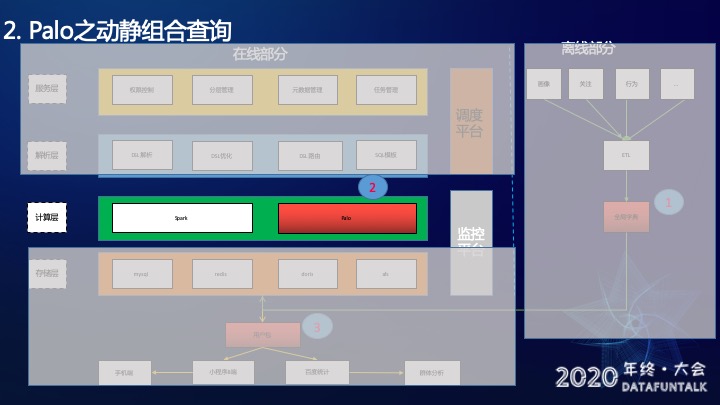
静态查询是用户维度是固定的,可以进行预聚合的。比如“男性用户”,这就是一个固定的群体,无论怎么查这部分用户是不会变的。动态查询是偏向一些行为的,会根据用户的不同而不同。比如“近30天收藏超过3次的用户”,或“近30天收藏超过4次的用户”,这种查询无法进行预聚合,所以称为动态的查询。

小程序用户分层相比于同类型的用户分层功能,增加了用户行为筛选(这也是小程序产品的特点之一),比如近30天用户支付订单超过30元的男性,20~30岁用户。其中近30天用户支付订单超过30元用户是Bitmap表无法记录的,也不能提前预计算好,只能在线去算。
这里的难点是,如何进行非Bitmap表和Bitmap表的交并补集运算?
结合上面的例子,我们的解决方法是将查询查分成四步。
Step1 先查20-30岁的男性用户,这部分直接查Bitmap表就行。
Step2 查询近30天用户支付订单超过30元用户,这步需要去查行为表获取用户ID。
Step3 将用户ID跟在线Bitmap的转化,Doris提供了一个bitmap_union(to_bitmap(id)) 功能,可以在线将用户id 转换成bitmap。
Step4 是将Step1和Step3的结果求交集。
这里的重点是Step3,Palo提供了to_bitmap的功能,帮我们解决了Bitmap表和非Bitmap表的联合查询的问题。
3.1.3 如何快速产出用户包
快速产出用户包是为了解决难点四——产出用户包要求时效性高。
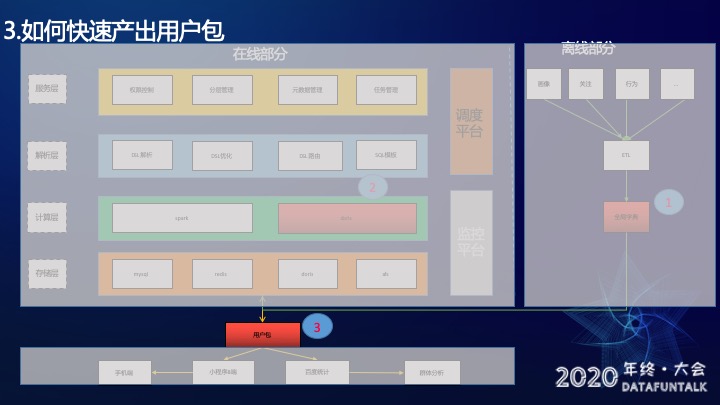
同样有两个方案,方案一是用调度平台+Spark。分成三步,首先产出分层用户cuid,然后产出用户uid,最后回调更新。方案二是用调度平台+solo,执行DAG图是用solo产出cuid、uid和回调,这里的solo是百度云提供的Pingo单机执行引擎,类似一个虚拟机。

方案一由于Spark自身yarn调度耗时,加上如何队列资源紧张需要延迟等待等原因,即使产出0个用户,也需要30分钟才能跑完。
方案二我们利用了百度Palo的SELECT INTO OUTFILE产出结果导出功能:查出的用户直接导出到afs上,百万级用户产出小于3分钟。
最终我们选择了方案二,因为Palo相比于Spark导出结果到afs更快。
3.2 收益
Palo的用户存储方案还是非常有效的,整体方案的收益如下图所示:

百度数据仓库Palo
基于 Apache Doris 的企业级数据仓库托管服务
全新UI支持,更有新用户0元试用3个月优惠活动
登陆百度智能云官网搜索Palo,马上试用!
https://cloud.baidu.com/product/palo.html

发表评论
登录后可评论,请前往 登录 或 注册