【动手学PaddlePaddle2.0系列】PP-YOLO详解(1)-- backbone
作者:沙与沫2021.01.27 03:38浏览量:640简介:本次教程将带领大家实战开启目标检测任务中经典的YOLO系列算法:PP-YOLO。对算法感兴趣的同学不要错过,另外有对课程的建议,也欢迎提出。
PP-YOLO详解(1)-- backbone
大家好,本次教程将带领大家开启PP-YOLO学习。通过前面一系列学习,相信大家已经掌握了图像分类任务的基本概念以及相关实践,下面将带大家实战目标检测任务中经典的YOLO系列算法:PP-YOLO。
本次将对使用的backbone网络:ResNet50-vd-dcn,进行讲解。
下载安装命令 ## CPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/cpu paddlepaddle ## GPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/gpu paddlepaddle-gpu
1 ResNet_D
Resnet_vd最早是在Bag of Tricks for Image Classification with Convolutional Neural Networks,这篇文章中提出了很多非常实用的训练技巧,我会在后面专门出一期教程对这些技巧进行详细讲解。
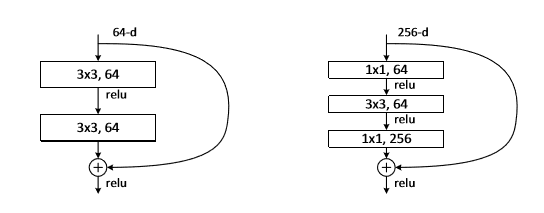
对于ResNet网络来说,最核心的部分即跳跃连接结构,其分为两种BasicBlock、BottleneckBlock,
 ,
,
在这里,我们只关心BottleneckBlock这个结构,在论文中,对该结构做了如下改进:

需要注意的是每个结构中输入和输出的连接方式,在resnet_c中,改进的地方为模型开始的7 * 7卷积层,使用了连续的3 * 3 卷积层进行了替代。在论文中主要针对BottleneckBlock进行了改进。原始的BottleneckBlock如下所示:
1.1 代码讲解
代码来源于paddle2.0rc官方API文档源码,传送门,通过阅读源码,发现这里直接实现了resnet_vb结构,即下采样放在了第二个卷积(3 * 3)上,没有放在第一个卷积(1 * 1)上。并且paddleclas中,对resnet的定义也是使用了resnet_vb结构。
1.1.1 ResNet_B详解
class BottleneckBlock(nn.Layer):
def __init__(self,
num_channels,
num_filters,
stride,
shortcut=True,
name=None,
data_format="NCHW"):
super(BottleneckBlock, self).__init__()
self.conv0 = ConvBNLayer(
num_channels=num_channels,
num_filters=num_filters,
filter_size=1,
act="relu",
name=name + "_branch2a",
data_format=data_format)
self.conv1 = ConvBNLayer(
num_channels=num_filters,
num_filters=num_filters,
filter_size=3,
stride=stride,
act="relu",
name=name + "_branch2b",
data_format=data_format)
self.conv2 = ConvBNLayer(
num_channels=num_filters,
num_filters=num_filters * 4,
filter_size=1,
act=None,
name=name + "_branch2c",
data_format=data_format)
if not shortcut:
self.short = ConvBNLayer(
num_channels=num_channels,
num_filters=num_filters * 4,
filter_size=1,
stride=stride,
name=name + "_branch1",
data_format=data_format)
self.shortcut = shortcut
self._num_channels_out = num_filters * 4
def forward(self, inputs):
y = self.conv0(inputs)
conv1 = self.conv1(y)
conv2 = self.conv2(conv1)
if self.shortcut:
short = inputs
else:
short = self.short(inputs)
y = paddle.add(x=short, y=conv2)
y = F.relu(y)
return y
在这里,不再对resnet中原始的BottleneckBlock进行赘述,直接使用飞桨官方给出的代码。对于想要尝试原始的BottleneckBlock的同学,只需将第二个卷积中的stride换到第一个卷积中即可。
1.1.2 ResNet_C详解
self.conv1_1 = ConvBNLayer(
num_channels=3,
num_filters=32,
filter_size=3,
stride=2,
act='relu',
name="conv1_1")
self.conv1_2 = ConvBNLayer(
num_channels=32,
num_filters=32,
filter_size=3,
stride=1,
act='relu',
name="conv1_2")
self.conv1_3 = ConvBNLayer(
num_channels=32,
num_filters=64,
filter_size=3,
stride=1,
act='relu',
name="conv1_3")
self.conv = ConvBNLayer(
num_channels=self.input_image_channel,
num_filters=64,
filter_size=7,
stride=2,
act="relu",
name="conv1",
data_format=self.data_format)
1.1.3 ResNet_D详解
class ConvBNLayer(nn.Layer):
def __init__(self,
num_channels,
num_filters,
filter_size,
stride=1,
groups=1,
is_vd_mode=False,
act=None,
lr_mult=1.0,
name=None):
super(ConvBNLayer, self).__init__()
self.is_vd_mode = is_vd_mode
self._pool2d_avg = AvgPool2D(
kernel_size=2, stride=2, padding=0, ceil_mode=True)
self._conv = Conv2D(
in_channels=num_channels,
out_channels=num_filters,
kernel_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
groups=groups,
weight_attr=ParamAttr(
name=name + "_weights", learning_rate=lr_mult),
bias_attr=False)
if name == "conv1":
bn_name = "bn_" + name
else:
bn_name = "bn" + name[3:]
self._batch_norm = BatchNorm(
num_filters,
act=act,
param_attr=ParamAttr(name=bn_name + '_scale'),
bias_attr=ParamAttr(bn_name + '_offset'),
moving_mean_name=bn_name + '_mean',
moving_variance_name=bn_name + '_variance')
def forward(self, inputs):
if self.is_vd_mode:
inputs = self._pool2d_avg(inputs)
y = self._conv(inputs)
y = self._batch_norm(y)
return y
1.2 ResNet_D总结
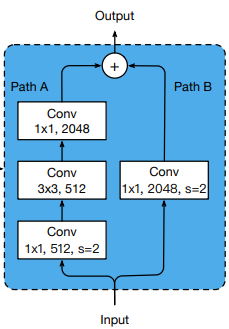
在原始的ResNet中,如图所示,Path A的第一个1 x 1卷积层使用了strde=2的步长,会导致3/4的信息丢失。因此ResNet-B将第一、二个卷积层的步长交换。实验表明ResNet-B 有0.5%的性能提升。
因为卷积的代价会随着卷积核的长和宽增大而接近平方增加,因此ResNet-C使用3个连续的3 x 3 卷积替换Input stem的7 x 7 卷积。实验表明ResNet-C 有0.2%的性能提升。
ResNet-D在ResNet-B的基础上进一步调整,在Path B的1 x 1卷积前面,加入2 x 2 stride 2的pooling层,将下采样提前,避免了3/4的信息丢失。实验表明ResNet-D 有0.3%的性能提升。
上述中均来自于论文中的论述。实际上这里还存在着一个问题,为什么在Path A中将下采样提前就会避免信息丢失。(目前我也对这部分存在疑问,找到答案后会对此进行阐述)
对于ResNet-C使用3个连续的3 x 3 卷积替换Input stem的7 x 7 卷积,我自己的理解有两方面的好处,
(1)感受野相同,(2)减少参数量。
ResNet-D同ResNet-B中Path A中相同处理的办法相同,同样将下采样提前,避免信息丢失。
下载安装命令 ## CPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/cpu paddlepaddle ## GPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/gpu paddlepaddle-gpu
一点小小的宣传&下期预告
下一个项目中将为大家介绍在Paddle2.0中DCN 是如何实现的,并且对代码详解。欢迎大家关注哦。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册