基于百度云的 GPU 实例实现 GPU 加速 Apache Spark 3.x 系列1:概览与环境搭建
2021.03.05 12:35浏览量:1549简介:GPU可以实现对Spark SQL的加速
Apache Spark简介
Apache Spark 是在当前数据分析领域处于领先地位的分布式、可扩展的快速通用分析引擎。它从Hadoop手中接过数据处理的光环,主要是源自于它对数据处理过程具有明显的性能加速。通用性的设计让它可以在Haddop、Apache Mesos、Kubernetes上运行,同时还可以以本地模式(local mode)独立运行;此外,国内外主流的云服务提供厂商也提供了通用大数据处理平台对Spark的集成,使得在云上直接调用Spark集群成为一种便利的方式。
Spark提供和很多高级运算符,开发人员可以使用交互式的shell,notebook或jar 包的方式使用Scala、Python、R、SQL等语言轻松构建数据处理的过程。
Spark 3.x与GPU加速的Spark过程
Spark 3.0版本之前的数据处理
始于21世界之初的Hadoop时代,将横向拓展的方式带入到了数据分析处理中。之后在2009年,Spark通过添加in-memory的数据处理方式和更强大的编程模型取得了当时最先进的加速效果。不过在端到端的分析流程中,通常仍是有70%的时间是用于数据处理的。
在Spark 3.0之前的版本,一直都是使用CPU进行数据处理的,而CPU性能增长的速度一直远低于数据处理的要求。同时,在Spark3.0之前的版本,实现横向的基础设施的扩展是相对比较可行的解决方案。也正是因为如此,才造成了我们如下图中所示的差距。当前最紧要的形式是需要改变计算性能的轨迹从而满足对需要处理数据的规模上的需求。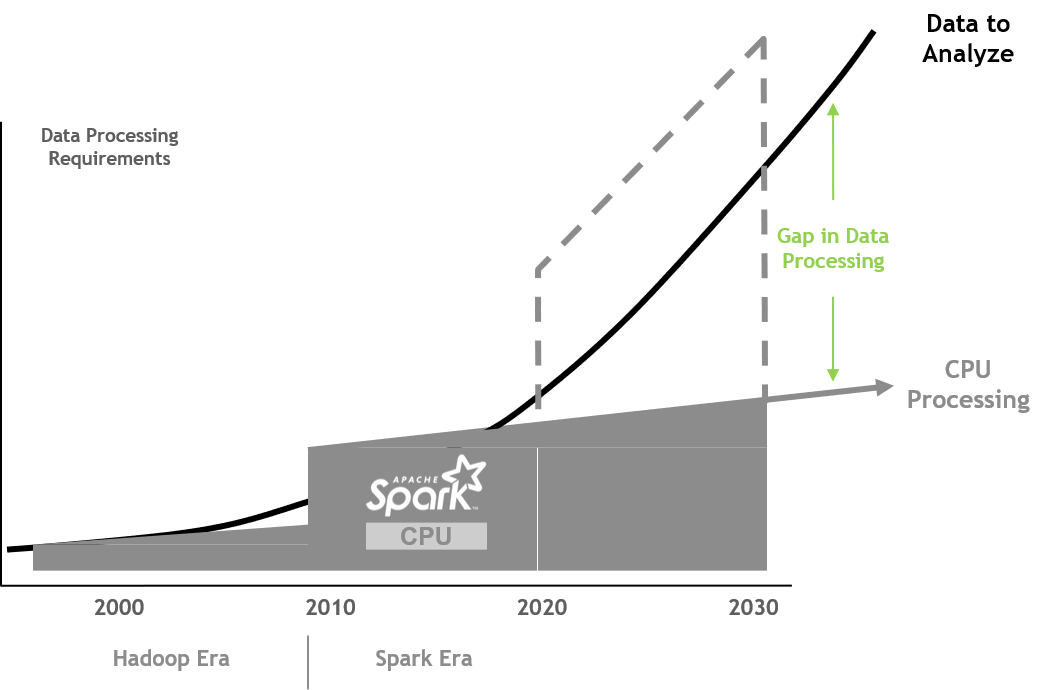
Spark 3 的新特性
Spark 3.0 开始增加了许多新特性,比如端到端的ETL & DL/ML 的Pipeline,用于SQL的Adaptive Query Execution(AQE), Dynamic Partition Pruning(DPP), 提升了对Graph的支持,对Kubernetes提供了更好的支持,提升了对语言的支持,此外一个比较特殊的性质就是使GPU成为第一梯队用于加速。
针对GPU具体的提升方面:
- 增加了对加速器 (GPU) 感知的调度
- 利用原生的Spark API实现发现、请求并赋予加速器资源
- 支持YARN,Kubernetes 和 Standalone三种集群调度方式
- 针对加速器 (GPU) 采用列式数据处理
- 具有处理行列数据方向的高效机制
GPU加速Spark 3.x
为了满足和超越现代数据处理的要求,GPU加速在Spark 3.0 版本中被引入。
从2020年的夏天开始,Spark3.0 可以通过横向扩展的方式使用RAPIDS和NVIDIA的GPU进行加速。这为数据处理,模型的训练和推理工作提供了及时的性能提升,允许数据科学家、企业、组织等以数据为驱动。
此外,GPU的性能同比增长明显超过CPU,以满足未来数据的处理需求,改变了我们可用的处理能力的轨迹。
利用Spark 3.x 与NVIDIA GPU的基础架构,数据科学的流程可以不用进行代码层面上的更改即可实现加速。NVIDIA GPU 加速 Spark 3.x主要有以下三点优势:
- 更快的执行时间
Spark 3.x 利用GPU可以加速数据处理的任务性能,从而可以快速地进入整个流水线中的下一个阶段,这是的模型可以以更快的速度被训练,给数据科学家及工程师带来更多的时间用于关注核心问题。 - 对AI的流式化分析
Spark 3.x协调了从数据获取,到模型训练再到可视化的端到端的流水线。同一个GPU加速的基础架构可以用来进行 Spark 的数据处理和机器学习/深度学习的框架使用,消除了每个部分需要使用独立的集群这样的一个限制,允许整个流水线均使用GPU进行加速 - 减少基础架构带来的开销
少花钱、多办事:与CPU相比,NVIDIA GPU上的Spark以更少的硬件能够更快地完成任务,节省了配置时间以及在云上的内部资本成本和运营成本。
GPU加速在Spark 3.x上的革新
在Spark 3.x的加速上,Spark 3.x中有三个关键步骤实现了GPU加速的透明化:
- Spark 3.x的 RAPIDS 加速器
NVIDIA CUDA是一个支持在GPU上实现并行计算的统一架构。RAPIDS是基于CUDA孵化出的一套开源代码,一个最主要的功能就是用于数据科学的GPU加速流水线的操作。NVIDIA为Spark 3.x创建了一个RAPIDS 加速器,通过显著提高Spark SQL和DataFrame的操作的性能来截取并加速ETL的流水线。 - Spark 组件的改装
在Catalyst 查询优化器 (query optimizer) 中, Spark 3.x 加入了列式处理的支持。RAPIDS 加速器把这个优化器插入,用以加速SQL和DataFrame操作。当查询计划执行时, 这些算子可以在Spark集群内的GPU上运行。此外,NVIDIA 还创建了一个新的Spark Shuffle的实现。它优化了Spark进程之间的数据传输,这个Shuffle实现基于GPU加速通信库,包括UCX,RDMA和NCCL。 - Spark中基于GPU的感知调度
Spark 3.x 会将GPU与CPU以及系统内存一起视为第一季资源。这样允许Spark 3.x将GPU加速的工作负载直接放到包含GPU资源的服务器上,因为这些资源是加速和完成任务所必须的。这其中就涉及到上面提及的Spark 3.0 协同GPU支持Standalone,YARN和Kubernetes等三种集群调度方式。
RAPIDS 加速器加速 Spark 3.x 中的SQL
在Spark 3.x 中我们以插件的形式,使用 Spark-RAPIDS 加速器来对 Spark 进行GPU上的加速操作。目前这个插件的版本的0.4版已经可以在github上面访问了。 Spark-RAPIDS 加速器针对原Spark CPU上的算子进行操作,如果算子可以被GPU加速,则将在GPU上被加速;否则,算子依然执行在CPU上,而终端用户由于使用的代码是没有变化的因而对该过程是无感知的。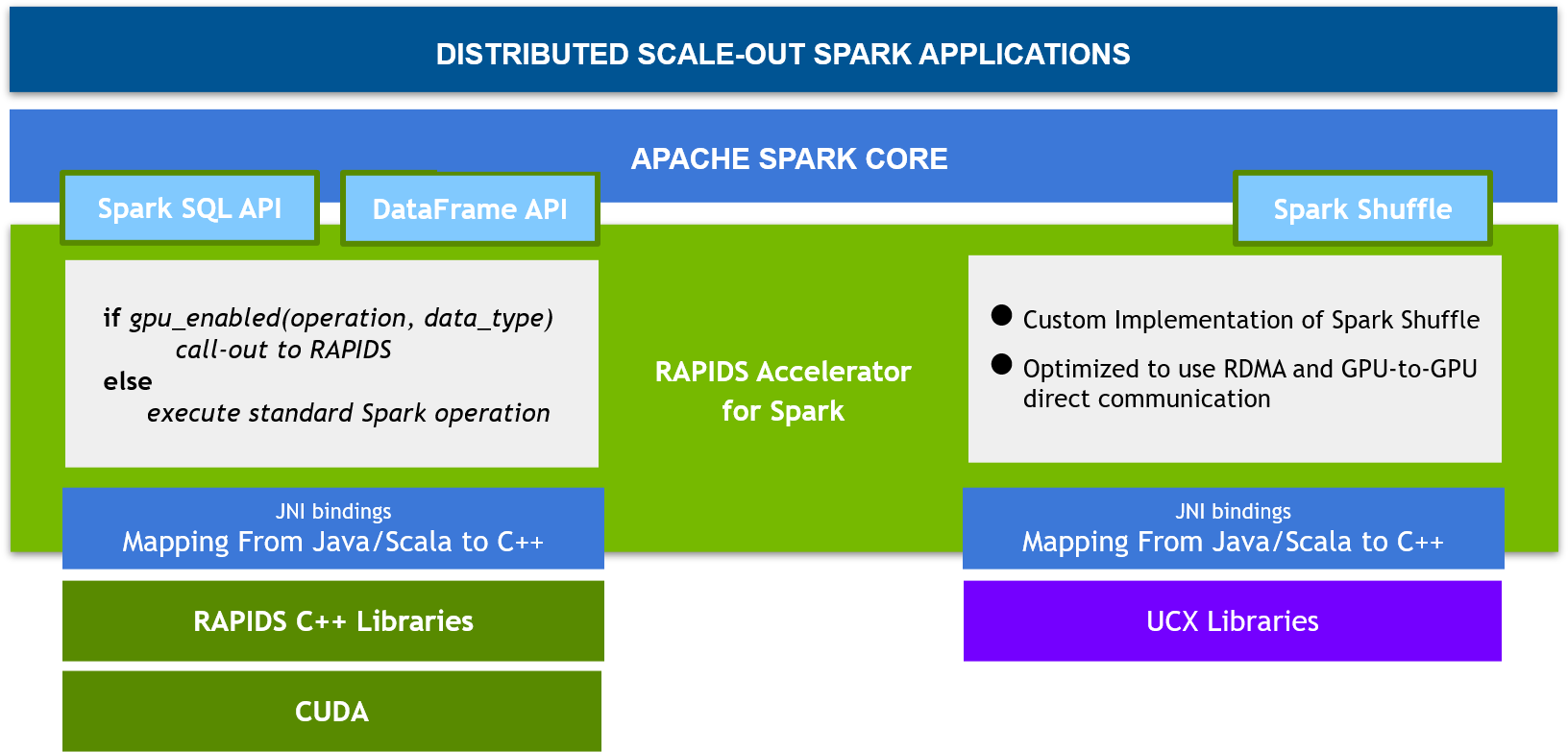
Spark-RAPIDS 插件也在不断的扩充对算子的支持,陆续会有更多的算子能够在GPU上实现更好的加速,目前支持的算子情况可以参考这里。
利用百度云GPU实例安装Spark 3.x 及其Spark-RAPIDS插件
如上面提到,Spark 3.x + Spark-RAPIDS 支持Kubernetes,Standalone和YARN的集群装配方式。这里我们以单实例的Standalone的方式为例,在百度智能云的GPU实例上进行安装和测试。
选择百度智能云上的GPU实例
进入百度智能云的云服务器页面:https://cloud.baidu.com/product/gpu.html
选择 购买GPU云服务器,进入GPU实例购买页面: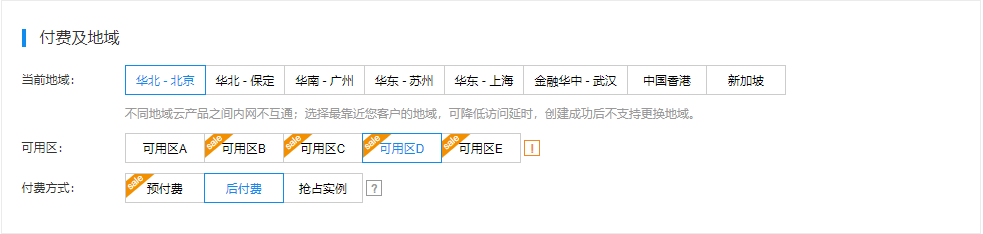
百度智能云上面会分成多个分区,用户可以根据自身地理位置选择离自己最近的地域。付费方式方面,有三种:预付费,后付费,抢占实例。预付费往往是按照月、年的方式进行实例的购买,后付费则是以实例的申请按照小时进行计费。如果对资源的使用量大的话,建议购买预付费的方式,这样相对来说更划算。抢占实例也算作一种后付费的方式,但由于实例本身是以抢占的形式申请,很有可能在资源不足的时候被迫下线。再者,抢占实例的方式通常是针对CPU实例的,目前没有可用GPU实例。
这里我们选择后付费的方式作为例子来使用。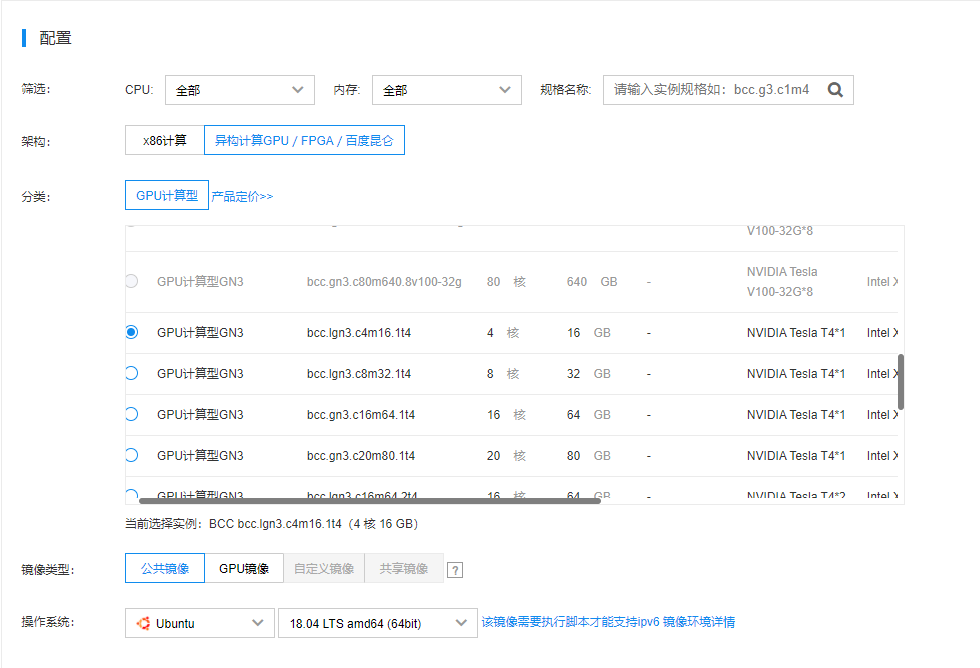
我们选一个T4的实例,同时配有4个CPU核心和16GB的系统内存。镜像选择上,百度智能云提供了多种GPU镜像的组合,但是为了契合最新版本的驱动和Spark程序,我们选择自行安装,因而选择公共镜像中的Ubuntu 18.04版本。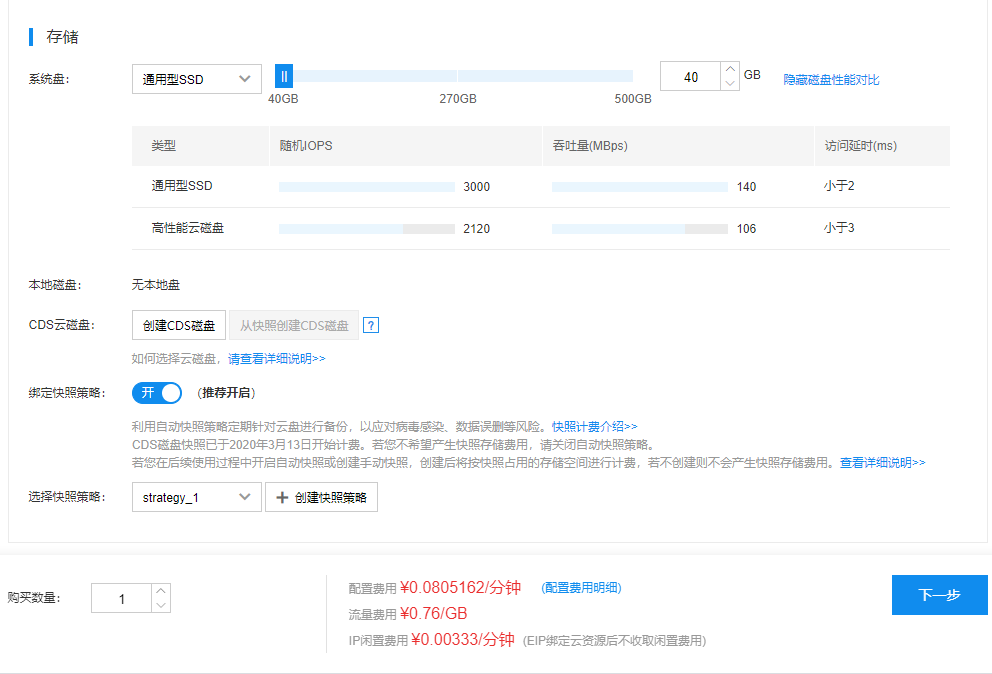
接下来是存储相关的配置,百度智能云的默认选项是采用的通用型的SSD存储,这对Spark程序来说是一件非常有利的事情,因为可以加速本地磁盘的数据读取。
网络和带宽可以根据自身情况进行配置,我们这里作为例子采用的是使用公网IP便于访问,同时使用流量计费的方式。
其余设定,用户均可根据自身情况即可。点击确认购买之后会生成一张配置表格,用户二次确认之后即可完成订单的提交。
创建成功之后,在控制面板中找到实例: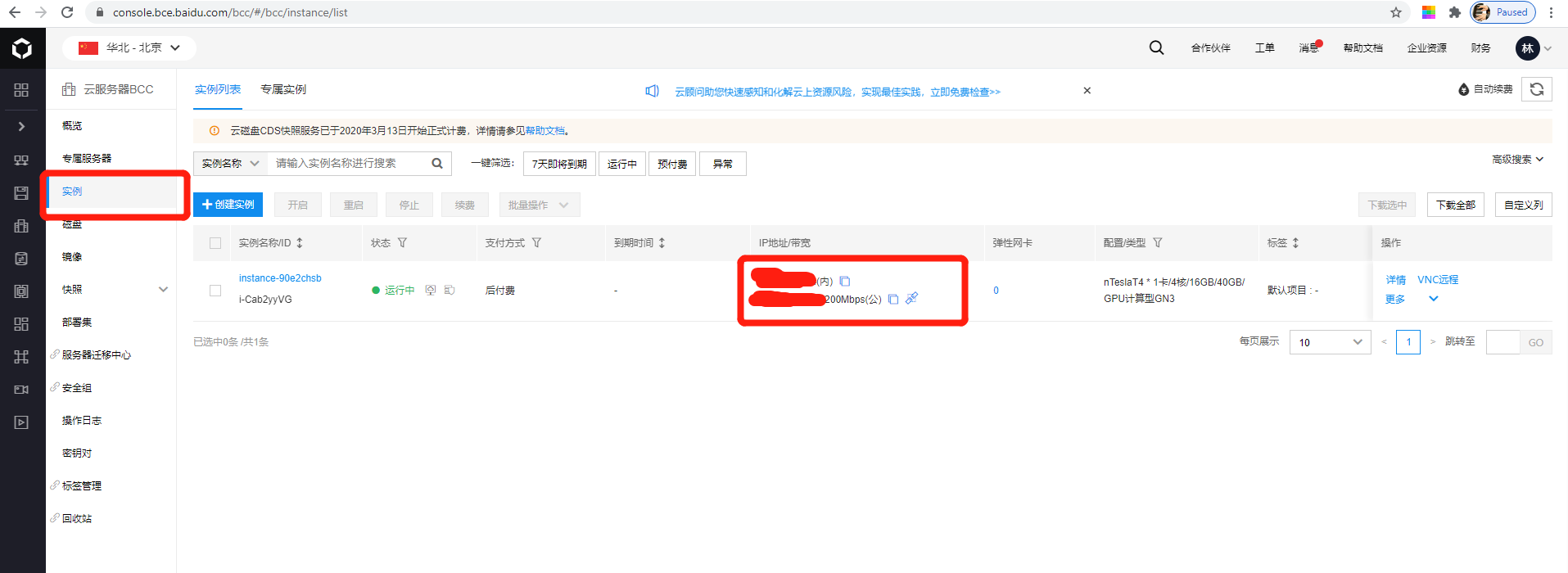
如图,内网和公网IP则创建成功。
配置GPU实例环境
使用远程ssh登录软件连接我们已经购买完成的实例,并输入密码。
$ssh root@public_IP_address
安装GPU驱动
由于我们即将安装的Spark-RAPIDS插件的最新版本可以支持CUDA 11.0,因此我们选择与该CUDA版本对应的驱动程序。
进入GPU驱动下载页面,选择相应的版本。这里我们安装的CUDA 11.0, Ubuntu 18.04 操作系统,GPU实例为T4的GPU,界面如下: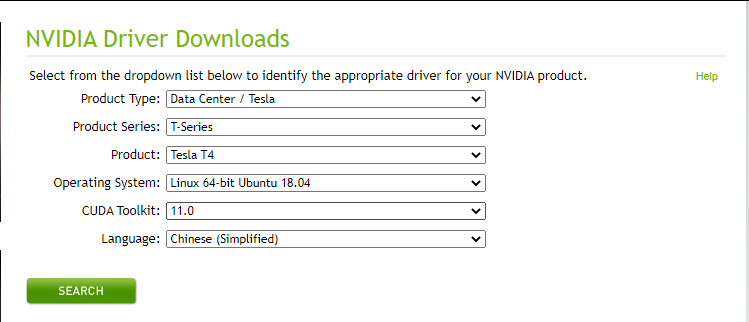
将下载好的驱动上传至刚刚建立好的实例中,按照如下步骤进行安装:
$dpkg -i nvidia-driver-local-repo-ubuntu1804-450.102.04_1.0-1_amd64.deb
$sudo apt-key add /var/nvidia-driver-local-repo-ubuntu1804-450.102.04/7fa2af80.pub
$apt update
$apt-get install cuda-drivers
安装过程持续时间比较长,成功之后,重启百度智能云实例即可。
重启之后在命令行中输入nvidia-smi,有检测到百度智能云上的GPU即说明驱动安装成功。
CUDA 安装
匹配最新版本的Spark-RAPIDS插件,我们安装CUDA 11.0的版本,CUDA软件的获取可以参考这里。我们选择CUDA Toolkit 11.0 Update 1:
我们选择如下匹配版本进行下载:
CUDA的安装过程按照提示即可:
$wget https://developer.download.nvidia.com/compute/cuda/11.0.3/local_installers/cuda_11.0.3_450.51.06_linux.run
$sudo sh cuda_11.0.3_450.51.06_linux.run
注意,由于我们之前已经安装过了驱动,因此在安装CUDA的过程中需要取消驱动的安装: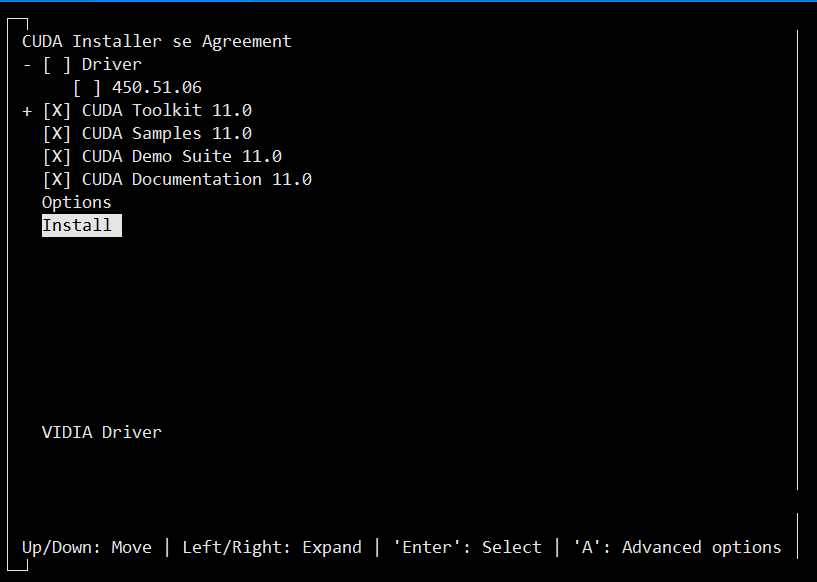
安装成功之后,我们需要将可执行命令和动态链接库加载到相应的环境变量中。
$export PATH=$PATH:/usr/local/cuda-11.0/bin
$export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.0/lib64
安装Standalone方式的Spark及其GPU 加速加速插件Spark-RAPIDS
安装Java 8
$apt install openjdk-8-jdk-headless
下载Spark 3.0.0 版本的安装包
$wget https://archive.apache.org/dist/spark/spark-3.0.0/spark-3.0.0-bin-hadoop3.2.tgz
下载Spark-RAPIDS的两个jar包
- rapids-4-spark_2.12-0.3.0.jar
$wget https://repo1.maven.org/maven2/com/nvidia/rapids-4-spark_2.12/0.3.0/rapids-4-spark_2.12-0.3.0.jar - cudf-0.17-cuda11.jar
$wget https://repo1.maven.org/maven2/ai/rapids/cudf/0.17/cudf-0.17-cuda11.jar
创建环境变量并将下载的jar包传至相应的位置
$export SPARK_RAPIDS_DIR=/opt/sparkRapidsPlugin
$export SPARK_CUDF_JAR=${SPARK_RAPIDS_DIR}/cudf-0.17-cuda11.jar
$export SPARK_RAPIDS_PLUGIN_JAR=${SPARK_RAPIDS_DIR}/rapids-4-spark_2.12-0.3.0.jar
$mkdir -p $SPARK_RAPIDS_DIR
$mv cudf-0.17-cuda11.jar $SPARK_RAPIDS_DIR/
$mv rapids-4-spark_2.12-0.3.0.jar $SPARK_RAPIDS_DIR/
下载GPU感知脚本
从这里下载GPU感知脚本 getGpusResources.sh ,并将该脚本放到 $SPARK_RAPIDS_DIR 下面,并增加脚本的可执行权限。
chmod +x getGpusResources.sh
解压Spark安装包
将前面下载好的spark-3.0.0-bin-hadoop3.2.tgz的安装包进行解压,并将解压后的文件放到Spark的执行位置,这里我们将解压后的文件放到/opt/spark下面
$tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz
$mkdir -p /opt/spark
$cp -r spark-3.0.0-bin-hadoop3.2 /opt/spark
同时配置Spark的家目录到指定的环境变量:
$SPARK_HOME=/opt/spark/spark-3.0.0-bin-hadoop3.2
启动Spark Master节点脚本
在百度智能云的GPU实例中,执行Spark的Master启动脚本
$$SPARK_HOME/sbin/start-master.sh
启动之后,会有类似于如下的输出产生
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/spark-3.0.0-bin-hadoop3.2/logs/spark-root-org.apache.spark.deploy.master.Master-1-instance-90e2chsb.out
后面/opt/spark/spark-3.0.0-bin-hadoop3.2/logs/spark-root-org.apache.spark.deploy.master.Master-1-instance-90e2chsb.out 的位置为输出的日志,查看这个日志我们就可以知道master节点是否成功启动了,或者还可以通过访问Spark的页面,即 公网IP:8080 是否有正常如下的页面显示:
出现以上页面说明spark的节点开启成功。
启动Spark Worker节点并配置相应的GPU参数
我们先来配置让Spark能够发现GPU的参数:
cp $SPARK_HOME/conf/spark-env.sh.template $SPARK_HOME/conf/spark-env.sh
修改spark-env.sh里面的参数
SPARK_WORKER_OPTS="-Dspark.worker.resource.gpu.amount=1 -Dspark.worker.resource.gpu.discoveryScript=/opt/sparkRapidsPlugin/getGpusResources.sh"
注意:此处我申请的百度智能云的GPU实例是一块T4的GPU卡,所以spark.worker.resource.gpu.amount设置的是1,安装的过程中,需要根据每个worker节点中GPU卡的数量的多少来设置这个参数。
接下来我们启动worker节点
$$SPARK_HOME/sbin/start-slave.sh spark://[公网IP]:7077
和Master节点启动的方式一样,我们可以查看输出指定的日志位置,查看日志内容确定是否启动成功,也可以回到web界面的位置:
可以看到,worker节点成功启动,并且成功发现GPU资源。
启动Spark,并进行简单验证
启动Spark应用,同时可以根据这里提供的参数进行配置Spark的启动:(下面的参数配置仅是一个例子)
$SPARK_HOME/bin/spark-shell --master spark://[公网IP地址]:7077 \
--conf spark.executor.extraClassPath=${SPARK_CUDF_JAR}:${SPARK_RAPIDS_PLUGIN_JAR} \
--conf spark.rapids.sql.concurrentGpuTasks=1 \
--driver-memory 2G \
--conf spark.executor.memory=4G \
--conf spark.executor.cores=4 \
--conf spark.task.resource.gpu.amount=0.25 \
--conf spark.rapids.memory.pinnedPool.size=2G \
--conf spark.locality.wait=0s \
--conf spark.sql.files.maxPartitionBytes=512m \
--conf spark.sql.shuffle.partitions=10 \
--conf spark.plugins=com.nvidia.spark.SQLPlugin \
--jars ${SPARK_RAPIDS_PLUGIN_JAR},${SPARK_CUDF_JAR} \
--conf spark.executor.resource.gpu.amount=1
注意:
- 到目前为止,我们通常设定一个executor的GPU为一个,即
spark.executor.resource.gpu.amount=1,不要试图用多个GPU去配置executor - 一个executor中可以有多个task。
开启界面之后如下: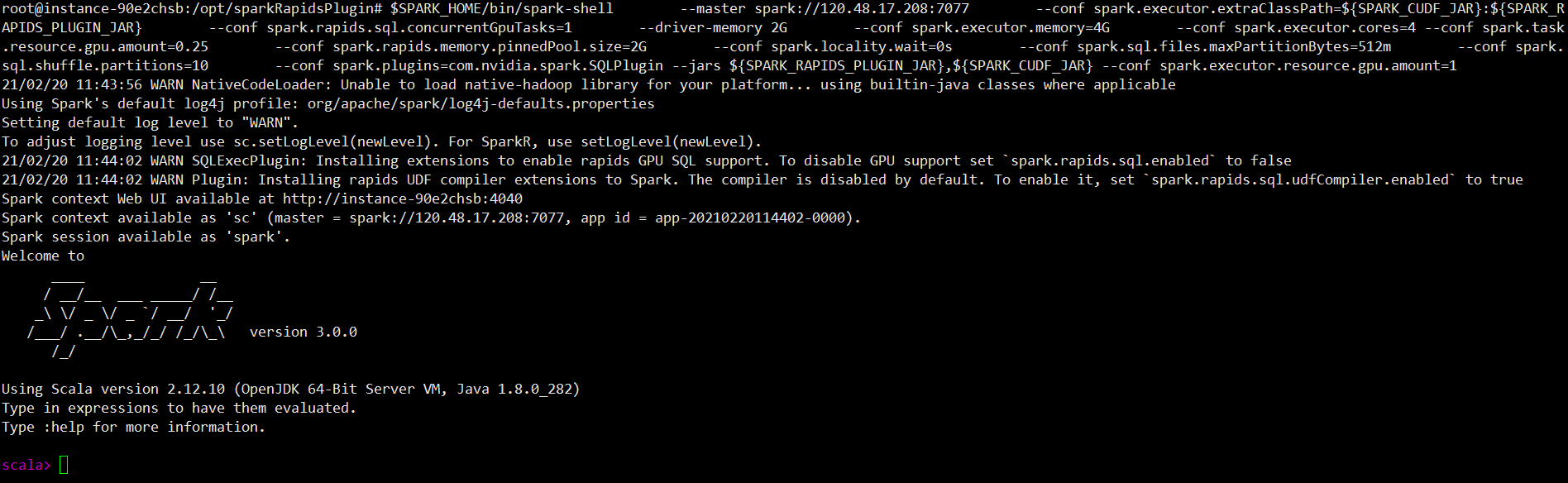
可以用如下的例子进行简单验证: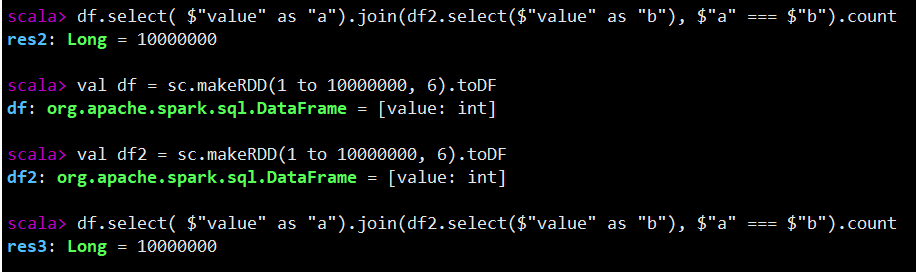
更多信息
Spark-RAPIDS 项目 GitHub 链接:https://github.com/NVIDIA/spark-rapids
Spark-RAPIDS 项目主页:https://nvidia.github.io/spark-rapids/
Spark-RAPIDS NVIDIA 官方主页:https://www.nvidia.com/en-us/deep-learning-ai/solutions/data-science/apache-spark-3/
Spark-RAPIDS GTC China 2020 上的内容介绍:https://on-demand-gtc.gputechconf.com/gtcnew/sessionview.php?sessionName=cns20960-%e4%bd%bf%e7%94%a8+rapids+%e5%8a%a0%e9%80%9f+apache+spark+3.0
Spark-RAPIDS 电子书下载页面:https://www.nvidia.com/en-us/deep-learning-ai/solutions/data-science/apache-spark-3/ebook-sign-up/

发表评论
登录后可评论,请前往 登录 或 注册