百度安全 Rust TrustZone SDK 正式成为 Apache Teaclave 子项目
2021.03.17 18:50浏览量:1265简介:百度安全 Rust TrustZone SDK 赋能多平台隐私安全计算开源生态
导读:百度搜索中台系统不但承接了搜索的阿拉丁流量,也致力于构建各个垂直业务的搜索能力。随着业务的不断发展,系统的流量规模已经达到百亿级别。而在百亿流量的背后,是千级别的微服务模块和数十万的实例数量,如何保证这套复杂系统的高可用、高性能和高可控,全要素多维度的可观测性成为搜索中台系统能力的关键。
本文首先会介绍什么是可观测性以及云原生时代为什么更要关注可观测性,然后阐述搜索中台是如何以极低的机器成本打造百亿流量的实时指标监控(Metrics)、分布式追踪(Traces)、日志查询(Logs)和拓扑分析(Topos)。
一、云原生和可观测性(Observability)
1)什么是可观测性
大家对监控并不陌生,只要有系统存在,就需要有监控帮我们去感知系统发生的问题。而随着业界传统技术架构往云原生架构的迈进,可观测性逐渐在越来越多的场合中被提到。如Distributed Systems Observability、Monitoring in the time of Cloud Native等都是对分布式系统可观测性的一些解读。在CNCF的云原生定义中,也将可观测性当成云原生架构很重要的一个特性CNCF CloudNative Definition 1.0。
可观测性是监控的一个超集。监控关注的是一些具体指标的变化与报警,而可观测性不仅需要提供对分布式系统所有链路运行状况的高级概览,还需要在系统发生问题时提供系统链路细化的分析,让开发和运维同学“理解”系统发生的一切行为。
目前,业界广泛推行可观测性的基本要素包括:
- 指标监控(Metrics)
- 分布式追踪(Traces)
- 日志查询(Logs)
经过一些实践之后,我们还拓展了一个要素:拓扑分析(Topos)。「分布式追踪」是从微观角度去看一个请求的完整链路,而「拓扑分析」是从宏观角度去分析问题。比如某个服务 Qps 比平时扩大了数倍,我们需要定位异常流量的源头,就依赖拓扑分析工具。
2)云原生架构下可观测性的必要性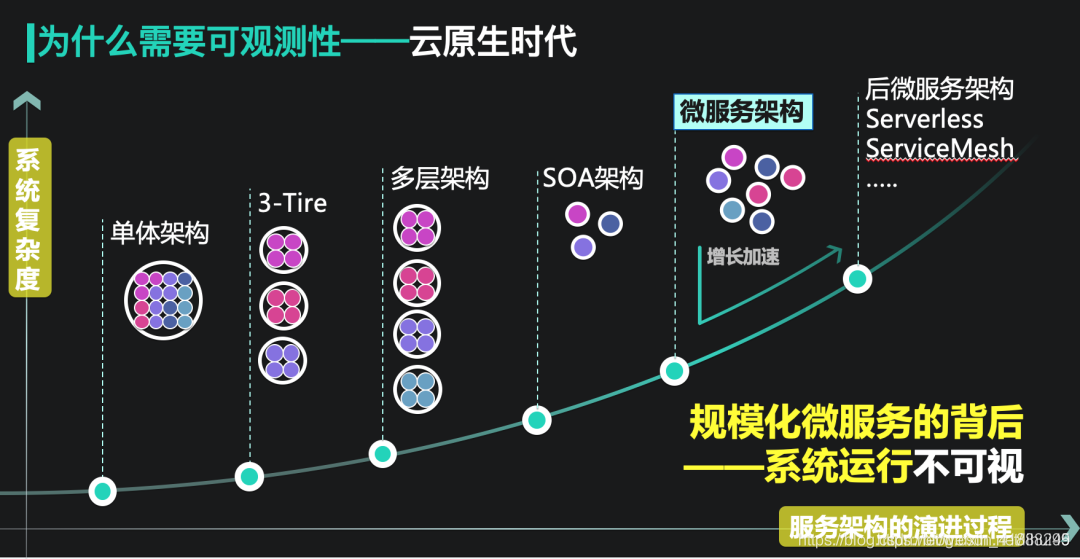
在云原生时代,传统的服务架构和研发运维模式正在进行着范式转变。微服务、容器化、FAAS(serverless)等技术从根本上改变了应用的研发模式和运维方式。但是,云原生架构在带来业务迭代效率指数级提升的同时,也产生了一些新的挑战。从单体应用往微服务进行的转变导致原本聚焦的系统变得分散,服务与服务之间连接的复杂度迅速提高,我们对系统整体的掌控力也在逐渐变弱。在这种情况下,如何去快速定位异常,做到系统的清晰可视,就成为了亟需解决的问题。
二、我们面临的挑战
1)超大系统规模
随着微服务化等技术的使用和新业务的接入,百度搜索中台的服务和实例规模不断增加,服务间的链路关系也日趋复杂,在这样一个庞大系统中建设可观测性,也面临着更多的挑战。
对于日志的trace来说,目前搜索中台天级别的请求量已经达到了百亿级别,如果使用常规的技术方案(如Dapper的思路),将日志放到集中式存储里,意味着我们要付出上百台机器资源,成本是非常高昂的。部分团队使用抽样或针对错误请求进行记录的方式,这种方式在搜索中台场景存在着明显问题:一. 抽样无法保证覆盖线上case。二. 很难有一种有效的方法识别错误请求,此外,用户对一些正常请求仍然有trace需求(如误召回问题)。
同样地,对于指标的数据聚合来说,在超大系统规模下,如何优化资源占用和时效,也是一个极具挑战的问题。
2)从应用到场景的观测要求
随着搜索中台业务场景的不断丰富,我们的观测视角也在发生着变化。过去更多关注的是应用维度的信息,而现在一个应用里可能有几十种业务场景,不同场景流量的规模是完全不同。如果只关注应用维度的指标,便可能在一些场景异常时,上层无法感知。如下图就是一个典型的例子:场景三的流量因为较小,无法从应用级别的指标中提现,因此在异常发生时,监控没有报警。同时,这种细分场景的指标也可以辅助上层做一定的决策,如不同的场景,其中一个场景通过同步加载,而另一场景通过异步加载,两者的超时要求是不一样的,这时候就可以通过这种细分场景的指标,指导我们做精细化的控制。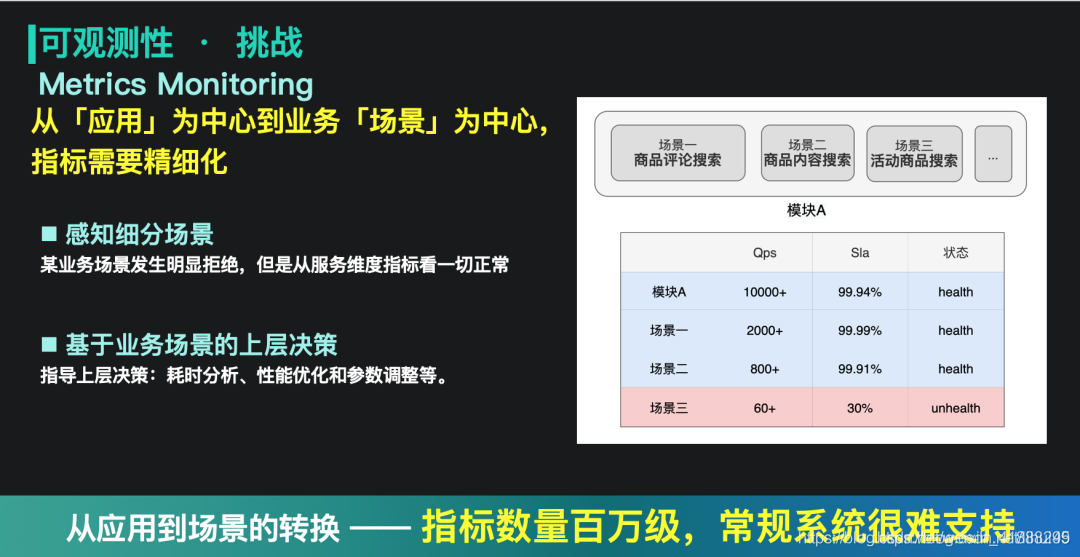
但是,从应用到场景的细分,导致系统的指标量级急剧扩大,达到了百万级。这对于指标的聚合和计算来说,就成为一个新的挑战。
3)对拓扑链路的宏观分析
在云原生架构下,应用与应用之间的连接关系变得越来越复杂。分布式追踪可以帮助我们定位某个具体请求的问题。而在系统出现一些宏观问题:流量剧增,97分位耗时增加,拒绝率增加等,就需要拓扑分析工具帮助我们进行定位。同时它对上层决策也有比较强的指导意义。如下图右侧的例子:商品搜索有两类场景,第1类场景有运营活动,预计增加300qps的流量,如果没有拓扑分析工具的话,我们就很难评估各个服务的容量Buffer。
三、我们做了什么
我们在去年,对可观测性的四个要素进行了探索和实践,并发布了全要素的观测平台,为保障搜索中台的可用性提供了有力保障。
1)日志查询、分布式追踪
随着业务规模的增长,搜索中台整体的日志量级达到了PB级的规模,通过离线存储日志数据,再进行索引的方式会带来巨大的资源开销。而我们在这里使用了一种突破性的解决方案:在离线结合,离线存储了少量的种子信息,在线直接复用线上的日志(0成本)。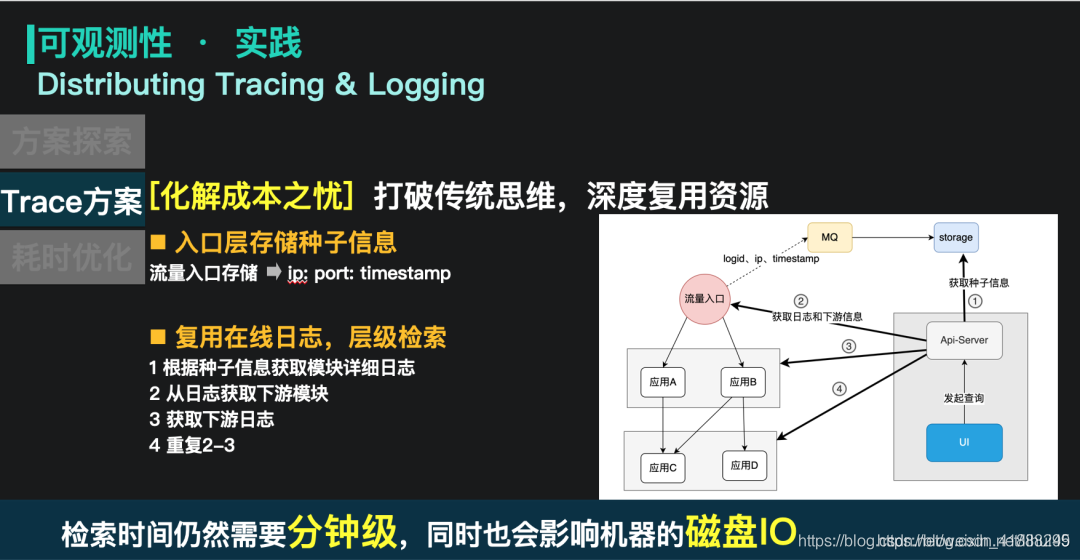
具体做法是:
- 在流量入口层将logid、ip、访问的时间戳存下来,存到一个kv存储里。
- 当用户使用logid检索的时候,在kv存储中查询logid对应的ip和时间戳。
- 通过ip和时间戳去对应的实例获取完整的日志信息。
- 通过规则解析日志,获取下游实例的ip和时间戳信息。 重复3-4的广度遍历过程,得到完整的调用链路拓扑。
- 但是这里仍然存在一个问题:Trace时间较长。
实例需要需要对自己的日志文件进行全量 grep,这在日志文件大、请求链路长的时候,会导致trace的时间较长,同时也会带来稳定性的冲击。这里我们使用了按时间动态N分搜索的思路,利用请求的时间信息和时间有序的日志结构,快速进行N分查找。
以下图给大家举例:图中日志文件是 20 点的日志文件,当前需要查询 20 : 15 分的一个日志请求。因为 15 分钟刚好是小时的 1/4,所以会先 fseek 这个文件的 1/4 位置。当前 1/4 段的日志信息在 20 : 13,这个时候下半段的日志文件就是 47 分钟的日志数据,那就会再往下偏移 2/47,重新进行fseek。重复这个过程就可以快速查询对应的详细日志信息。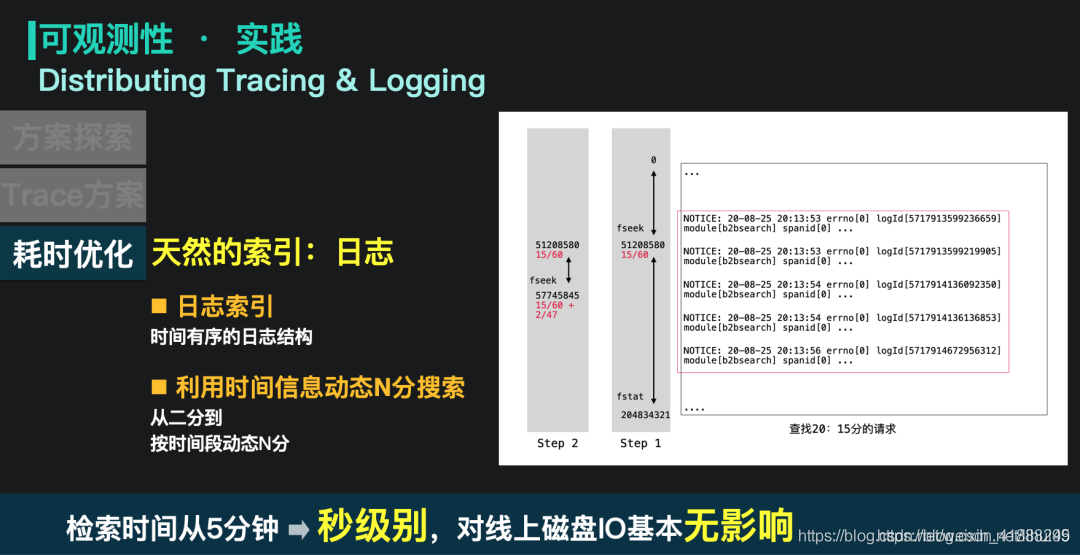
这种检索方式可以获得非常快的收敛速度,单实例的日志检索耗时控制在 100ms 以内,对 io 的影响基本忽略不计。同时,用户整体的检索时间也控制在了秒级别。
2)指标监控
因为我们的观测视角从应用级别发展到了场景级别,指标数量也从万级别增加到了百万级别,所以我们对监控架构进行了重新设计。这张图就是升级后的一个架构图。
它的主体思想是线上实例嵌一个依赖库,这个依赖库会收集所有的指标信息,并将它做一定的预聚合,之后采集器轮询式的去获取线上的实例的指标数据,然后把聚合后的数据写到tsdb里。值得注意的一点,这套方案和业界的一些指标方案较大的不同:实例维度的指标会在采集器里实时聚合,转换成场景或服务维度的指标,随后实例的维度指标会被丢弃,不再存储到tsdb中。因为实例维度的指标参考意义有限,我们是使用聚合后的数据等来分析应用的运行情况。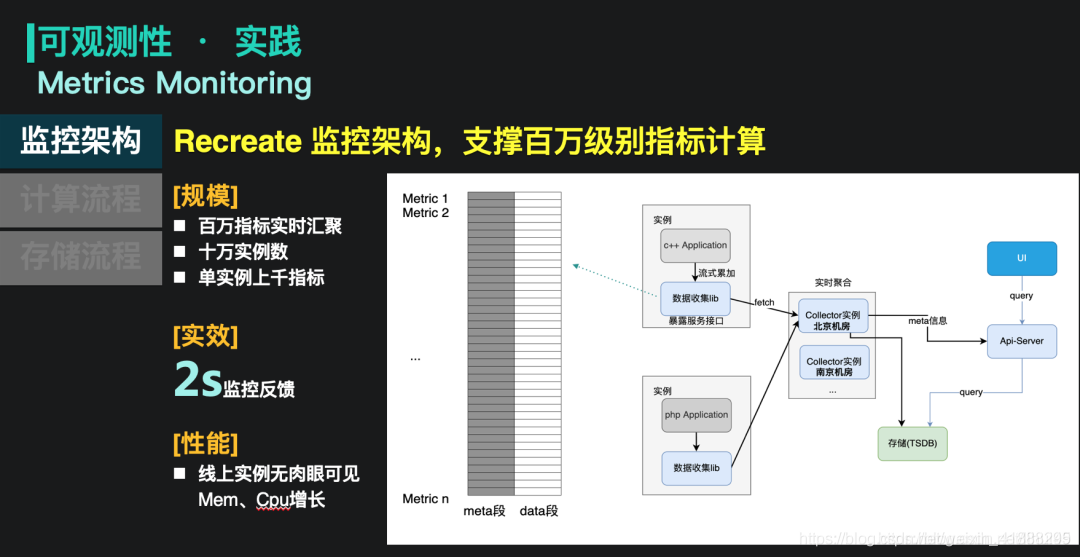
在这套架构里,我们对计算和存储进行了很多的优化,从线上指标变化到平台展现,只需要2s的反馈时间,资源开销非常轻量。以指标的聚合为例:线上实例只进行累加操作,而采集器会存上一次抓取的快照信息,和当前这一次采集做对比,进行线性差值计算。这种方式对线上实例的资源开销是肉眼不可见的。同时也可以方便的去产出Qps、延迟等信息。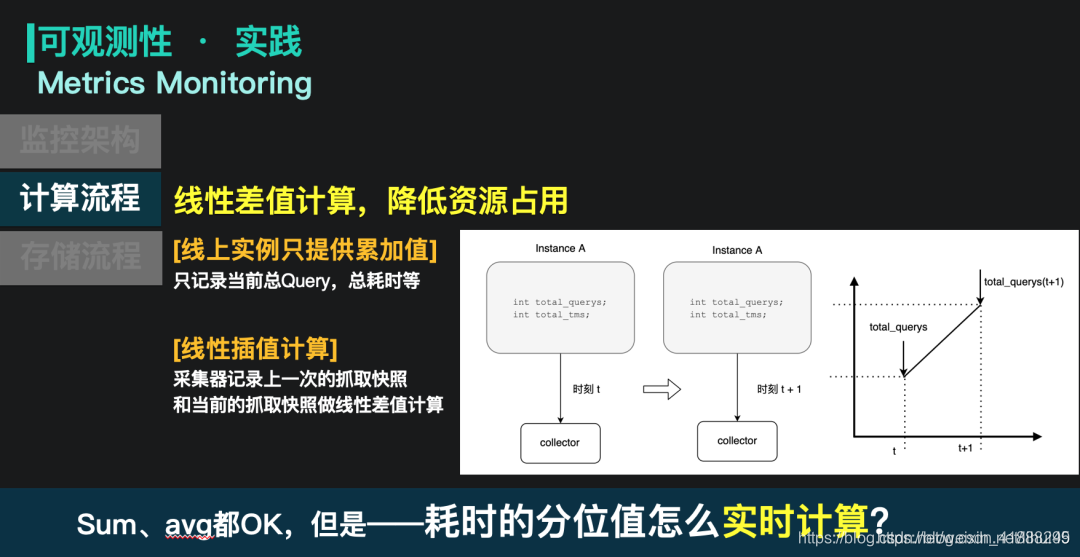
除了Qps、延迟之外,我们也优化了分位耗时的计算方式。
分位耗时的计算常规方案是将请求的耗时做排序,然后取它的分位位置上的耗时数值。这种计算方式在请求量级较高的时候,资源占用非常高。因此我们采用了分桶计算的方式,按请求的耗时进行分桶,当请求执行结束时,在对应耗时的桶里加1;而在计算分位值时,先确定分位值所在的桶,桶内数据则认为服从线性分布,通过这样的思路可以推导如下图的公式。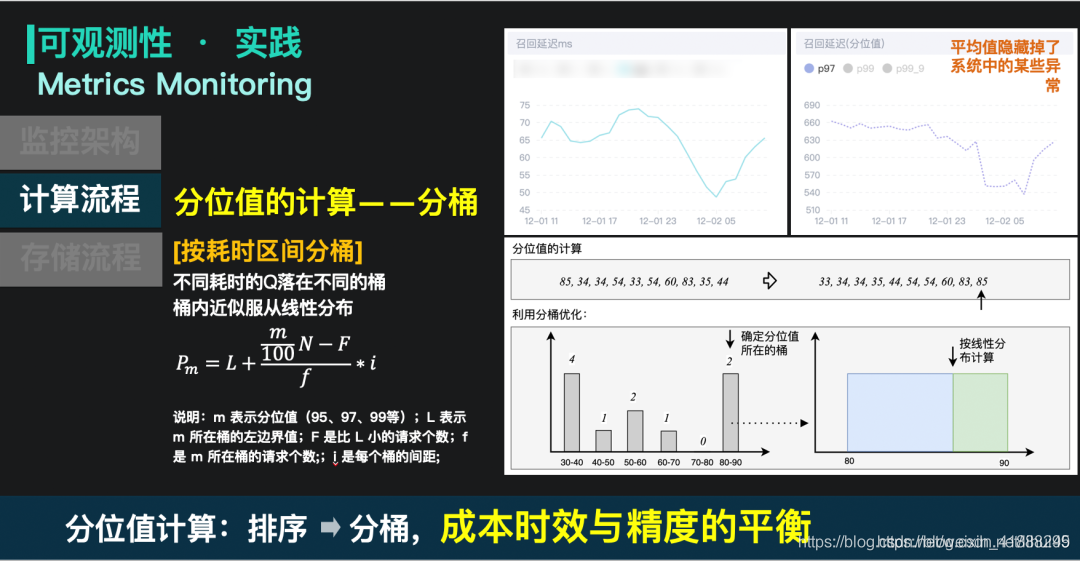
这样的好处是资源开销低,可实时计算,但是缺点是会损失一部分精度。这个精度取决于分桶的粒度,在搜索中台使用的桶大小是30ms,一般误差在15ms以内,可以满足性能观测的需求。
3)拓扑分析
拓扑分析的实现利用了指标监控的运作机制。
首先,对流量进行染色,并将染色信息通过RPC传递到各个服务。通过这种方式,让每个span(注:span的定义来自Dapper论文)持有场景的标识以及上游span的名称。场景标识可以区分不同场景的流量,而span名称和上游span名称可以建立父子的连接关系。这些span复用了上述指标计算的机制,通过将span的信息存入指标中,产出对应的性能数据。当用户提供一个场景标识时,平台会把它的全部指标提取出来,根据指标内的span信息,串联成完整的调用拓扑。
四、最后
到这里可观测性的四个基本要素基本讲述完了。在这四个要素之上,我们孵化了很多的应用产品,如历史快照、智能报警、拒绝分析等。通过这些产品,可以更好的帮助我们快速去发现和分析问题。
当然,可观测性的工作并不止步于此。我们也在依托这套观测系统,打造一些自适应、自调整的柔性机制,在异常出现时,能够自动容忍和恢复,最大化的保持系统的生命力。
期待你的加入
百度开发者中心已开启征稿模式,欢迎开发者登录developer.baidu.com进行投稿,优质文章将获得丰厚奖励和推广资源。


发表评论
登录后可评论,请前往 登录 或 注册