网易云音乐:基于分布式图学习PGL的推荐系统优化
2021.03.17 19:10浏览量:725简介:在“精准推荐者得民心”的今天,推荐系统已成为各大互联网公司的标配。
在“精准推荐者得民心”的今天,推荐系统已成为各大互联网公司的标配。但由于现实中很多数据是非欧氏空间生成的(例如,社交网络、信息网络等),一些复杂场景下的业务需求很难通过协同过滤等基于历史行为挖掘用户或产品相似性的传统算法来满足。图神经网络作为一种约束性较少、极其灵活的数据表征方式,在深度学习各主要领域中崭露头角,一系列图学习模型涌现并得到越来越多的应用。
网易云音乐在推荐领域的探索

作为国民级的音乐 App,网易云音乐很久之前就将定位从传统的音乐工具软件转移到音乐内容社区,致力于联结泛音乐产品与用户,打造最懂用户的音乐 App。在音乐内容社区中,直播可以说是用户参与度极高的场景了,云音乐内部投入了大量的人力物力以求将匹配度更高的主播推荐给用户,但仍然面临多重严峻的挑战。
如何破解历史行为稀少的用户冷启动问题
众所周知,推荐系统的整体框架主要包括召回、粗排和精排3个部分。其中,最底层的召回模型具有举足轻重的作用,而成功的召回推理需要依赖充足的历史数据。但在云音乐的业务场景中,通过站内广告看到直播推荐的用户很大比例是直播功能的新用户,即没有产生过观看直播行为数据的用户。如何向这类数据稀疏的用户推荐合适的内容成了亟待解决的难题,这类问题也通常被称为冷启动。
大规模图模型如何训练
云音乐现有计算资源已全面实现容器化部署,对于各个业务团队来说,计算资源都是有限的,需要以最高效合理的方式利用有限的资源。如何在有限的分布式资源调控策略下低本高效地完成大规模图神经网络的模型训练,成为必须攻克的难题。
PGL 图神经网络助力推荐场景落地
为了解决以上问题,网易云音乐的研发团队调研了大量开源方案,最终选择了对大规模图训练更加友好的百度飞桨分布式图学习框架 PGL,作为云音乐的基础框架。
基于 PGL 的行为域知识迁移解决冷启动问题
云音乐直播场景的新用户中,有很多在音乐、歌单、Mlog 等业务中产生过较丰富的历史行为,能否通过将这部分历史行为知识映射到直播领域,来解决“行为”数据不足的问题呢?
带着疑问,云音乐引入了图模型结构,以多种不同类型的实体(如歌曲、DJ、Query、RadioID 等)为节点,通过用户与主播、用户与歌曲、Query 与主播等历史行为关系,构建了一张统一的图关系网络。
然后,基于飞桨图学习框架 PGL 对图模型进行训练。先采用 DeepWalk、Metapath2Vec、GraphSage 等模型学习出足够强大的 Graph Embedding 表示来建模实体 ID;再通过向量召回,将用户在歌曲、Query 等处的行为迁移到主播领域,达到召回合适主播的目的。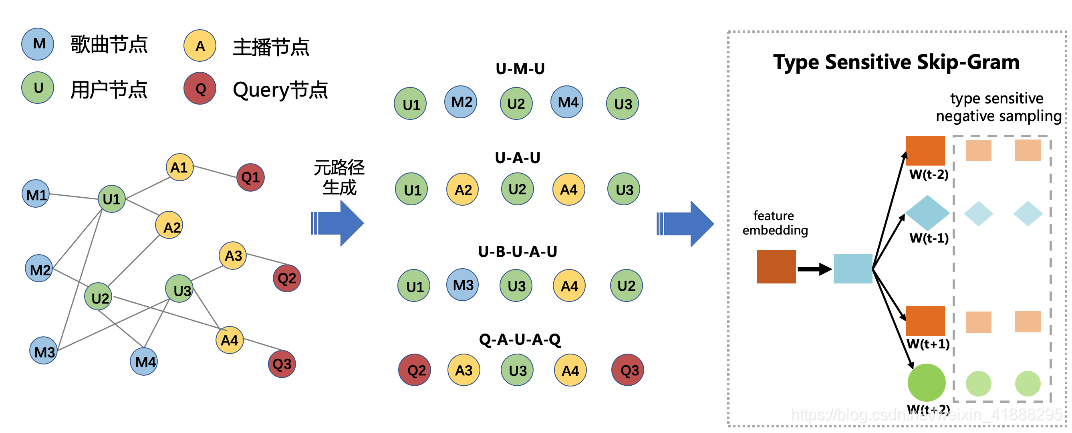
基于 PGL 通用的分布式能力进行训练
云音乐的数据规模非常庞大,数据关系即使经过裁剪也高达亿级别以上。在常用的硬件资源配备情况下,此等量级规模的数据早已成为某些开源的图神经网络框架的瓶颈,需要使用极其昂贵的计算资源才能解决。对于数据规模必将持续增大的云音乐来说,相较于使用什么类型的模型,能否在这种数据规模下训练出模型才是优先要考虑的关键问题,也是网易云音乐与 PGL 成功牵手的关键因素!
百度飞桨深度学习平台 PaddlePaddle 2019 年开源的分布式图学习框架 PGL,原生支持图学习中较为独特的分布式图存储(Distributed Graph Storage)和分布式采样(Distributed Sampling),可以方便地通过上层 Python 接口,将 图的特征(如Side Feature等)存储在不同的 Server 上,也支持通用的分布式采样接口,将不同子图的采样分布式处理,并基于 PaddlePaddle Fleet API 来完成分布式训练(Distributed Training),实现在分布式的“瘦计算节点”上加速计算。这些能力对云音乐内容社区直播推荐遇到的训练问题来说,极具魅力!
实验对比显示,在主播推荐场景采用图计算带来有效观看大幅提升,尤其在新用户和新主播冷启动上引入其它域数据后有了明显提升。
期待你的加入
百度开发者中心已开启征稿模式,欢迎开发者登录developer.baidu.com进行投稿,优质文章将获得丰厚奖励和推广资源。


发表评论
登录后可评论,请前往 登录 或 注册