BERT和GAN咋压缩,且看咱PaddleSlim新利器—— OFA
2021.04.13 18:19浏览量:432简介:深度学习领域,一方面需要追求更高的性能;另一方面又需要关注如何将算法更稳定、高效地在硬件平台上落地。
目前在深度学习领域,一方面需要追求更高的性能,采用强大、复杂的模型网络和实验方法;另一方面又需要关注如何将算法更稳定、高效地在硬件平台上落地。复杂的模型固然展现更好的性能,但过高的存储空间需求和计算资源消耗,是影响在各硬件平台上的落地的重要原因之一。尤其在NLP领域,以BERT、GPT为代表的预训练模型规模越来越大。
针对部署难题,可以使用剪枝、量化、蒸馏等传统的模型压缩技术,但是这些模型压缩技术整体的流程较长,直接串行结合的效果不佳。而OFA(Once For All)[1]技术巧妙地结合了剪枝、蒸馏和结构搜索策略,不仅提升了压缩效果,还简化了压缩流程。
百度飞桨模型压缩工具PaddleSlim新增支持OFA这一实用功能,并在BERT和GAN模型上做了验证:对于BERT模型实现了近2倍的加速;而对GAN模型则实现了33倍的体积压缩。除此以外,PaddleSlim还为用户提供了简单易用且低侵入的轻量级接口,用户无需修改模型训练代码,即可完成OFA压缩。
什么是OFA?
OFA(Once For All)是一种结合One-Shot NAS和蒸馏的压缩方案。其优势是可以基于已有的预训练模型进行压缩,不需要重新训练新的预训练模型;同时只需要训练一个超网络就可以从中选择满足不同延时要求的子模型。
OFA的搜索空间和One-Shot NAS不同,之前的搜索是在不同OP之间进行选择,比如把降采样中的卷积替换成Pooling,或者把3x3卷积替换成5x5。OFA中的搜索空间不是OP的替换,而是对当前OP进行属性变换,比如卷积核大小的变化和参数通道数的变化。
说明:
卷积核大小变化指的是对于网络中已有的5x5的卷积,在实际训练过程中随机把它修改成为3x3,而它与5x5的卷积是权重共享的。
参数通道数变化指的是在训练过程中随机把参数通道数修改成搜索空间中设置的任意一个通道数。
OFA的搜索空间还可以包含对模型深度的搜索。以BERT-base模型为例,一共有12个transformer encoder block。如果深度相关的搜索空间设置为[8, 12]两个选项,则在训练过程中会随机选择当前训练的子模型是包含8个还是12个transformer encoder block。如果训练的是包含8个transformer encoder block组成的子网络,则根据一些规则去掉原始12个block中的4个block。
通过上面训练,每次都会随机训练超网络中任意一个子网络,该网络仅包含超网络部分参数。
OFA中的蒸馏使用的是自蒸馏的方式,教师网络选择和超网络中最大子模型相同的模型,教师网络的参数是预训练好的,学生网络选择的是超网络中随机一个子模型。训练过程中,教师网络参数不进行更新。蒸馏损失作为整个超网络训练过程中整体损失函数的一部分,帮助训练超网络。
OFA对NLP的压缩
BERT系列模型是由多个transformer block堆叠得到的,每个block分为一个MultiHead-Attention和一个Feed-Forward Network。
对MultiHead-Attention,在训练超网络时,会在搜索空间中随机选择当前block需要保留的Head数量,当前训练的子网络仅包含这些Head对应的QKV矩阵中的参数。
对于Feed-Forward Network,包含两个线性计算层,第一个线性计算层会放大线性层的宽度,在训练超网络时,对线性层计算中放大的宽度进行随机搜索,当前训练的子网络仅训练保留下来的相应宽度的参数。
整体压缩流程如下:
对预训练模型的参数和head进行重要性重排序,把重要参数和head排在参数的前侧,保证训练过程时的参数裁剪不会裁掉这些参数。重要性计算是先使用dev数据计算一遍每个参数的梯度,然后根据梯度和参数的整体大小来计算当前参数的重要性,head的重要性计算是通过传入一个全1的对head的mask,并计算这个mask的梯度,根据mask的梯度来判断每个Multi-Head Attention层中每个Head的重要性。
使用预训练模型作为蒸馏过程中的教师网络,同时定义一个超网络。超网络中最大的子网络的结构和教师网络的结构相同。使用重排序之后的预训练模型参数初始化超网络,并把这个超网络作为学生网络。然后分别为embedding层,每个transformer block层和最后的logit添加蒸馏损失。
每个batch数据在训练前会选择当前要训练的子网络配置(子网络配置目前仅包括对整个模型的宽度的选择),参数更新时仅会更新当前子网络计算中用到的那部分参数。
通过以上方式优化整个超网络参数,训练完成后选择满足加速要求和精度要求的子模型。
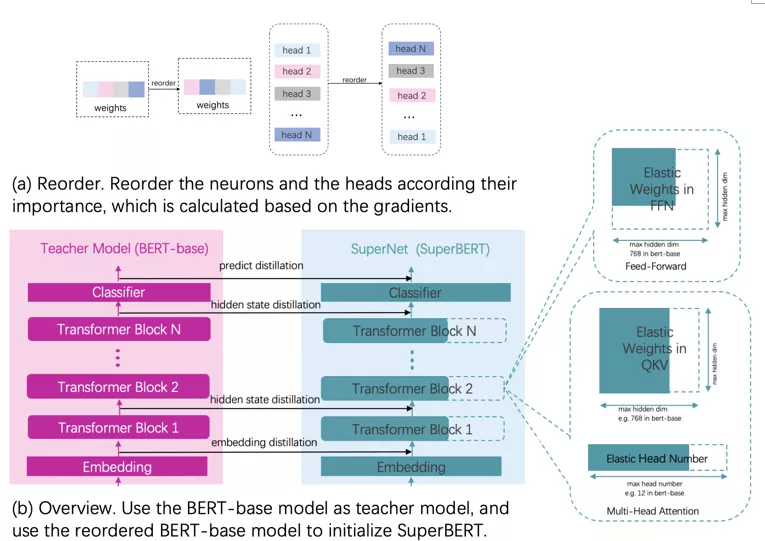
图BERT压缩流程
压缩结果
利用bert-base-uncased模型在GLUE数据集上进行finetune,得到需要压缩的模型,之后基于此模型进行压缩。压缩后模型参数大小减小26%(从110M减少到81M),精度没有任何损失,并且在GPU上实现了近2倍的加速。
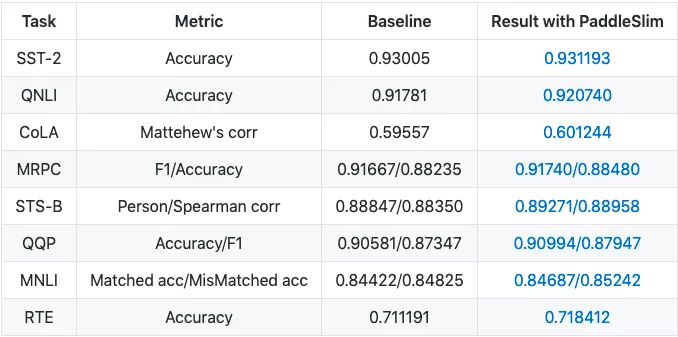
表GLUE数据集精度对比
OFA对GAN的压缩
接下来再讲解OFA对于CV中的GAN的压缩。
选取CycleGAN模型作为压缩流程的示例。为了得到更高压缩比例,对GAN的压缩整个分为3个步骤:
模型结构修改
原始CycleGAN模型Backbone由ResNet 模块组成,因为ResNet模块计算量较大,把其中的计算量大的普通卷积替换成计算量较小的MobileNet模块中的depthwise-pointwise卷积,得到一个新的轻量级backbone。替换backbone之后,直接训练得到一个较轻量级的CycleGAN模型。我们把这个轻量级的CycleGAN模型称为CycleGAN-MobileResNet。
蒸馏和裁剪结合
直接修改完backbone之后的CycleGAN-MobileResNet模型还是有点大,我们利用剪枝功能对backbone进行一些通道裁剪,基于L1Norm的方法来计算每个参数的重要性,裁剪掉一半相对不重要的卷积核,模型的计算量和参数量减少一倍。
直接剪枝之后FID会有一定的损失,通过添加蒸馏的方法来减少损失。蒸馏教师模型选择的是裁剪之前的模型,学生模型选择裁剪之后的模型,损失函数使用的是均方差损失函数,为了更好的利用教师网络中的有用信息,对教师模型中多个中间层的信息进行提取,用这些信息指导学生模型学习,更有利于训练的稳定和效果的提升。
OFA超网络训练
裁剪之后的模型已经很小了,但是在裁剪之后额度模型上是否还能再进一步进行压缩呢?结果证明是可以的,裁剪之后的模型本质上说还是人工设计出来的网络,仍然有一定的冗余性,可以通过神经网络搜索的方式对冗余参数进行进一步压缩,这里选择用OFA的方式进行神经网络搜索。把上一步训练完成的学生网络作为OFA中的超网络,根据backbone中的通道数设计相应的搜索空间,在训练超网络时随机在搜索空间中选择卷积的通道数,通过这种方式来进一步压缩网络中的参数。
同时为了超网络训练的稳定性,也添加了蒸馏方法来辅助训练,本次蒸馏中使用步骤2中训练完成的学生网络作为教师网络,超网络作为学生网络。具体的蒸馏方案和上一步骤中相同,在此就不重复介绍了。
压缩结果
通过上面整体压缩流程的压缩,CycleGAN模型在horse2zebra数据集上在指标基本持平的情况下的计算量减少22.2倍,模型体积减少33.3倍,详细数据展示:

表 CycleGAN在horse2zebra上的压缩情况
轻量级OFA接口
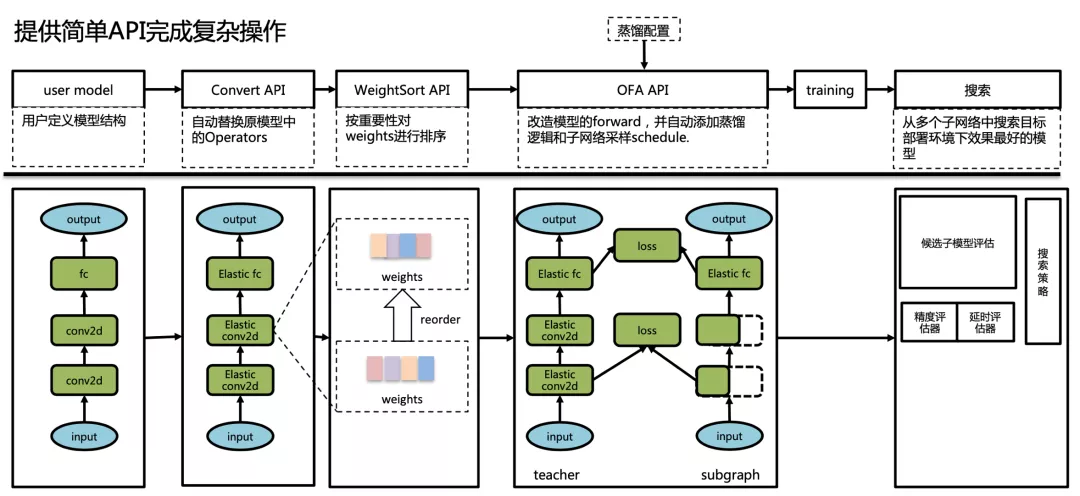
图 PaddleSlim OFA接口示意图
如上图所示,OFA涉及多个复杂的操作,包括按重要性对权重重排、剪枝、蒸馏、子模型搜索等,PaddleSlim将这些操作隐藏到底层,提供给用户简单的适用接口。更重要的是,PaddleSlim提供的接口对用户代码是低侵入的,用户不用修改现有的模型训练代码,通过调用PaddleSlim的转换接口即可将原有模型自动转换为超网络。
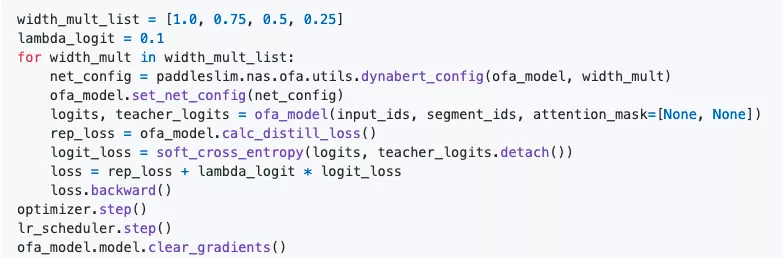
以下步骤展示了如何利用PaddleSlim中OFA压缩功能对PaddleNLP中BERT模型进行压缩:
调用PaddleNLP中相应接口定义原始BERT-base模型并定义一个字典保存原始模型参数。普通模型转换为超网络之后,由于其组网OP的改变导致原始模型加载的参数失效,所以需要定义一个字典保存原始模型的参数并用来初始化超网络。

定义搜索空间,并根据搜索空间把普通网络转换为超网络。

调用PaddleNLP中的接口直接构造教师网络。

进行相关的蒸馏配置,需要配置的参数包括教师模型实例;需要添加蒸馏的层,在教师网络和学生网络的Embedding层和每一个Tranformer Block层之间添加蒸馏损失,中间层的蒸馏损失使用默认的MSE损失函数;配置’lambda_distill’参数表示整体蒸馏损失的缩放比例。

普通模型和蒸馏相关配置传给OFA接口,自动添加蒸馏过程并把超网络训练方式转为OFA训练方式。

计算神经元和head的重要性并根据其重要性重排序参数。
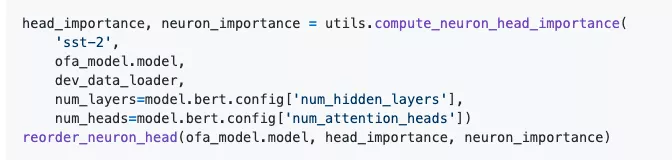
设置当前所处的状态并传入配置开始训练。

了解了那么多,欢迎读者去Github上了解我们的项目,如果觉得不错的话,也辛苦帮忙点个star~
项目链接:
https://github.com/PaddlePaddle/PaddleSlim
如果您还想深入的交流,可以微信添加AIDigest,备注“压缩”,飞桨同学会拉您进入PaddleSlim的官方讨论群之中。
参考文献:
[1]. Once-for-All: Train One Network and Specialize it for Efficient Deployment
[2]. DynaBERT-Dynamic BERT with Adaptive Width and Depth
[3]. GAN Compression: Efficient Architectures for Interactive Conditional GANs
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台,包括飞桨开源平台和飞桨企业版。飞桨开源平台包含核心框架、基础模型库、端到端开发套件与工具组件,持续开源核心能力,为产业、学术、科研创新提供基础底座。飞桨企业版基于飞桨开源平台,针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。

发表评论
登录后可评论,请前往 登录 或 注册