深度强化学习的现在,将来与未来
作者:不轻松的熊2021.05.06 11:28浏览量:1158简介:深度强化学习当前的核心技术、需要解决的问题和深度强化学习未来可能的发展方向
作者:Flood Sung
原发布于知乎专栏:强化学习葵花宝典
1 前言
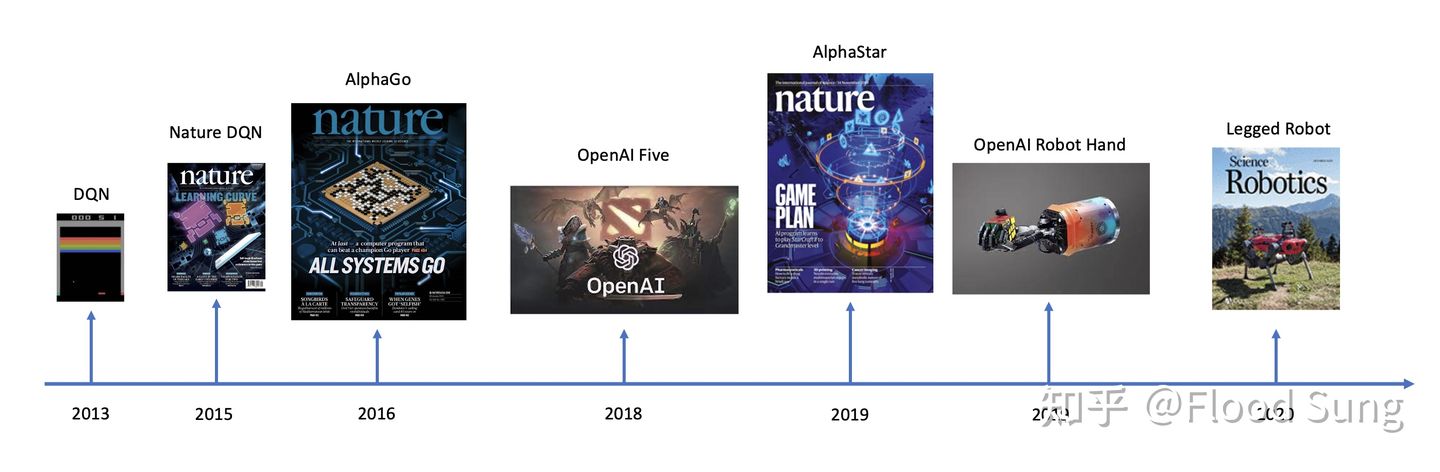
从2013年Deepmind提出DQN开始,深度强化学习(Deep Reinforcement Learning)作为一种面向决策控制的革命性技术,已经发展了8年之久,在这8年中,涌现了AlphaGo,AlphaStar,OpenAI Five等里程碑式的突破。下图展示了深度强化学习这8年来的里程碑成果,非常激动人心:
在这篇文章中,我们想探讨三个方面的内容:
(1)深度强化学习当前的核心技术
(2)深度强化学习需要解决的问题
(3)深度强化学习未来可能的发展方向
阅读对象:
(1)想入门深度强化学习的同学
(2)有一定深度强化学习基础,想做大型研究的同学
(3)工业界考虑用深度强化学习落地的创业者
写这篇文章的目的:尽可能在中文社区推广和普及深度强化学习,减少学习门槛,少走弯路,促进国内研究者在深度强化学习领域也能取得革命性突破及更好的工业落地。
2 深度强化学习的最核心技术
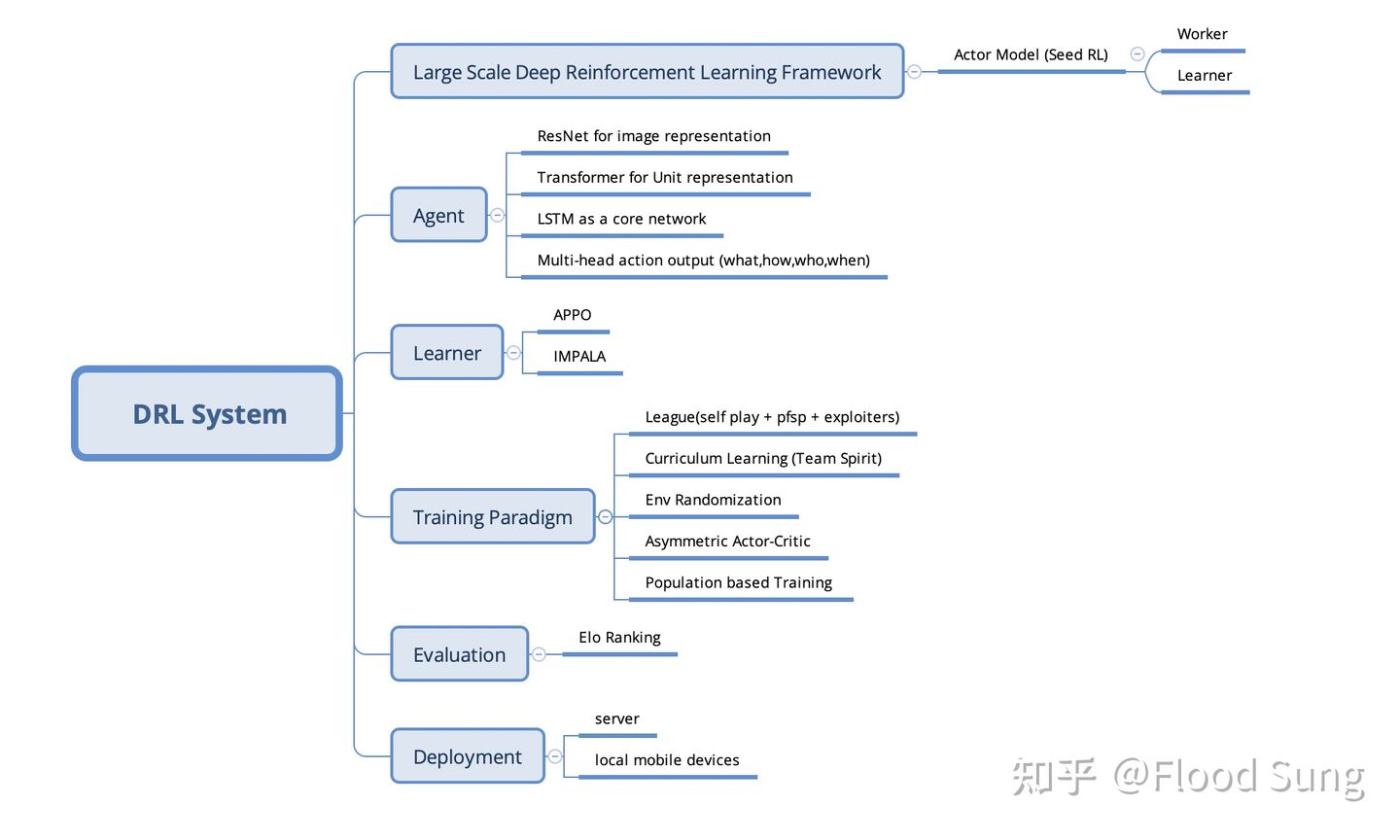
目前(2021.4)深度强化学习最核心的技术还是AlphaStar,OpenAI Five这一整套技术。也就是说虽然AlphaStar已经过去了2年,但深度强化学习在这两年里并没有质的变化。所以,如果你考虑做大型的深度强化学习研究项目或者就用深度强化学习来创业,那么掌握并实现上图的技术就足够了。如果你是一个对深度强化学习有兴趣的同学,刚想入门,那么你只要把AlphaStar和OpenAI Five两篇paper彻底掌握你也就掌握了最关键的技术。
下面,我们来解释一下上面这张图:
2.1 DRL System 深度强化学习系统
对,这是一个系统,需要用系统工程的视角去看待。如果你是还在学校的同学,实验室里仅有极少的GPU,CPU,你也应该去思考如果未来有成千上万的GPU,CPU的时候该怎么去用。在工业界,要训练出有价值的智能体,那么你一定需要两个团队,一个顶层算法团队和一个底层框架系统团队。其中,底层框架系统团队来构建大规模的深度强化学习框架,能够支持调度巨量的计算资源,而顶层算法团队则负责构建深度强化学习算法,进行智能体的训练。两者缺一不可。
这套深度强化学习系统主要是面向竞技类的环境,即有至少两方的智能体进行博弈对抗,从而能够进行self play 自对弈不断提升智能体的水平。对于单智能体的情况,比如机器人,其实可以看做是机器人与环境的对抗,需要不断的变换环境的复杂度来提升机器人的智能水平。也因此,这套深度强化学习系统是适用于所有场景的。
同时,深度强化学习系统主要面向虚拟环境,只有虚拟环境才能进行无限的并行产生巨量数据。如果是机器人则需要sim2real技术加持。
2.2 Large Scale Deep Reinforcement Learning Framework 大规模深度强化学习框架
深度强化学习和一般深度学习的不同之处在于深度强化学习的训练没有现成的数据,需要智能体和环境Env交互来产生数据。这使得CPU的需求比一般的深度学习训练大得多,因为环境Env(比如一个游戏)往往是放在CPU来产生数据。一般,一个GPU的训练需要有50个甚至100个CPU core来产生数据。比如OpenAI Five,就用了几百个GPU和几万核的CPU。
相比于一般的分布式系统,深度强化学习系统比较专用,核心是Worker(CPU,用来采集数据),Learner (GPU,用来训练智能体)。具体的架构可以看OpenAI的Rapid或Google Seed RL,基本一样。需要解决的关键问题是采样和学习效率,网络带宽,内存泄漏等等问题。
对于这种系统,构建一个针对性的Actor Model的分布式系统其实就够了。
对于广大还在学校的同学,可能很难自己去构建这样的系统,因此开源的分布式深度强化学习框架就显得非常重要。这一块,Ray算是走在了前面,Rllib基于Ray构建,支持多GPU,CPU训练,支持Pytorch和TensorFlow,虽然代码结构比较复杂,但要做大一点的项目,在没有自研框架的情况下还是可以考虑用它。除此之外,Tencent开源的Tleague也是支持多GPU,CPU训练的,但TLeague的效率一般。
2.3 Agent 智能体网络结构
对于较大型的项目,智能体网络结构基本上都可以参考AlphaStar及OpenAI Five的网络结构。简单的总结就是:
(1)使用ResNet对图像提取特征
(2)使用Transformer对unit信息提取特征。Transformer 没有顺序性的特点特别适合unit信息的提取。当然,如果unit数量不多,也可以考虑graph network。
(3)LSTM 作为核心网络。虽然Deepmind也有尝试用Transformer来代替LSTM,但这会导致整个计算量大增,如果观察特征本身就非常多的话,那么换成Transformer会对当前系统带来极大挑战。因此,使用LSTM依然是一个好的选择。未来,随着算力的提升,LSTM应该早晚会被取代掉。
(4)多个动作头。一般做研究使用的环境都比较简单,往往只有一个动作头(比如Atari),但真实的竞技环境会复杂得多,需要同时输出多个动作,但基本上和单个动作头差别不大。根据需要使用autoregressive action。
2.4 Learner 学习器/优化算法
这块这两年基本上没有大的变化,PPO和IMPALA就是主流,至多在上面做点小的改动,比如Tencent做的Double clip PPO。OpenAI对PPO做了改进提出PPG,优化样本使用效率,但反响不是很大。
所以,对于深度强化学习刚入门的同学,就不一定要从DQN学起了,直接学PPO更好。
2.5 Training Paradigm 训练范式
这一块往往是初学者最容易忽略或者不了解的地方,但其实是深度强化学习训练能否成功最关键的地方。
核心是如何为智能体构造足够多样的样本?智能体见到的样本分布越广,学出来的效果就可以越鲁棒,越智能。反之,很容易被针对。AlphaGo对李世石的第4局,为什么会因为李世石的一步棋而突然溃败就在于此,AlphaGo在自对弈self play的时候从来没有见过李世石这种下法,就傻掉了。
AlphaStar 在星际争霸2上为了构建多样性Diversity 使用人类样本做统计量z来实现对手的多种风格,通过使用League训练来进一步提升策略的多样性。
对于机器人的训练,Domain Randomization往往是必须使用的方法,目的也是构建多样性。
深度强化学习研究到现在,如何实现好的多样性依然是个问题,值得探索。Population based Training (PBT)也是一个重要方法,League就是其中之一的方法。
除此之外,如何让智能体能够循序渐进的学习,如何充分的利用模拟环境带来的隐藏信息也是提升智能体水平的方法。Curriculum Learning课程学习和Asymmetric Actor Critic往往会被使用。
2.6 Evaluation评估和Deployment部署
这块需要谈的不多,Evaluation 评估就是去评估智能体的水平,可以使用很多现有的方法如Elo Rank来计算。Deployment 部署则是面对落地上线必须的环节。
3 深度强化学习需要解决的问题
虽然上述的种种核心技术已经能构建各种各样的智能体,但深度强化学习又远远没有到完全落地的状态,目前只能落地到虚拟环境,对智能要求或者说失误没有很大要求的场景,在现实环境中的落地还有点距离。
根本原因是什么?
深度学习本身存在严重缺陷!
深度学习的神经网络是建立在iid(样本独立同分布)的基础上,本质是采用概率统计的方式去拟合输入和输出的关系。因此,在遇到ood(out of distribution 分布之外)的数据的时候,神经网络将无法处理而输出错误的结果。
由于这个问题的存在,导致深度学习很难处理corner case!深度强化学习是在深度学习基础上结合强化学习发展出来的技术,同样有这样的问题。因此,在现实落地场景中,有很多场景是要求99.99%甚至更高的准确度的,比如机械臂的抓取,比如自动驾驶。那么在这种场景下,落地要求对corner case能够很好的处理,就会变得很难。
要解决这个问题,要么深度学习理论本身发生变革,能够很好的支持ood,要么只能在数据端进行处理,让智能体的训练尽可能的覆盖各种各样的场景,让corner case尽可能的少。
要变革深度学习理论是一件非常困难的事情,因此,目前的做法就是通过更多样的数据来处理。
数据的多样性就成了深度强化学习需要解决的难题。就算在虚拟场景的落地比如游戏AI,一样会遇到这个问题。
比如在游戏AI的开发中,有时候游戏还没上线,并没有现成的人类数据可以做模仿学习,那么怎么去构建多样的策略呢?
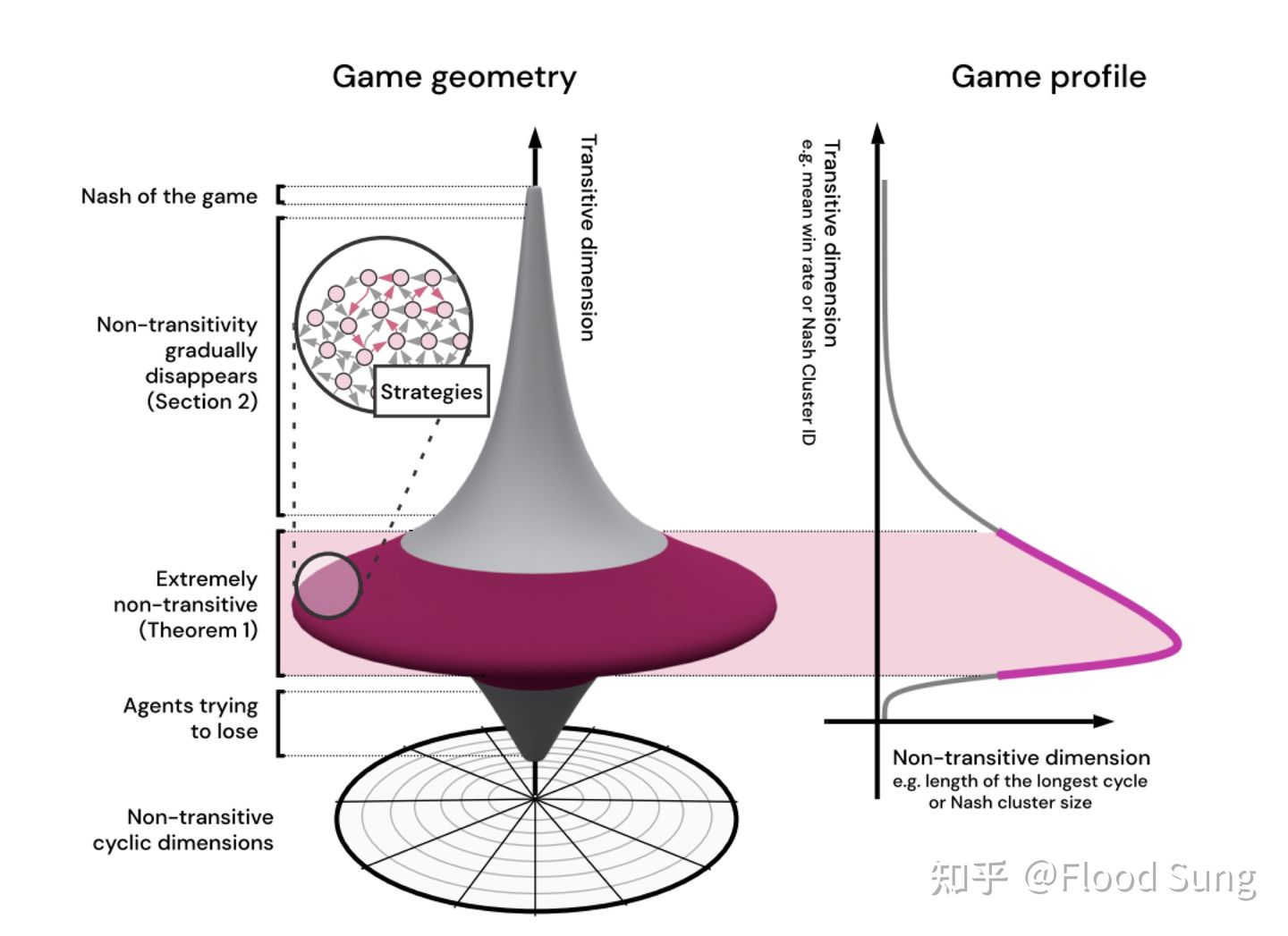
Deepmind的一篇paper Real World Games Look Like Spinning Tops 也揭示了游戏就像一个陀螺,陀螺的宽就是多样性,高则是游戏水平。要想让智能体能够最终实现纳什均衡,那么就需要能够构造尽可能多的多样的策略。
和Diversity一样,深度强化学习的Exploration也是很大的问题。在很多场景中,reward可能非常稀疏,如何探索到有效的路径就很困难,导致无法学习。因此,需要研究更好的exploration的方法才能解决。
最后,如何提升深度强化学习的研发效率也很重要。目前的深度强化学习系统,里面的很多超参,特别是reward的设计,是非常依然于人类经验的,稍微做一点改变,都可能导致智能体的行为发生很大改变。这就导致深度强化学习技术很不成熟。如何让深度强化学习系统更鲁棒,进行可复制性的便捷开发是该技术成熟的标志。
总结一下,当前深度强化学习依然面临着很多问题,其中面向落地最最重要的是(个人观点)
1)Diversity 多样性问题。如何从0构建多样的策略来让智能体足够鲁棒,覆盖99.99%的场景
2)Exploration 探索问题。如何在现实的稀疏奖励Sparse Reward 进行智能体的有效训练?
3)深度强化学习的研发效率问题。如何减少reward shaping及超参数调整的工作量?
当然在学术界还有各种各样的问题也值得探索。
4 深度强化学习的未来
一直以来,深度强化学习被认为是通往AGI通用人工智能的关键技术。在未来的10年中,深度强化学习也必将扮演很重要的角色。这里分学术界和工业界两个角度去分析。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册