图像处理任务的论文推荐
作者:发出毛毛毛毛的声音2021.06.08 10:40浏览量:659简介:推荐三篇图像处理相关任务的论文,分别来自中国科学院大学等机构。
FoveaTer:用于图像分类的Foveated Transformer
论文标题:FoveaTer: Foveated Transformer for Image Classification
论文链接:https://arxiv.org/abs/2105.14173
作者单位:加州大学圣巴巴拉分校
本文提供了一个综合框架,用于在视觉Transformer上使用foveal(视网膜中央凹)来完成图像分类任务。类似于DeiT模型对知识迁移的依赖,本文模型依赖于模型集成来达到最先进的性能。
许多动物和人类以不同的空间分辨率(foveated vision)处理视野,并使用外围处理使眼球运动并指向中心凹以获取有关感兴趣对象的高分辨率信息。这种架构导致计算效率高的快速场景探索。视觉Transformer的最新进展为传统上依赖卷积的计算机视觉系统带来了新的替代方案。然而,这些模型没有明确地模拟视觉系统的注视点属性,也没有对眼球运动和分类任务之间的相互作用进行建模。我们提出了 foveated Transformer (FoveaTer) 模型,该模型使用池化区域和扫视运动来使用视觉 Transformer 架构执行物体分类任务。我们提出的模型使用平方池化区域来池化图像特征,这是对受生物启发的注视架构的近似,并将池化特征用作 Transformer 网络的输入。它根据 Transformer 分配给先前和当前注视的各个位置的注意力来决定接下来的注视位置。该模型使用置信阈值来停止场景探索,从而允许为更具挑战性的图像动态分配更多的注视/计算资源。我们使用我们提出的模型和 unfoveated 模型构建了一个集成模型,实现了比 unfoveated 模型低 1.36% 的精度,同时节省了 22% 的计算量。最后,我们证明了我们的模型对对抗性攻击的鲁棒性,它优于 unfoveated 模型。

StyTr^2:首个基于Transformer的图像风格迁移
论文标题:StyTr^2: Unbiased Image Style Transfer with Transformers
论文链接:https://arxiv.org/abs/2105.14576
作者单位:中国科学院大学
据作者称,这是第一个基于Transformer的风格迁移网络,并提出专用的内容感知位置编码机制(CAPE),表现SOTA!性能优于ArtFlow、MCC和AdaIN等网络。
图像风格迁移的目标是在保持原始内容的同时,通过风格参考来渲染具有艺术特征的图像。由于 CNN 的局部性和空间不变性,很难提取和维护输入图像的全局信息。因此,传统的神经风格迁移方法通常是有偏差的,通过使用相同的参考风格图像运行多次风格迁移过程可以观察到content leak。为了解决这个关键问题,我们通过提出一种基于Transformer的方法,即 StyTr^2,将输入图像的long-range依赖性考虑到无偏风格转移。与用于其他视觉任务的视觉Transformer相比,我们的 StyTr^2 包含两个不同的Transfomrer编码器,分别为内容和风格生成特定于域的序列。在编码器之后,采用多层Transformer解码器根据样式序列对内容序列进行风格化。此外,我们分析了现有位置编码方法的不足,提出了尺度不变且更适合图像风格迁移任务的内容感知位置编码(CAPE)。与最先进的基于 CNN 和基于flow的方法相比,定性和定量实验证明了所提出的 StyTr^2 的有效性。

以人为中心的关系分割:数据集和解决方案
论文标题】Human-centric Relation Segmentation: Dataset and Solution
【作者团队】Shaohua Li, Xiuchao Sui, Xiangde Luo, Xinxing Xu, Yong Liu, Rick Siow Mong Goh
【发表时间】2021/05/20
【机构】北京航空航天大学、中科院、Sea AI Lab
【论文链接】https://arxiv.org/pdf/2105.11168.pdf
本文出自北京航空航天大学、中科院、Sea AI Lab 联合团队,已被 TPAMI 接收。在本文中,作者提出了一种细粒度的视觉关系检测问题,旨在预测人类与周围物体的关系,并识别与关系相关的人体部位。作者发布了用于该任务的数据集 PIC,并提出了相应的解决方案对比基线。
近年来,视觉和语言理解技术取得了显著进步,但目前的技术仍然难以很好地处理涉及非常细粒度的细节问题。例如,当机器人被告知「把女孩左手的书拿给我」时,如果女孩的左手和右手各拿着一本书,则大多数现有的方法将失效。
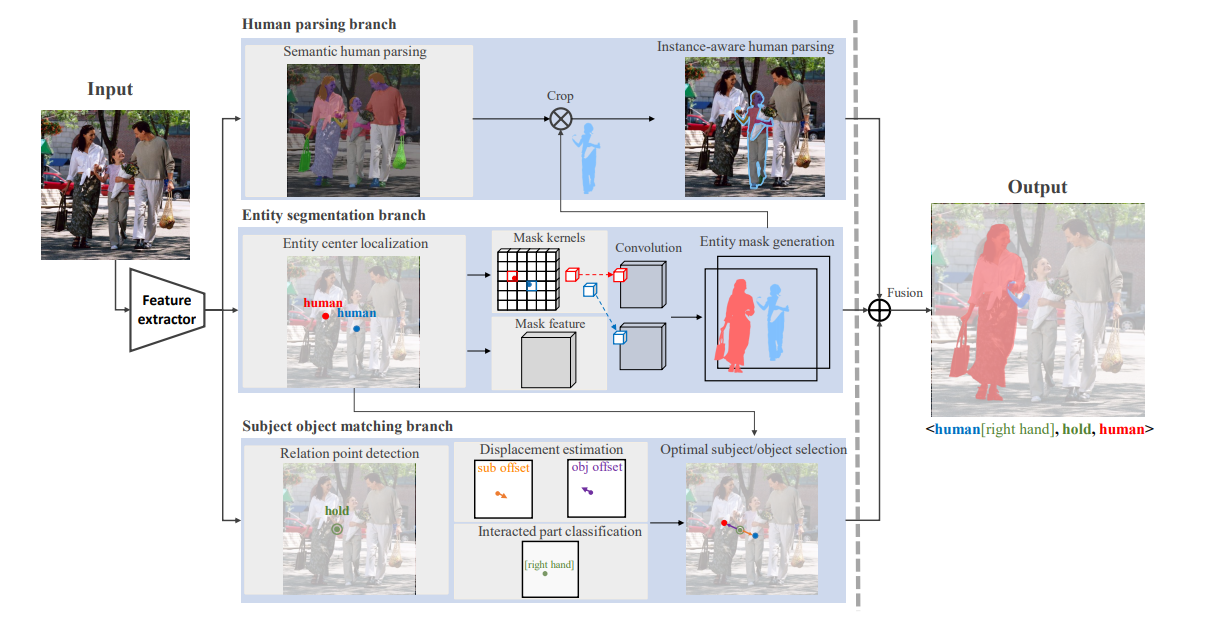
在本文中,作者引入了一种名为「以人为中心的关系分割」(HRS)的新任务,该任务可以被视为人物交互检测的细粒度版本。 HRS 旨在预测人类与周围实体之间的关系并识别与关系相关的人体部位,我们将这些部位表示为像素级掩码。对于上述示例,HRS 任务产生的输出为关系三元组 <girl [left hand], hold, book> 的形式,并给出精确分割出来的书本掩码,机器人可以轻松完成抓取任务。
本文作者为这项新任务收集了一个新的数据集——Person In Context (PIC) ,该数据集包含 17,122 张高分辨率图像和密集注释的实体分割和关系,包括 141 个对象类别、23 个关系类别和 25 个语义人体部位。
本文作者还提出了同时进行匹配和分割 (SMS) 的框架,该框架可以作为 HRS 任务的解决方案。 它将实体分割、主语宾语匹配、人物解析三个分支的输出融合,从而以产生最终的 HRS 结果。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册