隐私保护机器学习研究综述
2021.06.20 14:23浏览量:421简介:隐私保护机器学习中的问题定义和挑战章节内容
论文标题:SoK: Training Machine Learning Models over Multiple Sources with Privacy Preservation
其中,该文献于2020年12月6号发表,算是最新的隐私保护机器学习领域的研究综述。
一、定义
今天,主要带来的是隐私保护机器学习中的问题定义和挑战章节内容。我们首先来了解下什么是隐私保护机器学习。
如图1所示,考虑以下场景时:一组数据属主 (他们可能是半诚实的,甚至是恶意的) 计划在他们拥有的数据上联合训练一个机器学习模型,并提供安全保证(只考虑安全训练阶段,忽略安全推断)。 请注意,这里的重点是安全训练阶段,这是更通用的,因为在进行训练时,安全推断自然是隐含的。 这些数据属主在训练期间与 (或不与) 集中式服务器通信。 但是,它们不会将原始数据上传到集中服务器(或其他数据属主)。
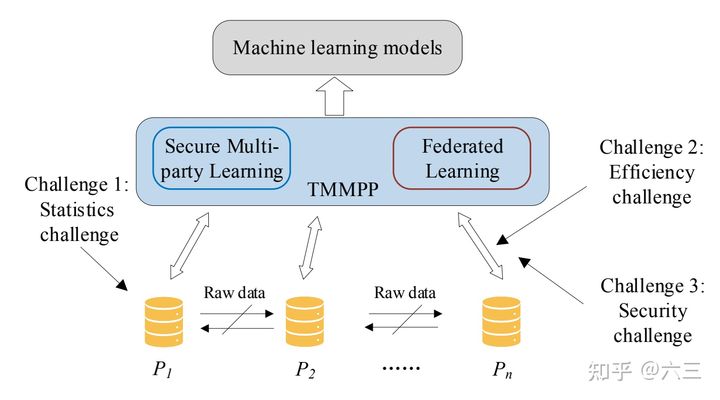
图1 具有隐私保护的多个数据源上的训练机器学习模型的结构
二、挑战
作者总结了三个关键挑战,即,当我们解决 TMMPP 问题时,
1)统计挑战
2)效率挑战
3)安全挑战
2.1 统计挑战
数据属主所掌握的数据通常是以非IID(not independent and identically distributed)的方式产生或收集的,即数据可能不是独立的,或者有明显的分布差别,甚至既不独立也不相同分布。
此外,分布在各数据属主之间的数据量也可能有很大差异,换句话说,数据是不平衡的。非IID和不平衡的数据使得训练一个高质量的机器学习模型变得困难,并且可能会增加分析、评估的复杂性。例如,占总数据量很大一部分的数据属主,在集中式服务器聚合模型参数的阶段会起到决定性的作用,从而影响模型的性能。
2.2 效率挑战
效率是TMMPP的重要瓶颈,包括通信开销和计算复杂性。在多个数据源上训练机器学习模型,涉及到大量的数据属主 (例如在FL的场景中,就有数百万个数据属主)。由于保护每个数据主隐私的安全要求,它们之间的通信带来了额外的开销,相比于原始数据的本地计算,开销增加了很多数量级。
此外,在MPL框架中,通信和计算的成本很大程度上取决于底层协议。例如,基于HE的协议通常会导致较高的计算复杂度,而基于GC的协议通常会导致昂贵的通信开销。一般来说,为了提高MPL框架的效率,应该在通信开销和计算复杂度之间进行权衡。
2.3 安全挑战
每个数据控属主和集中式服务器都不能完全信任。 他们中的一些人可能是 adversaries,他们可以以某种方式对私人信息进行攻击或干扰训练算法的正常执行。
此外,FL通过交换模型参数(例如局部梯度)而不是原始数据来保护每个数据控制器的数据。 然而,如果对这些梯度进行推算操作,这些梯度可能会泄漏原始数据的敏感信息,从而导致集中式服务器在聚合这些梯度过程中的隐私泄漏。

发表评论
登录后可评论,请前往 登录 或 注册