视频分类之多模态融合
2021.07.12 09:00浏览量:685简介:以视频-文本两个模态为例,介绍多模态视频数据分类模型设计思路。
前言
之前介绍的主要是在处理视频数据的时候一些常用的算法,但是在视频理解相关业务中,往往用的到不仅仅是视频数据,还会有文本和音频信息,在图像相关任务中,也会有多模态算法,比如VCR等等,而且视频的多模态算法,往往也是从图像多模态任务中迁移过来,特别是Transformer、BERT系列逐步在CV领域成功应用越来越多,目前基于Transformer(或者说BERT)处理多模态视频数据已经逐渐成为了主流。参考学术界论文最多的任务,这里也以视频-文本两个模态为例。
多模态融合
这里首先借用VILT论文中的一个示意图。
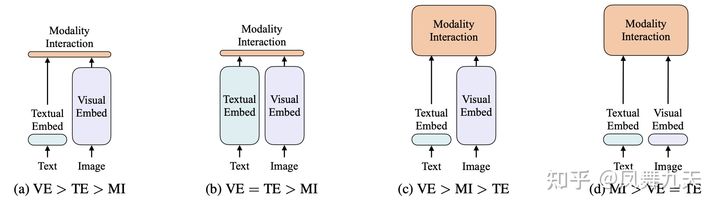
个人感觉这张图总结的比较清晰,多模态模型一共分为三个模块:Text embedding 模块、Visual embedding 模块和Modality Interaction模块,分别代表了文本特征提取,图像(视频)特征提取和多模态融合。在图中每个模块的面积代表了各个模块参数的多少。其中(a) 和 (b) 中 Modality Interaction 参数比较少,(c)和 (d)中 Modality Interaction 参数比较多。可以说自己用过的模型,涵盖了(a),(b),(c)三种结构((d)结构是论文VILT新提出来的结构,自己还没有用过)。
(a)结构:其中Text embedding 模块用的是nlp中word2vec进行特征提取,Visual embedding 则是用Resnet进行特征提取,Modality Interaction模块用的是《Learnable pooling with Context Gating for video classification》中的Context Gating 结构,这个结构很简单,整个模型主要参数集中在Visual embedding中;
(b)结构:其中Text embedding 模块用的是nlp中bert模型进行特征提取,Visual embedding 则是用Resnet进行特征提取,Modality Interaction模块用的是《Learnable pooling with Context Gating for video classification》中的Context Gating 结构;
在自己实际应用中,(a)结构和(b)结构各有特点,一般来说,(b)结构效果会比(a)要好一些,bert效果确实没得说。
(c)结构:其中Text embedding 模块用的是nlp中word2vec进行特征提取,Visual embedding 则是用Resnet进行特征提取,Modality Interaction模块用的就是Transformer的encoder(BERT)模型。
多模态Transformer
这里对多模态Transformer做进一步说明,目前利用Transformer做多模态融合这个领域内相关的论文比较多,也算是当前研究比较多的一个方向。模型结构大同小异,基本上是都是首先得到文本的embedding和图像(视频)的embedding,然后特征拼接送入Transformer,但是类似于Bert用法,这样的好处是可以进行大数据的预训练,根据各个模态不同的形式,可以设计不同的预训练任务,当然,最重要的仍然是MLM任务以及ITM任务。由于论文太多,各个模型的细节也都有gap,很难在一篇文章中将所有模型讲好,所以这里只能是整体概括多模态Transformer一般套路。

发表评论
登录后可评论,请前往 登录 或 注册