清华大学计算机系信息检索组:司法类案检索技术研究进展
作者:发出毛毛毛毛的声音2021.07.15 15:47浏览量:2463简介:司法类案检索成为人工智能技术与法治现代化建设密切衔接的重要应用场景
背景介绍
随着计算机和人工智能技术在司法领域的深度融合发展,司法类案检索成为人工智能技术与法治现代化建设密切衔接的重要应用场景。类案检索作为人工智能支持司法审判的重要内容,对于提升法院整体裁判水平、实现类案适法统一、促进司法公正有极其重要的积极意义。2020年7月,最高人民法院颁布了《关于统一法律适用加强类案检索的指导意见(试行)》,进一步从规范层面确立了特定案件的类案强制检索制度,同时也对类案检索系统的性能提出了更高期待。
当前司法类案检索在应用中凸显出“类而无用”、“千人一面”、缺反馈缺评价等问题,导致用户使用率和满意度较低,无法满足多主体检索需求。与此同时,根据《中国法院信息化发展报告No.5(2021)》,我国已经建成世界上最大的司法审判信息资源库,司法裁判文书的半结构化、逻辑性、数据体量等优势为计算机和人工智能领域构建认知模型,提高算法的鲁棒性和可解释性提供了良好的应用场景。
近年来,清华大学计算机系信息检索组对司法类案检索问题开展了较为系统的研究。2021年,相关研究工作集中在面向司法类案检索的用户行为模型构建、性能评价语料库建设、对话式交互模式探索三方面,相关成果发表在ACM SIGIR 2021会议。
面向司法类案检索的用户行为模型构建

论文标题:Investigating User Behavior in Legal Case Retrieval
论文作者:邵韵秋(清华大学)、吴玥悦(清华大学)、刘奕群(清华大学)、毛佳昕(中国人民大学)、张敏(清华大学)、马少平(清华大学)
论文收录:SIGIR 2021 Full Paper
1. 研究动机
我们认为,缺乏从用户视角的技术研究和系统设计是造成当前类案检索应用存在诸多瓶颈的关键原因。近年的类案检索研究主要侧重于构建自动类案检索模型以提升检索性能,但缺乏对类案检索过程中用户和系统的交互研究。与传统网页检索场景相比,类案检索在目标用户、检索工具和相关性定义等多方面均有差异。我们尝试通过类案检索的用户行为研究,为实现政策、模型和用户三者的对齐提供可靠依据和基础。
2. 用户实验
本文通过用户实验,收集类案检索过程中用户的查询,浏览,点击,悬停,鼠标滚动等行为,细粒度地研究了该搜索场景下的用户行为,主要研究了:1)类案检索与传统网页检索用户行为的差异;2)类案检索中用户行为的影响因素(例如:用户的专业水平,任务的难度);3)用户行为的隐式反馈及其对于类案检索系统的启发。

- 图:用户实验流程图及实验系统界面样例(结果列表页面和案例详情页面)
3. 实验结果
实验结果表明,类案检索中的用户行为与传统网页检索中的有显著差异,类案检索的过程主要为探索式的检索过程,用户付出的搜索代价会更高。
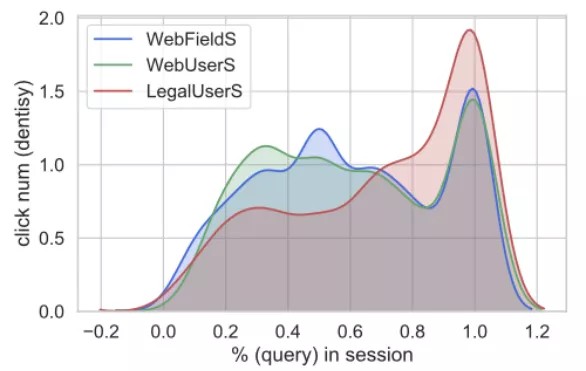
- 图:用户在一个搜索会话中的点击分布
在类案检索中,相较于用户的专业水平,任务难度对于用户的搜索行为有更为显著的影响。在查询中使用正确的案由有利于提升搜索效用。同时,利用裁判文书本身的结构特征结合用户在详情页上的浏览行为可以有效预测结果案例的相关性,进一步可以辅助系统进行相关性反馈。
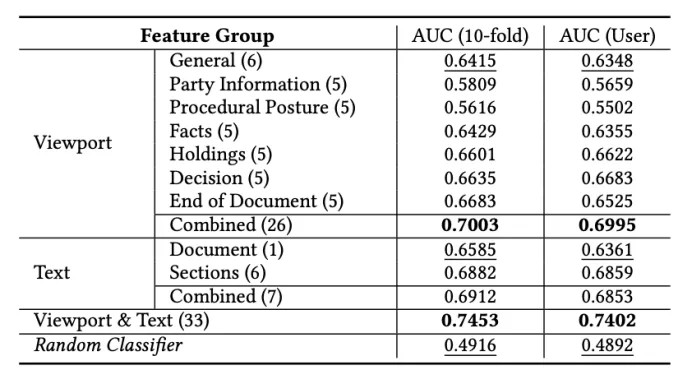
- 图:利用用户的viewport特征预测类案相关性
4.研究贡献
本文构建了类案检索场景下用户行为数据集,归纳了用户探索式的搜索过程,论证了利用用户行为特征进行相关性反馈的有效性。本文的研究有助于启发类案检索系统的设计,例如,任务难度预测,查询推荐,相关性反馈等相关任务,此外也为其他专业搜索领域的研究提供了参考。
多样化类案检索语料集合构建

论文标题:LeCaRD: A Legal Case Retrieval Dataset for Chinese Law System
论文作者:马奕潇(清华大学)、邵韵秋(清华大学)、吴玥悦(清华大学)、刘奕群(清华大学)、张瑞喆(清华大学)、张敏(清华大学)、马少平(清华大学)
论文收录:SIGIR 2021 Resource Paper
1. 研究动机
多样化搜索作为信息检索领域的重要研究问题,旨在解决如何提升检索结果的多样性使之尽量满足不同用户的需求。尽管多样化搜索在信息检索领域已经有较为丰富的探索,但是司法类案检索的多样化研究尚未引起重视,类案检索中subtopic的封闭性特点使之成为研究多样化搜索的绝佳场景。
2. 数据集构成
基于真实场景的类案检索需求,我们将类案检索的任务定义为:对于给定的案情描述,从候选案例中检索出与之相关的案例。我们构建了基于中国刑事判决书的类案检索数据集LeCaRD,其中包含107个查询案例和43,823个候选案例。查询案例和候选案例均取自中国裁判文书网。
- 图:LeCaRD 数据集基本构成
3. 考虑多样性的相关性判断标准
我们基于最高人民法院颁布的类案检索指导意见建立了考虑结果多样性的四级类案相关性判断标准,并由法律专家对相应候选案例进行了人工标注。

- 图:相关性判断标准

- 图:LeCaRD 数据集的query和candidate实例
4. 兼顾多样性和难度的查询采样策略
考虑到中国刑事案件案由分布不均衡的特点,我们选取了排名前二十的常见罪名,并通过法律判决预测模型分别对每个罪名下的案例进行预测,根据预测准确率和熵值挑选出77个查询案例。查询采样的另一部分来自于改判数据集,我们认为二审或再审改判的案件往往具有较高的难度。通过计算改判可能性,从排名前二十的每个常见罪名中分别采样30个查询。
5. 数据集评估
我们选取了基于词袋的常用传统检索模型,包括BM25、TF-IDF 和 LMIR,以及基于法律语料训练的BERT模型作为LeCaRD类案检索的baseline。不同模型在普通查询案例和有争议查询案例中体现出了性能差异。
- 图:评估不同模型在LeCaRD不同查询类型的表现
6.研究贡献
我们构建了第一个中文刑事类案检索数据集LeCaRD,首次提出了基于多样性的类案相关性判断标准,创新采用了兼顾不同难度和案件多样性的查询案例采样策略,并通过评估实验进一步证明了司法类案检索的挑战性。
LeCaRD下载地址:https://github.com/myx666/LeCaRD
对话式交互在司法类案检索中的应用

论文标题:Conversational vs Traditional: Comparing Search Behavior and Outcome in Legal Case Retrieval
论文作者:刘布楼(清华大学)、吴玥悦(清华大学)、刘奕群(清华大学)、张帆(清华大学)、邵韵秋(清华大学)、李晨亮(武汉大学)、张敏(清华大学)、马少平(清华大学)
论文收录:SIGIR 2021 Short Paper
1. 研究动机
对话式搜索在满足用户的复杂性需求和探索性需求中的价值已经得到了广泛认可。我们认为,用户在进行司法类案检索过程中面临着难以准确构建查询,难以精准表达信息需求的困难,尤其是在缺乏足够的专业知识的情况下信息需求表达困难格外突出。尽管当前基于专业知识场景的人机对话搜索研究尚未成熟,作为一项前瞻性研究,我们从用户行为和搜索结果的角度,探索了对话式交互的范式是否可以应用于典型的探索式复杂信息搜索场景——司法类案检索。
2. 用户实验
本文通过用户实验,收集了类案检索过程中用户的查询数量,浏览数量、悬停时间等行为,并结合用户专业水平研究了对话式类案搜索场景下的用户体验,主要研究了:1)传统式类案搜索与对话式类案搜索用户交互行为的差异;2)传统式类案搜索与对话式类案搜索结果的差异。由于没有成熟的人机对话式类案检索系统,我们通过聘请法律专家作为agent的方式完成实验。
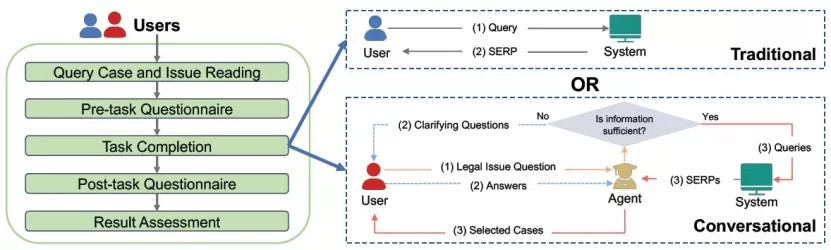
- 图:传统式与对话式类案搜索流程对比图
3. 实验结果
1)用户交互行为差异分析
实验结果表明,无论专业知识水平如何,对话式搜索都可以降低用户在司法类案检索中查询构造和结果检查的工作负担;同时,相比传统式类案搜索,在对话式搜索中用户检索更有耐心地检查结果案件。
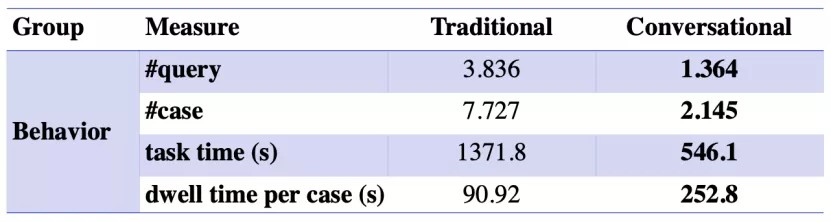
- 图:传统式与对话式类案搜索用户交互行为对比
2)检索结果差异分析
实验结果表明,相较于传统式类案检索,在对话式类案搜索中用户的主观感知的工作负担更少,满意度和成功率更高。同时,在对话式类案搜索中用户可以更准确地表达自己的信息需求,并且获得更加准确的搜索结果。
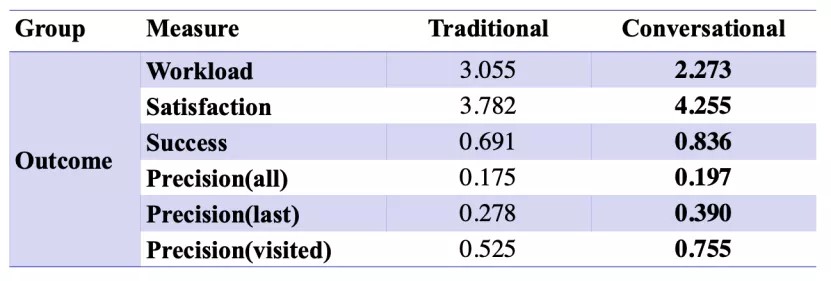
- 图:传统式与对话式类案搜索结果对比
4.研究贡献
本文首先定义了司法类案检索信息需求的复杂性和探索性特征,并提出了将其与对话式搜索范式相想结合的前瞻性研究方法。揭示了采用对话式搜索范式进行案件检索的必要性和合理性。同时,本文还发布了第一个对话式司法类案检索数据集。为进一步进行对话式类案检索的自动化建模奠定了良好的研究基础。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册