DHT算法的一知半解
作者:中二柚2021.08.23 16:46浏览量:803简介:读取哈希表的数据(Value),只需提供key,哈希表即可取得映像到该键值的完整数据。
如果所有的数据结构只能留下一种,那可能就是哈希表。
哈希表是一种能高效进行数据读取/写入的数据结构,通过哈希函数可以将任意的数据映像到固定长度的随机字符串,由于函数具有单向性与唯一性,因此这个随机字符串可以作为辨识数据的指纹,即Key。读取哈希表的数据(Value),只需提供key,哈希表即可取得映像到该键值的完整数据。
DHT,Distributed Hash Table,即分布式哈希表,应用于网络之上的覆盖网络,典型的应用场景就是点对点网络(P2P网络)。关于P2P 网络,可以参考《这是你所了解的P2P么》一文。在P2P网络中,有着结构化,半结构化和非结构化的系统分类。在结构化P2P系统中,每个节点只存储特定的信息或特定信息的索引。当用户需要在P2P系统中获取信息时,必须知道这些信息(或索引)可能存在于那些节点中。由于用户预先知道应该搜索哪些节点,避免了非结构化P2P系统中使用的洪泛式查找,因此提高了信息搜索的效率。
结构化P2P 用纯分布式的消息路由,目前的主流方法是采用分布式哈希表(DHT)技术。在不需要服务器的情况下,每个客户端负责一个小范围的路由,并负责存储一小部分数据,从而实现整个DHT网络的寻址和存储。DHT 各节点并不需要维护整个网络的信息,节点仅存储其临近的后继节点信息,因此较少的路由信息就可以有效地实现资源定位。该P2P 网络模式有效减少了资源定位的开销,提高了P2P 网络的可扩展性。
DHT的去中心化提供了相比于传统的键值对存储更好的优势。包括:
扩展性:哈希请求最多为对数次查找即可解决。
通过冗余进行容错。即可能每一个节点都加入或离开DHT。另外,如果一个节点反应缓慢或者不可达,请求可以连接到其他节点。
负载均衡,请求可以发送到任何节点,没有任何一个节点处理所有的请求,例如基于DHT的DNS服务能够拥有更好的负载均衡特性。
那么,DHT 是如何实现P2P网络中的寻址或者路由呢?
如果key是某个实体的标识,value是实体的具体地址,则DHT 就可以用来选址。在Ethereum中,DHT就作为一种高效的对等节点选择机制(PeerSelection)。所有可能出现的实体识别集合,称之为键值空间(Key Space)。如果以m表示识别符的位数,若m=160,则键值空间大小为2¹⁶⁰。于是,通过对键值空间进行不同的设计,就出现了不同的DHT算法,通过这些算法即可实现在P2P网络中的寻址或者路由。
DHT 算法之 Kademlia
Kademlia于2002年被Petar Maymounkov和David Mazieres两人发表,Ethereum也使用Kademlia作为GossipProtocol的节点选择机制,IPFS更是引入改良后的S/Kademlia作为核心。
Kademlia 使用 m 位整数作为节点和资源的唯一标识。与 Chord 中的 “区间负责制” 不同, Kademlia 中的资源都是被离它最近的节点负责。出于容错考虑, 每个资源通常都被距离它最近的 k 个节点负责, 这里 k 是一个常量, 通常取 k 使得在系统中任意 k 个节点都不太可能在一小时之内同时失效。
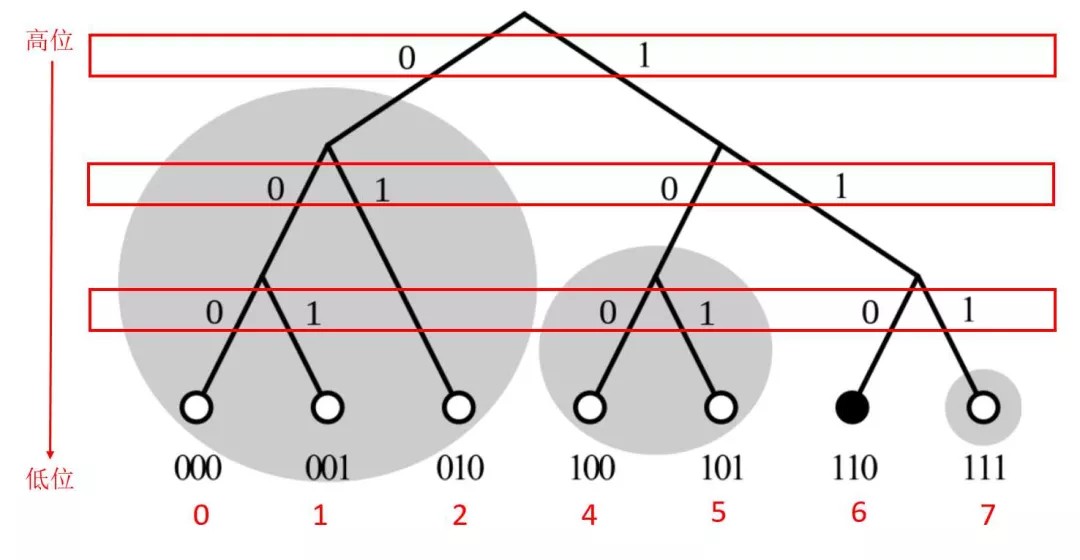
Kademlia的键值空间可以表示成一棵二叉树 每个节点都可以看作一颗高度为 m + 1 的二叉树上的叶子节点。把 ID 二进制展开, 从最高位开始, 自根节点逢 1 向左逢 0 向右, 直到抵达叶子节点。节点的距离则定义为XOR运算结果。也就是说,两实体标识的距离可以视为其差异程度。异或运算的特点是异为真同为假, 如果两个 ID 高位相异低位相同, 它们异或的结果就大; 如果它们高位相同低位相异, 异或的结果就小。这与二叉树中叶子的位置分布是一致的: 如果两个节点共有的祖先节点少(高位相异), 它们的距离就远; 反之, 如果共有的祖先节点多(高位相同), 它们的距离就近。
这种通过“异或”进行的距离测量,具有以下几何特征:
(A ⊕ B) == (B ⊕ A): XOR 符合“交换律”,具备对称性。A和B的距离从哪一个节点计算都是相同的。
(A ⊕ A) == 0: 反身性,自己和自己的距离为零。
(A ⊕ B) > 0: 两个不同的 key 之间的距离必大于零。
(A ⊕ B) + (B ⊕ C) >= (A ⊕ C): 三角不等式, A经过B到C的距离总是大于A直接到C的距离。
Kademlia 的路由
Kademlia的路由表切分成不同的距离区间,查询过程可视为从一棵子树跳到另一棵子树,直到找到与目标最近的子树为止。因此,Kademlia属于高效的二元搜寻。Kademlia的距离对称性使得每个新节点加入后可以同步更新其每个新邻员的路由表,大幅增加网络效率。而最近更新的节点,则会是k桶当中的查询的第一顺位,这又再次增加了Kademlia的强健性。
对于任意一个给定节点, 二叉树从根节点开始不断向下分成一系列不包含该节点的子树。最高的子树由不包含该节点的二叉树的一半组成, 下一个子树又由不包含该节点的剩余树的一半组成, 以此类推。如果这个二叉树的高度为 m + 1, 最终会得到 m 个子树。接着,在每个子树中任取 k 个节点, 形成 m 个 k 桶(k-bucket), 这 m 个 k 桶就是 Kademlia 节点的路由表。下图展示了 m = 3, k = 2 时节点 101 的 k 桶。

Kademlia 中每个节点都有一个基础操作, 称为 FIND_NODE 操作。FIND_NODE 接受一个 Key 作为参数, 返回当前节点所知道的 k 个距离这个 Key 最近的节点。基于 k 桶, 先求出这个 Key 与当前节点的的距离 d, 第 i个 k 桶中节点与当前节点的距离总是在区间2^i~2^(i+1)之内, 这些区间都不会互相重叠, 那么,d落在的区间所属的 k 桶中的节点就是距离这个 Key 最近的节点。如果这个 k 桶中的节点不足 k 个, 则在后一个 k 桶中取节点补充, 如果还不够就再在后一个 k 桶中取。如果这个节点所有的 k 桶中的节点数之和都不足 k 个, 就返回它所知道的所有节点。
Kademlia 中最重要的过程是节点查找,给定一个 Key, 找出整个系统中距离它最近的 k 个节点。这是一个递归过程: 首先初始节点调用自己的FIND_NODE, 找到 k 个它所知的距离 Key 最近的节点。接下来,在这 k 个节点中取 α个最近的节点, 同时请求它们为 Key 执行 FIND_NODE。这里的 α也是一个常量, 作用是同时请求提高效率, 例如 α=3。
在接下来的递归过程中, 初始节点每次都在上一次请求后返回的节点中取 α个最近的, 并且未被请求过的节点, 然后请求它们为 Key 执行FIND_NODE, 以此类推。每执行一次, 返回的节点就距离目标近一点。如果某次请求返回的节点不比上次请求返回的节点距目标 Key 近, 就向所有未请求过的节点请求执行 FIND_NODE。如果还不能获取更近的节点, 过程就终止。这时,在其中取 k 个距离 Key 最近的节点, 就是节点查找的结果。
Kademlia 的拓扑结构是单向的, 其他离目标资源比自己远的节点在查找时就很可能会经由缓存的节点, 这样就能提前终止查找, 提高了查找效率。
Kademlia节点的加入与退出
要想加入 Kademlia, 首先使用一些算法生成自己的 ID, 然后它需要通过一些外部手段获取到系统中的任意一个节点 n′, 把 n′加入到合适的 k 桶中。然后对自己的 ID 执行一次节点查找。在查找的过程中新节点 n′就能自动构建好自己的 k 桶, 同时把自己插入到其他合适节点的 k 桶中。
节点加入时除了构建 k 桶之外, 还应该可以取回这个节点应负责的资源。Kademlia 的做法是每隔一段时间(如按小时),所有的节点都对其拥有的资源执行一次发布操作; 此外,在每隔一段时间(如按天)节点就会丢弃这段时间内未收到发布消息的资源。这样新节点就能收到自己须负责的资源, 同时资源总能保持被 k 个距离它最近的节点负责。
为了优化重复发布, 当一个节点收到一个资源的发布消息, 它就不会在下一个小时重发它。因为当一个节点收到一个资源的发布消息, 它就可以认为有 k - 1 个其他节点也收到了这个资源的发布消息。只要节点重发资源的节奏不一致, 这就能保证每个资源都始终只有一个节点在重发。
鉴于此, 不需要为节点的失效和离开做任何其它的工作,这也是 Kademlia 的容错性要高于其他分布式哈希表算法。
DHT算法之 Chord
Chord 中每个key和节点都分别拥有一个m 比特的标识符。Key标识符K 通过哈希关键字本身得到,而节点标识符N 则通过哈希节点的IP 地址得到。哈希函数可以选用SHA-1。所有节点按照其节点标识符从小到大(取模2^m 后)沿着顺时针方向排列在一个逻辑的标识圆环上,称为Chord 环。
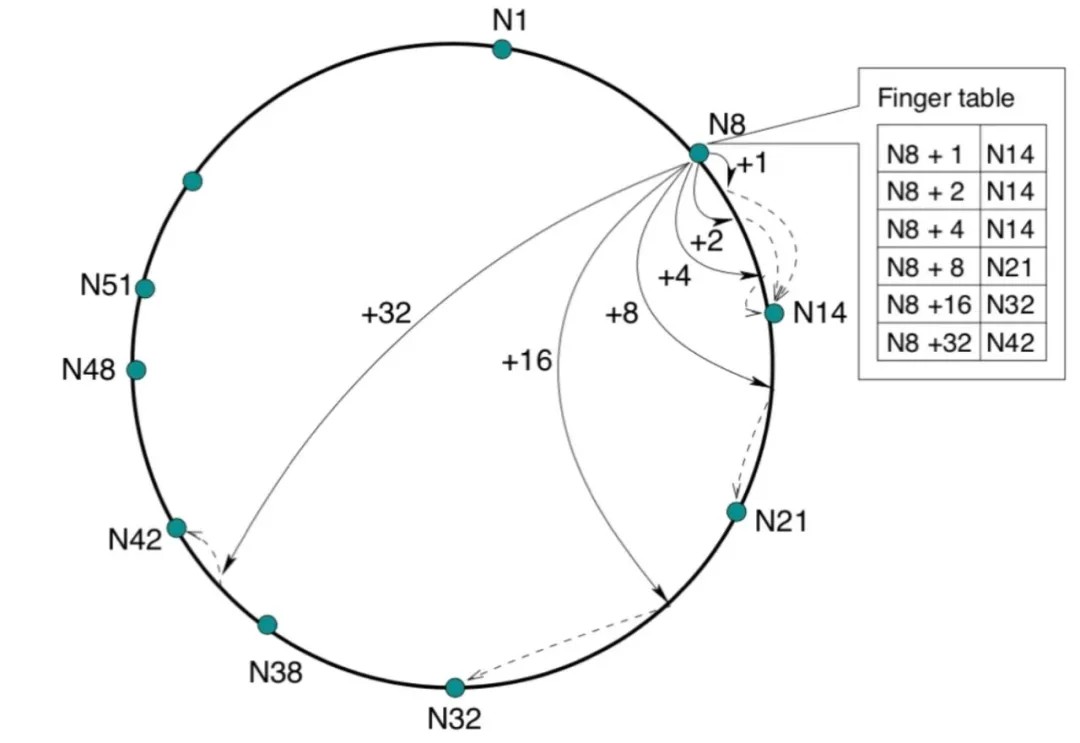
Chord 的映射规则是:关键字标识为K 的(K, V)对存储在这样的节点上,该节点的节点标识等于K 或者在Chord 环上紧跟在K 之后,这个节点被称为K 的后继节点,表示为successor(K)。因为标识符采用m 位二进制数表示,并且从0 到2^m-1 顺序排列成一个圆圈successor(K)就是从K 开始顺时针方向距离K 最近的节点。
Chord 的路由
为了快速查询,Chord每个节点需要维护一个路由表,称为指针表。如果关键字和节点标识符用m 位二进制位数表示,那么指针表中最多含有m 个表项。节点n 的指针表中第i 项是圆环上标识大于或等于n+2^(i-1) 的第一个节点。例如若s=successor(n+2^(i-1)), 1≤i≤m,则称节点s为节点n 的第i 个指针,就是节点n 的后继节点。指针表中每一项既包含相关节点的标识,又包含该节点的IP 地址和端口号。
维护指针表使得每个节点只需要知道网络中一小部分节点的信息,而且离它越近的节点,它就知道越多的信息。
任何一个节点收到查询关键字K 的请求时,首先检查K 是否落在该节点标识和它的后继节点标识之间,如果是的话,这个后继节点就是存储目标(K, V)对的节点。否则,节点将查找它的指针表,找到表中节点标识符最大但不超过K 的第一个节点,并将这个查询请求转发给该节点。通过重复这个过程,最终可以定位到K 的后继节点,即存储有目标(K, V)对的节点。
Chord节点的加入和退出
为了应对系统的变化,每个节点都周期性地运行探测协议来检测新加入节点或失效节点,从而更新自己的指针表和指向后继节点的指针。新节点n 加入时,将通过系统中现有的节点来初始化自己的指针表。这时,系统中一部分关键字的后继节点也变为新节点n,因而先前的后继节点要将这部分关键字转移到新节点上。当节点n 失效时,所有指针表中包括n的节点都必须把它替换成n 的后继节点。为了保证节点n 的失效不影响系统中正在进行的查询过程,每个Chord 节点都维护一张包括r 个最近后继节点的后继列表。
DHT算法之Pastry
Pastry 是自组织的覆盖网络结构,每个节点都被分配一个128 位的nodeId。nodeId 用于在环形的节点空间中(从0 到2^128-1)标识节点的位置,它是在节点加入系统时随机分配的,随机分配的结果是使得所有的nodeId 在128 位的节点号空间中均匀分布。nodeId 可以通过计算节点公钥或者IP 地址的哈希函数值来获得。Pastry使用一致性哈希作为哈希算法。哈希所得的键值为一维(实际上使用的是128bit的整数空间)。Pastry并没有规定具体应该采用何种哈希算法。
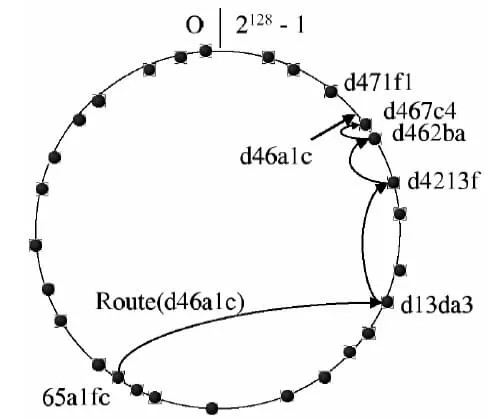
假设网络包含N 个节点,Pastry 可以把一个给定的关键字路由到nodeId 和该关键字最接近的节点。即使发生节点失效,Pastry 也可以保证关键字送达目标节点,除非nodeId和关键字临近的节点中有半数同时失效。每个节点把查询消息转发给下一个节点时,要保证这个节点的nodeId 和关键字的相同前缀至少要比当前节点的nodeId 和关键字的相同前缀长一个数位(即b 个比特)。如果找不到这样的邻居节点,消息将转发给前缀长度相同但是节点号数值更接近关键字的节点。为此,每个Pastry 节点都需要维护状态表:一张路由表,一个邻居节点集和一个叶子节点集。在应用层能够及时准确地获得这两个集合的节点信息时,可以大大加快路由查找的速度,同时降低因路由引起的网络传输开销;不过在动态变化的P2P网络中如何理想地做到这一点的确有很大的难度。
Pastry 的路由
Pastry的路由利用了成熟的最大掩码匹配算法,实现时可以利用很多现成的软件算法和硬件框架,可以获得很好的效率。
Pastry 的节点收到一条查询消息时,首先检查该消息的关键字是否落在叶子节点集范围内。如果是,则直接把消息转发给对应的节点,也就是叶子节点集中nodeId和关键字最接近的节点。如果关键字没有落在叶子节点集范围内,节点就会把消息转发给路由表中的一个节点,该节点的nodeId 和关键字的相同前缀至少要比当前节点的nodeId 和关键字的相同前缀长一个数位。如果路由表中相应的表项为空,或者表项中对应的节点不可达,这时候查询消息将被转发给前缀长度相同但是节点号数值更接近关键字的节点。
Pastry节点的加入和退出
Pastry是完全分布式的、可扩展的和自组织的,它能够自动应对节点加入、离开和失效。
新节点加入时需要初始化自身的状态表,并通知其他节点自己已经加入系统。假定新加入节点的nodeId 为Y,同时Y 在加入Pastry 之前已经知道系统中和自己距离相近的节点C。新节点Y 首先请求C 路由一条“加入”消息,消息的关键字就是Y。这条消息最终会到达nodeId和Y 最接近的节点Z。Pastry 一旦节点检测出其叶子节点集L 中的某个节点失效,它就会请求该集合中nodeId 最大或最小的节点把其叶子节点集L’发送过来。当前节点将从L’中选择一个L 中没有的活动节点来替代失效节点。如果节点检测出其路由表中某项对应的节点失效,它将从该项所在的路由表行中选择另一个节点,要求该节点把路由表中对应位置的项发过来。
DHT算法之Tapestry
Tapestry 目前使用160 比特的标识符空间,标识符用一个全局统一的进制表示,所有的节点依据标识符自组织成一个覆盖网络。Tapestry 动态地把每个标识符G 映射到当前系统中一个节点上,该节点称为G 的根节点。如果某节点的NodeID=G,则这个节点就是G 的根节点。为了转发查询消息,每个节点需要维护一个邻居映射表,每个表项包括一个邻居节点的标识符和IP 地址。往GR 路由时,消息将沿着邻居指针向节点标识符在标识符空间中更接近G 的节点转发。
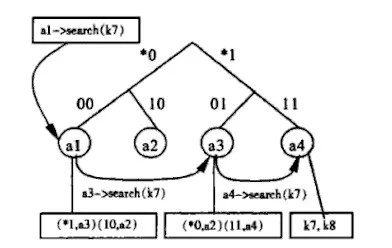
Tapestry 中的每个节点都保存有邻居映射表。邻居映射表可以用于把消息按照目的地址一位一位地向前传递,这种方式类似于IP 分组转发过程中的最长前缀匹配。节点N 的邻居映射表分为多个级别,每个级别包含的邻居节点的数量等于标识符表示法的基数,而每个级别中邻居节点标识符和本节点标识符的相同前缀都比前一级别多一个数位。
Tapestry 的路由
Tapestry 采用的基本查找和路由机制,当一条查找消息到达传递过程中的第n 个节点时,该节点和目的节点的共同前缀长度至少大于n。为了进行转发,该节点将查找邻居映射表的第n+1 级中和目的标识符下一数位相匹配的邻居节点。转发过程将在每个节点中依次进行直到到达目的节点。
Tapestry 中的节点在共享数据时被称为服务器,请求数据时被称为客户,转发消息时被称为路由器。也就是说每个节点可以同时具有客户、服务器和路由器的功能。服务器S通过向对象的根节点定期的发送消息来报告S保存有该对象。在这条发布路径上的每个节点都保存关于这个对象的位置信息指针,当多个都存有同一对象拷贝的服务器分别向根结点发布消息时,路径上的每个节点按各个服务器离自己的网络时延递增的顺序保存这些位置指针列表。
Tapestry节点的加入和退出
Tapestry 的节点加入算法和Pastry 类似。节点N 在加入Tapestry 网络之前,也需要知道一个已经在网络中的节点G。然后N 通过G 发出路由自己的节点ID 的请求,根据经过的节点的对应的邻居节点表构造自己的邻居节点表。构造完自己的数据结构后,节点N 将通知网络中的其他节点自己已经加入网络。通知只针对在N 的邻居映射表中的主邻居节点和二级邻居节点进行。
Tapestry 采用两种机制处理节点的退出。一种情况是节点从网络中自行消失(主要原因是节点失效),在这种情况下,它的邻居可以检测到它已经退出网络并可以相应的调整路由表。另一种机制是节点在退出系统之前通过后向指针通知所有把它作为邻居的节点,这些节点会相应调整路由表并通知对象服务器该节点已经退出网络。检测正常操作过程中的链路和服务器失效,可以使用TCP 连接超时机制。
DHT算法之 CAN
CAN 的设计基于虚拟的维笛卡尔坐标空间,这个坐标空间完全是逻辑上的,和任何物理坐标系统都没有关系。在任何时候,整个坐标空间动态地分配给系统中的所有节点,每个节点负责维护独立的互不相交的一块区域。CAN 中的节点自组织成一个代表这个虚拟坐标空间的覆盖网络。每个节点要了解并维护相邻区域中节点的IP 地址,用这些邻居信息构成自身的坐标路由表。基于路由表,CAN 可以在坐标空间中任意两点间进行寻址。

虚拟坐标空间当保存(K1, V1)时,使用统一的哈希函数把关键字K1 映射成坐标空间中的点P。那么这个值将被保存在该点所在区域的节点中。当需要查询关键字K1 对应的值时,任何节点都可以使用同样的哈希函数找到K1 对应的点P,然后从该点对应的节点取出相应的值V1。如果此节点不是发起查询请求的节点,CAN 将负责将此查询请求转发到P 所在区域的节点上。
CAN 的路由
CAN 中的路由很简单,沿着坐标空间中从发起请求的点到目的点之间的一条路径转发即可。为此,每个CAN 节点都要保存一张坐标路由表,其中包括它的邻居节点的IP 地址和其维护的虚拟坐标区域。两个节点互为邻居是指:在d维坐标空间中,两个节点维护的区域在d-1 维的坐标上有重叠而在剩下的一维坐标上相互邻接。每条CAN 消息都包括目的点坐标。进行路由的时候,节点只要朝着目标节点的方向把消息转发给自己的邻居节点即可。
如果一个d 维空间划分成n 个相等的区域,每个节点只需要维护2d 个邻居节点的信息。这个结果表明CAN 的可扩展性很好,节点数增加时每个节点维护的状态信息不变,而路由长度只是以n/d的数量级增长。坐标空间中两点之间可以有许多条不同的路径,所以单个节点的失效对CAN 基本上没有太大的影响。遇到失效节点时,CAN 会自动沿着其他的路径进行路由。
CAN的节点加入和退出
因为整个CAN 空间要分配给系统中现有的全部节点,当一个新的节点加入网络时必须得到自己的一块坐标空间。CAN 通过分割现有的节点区域实现这一过程。它把某个现有节点的区域分裂成同样大小的两块,自己保留其中的一块而另一块分给新加入的节点。
当节点离开CAN 时,必须保证它的区域被系统中剩余的节点接管,也即分配给其他仍然在系统中的节点。一般是由某个邻居节点来接管这个区域和所有的索引数据(K,V)对。如果某个邻居节点负责的区域可以和离开节点负责的区域合并形成一个大的区域,那么将由这个邻居节点执行合并操作。否则,该区域将交给其邻居节点中区域最小的节点负责。也就是说,这个节点将临时负责两个区域。
有些研究人员己经认识到基于结构化分布式哈希表的路由机制也有无法解决的问题。首先,经过哈希之后,结点的位置信息被破坏了,来自同一个子网的站点很可能结点号相距甚远,这不利于查询性能的优化。其次,基于哈希表的系统不能利用应用本身的信息,许多应用(比如文件系统)的数据本身是按照层次结构组织的,而使用哈希函数后,这些层次信息就丢失了。

小结
DHT 有很多的应用场景,P2P网络只是其中的典型应用之一。本文初步梳理了DHT的主流算法,这些算法的核心在于键值空间的设计。Kademlia 采用的是二叉树,Chord和astry 采用的是环状空间,Tapestry采用的是线性空间,而CAN 采用的则是笛卡尔坐标空间,不同数据结构的键值空间导致了不同的路由效率,以及物理网络距离的不同影响。基于不同的DHT算法,P2P网络的负载均衡会会同样导致路由延迟不同。P2P网络的动态性造成其稳定性不佳,像IPFS/Filecoin 则通过激励机制来试图保证网络的稳定性。
本文来自公众号: 喔家ArchiSelf
作者: 半吊子全栈工匠
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册