调研了1660篇CVPR2021论文,发现了自动驾驶的研究热点
2021.08.24 14:38浏览量:261简介:本文通过CVPR2021论文,分析了自动驾驶的研究热点。
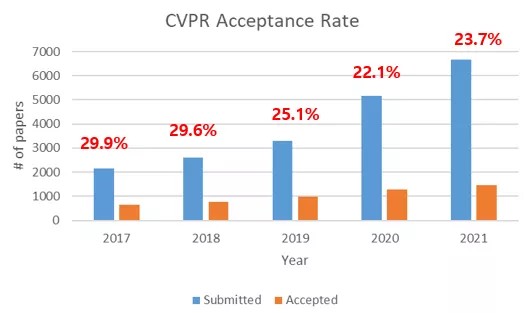
计算机视觉领域三大顶会之一的CVPR2021已经结束了,目前已公布了所有接收论文ID,一共有1663篇论文被接收,接收率为23.7%,接受率相比去年有所增加。从国外统计的数据上看,接受率和投稿率都在逐年增加,也说明了计算机视觉方向还是人工智能研究的热点和应用的焦点。
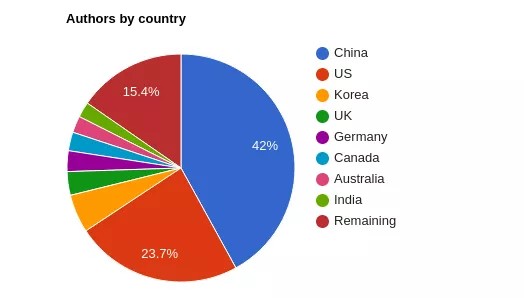
从接受作者所属的国家来看,中国占比仍然是最大的,而且审稿人和区域主席的数量也在增加来应对庞大的稿件数量。
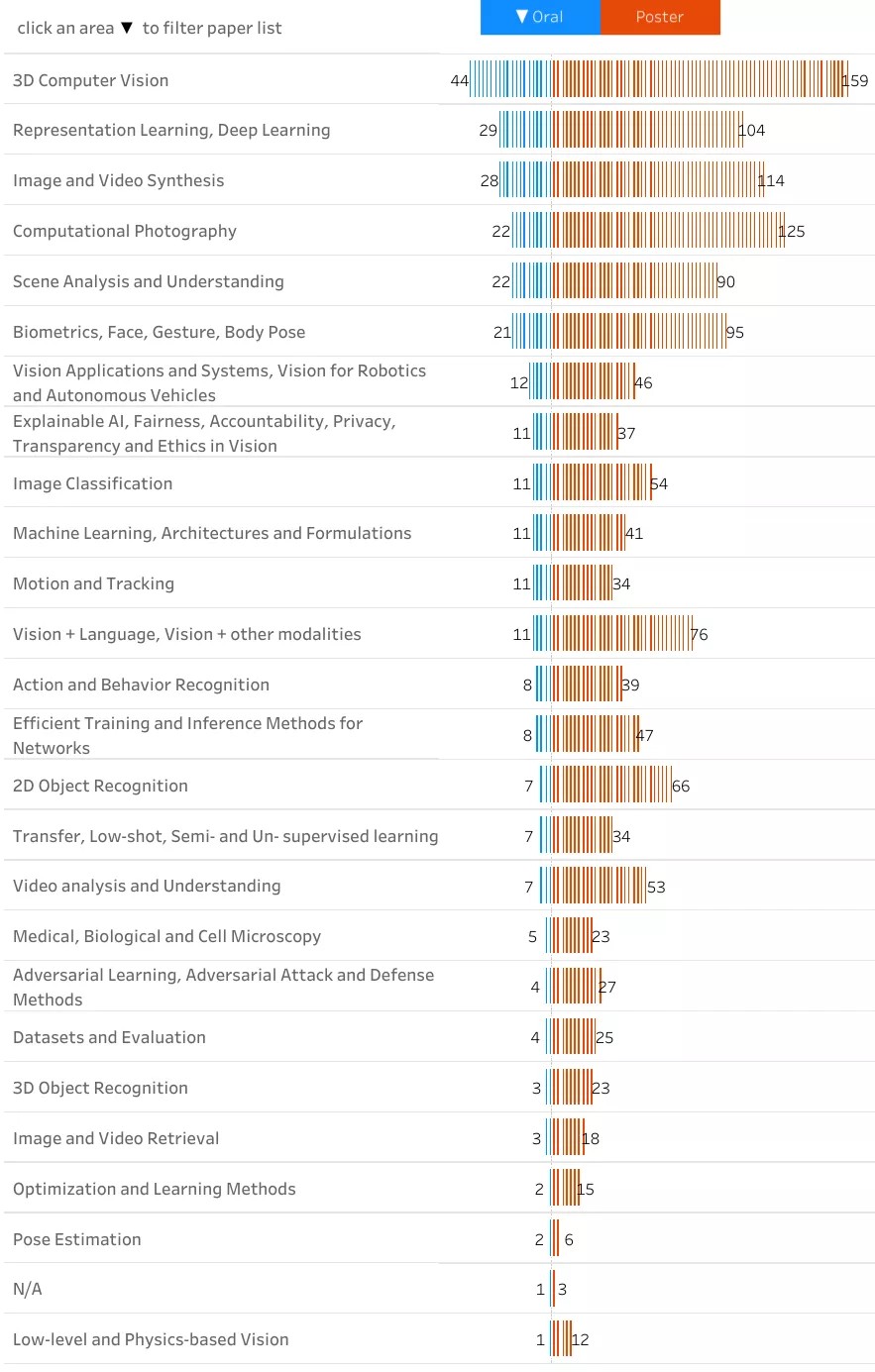
正如大家预想的那样,大多数被接受的论文都集中在与学习、识别、检测和理解等相关的主题上。然而,今年的主题是 3D 计算机视觉,仅此主题就有 200 多篇论文,其次是深度和表示学习、图像合成和计算摄影。可能因为疫情的影响,医学上的应用也有很多,可解释的人工智能和医学和生物成像相关的论文也显着增加。
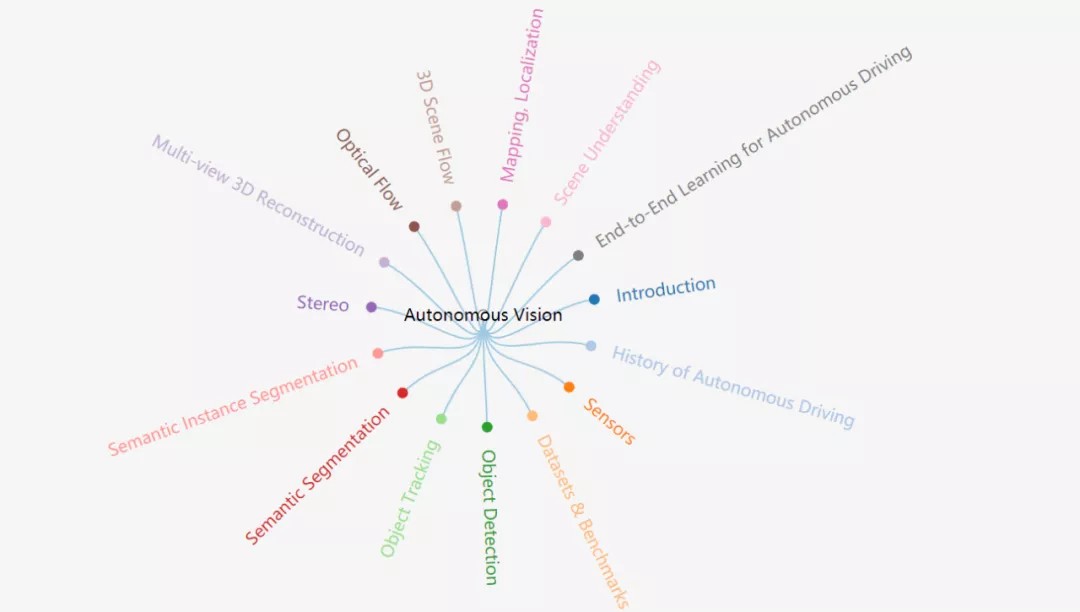
自动驾驶视觉是CV领域重要的应用方向之一,据不完全统计统计,大约有近百篇与自动驾驶视觉强相关的文章。其中涵盖的方向有:识别、重建、运动估测、追踪、场景理解,地图,目标感知,语义分割,立体视觉、数据集、光流等。
通过对这近百篇文章分析,我们总结了大概以下几个研究热点:
1.单目摄像头的3D视觉
2.多种语义分割模型
3.Transformer模型的引入
4.特殊场景的感知及预测
5.图像和视频的合成
6.场景分析与理解
下面列举了几个有意思的自动驾驶方面的论文,希望大家有所收获。
1.Multimodal Motion Prediction With Stacked Transformers
这是香港中文大学与商汤科技的合作项目,该论文主要研究了无人车多模态预测问题。毫无疑问,预测附近车辆的下一步轨迹,对于自动驾驶汽车系统了解周围环境并做出信息决策至关重要。目前的运动预测主要是两大类,基于特征的预测和基于提议的预测。该团队提出了一种端到端运动预测框架 mmTransformer,应该是最近比较火的Transformer模型的变体,这个模型的优势在于它能够通过考虑整个上下文来学习高质量的特征。通过将过去车辆的运动轨迹、道路信息和社会互动三大因素作为输入,再由几个Transformer编码器解码模块分层聚合,最终得到周围车辆的多模态运动预测。
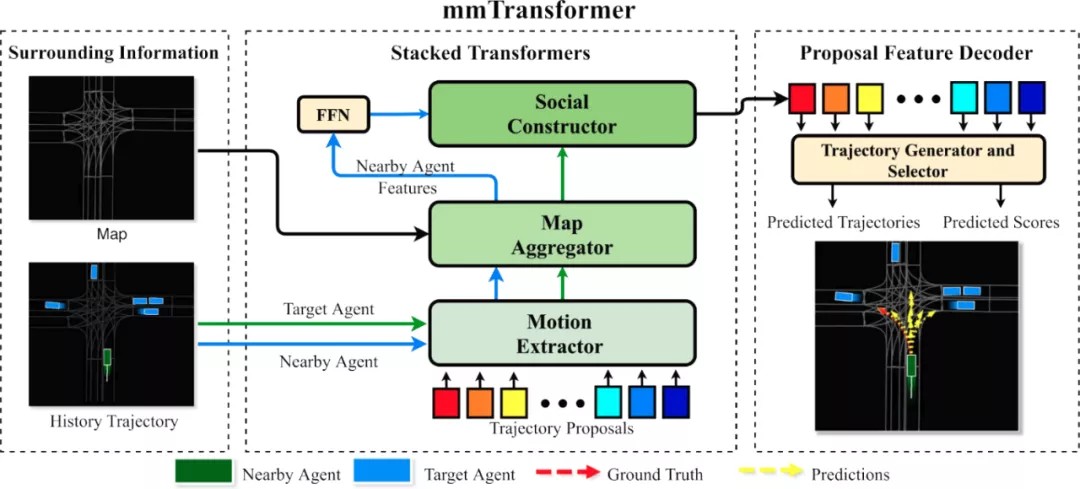
产生的效果如下图,本体车辆周围一定区域内,每个车辆都有三个箭头,显示了未来可能的三种运动轨迹。当然,三个箭头重合了那就表示,不存在换道的概率。
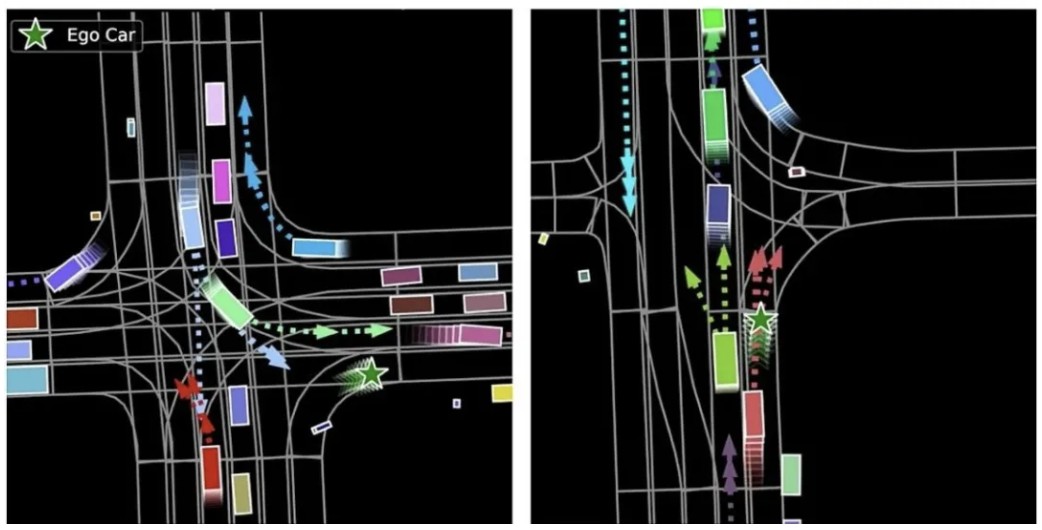
在Argoverse数据集上的实验表明,该模型在运动预测方面达到了先进的性能,大大提高了预测轨迹的多样性和精度。模型在2020年11月16日的Argoverse benchmark排行榜上排名第一,并且在排行榜上保持竞争力。
论文下载网站:https://arxiv.org/abs/2103.11624
2.Multi-Modal Fusion Transformer for End-to-End Autonomous Driving
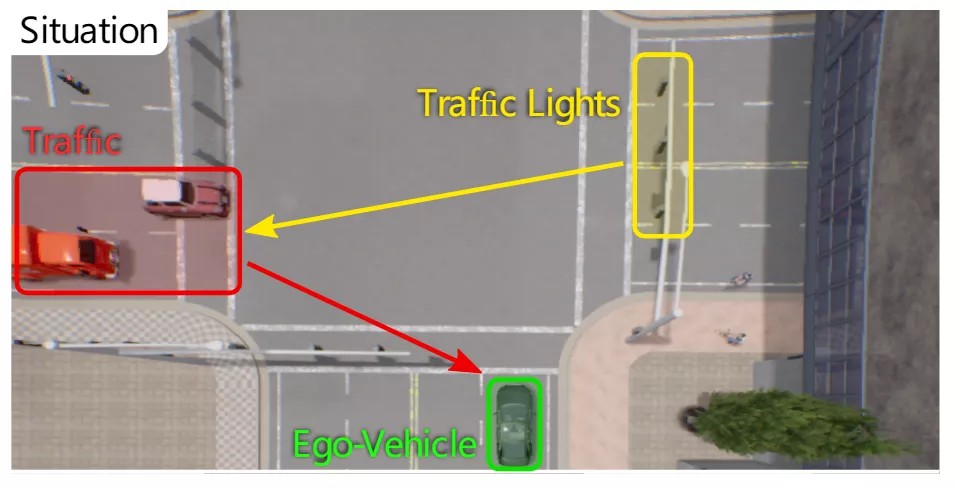
这篇文章是思考了一些极限场景的存在,比如本体车辆在一个十字路口准备右转汇入车流,横向的交通灯为绿灯,车辆正常行驶,这种情况下,由于四车道等外部条件的影响下,可能激光雷达扫描不到红色框里的来车,同时摄像头被左侧同车道的大车遮挡或者摄像头采集的兴趣点错过左侧来车,尽管用一种多传感器融合方案,左侧稀疏的点云特征也难以识别,发生碰撞的情况。
目前,相机和 LiDAR 传感器之间大多数是属于几何融合方法。3D 点云投影到图像空间(相机输入)中的像素,并从投影位置聚合信息。再把与这些投影位置对应的特征(使用卷积神经网络提取)组合在一起,而这种几何融合在涉及密集交通的复杂城市场景中往往表现不佳。
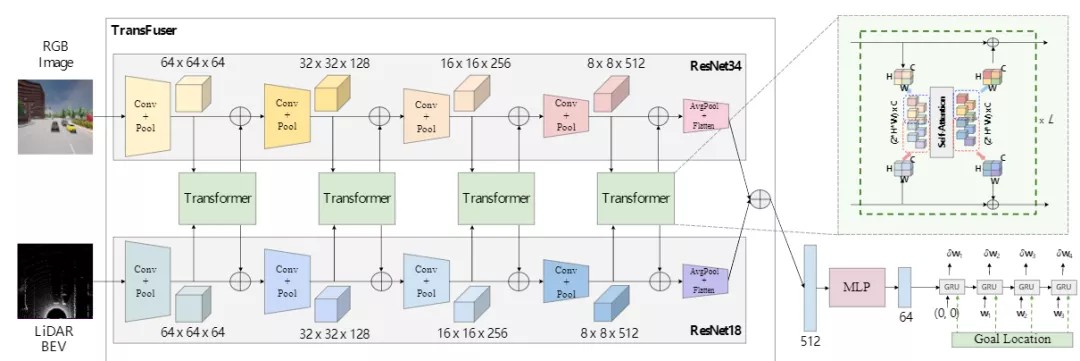
这篇文章使用了基于注意力的特征融合,让神经网络从两个传感器的相关区域聚合特征。这些相关区域分布在整个输入空间中,而不是仅限于投影位置(如几何融合),有助于捕获整个 3D 场景的全局上下文。
同时,他们提出了TransFuser模型,这是一种新颖的多模态融合Transformer,可以通过注意力机制融合图像和LiDAR数据。
RGB 图像和 LiDAR BEV(LiDAR 点云的自顶向下视图)作为模型的输入。这些数据由卷积神经网络(特别是ResNet模块)处理,产生不同分辨率的中间特征图。然后,使用Transformer将图像和 LiDAR 特征以多种分辨率结合起来。
整体的TransFuser模块输出一个特征向量,然后将其传递给基于 GRU 的自回归航路点预测网络。最终,将预测的航路点馈送到输出车辆控制的 PID 控制器。
该模型在CARLA环境中进行了广泛的实验,涉及一些复杂的场景,结果发现确实比一般的传感器融合感知效果要好很多。TransFuser 发生更少的碰撞和闯红灯,并且可以驾驭困难的场景。
3.Pixel-wise Anomaly Detection in Complex Driving Scenes
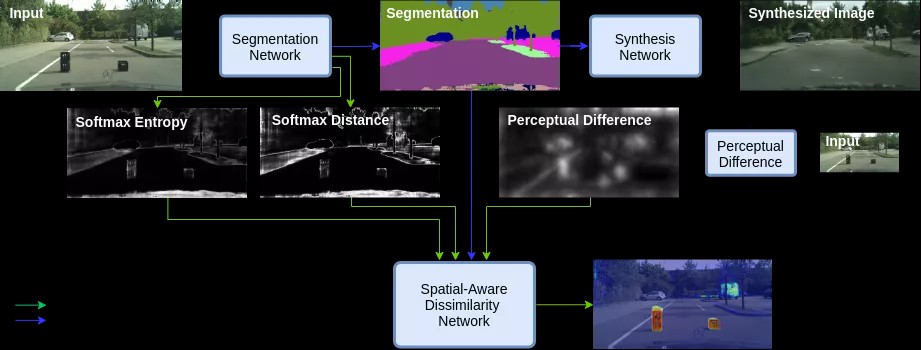
这篇是研究的是“复杂驾驶场景中的像素级异常检测”问题。在语义分割异常检测方面,比较有名的应该是Fishyscapes基准的方法,而这篇文章与之进行了PK,具有领先性。
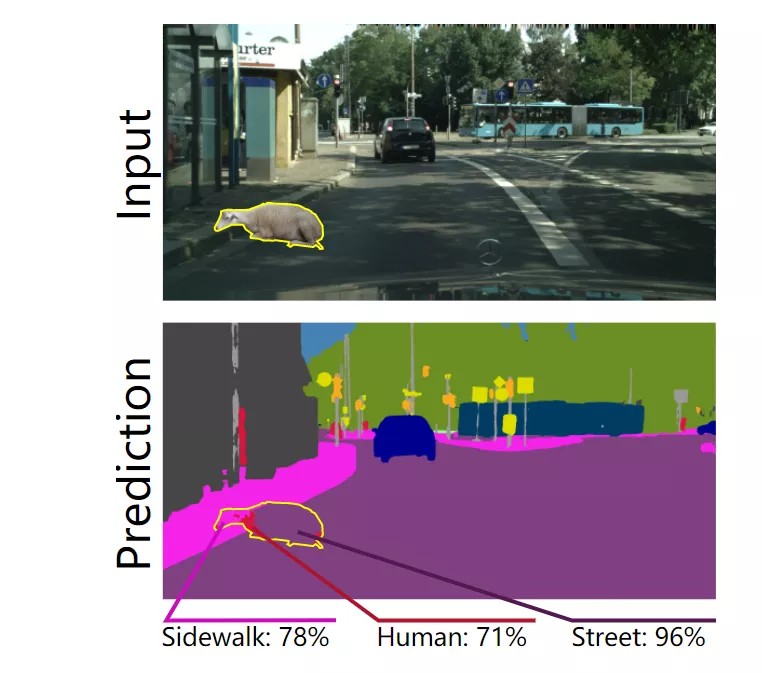
目前,前沿的语义分割方法对异常实例的检测能力是有限的,从而阻碍了它们在安全和复杂的应用程序中使用。比如自动驾驶,最近的方法侧重于利用分割的不确定性来识别异常区域,或者从语义标签地图融合,来发现与输入图像不相似的地方。
在这项工作中,证明了上述两种方法包含互补的信息,并可以结合起来,产生更鲁棒的预测异常分割。他们提出了一个像素级的异常检测框架,通过使用不确定性地图,改进现有的融合方法,来发现输入和生成图像之间的不相似性。
该方法在已经训练过的分割网络周围建立了一个通用框架,它确保了异常检测而不影响分割精度,同时显著优于目前所有类似的方法。在一系列不同异常数据集能够实现一个排名前2的性能,从而得到了处理不同异常实例更鲁棒的方法。
论文下载链接:https://arxiv.org/pdf/2103.05445.pdf
4.Binary TTC: A Temporal Geofence for Autonomous Navigation

这篇文章拿下了今年CVPR2021最佳学生论文奖,是作者在英伟达公司实习时候写的。
这篇论文确实很有创新性,它是利用了摄像头在运动过程中,连续的帧间产生光流,进行场景深度估计,也就是我们常说的光流估计方法。然而,深度信息只能在静态场景的约束情况下估计。对于动态场景,像素的2D流是其深度、速度和摄像头移动速度的函数。理清这三个部分是一个不受约束且具有挑战性的问题。
之前的研究主要停留在静态场景里做深度估计,目前特斯拉的视觉方案也是这么做的,要么忽略动态区域,要么使用强场景先验来估计图像的深度信息。
然而该方法考虑了场景中物体与摄像头的相对移动,一个向摄像头移动的物体比另一个可能离相机更近但却远离相机的物体更重要。这种假设成立的情况下,预测一个物体与相机接触的时间(TTC),可能比知道它的实际深度、速度或加速度更有价值。如何知道物体与相机接触的时间,只需要对比前一帧画面与后一帧画面的移动就能判断物体的移动速度。
所以,该方法考虑了图像中每个像素的运动,也就是每个像素回归TTC。通过简化的二进制分类估算像素回归TTC,以更低延迟来预测观察者是否会在一定时间内与障碍物发生碰撞,这通常比知道精确的每像素TTC更为关键,同时也节省了算力,该方法可在6.4毫秒内提供时间地理围栏,比现有方法快25倍以上。
当计算预算允许时,该论文认为还可以通过任意精细的量化(包括连续值)来估算每个像素的TTC。作者认为该方法是第一个以足够高的帧速率提供TTC信息(二进制或粗略量化)以供实际使用的方法。
这一论文进一步挖掘了单目视觉的潜力,让光流估计能够处理视频级画面,同时也不至于牺牲太大的算力,快速得到一个更准确的地理信息,足够有新意,所以得到最佳论文也不为过。
论文下载链接:
https://arxiv.org/pdf/2101.04777.pdf
5.LiDAR-Based Panoptic Segmentation via Dynamic Shifting Network
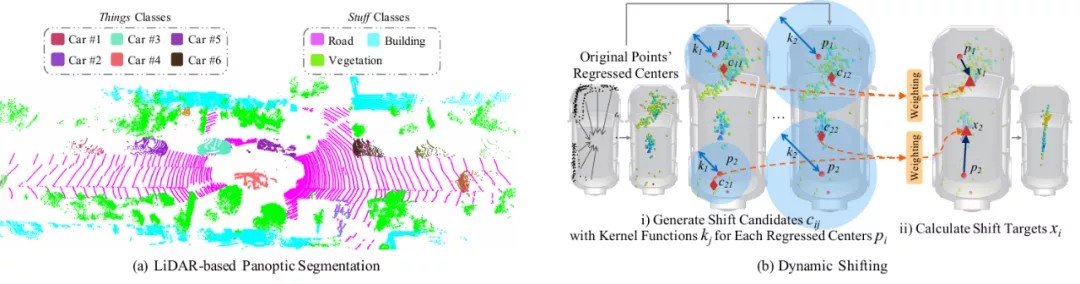
随着自动驾驶的快速发展,为其传感系统配备更全面的 3D 感知变得至关重要。目前的研究主要侧重于从 LiDAR 传感器解析物体(例如汽车和行人)或场景(例如树木和建筑物)。而在这项工作中,主要是解决基于 LiDAR 的全景分割任务,希望用统一的方式解析目标和场景。
该论文提出了一种动态移动网络(DS-Net),把它作为点云领域中有效的全景分割框架。文章指出DS-Net 有三个吸引人的特性:
1)强大的主干设计。DS-Net 采用了专为 LiDAR 点云设计的柱面卷积。提取的特征由语义分支和实例分支共享,它们以自底向上的聚类方式运行。
2) 复杂点分布的动态移位。像 BFS 或 DBSCAN 这样常用的聚类算法无法处理具有非均匀点云分布和不同实例大小的复杂自动驾驶场景。因此,提出了一个有效的可学习聚类模块,动态移位,它可以针对不同的实例即时调整核函数。
3)共识驱动的融合。共识驱动的融合用于处理语义和实例预测之间的分歧。
为了全面评估基于 LiDAR 的全景分割的性能,论文从两个大规模自动驾驶 LiDAR 数据集构建和管理基准,SemanticKITTI 和 nuScenes。经过实验表明,这种DS-Net 比当前最先进的方法具有更高的准确性。并在 SemanticKITTI 的公共排行榜上获得了第一名,在 PQ 指标的 2.6 项上超过了第二名。
6.(AF)2-S3Net:Attentive Feature Fusion with Adaptive Feature Selection for Sparse Semantic Segmentation Network
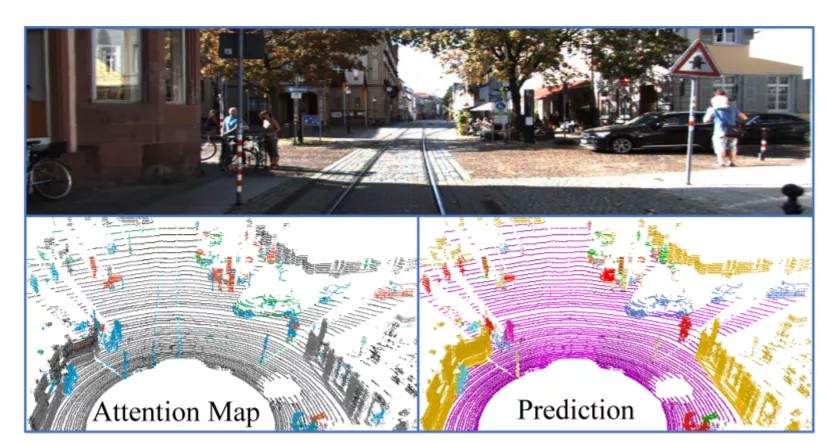
这也是一篇关于语义分割的问题,似乎是一篇与华为有关的项目。作者提出了(AF) 2 - S3Net,一种端到端编解码的CNN网络,用于3D激光雷达语义分割,尝试解决传统用于三维激光雷达语义分割的方法,受到高计算复杂度以及效率低下的问题。
为了缓解这些问题,提出了一种新颖的多分支关注特征融合模块和一种独特的自适应特征选择模块。作者的(AF) 2 -S3Net将基于体素的学习方法和基于点的学习方法融合成一个统一的框架,有效地处理大型3D场景。作者的实验结果表明,该方法在大规模SemanticKITTI基准测试中优于最先进的方法,在公开排行榜竞争中排名第一。
这种基于三维稀疏卷积的网络(AF) 2 -S3Net,包含两个新的注意块,即注意特征融合模块(AF2M)和自适应特征选择模块(AFSM),能够有效地学习局部和全局上下文,强调给定激光雷达点云中的精细细节信息。通过大量实验表明,该方法能够捕获作者提出的模型的局部细节和最先进的性能。未来的工作将利用该方法扩展到端到端三维实例分割和大规模激光雷达点云上的目标检测。
7.Pedestrian Detection: The Elephant In The Room

这篇论文的名字很有特点,它时一个行为检测的数据集,一作来自加州理工学院。它与普通的数据集有何不同呢?作者认为,现有的行人检测器从一个数据集到另一个数据集的概括性很差。形成这种趋势有两个原因:
1.它们在传统的单数据集训练和测试管道中过度拟合流行的数据集。
2.训练源通常在行人中并不密集。
该作者提出的这种Pedestron是一个基于MMdetection的存储库,专注于行人检测研究。提供了一系列检测器,既有通用的,也有专用于训练和测试的行人。此外,在不同的行人检测数据集上,提供了几个检测器的预训练模型和基准测试。通过提供处理过的注释和脚本来处理不同行人检测基准的注释。
该数据集与最先进的行人检测器相比,通用目标检测器在直接跨数据集评估中的效果更好,并且说明了通过爬网收集的各种密集数据集,可以作为行人检测的有效预训练资源。此外,渐进式训练流水线对于自动驾驶导向的探测器非常有用。
论文下载链接:
http://arxiv.org/pdf/2003.08799v1.pdf
8.Shared Cross-Modal Trajectory Prediction for Autonomous Driving
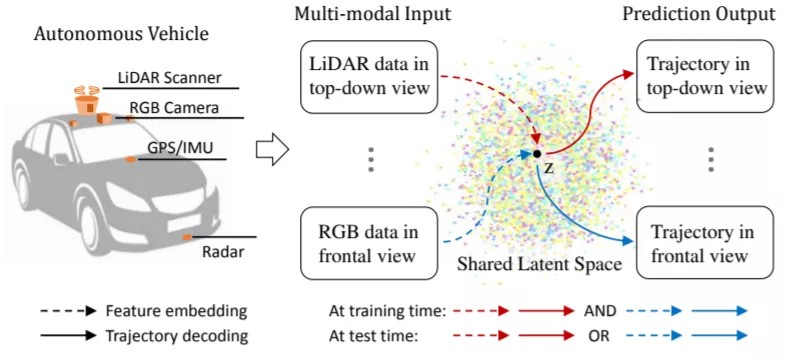
这是一篇源自本田研究院的论文,它是为了解决行为预测问题。目前,大多数公司在采用多传感融合的方式,然而这种方式的弊端在于,可以简单地融合提取的来自几种传感器信息,但本质上增加输入方式的数量就会增加计算时间。同时,如果使用了异常的 LiDAR 数据,该模型几乎就失败了。
对于前一个问题,文章提出了跨模式嵌入的方式,在推理过程中只需要一个输入数据,因此不会影响计算时间,同时它仍然受益于使用多输入训练的模型方式。在后一个问题中,该模型提供了替代方法,使用 RGB 数据的正面视图解决方案时,其中将激活驾驶辅助功能(即ADAS)安全的车辆操作,即使传感器出现故障。
本文提出的 Cross-Modal框架, 旨在从使用中受益的嵌入框架多种输入方式,用于预测高度交互环境中交通代理的未来轨迹。基于自动驾驶车辆配备各种类型的传感器(例如,LiDAR 扫描仪、RGB 摄像头等),相互补充的多种输入模式的使用中获益。在训练时,该模型学习将一组互补的特征,嵌入到一个共享的通过联合优化目标函数,实现潜在空间跨不同类型的输入数据。测试时,单需要输入模态(例如,LiDAR 数据)来生成从输入角度进行预测(即在 LiDAR 中空间),同时利用经过训练的模型的优势多种传感器模式。
9.Delving Into Localization Errors for Monocular 3D Object Detection

从单目图像中估计 3D Bounding 是自主驾驶的一个重要组成部分,而从这类数据中准确地检测三维目标是一个非常具有挑战性的问题。
在这项工作中,通过量化了每个子任务引入的影响,通过回顾二维BBOX的中心和三维物体的投影中心之间的不对齐,发现“定位误差”是限制单目 3D 检测的重要因素。通过研究发现,用现有的技术精确定位远处的目标几乎是不可能的,而这些样本会误导学习的网络。
此外,本文还探讨了定位错误背后的深层原因,分析了它们可能带来的问题,并提出了三种策略:注释操作、训练样本操作和优化损失操作,以缓解定位误差带来的问题,从而提高检测率。
本文还提出了一种新的面向3D IoU的物体尺寸估计方法,该方法不受定位误差的影响。在KITTI数据集上进行了大量的实验,实验结果表明,该方法实现了实时检测,比以往的方法有很大的提高。
论文下载链接:
https://arxiv.org/abs/2103.16237
10.Capturing Omni-Range Context for Omnidirectional Segmentation
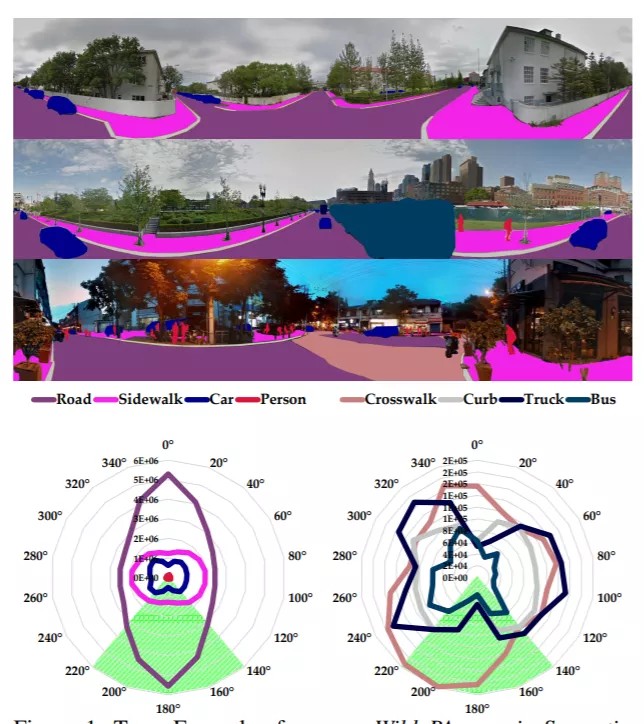
卷积网络(ConvNets)擅长于语义分割,已成为自动驾驶感知的重要组成部分。全方位的摄像头可以全方位地看到街景,完全适合这种系统。大多数用于解析城市环境的分割模型都是在常见的、窄视场(FoV)图像上运行的。
然而,当把这些模型从它们设计的领域转移到360度感知时,它们的性能急剧下降,例如,在建立的试验台上下降了绝对30.0% (mIoU)。
为了弥补成像域之间视场和结构分布的差距,本文引入了高效的并发注意网络Efficient Concurrent Attention Networks (ECANets) ,直接捕捉全向(omnidirectional)成像中固有的远程依赖关系。
除了可以利用到360度图像的基于学习注意力的上下文先验,还通过多源和全监督学习来升级模型训练,利用来自多个数据集的密集标记和未标记数据。为了促进全景图像分割的进展,该研究提出并广泛评估了模型在野生全景语义分(WildPASS)数据集上,该数据集旨在捕获全球各地的不同场景。新模型、训练方案和多源预测融合将性能(mIoU)提升至公共PASS(60:2%)和新鲜的WildPASS(69:0%)基准的最新水平。
论文下载链接:
https://arxiv.org/abs/2103.16237
11.MP3: A Unified Model to Map, Perceive, Predict and Plan(Finalist)
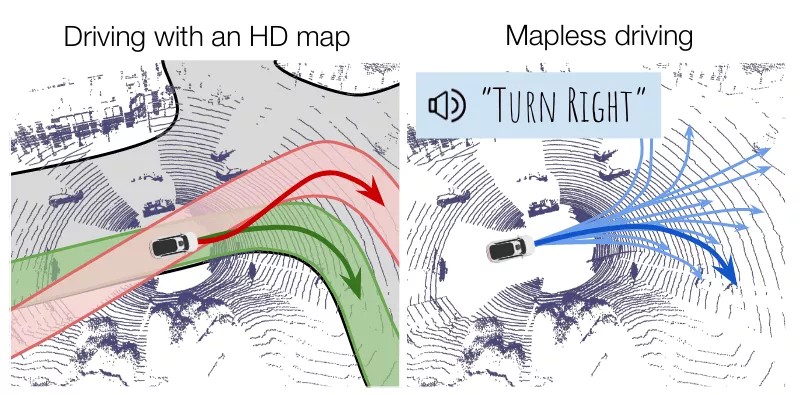
大多数现代自动驾驶堆栈需要最新的高清地图,其中包含驾驶所需的丰富语义信息,例如车道、人行横道、交通灯、交叉路口的拓扑和位置以及每条车道的交通规则. 虽然此类地图极大地促进了感知和运动预测任务,但由于在线推理过程必须主要关注动态对象(例如,车辆、行人、骑自行车的人),考虑到它们的复杂性和成本,缩放它们是很困难的,而且考虑到即使非常小映射中的错误可能会导致致命错误。这推动了无地图技术的发展,它可以在定位失败或地图过时的情况下作为故障保险,并有可能以更低的成本大规模解锁自动驾驶。
然而,无地图方法带来了许多挑战:(1) 训练信号的唯一来源是专家驾驶员的控制(例如转向和加速),而没有提供可以帮助解释自动驾驶车辆决策的中间可解释表示. (2) 没有任何机制来注入结构和先验知识,这种方法对于分配转移(例如缺少车道)来说非常脆弱。为了解决这些问题,本文介绍了 MP3,这是一种可解释的无地图驾驶的端到端方法,不会导致任何信息丢失,以及中间表示中不确定性的原因。
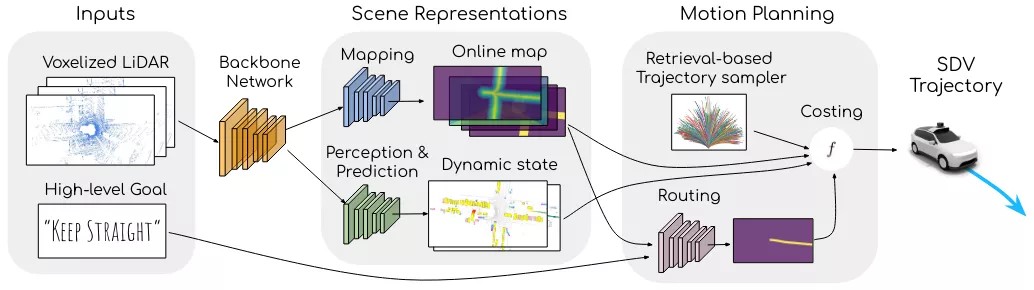
MP3 模型将一个高级目标作为输入,即 LiDAR 点云的历史,随着时间的推移从场景中提取丰富的几何和语义特征(请参阅此有关更多详细信息)和里程计数据以补偿车辆的运动。然后使用主干网络处理输入,并将其输入一组概率空间层,以对环境的静态和动态部分进行建模。静态环境由以规划为中心的在线地图表示,该地图捕获有关哪些区域可行驶以及哪些区域根据交通规则可到达的信息。动态参与者被捕获在一个新的占用流中,该流提供了随着时间的推移的占用和速度估计。然后,运动规划模块利用这些表示来检索动态可行的轨迹,预测地图上的空间掩码以估计给定抽象目标的路线,并直接利用在线地图和占用流量作为可解释的安全计划的成本函数。
论文下载链接:
https://arxiv.org/abs/2101.06806
12.GIRAFFE: Representing Scenes As Compositional Generative Neural Feature Fields
虽然 GaN 能够生成逼真和多样化的高分辨率图像,但对数据变化因素和生成场景的组成性的细粒度控制仍然有限,仅在 2D 中运行,而忽略了底层场景。
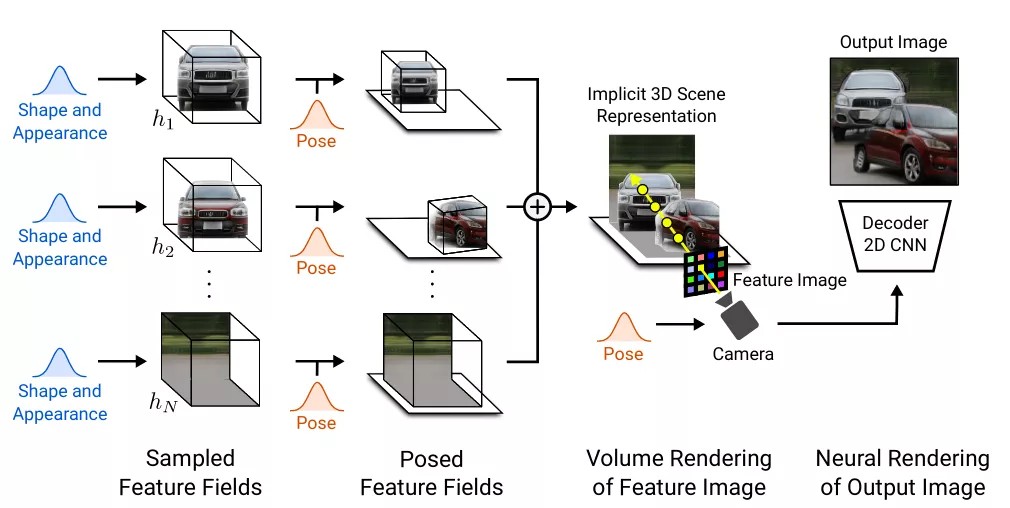
GIRAFFE 建议将场景表示为合成生成神经特征字段。在训练期间,与标准 GaN 设置中的单个潜在代码不同,GIRAFFE 随机生成一组形状和外观场景中每个对象(和背景)的代码,用于生成特征字段。然后生成第二组潜在代码,这次表示姿势变换,将其应用于生成的特征标准以获得姿势特征字段。最后,最终的 Posed Feature Fields 被聚合成一个单一的场景表示,并给定一个相机姿势,用作神经渲染网络的输入以生成 2D 图像。然后将生成的和真实的 2D 图像传递给鉴别器以计算对抗性损失。整个模型是端到端训练的,在测试时,可以使用 Shape & Appearance 和 Pose 潜在代码控制生成图像的组成。
论文下载链接:
https://arxiv.org/abs/2011.12100
13.GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields

模拟/增强各种真实世界场景的能力是一个重要但具有挑战性的开放性问题,特别是对于安全关键领域,例如自动驾驶,在这些领域中,产生视觉吸引力和逼真的结果需要基于物理的渲染,这非常昂贵。作为另一种选择,GeoSim 通过结合数据驱动方法(例如生成建模)和计算机图形将动态对象插入现有视频,利用图像合成的最新进展,同时通过物理接地模拟保持高视觉质量(参见上面的示例) .
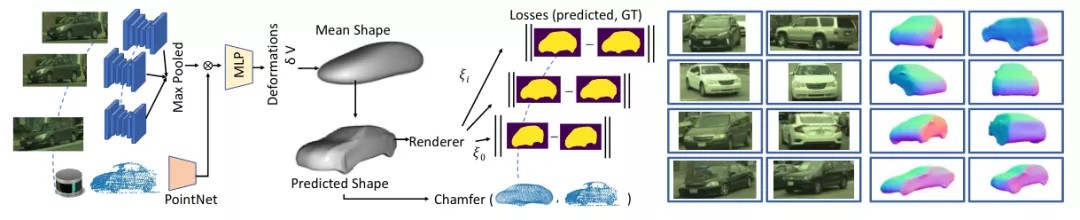
GeoSim 的第一步是创建具有准确姿势、形状和纹理的大型 3D 资产(不同类型和形状的车辆)。GeoSim 不是使用艺术家来创建这些资产,而是利用公开可用的数据集来构建对象的 3D 资产。这是使用基于学习的、多视图、多传感器的重建方法完成的,该方法利用 3D 边界框并以自我监督的方式进行训练,以便在预测的 3D 形状与相机和 LiDAR 的形状之间达成一致观察。然后,GeoSim 利用来自高清地图和 LiDAR 数据的 3D 场景布局,将这些学习到的 3D 资产添加到合理的位置,并通过考虑整个场景使它们表现得逼真。最后,使用这个新的 3D 场景,GeoSim 执行基于图像的渲染以正确处理遮挡,以及基于神经网络的图像修复,通过填充孔洞、调整因光照变化导致的颜色不一致以及去除尖锐边界来确保插入的对象无缝融合。
14.Rethinking Semantic Segmentation From a Sequence-to-Sequence Perspective With Transformers
本文提出的 SEgmentation TRansformer (SETR) 基于作为序列到序列任务的语义分割的替代公式。通过这种方式,而不是使用标准的编码器-解码器架构,这样的公式使我们有可能使用没有卷积和分辨率降低的纯转换器来进行像素级分类,因为它符合转换器在输入和他们如何产生他们的预测。除了利用转换器层的能力对全局上下文进行建模之外,这对于语义分割很重要,以获得相干掩码。
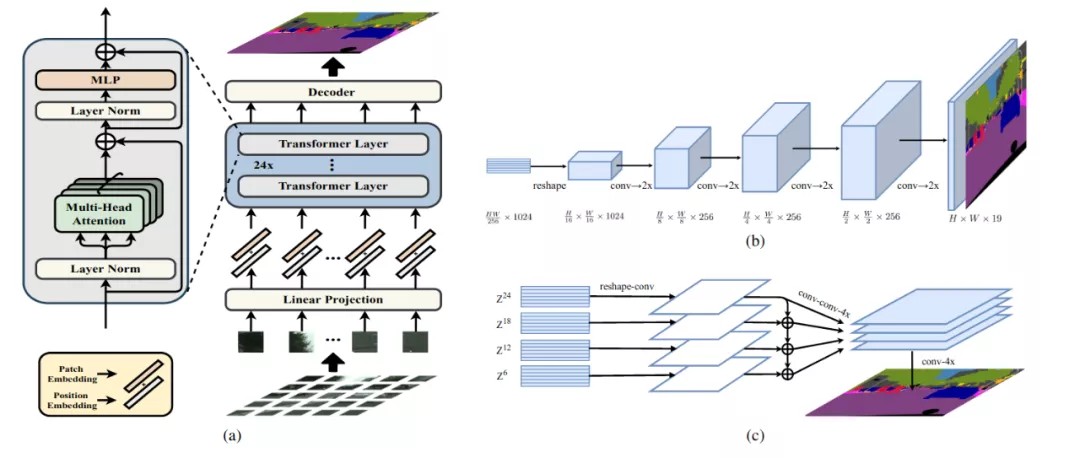
SETR(上图,a)将输入图像视为一系列图像块,其中每个图像首先被分解为固定大小的块。然后,将每条路径展平为像素值向量并通过线性层,输出补丁嵌入。这些补丁嵌入作为一个序列传递给具有全局自注意力的变换器编码器(即 24 个变换器层),以便为分割任务量身定制判别特征。然后将生成的表示重新整形回 2D 形状(补丁数 x 嵌入维度)到标准 3D 特征映射形状(H x W x 嵌入维度)。然后将重塑的特征传递给解码器,以预测原始输入大小的最终每像素分类。这里,SETR 提出了 3 种类型的解码器:(1)朴素上采样:一个 2 层网络,然后是双线性上采样,(2)渐进式上采样:在 conv 层和单个 2x 双线性上采样操作之间交替(上图,b)。(3) 多级特征聚合:通过对编码器的输出进行双线性上采样,应用多级 conv 层和 4x,合并它们并应用最终上采样(上图,c)。
15.DatasetGAN: Efficient Labeled Data Factory With Minimal Human Effort
DatasetGAN 是一种以最少的人力生成高质量语义分割图像的海量数据集的方法。基于对 GaNs 能够获取丰富的语义知识以呈现对象的多样化和真实示例的观察,DatasetGAN 利用经过训练的 GAN 的特征空间并训练浅层解码器来生成像素级标签,其中这样的解码器在非常少量的标记示例上进行训练,然后可用于标记无限量的合成图像。生成的数据集可用于在合成数据集上以半监督的方式训练模型,然后可以在真实世界的图像上进行测试。

DatasetGAN 的架构由两个模型组成,一个是生成合成图像的 StyleGAN,以及一个三层 MLP 分类器集合形式的 Style-Interpreter,其中每个分类器将 StyleGAN 的特征映射作为输入(AdaIN 的输出)层),将它们上采样到图像分辨率并预测像素级标签。最终的预测是所有 MLP 分类器的预测的聚合,然后用少量精细注释的示例进行训练,并用于标记合成图像。
本文来源:CVPR官方论文集合,部分内容摘自Yassine,CVPR2021综述,感谢每一位论文作者。

发表评论
登录后可评论,请前往 登录 或 注册