数据湖:存储全量数据,快速实现洞察
作者:揽月2021.08.24 18:49浏览量:1028简介:数据湖经成为继数据库、数据仓库之后敏捷处理数据、提升数据洞察力的又一标志性技术。
“数仓出局,中台已凉,数据湖将称王!”目前,市场上出现了这样一种说法,估计大多数人很难评断真伪。
既便是专业人士,也不会武断地做出这样的研判,毕竟数据湖并不是为了取代数仓而生的。同时广大的用户更看重的是应用价值,而不是新名词或者换汤不换药的噱头。
毫无疑问,数字经济时代,数据已成为企业的核心资产。数据湖(Data Lake)已经成为继数据库、数据仓库之后敏捷处理数据、提升数据洞察力的又一标志性的技术。摸清家底,搞清方向,应用数据湖才能心里有谱。
01 数据湖是开疆拓土不是替代既有产品
1)数据湖通常是企业中全量数据的单一存储。
2010年,Pentaho创始人兼首席技术官James Dixon首次提出了数据湖概念。
经过多年的发展,中国软件网发现,数据湖是以集中方式存储各种类型数据,提供弹性的容量和吞吐能力,能够覆盖广泛的数据源,支持多种计算与处理分析引擎直接对数据进行访问的统一存储平台。从结果来看,数据湖能够实现数据分析、机器学习,以及数据访问和管理等细粒度的授权、审计等功能。
数据湖通常是企业中全量数据的单一存储,对存取的数据没有格式类型的限制,可以存储结构化数据(如关系型数据库中的表),半结构化数据(如 CSV、JSON 、XML、日志等),非结构化数据(如电子邮件、文档、PDF 等)以及二进制数据(如图形、音频、视频等)。数据产生后,可以按照数据的原始内容和属性,直接存储到数据湖,无需在数据上传之前对数据进行任何的结构化处理。

2)数据湖的主要特征日益明显。
数据特征。能够实现全量数据的单一存储,通常存储原始格式的对象块或者文件,可与企业业务数据库和数据仓库无缝集成,扩展现有数据应用。同时并非将数据移动到单个存储库中,在数据原本存储的地方访问数据并动态执行数据转换和汇总。
数据规模。数据湖技术支持超大规模存储及可扩展的大规模数据处理能力,可根据企业的业务需求提供可大可小的弹性扩充。
数据类型。不管是传统数仓承载的结构化数据,还是数仓不能存储的半结构化数据、非结构化数据、二进制数据等任意类型的数据,数据湖都可以轻松实现采集、存储和分析。
赋能用户。数据湖无需任何预处理即可对数据进行采集、存储和分析,还能消除数据采集和存储的复杂性,加速应用数据,赋能广大研发者、数据科学家、分析师,实现对跨平台、跨语言、跨领域的所有数据进行高效分析和处理。
多样化分析能力。可以运行从控制面板和可视化到大数据处理、实时分析和机器学习等不同类型的分析,深度挖掘数据价值,进行预测分析,并保证了数据一致性、可治理和安全性的实现。
3)数据库、数据仓库、数据湖是数据技术不断发展的结果,是传承不是取代。
数据仓库是一个经过优化的数据库,用于分析来自事务系统和业务线应用程序的关系型数据,因此数据仓库存储的都是结构化数据。数据经过了清理、丰富和转换,因此可以充当用户可信任的“单一信息源”。
数据仓库对数据提供高效地存储,便于用户通过报表、看板和分析工具来获取查询结果,从数据中获得洞察力、决策指导。
对应起来看,数据湖存储着来自业务线应用程序的关系型数据,以及来自移动应用程序、IoT 设备和社交媒体的非关系型数据。
用户可以对数据使用不同的方式如 SQL 查询、大数据分析、全文搜索、实时分析和机器学习等,来获得对数据的深入了解。
当不清楚某些数据存在的价值时,将数据以原生格式天然沉积在数据湖。数据来源不尽相同,能够同时存储结构化和非结构化数据。同时,可以使用不同的过程将数据注入到数据湖中。最终,都是为了帮助用户,根据自己的需要更好地处理数据。
4)数据湖技术架构发展经历了三个发展阶段。
第一阶段是自建开源Hadoop数据湖架构。不过随着数据量激增、应用场景的丰富,导致Hadoop的问题凸显。因此,越来越多的方案开始向数据湖转型,解决靠单一Hadoop所没能解决的问题。
第二阶段是上托管Hadoop数据湖架构,底层物理服务器和开源软件版本由云厂商提供和管理,企业需要自己运维和管理。
第三阶段采取云上数据湖架构,即云上纯托管的存储系统,引擎丰富度不断扩展,分离后的存储系统可独立扩展,完成存算分离。
目前,数据湖应用正处于第二和第三阶段,云上纯托管的存储系统,正成为数据湖的存储基础设施。

02 数据湖市场的增速超出预想
虽然数据湖的概念提出仅仅只有十年的时间,但是数据湖市场的增长速度却超出了许多人的预想,带来意外的惊喜。
1)到2024年数据湖市场将突破200亿美元
市场研究机构MarketsandMarkets发布的研究报告显示,2019年全球数据湖市场规模为79亿美元。同时该机构预测,到2024年,市场规模将达到201亿美元,预测期内(2019~2024年)的复合年增长率为20.6%。
中国软件网分析,全球数据湖市场的增长主要取决于以下几个因素:
一是新型数字化企业的需求得到了激发,传统企业以前因为成本、技术和环境限制的需求也得到释放,越来越需要从不断增长的数据量中进行分析从而获得更深入的内容。
二是公有云服务商的大量介入,以及开源技术的应用,将数据湖应用的成本和技术实现难度大幅降低,基于云的数据平台转变有利于管理和减轻数据问题,增加了市场的发展机会。
三是在数据湖上新增的与数据分析相关的功能有望得到更大的丰富。到2021年,将数据湖和数据仓库良好融合的企业,在实际应用中可以支持多30%的业务使用场景。
2)北美将占据最高份额,亚太市场增长最快。
MarketsandMarkets的报告显示,从地域来看,预计北美将占据最高的全球数据湖市场份额和高增长率,源于大数据技术的使用增加,跨行业、垂直行业的数据量不断增加,公司对数据湖解决方案的投资不断增加,以及数据湖技术的不断进步等。
在欧洲,一方面政府采取了更多的措施来推动数据湖解决方案的采用,如英国。法国越来越注重研发和来自全球玩家和投资者的大量资本流入,推动法国市场的增长。
而亚太地区(APAC),在预测期(2019~2024年)内的年复合增长率将达到最高。中国加强人工智能、物联网和大数据技术的整合,推动数据湖解决方案在中国的应用。
3)市场发展呈现四大特点。
一是数据湖组件市场分析中的数据发现、解决方案、数据集成和管理、数据湖分析、数据可视化等几大重要组件迅速发展,快速赢得市场和用户。
二是运营部门年复合增长率最高。从业务功能来看,数据湖具有市场营销、销售、运营、金融和人力资源五大业务功能。MarketsandMarkets预测,运营业务功能年复合增长率最高,市场营销业务功能将占据最大的市场规模。数据湖使公司能够提高运营效率,降低成本。
三是基于云部署模式的数据湖解决方案快速增长。从部署模式来看,数据湖具有本地部署和云部署两种部署模式。MarketsandMarkets报告认为,数据湖市场的大多数供应商都提供基于云的数据湖解决方案,以实现利润最大化和设备维护过程的有效自动化。同样,基于云部署模式的数据湖解决方案增长快速。
四是数据湖行业应用发展迅速。数据湖解决方案被广泛应用在银行、金融服务和保险、IT、零售、医疗、制造生产、能源和公共事业、媒体和娱乐、政府以及教育等多个垂直领域当中。
03 云服务商已经是数据湖市场最大的赢家
作为大数据的变革新生力量,数据湖技术一经问世,便深受不同领域企业的拥戴。目前,数据湖市场主要有三类供应商:
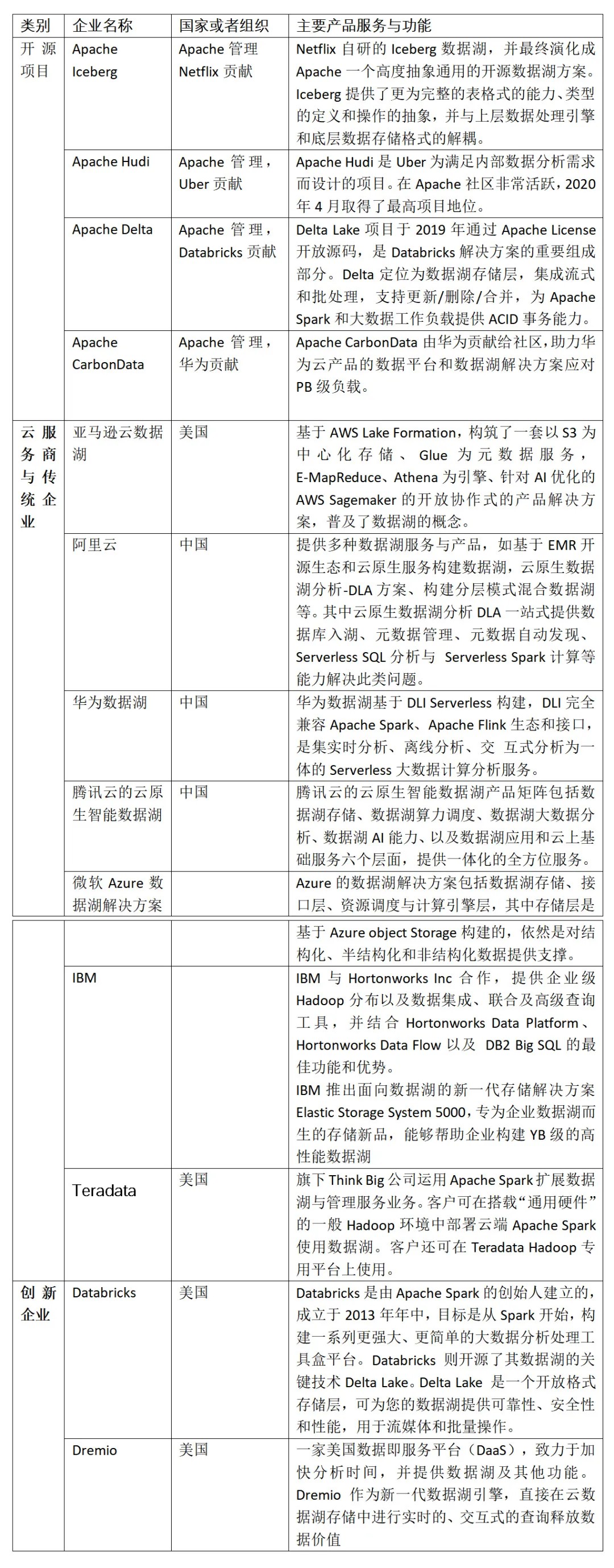
1)开源数据湖的四大项目
目前市面上流行的三大开源数据湖方案分别为:Apache Delta、Apache Iceberg和Apache Hudi。开源项目的优势包括:头部企业提出的开源项目,技术可行性强;群策群智,发展迅速;商业化版本也比较多,方便选择等。
由于Apache Spark在商业化上取得巨大成功,所以由其背后商业公司Databricks推出的Delta Lake也显得格外亮眼。
Delta Lake项目于2019年通过Apache License开放源码,是Databricks解决方案的重要组成部分。Delta定位为数据湖存储层,集成流式和批处理,支持更新/删除/合并,为Apache Spark和大数据工作负载提供ACID事务能力。一些关键特性包括:支持多重分析引擎、廉价存储、支持流批读写、支持Python接口等。
Apache Hudi是由Uber的工程师为满足其内部数据分析的需求而设计的数据湖项目,后提供Apache License开放源码。该项目在Apache社区非常活跃,2020年4月取得了最高项目地位。Hudi提供的fast upsert/delete以及compaction等功能,精准命中用户的痛点。其在文件管理、索引、表类型、查询类型、Hudi工具等关键特性特色鲜明。
Netflix的数据湖原先是借助Hive来构建,但在发现Hive设计上的诸多缺陷之后,开始转为自研Iceberg,并最终演化成Apache下一个高度抽象通用的开源数据湖方案。
Apache Iceberg目前社区关注度暂时比不上Delta,功能也不如Hudi丰富,但因为它具有高度抽象和非常优雅的设计,为成为一个通用的数据湖方案奠定了良好基础。
Apache CarbonData是由华为贡献给开源社区的数据湖项目,助力华为云产品的数据平台和数据湖解决方案应对PB级负载。除了支持更新、删除、合并操作、流式采集外,它还拥有大量高级功能,如时间序列、物化视图的数据映射、二级索引,并且还被集成到多个AI平台,如Tensorflow。
2)云服务商的数据湖产品与服务
亚马逊云科技、微软、谷歌云、阿里云、华为云、腾讯云等纷纷推出自己的数据湖解决方案和相关产品,同时一些传统企业如IBM也推出类似的项目,但是影响力甚微。
专家认为,云服务商数据湖服务弹性分析可以满足企业业务潮汐带来了资源波动,按试用付费,也让企业无需先期购买服务器、存储等硬件设备,降低了运维成本使用成本,大大提高了资金利用率;同时,能够实现与企业现有技术的深度融合,支持数据多元集成和迁移,大幅带动提升了企业原有分析和治理系统的性能优化等。
亚马逊云数据湖,率先基于AWS Lake Formation,构筑了一套以S3为中心化存储、Glue为元数据服务,E-MapReduce、Athena为引擎、针对AI优化的AWS Sagemaker的开放协作式的产品解决方案,普及了数据湖的概念。
AWS Lake Formation是一个管理性质的组件,与其他AWS服务互相配合,来完成整个企业级数据湖构建功能。其中,采用Amazon S3作为整个数据湖的集中存储,按需扩展/按使用量付费。AWS Glue完成元数据抓取、ETL和数据准备。使用Amazon EMR进行数据的高级处理分析,或者基于Amazon EMR、Amazon Kinesis来完成流处理任务。数据通过Athena/Redshift来提供基于SQL的交互式批处理能力,通过 Amazon Machine Learning、Amazon Lex、Amazon Rekognition进行深度加工。
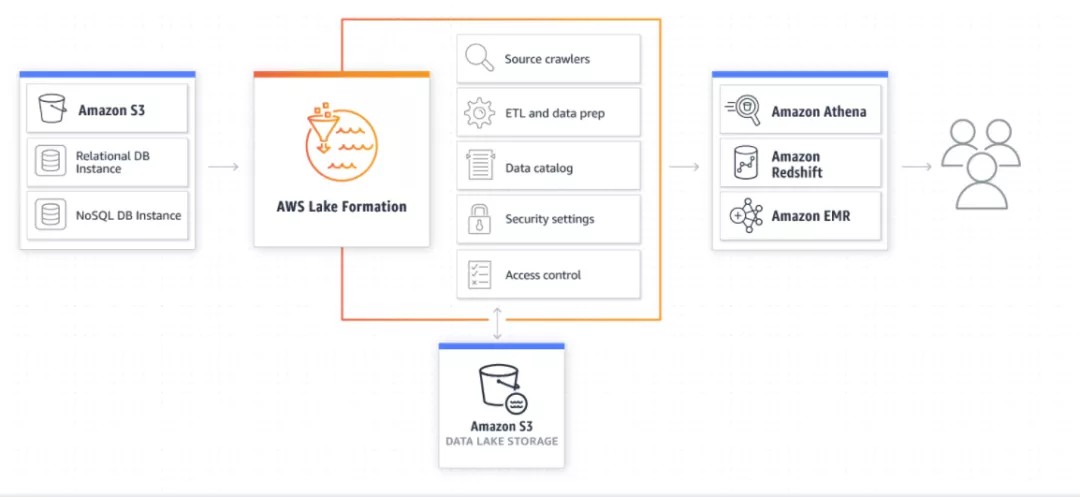
AWS Lake Formation工作原理
微软Azure数据湖解决方案,包括数据湖存储、接口层、资源调度与计算引擎层,其中存储层是基于Azure object Storage构建的,对结构化、半结构化和非结构化数据提供支撑;接口层为WebHDFS,在Azure object Storage实现了HDFS的接口;在资源调度上,Azure基于YARN实现;计算引擎上,Azure提供了U-SQL、hadoop和Spark等多种处理引擎。
Azure基于visual studio提供给了客户开发的支持。实现多计算引擎的适配,包括SQL、 Apache Hadoop和Apache Spark,提供多种不同引擎任务之间的自动转换能力。
腾讯云数据湖。今年年5月13日,腾讯云首次展示了云原生数据湖体系,并发布两款“开箱即用”数据湖产品——数据湖计算服务DLC和数据湖构建DLF。
腾讯云的云原生智能数据湖产品矩阵包括数据湖存储、数据湖算力调度、数据湖大数据分析、数据湖AI能力、以及数据湖应用和云上基础服务六个层面,提供一体化的全方位服务。
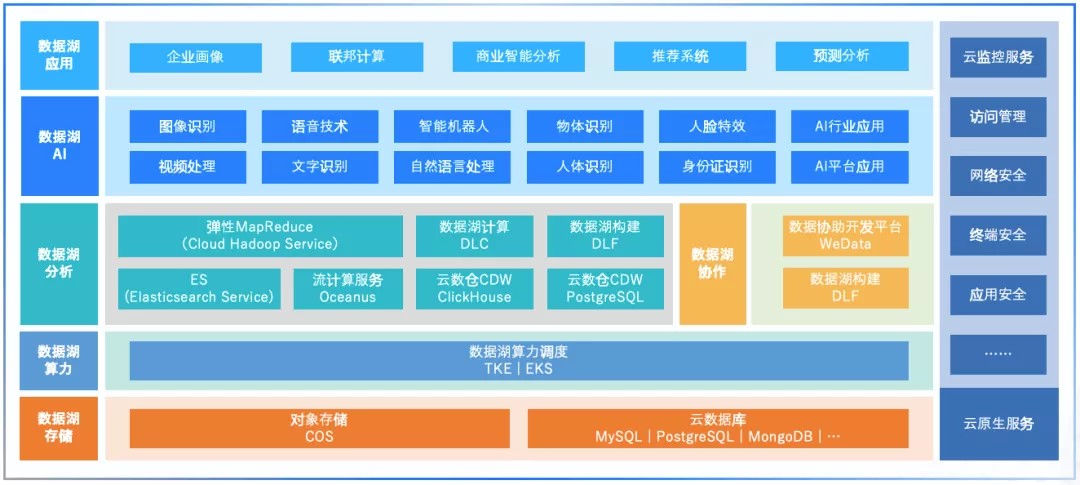
两款“开箱即用”数据湖新品DLC和DLF核心功能是更简单地让数据入湖、统一管理数据信息,通过DLC数据湖计算让用户在数据分析时可以即时编写SQL,随时发起集群查询,降低运维门槛。其中,数据湖计算服务采用的是无服务器架构设计,计算性能提升35.5%,构建效率提升60%,业务增长量提升可达75%。
数据湖构建则能帮助用户快速高效的构建企业数据湖技术架构。借助数据湖构建,用户可以极大提高数据入湖准备的效率,资源成本节省超30%,湖构建时间减少60%,运维工程师人数降低100%。
华为数据湖基于DLI Serverless构建,DLI完全兼容Apache Spark、Apache Flink生态和接口,是集实时分析、离线分析、交 互式分析为一体的Serverless大数据计算分析服务。
华为云提供了DAYU智能数据湖运营平台,DAYU涵盖了整个数据湖治理的核心流程,并对其提供了相应的工具支持。
据介绍,华为数据湖拥有逻辑统一、类型多样、汇聚原始纪录三大特点,提出数据入湖的6项标准,包括明确数据Owner、发布数据标准、定义数据密级、明确数据源、数据质量评估、元数据注册,保证入湖的数据都有明确的业务责任人,各项数据都可理解,同时都能在相应的信息安全保障下进行消费。同时提供了5种数据入湖的技术手段,包括批量集成、数据复制同步、消息集成、流集成、数据虚拟化等。
阿里云提供多种数据湖服务与产品,如基于EMR开源生态和云原生服务构建数据湖,云原生数据湖分析-DLA方案、构建分层模式混合数据湖等。其中云原生数据湖分析DLA一站式提供数据库入湖、元数据管理、元数据自动发现、Serverless SQL分析与 Serverless Spark 计算等能力解决此类问题。
阿里云数据湖解决方案有三大特色:强大的数据存储引擎,阿里云的数据湖底层基于阿里云自研的分布式存储引擎搭建,提供体系化的数据采集能力,支持结构化/半结构化/非结构化数据源。
与云原生平台的深入结合。 数据湖可以对接多种差异性的计算引擎,运行在不同负载之上,多种计算引擎都共享同一套存储系统,打破数据孤岛,洞察数据价值。
内部及外部的有效验证。阿里巴巴集团首先是阿里云数据湖产品的最佳实践者,后者首先支撑了阿里巴巴集团内部的电商、移动办公、文娱、物流、本地生活等各种复杂业务,建立了完善的自我实践机制,产品和方案得到有效的验证。同时,阿里云的数据湖方案也支撑了在线教育、互联网广告、新媒体、网络游戏等行业用户在快速发展过程中的实际业务需求,实现了技术的有效赋能。
3)创新型企业
Databricks 开源了其数据湖的关键技术Delta Lake。同时Delta Lake、Apache Spark 和 Databricks 统一分析平台的进步,不断提高了架构的功能和性能。
Delta Lake是一个开放格式存储层,可为数据湖提供可靠性、安全性和性能,用于流媒体和批量操作。Delta Lake通过将数据孤岛替换为结构化、半结构化和非结构化数据的单个住宅, 成为一个具有成本效益、高度可扩展的湖屋Lakehouse的基础。
其优势包括:支持 ACID 交易和架构执行,提供了传统数据湖所缺乏的可靠性;Delta Sharing是业界首个安全数据共享的开放式协议,无论数据位于何处,与其他组织共享数据都变得简单,与Unity Catalog 的本地集成允许企业集中管理和审核跨组织的共享数据;在Apache Spark下,提供更大规模和速度;所有数据都以开放式 Apache Parquet 格式存储,允许任何兼容的API读取数据;Delta Live Tables,一个简单的方法来建立和管理数据;通过启用数据治理的细粒度访问控制来降低风险等。
Dremio 是美国一家数据即服务平台(DaaS),致力于加快分析时间,并提供数据湖及其他功能。Dremio 作为新一代数据湖引擎,直接在云数据湖存储中进行实时的、交互式的查询释放数据价值,主要应用于三大场景:商业智能,无需依赖 IT 或数据工程,直接针对数据湖存储提高即席和报告查询速度;数据科学上,使用工具利用数据价值,加速数据发现、挖掘潜在关系;数据化的现代化上,针对现代化云数据湖存储方案面临的复杂任务,通过语义层使迁移期间的分析工作负载无缝运行。
数据湖企业附录表格
本文来自公众号: 中智观察
作者:赵满满
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册