DeepMind 开源最强多模态模型Perceiver IO!玩转音频、文本、图片,还会打星际争霸
作者:苏大泽2021.09.01 17:36浏览量:979简介:DeepMind最近开源了一个新模型Perceiver IO,作者宣称这可能是迈向人工智能的重要一步
【新智元导读】你印象中的多模态模型还停留在文本+图片吗?DeepMind最近开源了一个新模型Perceiver IO,除了传统的音频、文本、图片数据可以输入进去以外,还能打星际争霸!作者宣称这可能是迈向通用人工智能的重要一步!
神经网络和人脑之间最大的区别可能就是输入输出数据的不同,人脑和其他动物都具有从多种来源获取数据、并且把多种类型的数据集成起来产生知识、灵活部署数据来实现某个特定目标的能力。
然而,大多数机器学习研究侧重于构建定制系统,以处理与单个任务相关的定型输入和输出集,例如一个人工神经网络模型只能输入特定类型的数据,如文本、音频、图片,输出也是固定不变的。

即使是处理多模态的输入或输出的模型也是如此,典型的流程就是使用深度、模态特定的架构:例如使用2D ResNet进行视觉数据转换,使用Transformer进行语言数据转换,两个模型独立处理每个输入,然后使用第三个融合网络对其进行集成,并以特定于任务的方式读出结果。
随着输入或输出变得更加多样化,这样的系统模型复杂性会急剧增加,而任务输入和输出的形状(shape)和结构可能会对这样一个系统处理数据的方式产生极大限制,使其难以适应新的数据模式。
在目前的研究来说,为每一组新的输入和输出开发特定问题的模型已然不可避免。但如果一个单一的神经网络模型架构能够处理各种各样的输入模式和输出任务,那么这种模型开发工作将大大简化。
DeepMind的研究团队还真就开发出这样一个模型,取名Perceiver IO(感知者 IO),

这个模型已经是第二版,第一版模型为Perceiver,第一版模型基于Transformer 的结构,不需要修改网络结构,就可以利用于各种模态的数据,模型结构达到甚至超过了精心设计用于某一个模态数据的模型的效果。

Perceiver使用交叉注意力机制将多模态数据(byte array)转换为一个固定大小的隐空间,这个过程将网络的处理与输入的大小和特定于模态的细节相分离,并允许其扩展到大型多模态数据。
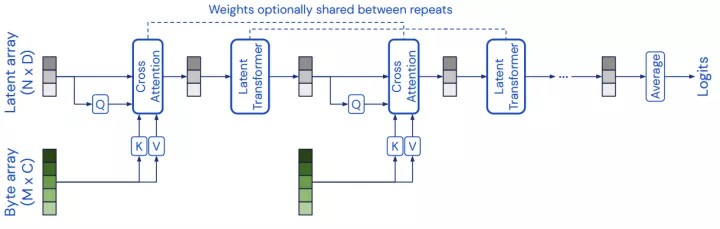
但是Perceiver模型过于简单,只能处理如分类这种简单的输出,与现实世界任务的复杂性还有很大差距,所以这个模型并不是真正意义上的多模态通用模型。
新模型Perceiver IO 具有从Perceiver 的隐空间中直接解码结构化输出(文本、视频、音频、符号集合等)的机制,该机制允许Perceiver IO处理大量新的数据类型。

Perceiver IO 模型的架构基于Perceiver,第一步包括输入的encoding,processing和decoding。
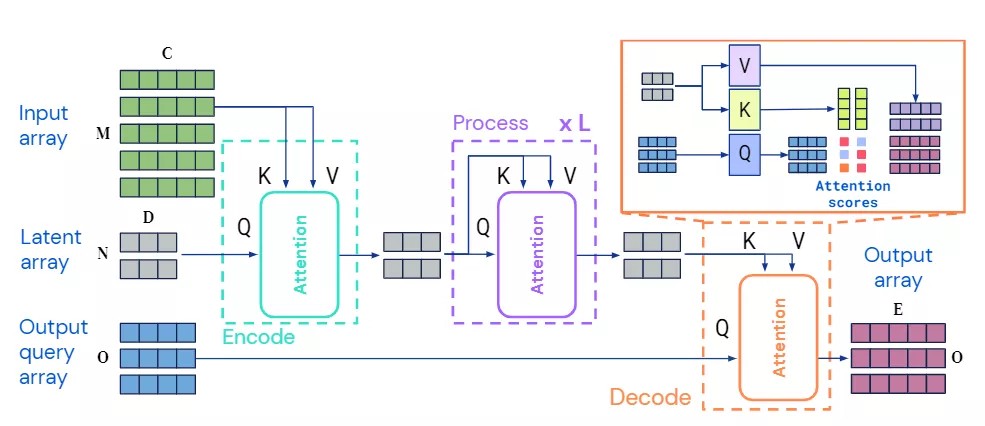
每个模块都是用一个全局query-key-value(QKV)注意力操作,然后是一个多层感知器(MLP)。在Transformer的架构中,通常将MLP独立地应用于索引index维度的每个元素。
编码器和解码器都接受两个输入矩阵,第一个用作模块的key和value网络的输入,第二个用作模块查询网络的输入。模块的输出具有与query输入相同的索引维度(即相同数量的元素),这也是编码器和解码器模块能够产生不同大小输出的原因。
那为什么不直接用Transformer?
作者给出的答案是Transformer在计算和内存方面的扩展性都很差,Transformer需要在其整个架构中全部署注意力模块,使用其全部输入在每一层生成query和key,这也意味着每一层在计算和内存中都是二次时间复杂度的,像图片这种输入比较长的数据,不预处理的话根本没法训练。
相比之下,Perceiver IO非均匀地使用注意力,首先使用它将输入映射到隐空间,然后在该隐空间中进行处理,最后使用注意力映射到输出空间。
最终这个架构对输入或输出大小没有二次时间复杂度的依赖性,因为编码器和解码器注意模块分别线性依赖于输入和输出大小,而隐注意力独立于输入和输出大小。
并且这个架构需要更少的计算和内存需求,Perceiver IO可以扩展到更大的输入和输出。虽然Transformer通常用于输入和输出最多几千维的设置,但这个新模型在输入和输出维度数十万的数据上都显示了不错的结果。
第二步是将隐空间中的表示向量进行解码,目标是在给定大小为N×D的隐表示的情况下,生成大小为O×E的输出矩阵,这意味着query信息应该反映下游任务,并能够捕获输出中所需的任何结构,可能也包括图像中的空间位置或序列中输出字的位置。
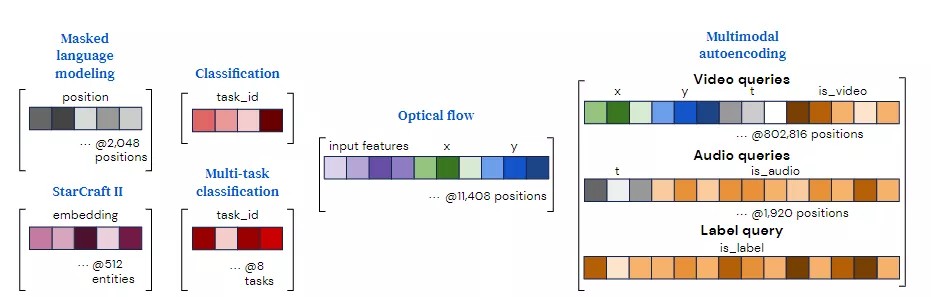
通过组合(连接或添加)一组向量到一个query向量中来构造queries,该查询向量包含与O个期望输出之一相关的所有信息。
对于具有简单输出的任务,例如分类,这些query可以在每个示例中重复使用,并且可以从头开始学习。对于具有空间或序列结构的输出,例如,学习的位置编码或傅里叶特征,则额外包括表示输出中要解码的位置的位置编码。对于具有多任务或多模态结构的输出,学习每个任务或每个模态的单个查询,该信息允许网络将一个任务或模态查询与其他任务或模态查询区分开来,就像位置编码允许注意区分一个位置与另一个位置一样。
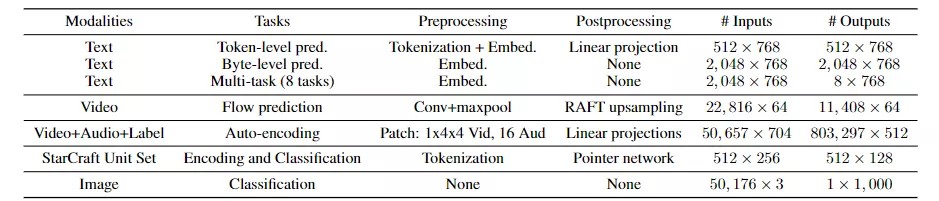
为了评估Perceiver IO的通用性,研究人员在多个领域、多种数据的任务中对其进行评估,包括语言理解(masked language modeling和下游任务微调)、视觉理解(optical flow和图像分类)、游戏符号表示(星际争霸II)以及多模式和多任务设置。
在语言实验中,首先探讨了如何使用Perceiver IO进行语言理解,特别是查看它与标准Transformer相比在一个环境中的性能是否有提升,在GLUE基准上评估了Perceiver IO学习表示的质量。
与最新的语言理解模型(如BERT[21]或XLNet[96])不同,Perceiver IO能够随着输入长度的增加有效地扩展。对于限制给定的FLOPs下允许研究人员训练一个无标记器的语言模型,该模型与使用句子片段标记器训练的基线模型的性能相匹配,因此不再需要手工制作可能具有潜在不正确的标注方案。
在多模态语音编码上,研究人员在Kinetics-700-2020数据集上使用Perceiver IO进行音视频标签多模自动编码,这个数据具有视频、音频和类别标签。。这个任务的目标是学习一个模型,使该模型能够准确地重构多模态输入。这个问题之前已经用限制玻尔兹曼机(Restricted Boltzmann Machines)等技术进行了研究,但研究的是更定型和更小规模的数据。

通过在评估期间屏蔽分类标签,文中提出的自动编码模型成为一个分类器。由于隐变量在各个模式之间共享,因此每个模式的重建质量对其损失项和其他训练参数的权重非常敏感。所以主要强调视频和音频PSNR,但牺牲了分类精度。如果更加强调分类准确率,则可以在保持20.7 PSNR的同时达到45%的top-1准确率。结果表明该模型能够学习到跨模式的联合分布。
Perceiver IO 模型能够处理通用输入和输出,同时可以线性扩展输入和输出大小,这种架构在各种各样的环境中都取得了不错的效果,并且可能有希望成为通用神经网络架构的候选模型。
但这个模型还有局限性:例如,目前没有解决生成性建模,也没有探索自动调整潜在空间大小的机制。
从道德的角度来看,这个模型和其他深度学习模型一样,可能受到大数据中的偏见的影响,并且它们可能对域转移或对抗性攻击不具鲁棒性,这意味着在安全关键应用中必须小心。
总的来说,这是迈向通用人工智能的关键一步!
参考资料:
https://arxiv.org/pdf/2107.14795.pdf
本文来自公众号:新智元
编辑:LRS
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册