最佳实践|Apache Doris Join 实现与调优实践
2021.09.03 15:34浏览量:2691简介:本文主要介绍 Apache Doris Join 的实现机制以及调优策略实战。
8 月 14 号,由示说网和上海白玉兰开源开放研究院联合举办的开源大数据技术线上 Meetup 如期举行,Apache Doris 社区受邀参与本次 Meetup ,来自百度的数据内核高级研发工程师、Apache Doris Contributor 李昊鹏为大家带来了题为“ Apache Doris 的Join实现与调优实践 ”的主题分享,主要介绍了 Apache Doris Join 的实现机制以及调优策略实战,以下是分享内容。
非常高兴可以参与本次的开源大数据技术 Meetup ,今天跟大家分享的主题是 Apache Doris 的 Join 实现和调优,内容主要分为三块:第一部分会先给不太了解 Apache Doris 的小伙伴们简单介绍一下 Doris,第二部分会介绍 Doris 的整个 Join 实现的机制,第三部分是我们基于 Doris 这些 Join 实现机制将怎样展开 Join 的调优工作。

分享目录
Doris 简介
首先简单介绍一下 Doris 。Doris 是百度自主研发并开源的一个基于 MPP (大规模并行处理) 架构的分析型数据库,它的特点就是性能卓越,能够做到 PB 级别的数据分析的毫秒/秒级的响应,适用于高并发低延时下的实时报表、多维分析等需求场景。
Doris 最早是叫 Palo ,2017 年我们以百度 Palo 的方式在 GitHub 上进行了开源,在 2018 年的时候把它贡献给 Apache 社区,正式更名为 Apache Doris 。而在百度内部一直沿用了 Palo 的名称,并在百度智能云上提供了 Palo 的企业级托管版本。

系统定位
Doris 的历史是从 2008 年开始的,最早是应用于百度凤巢统计报表的场景。在 2009 年我们对它进行了通用化改造,开始承接百度内部的其他报表业务。在 2012 年我们对 Doris 的性能、可用性以及扩展性进行了全面的升级,基本上承担起百度内部的所有统计报表的业务。

发展历程
在 2013 年我们对 Doris 做了 MPP 框架的升级,开始支持了分布式计算。在 2015 年对系统架构进行了大幅精简,主体架构一直沿用至今。 从2017 年百度 Palo 正式开源并于 2018 年贡献给 Apache 社区,截止目前,Apache Doris 在 Github 上有大概 2.9k+ Stars,Contributors 大概有 180+,在美团、小米、京东、网易、字节、快手等众多一线的互联网公司当中都有广泛的使用。

发展历程
接下来这张图是 Doris 在整个数据分析场景当中的定位。Doris 它本身承担的是一个数据分析的角色,从传统的数据源,包括 RDMS、业务应用,包括一些 WEB 端、移动端的日志,通过 Spark、Flink 等批计算或流计算引擎将数据快速接入到 Doris 当中,并对外向各类数据应用赋能、提供数据分析的服务。
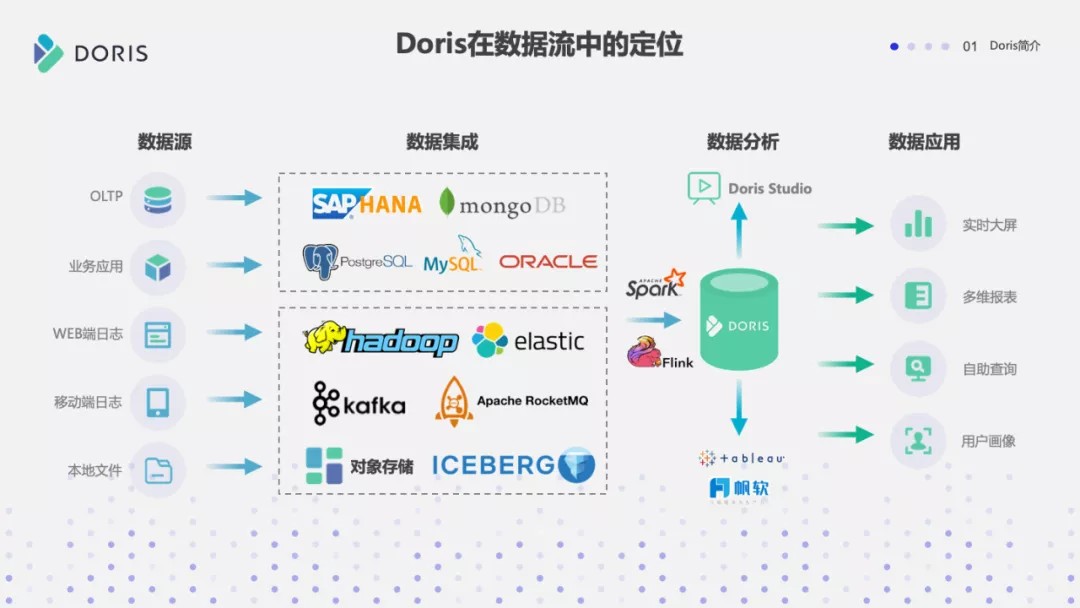
Doris 在数据流中的定位
Doris 是一个 MPP 架构的分析型数据库,有几个特点:第一个特点,简单易用,支持标准 SQL 并且完全兼容 MySQL 协议,产品使用起来非常方便。
第二,它采用了预聚合技术、向量化执行引擎,再加上列式存储,是一个高效查询引擎,能在秒级甚至毫秒级返回海量数据下的查询结果。
第三,它的架构非常简单,只有两组进程:FE 负责管理元数据,并负责解析 SQL 、生成和调度查询计划;BE 负责存储数据以及执行 FE 生成的查询计划。
这个简洁高效的架构使得它运维、部署简单、扩展性强,能够支持大规模的计算。

核心特性
通过下面这张图我们简单梳理一下 Doris 的结构,Doris 主要分为两个角色,一个是 FE,另外一个是 BE 。
从 SQL 执行的角度说, FE 在 Doris 当中承担了 MySQL 接入层,负责解析、生成、调度查询计划。BE 负责对应的查询计划的执行,负责实现实际的查询、导入等工作。从数据的角度说,FE 负责元数据的存储,比如表,数据库,用户信息等数据,BE 负责列存数据的落地存储。
这个架构是非常简洁的,每个 BE 节点它是对等的。FE 分为 Leader、Follower、Observer这几个角色,这和 ZooKeeper 之中的角色定位是类似的, Leader 跟 Follower 参与到集群选主、元数据的修改等工作,而 Observer 是不参与这个过程的,只提供数据的读取,对外提供 FE 的读扩展性,所以 FE 与 BE 节点都可以线性的扩展。
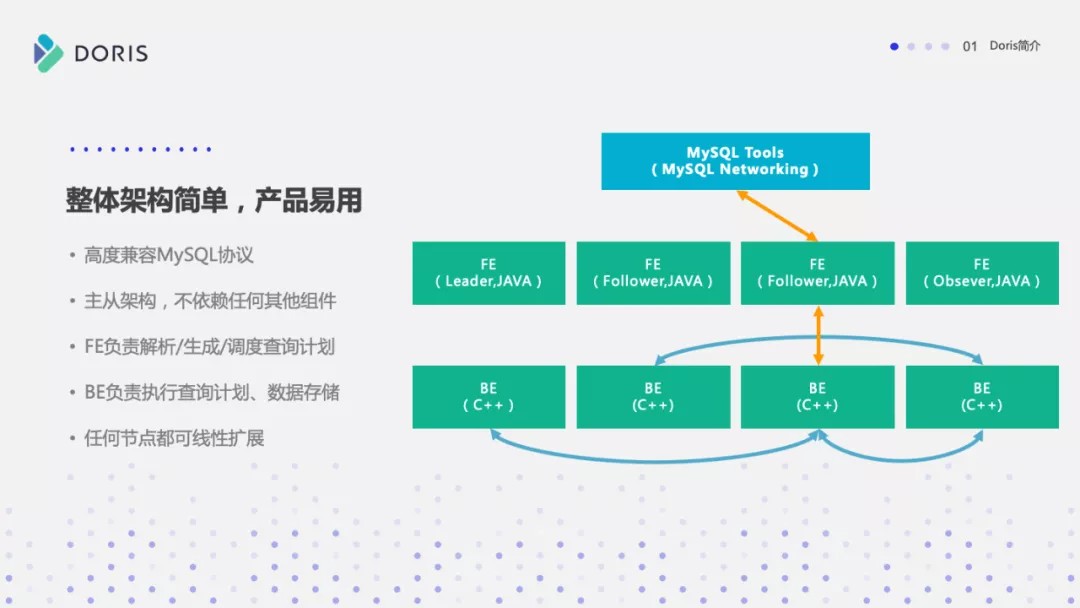
系统架构
接下来是 Doris 当中数据的分布式存储机制,Doris 作为一个 MPP 数据库,它的数据存储会深刻影响到后续我们要分析的 Join 实现与调优。
Doris 可以支持多副本的存储,而且数据能够自动迁移实现副本平衡。我们看到,Doris 中的数据是以 Tablet 的形式组织的,每一个表会拆分成多个 Tablet ,每个 Tablet 是由数据分区跟数据分桶来确定的。一旦确定了 Tablet 之后,在 Doris 当中所有的数据都是基于 Tablet 来调度,我们可以看到一个 tablet 可以分散在多个 BE 上做多副本的存储,如果有 BE 节点宕机,或者是有新的 BE 节点加入时,系统也会自动在后台执行数据副本的均衡。
在查询的时候也会把查询负载均衡到所有的 BE 上,这就是 Doris 在数据副本存储上的整体架构,后面我们做 Join 分析的时候也会看到数据副本、包括数据是怎么样在当中调度的。
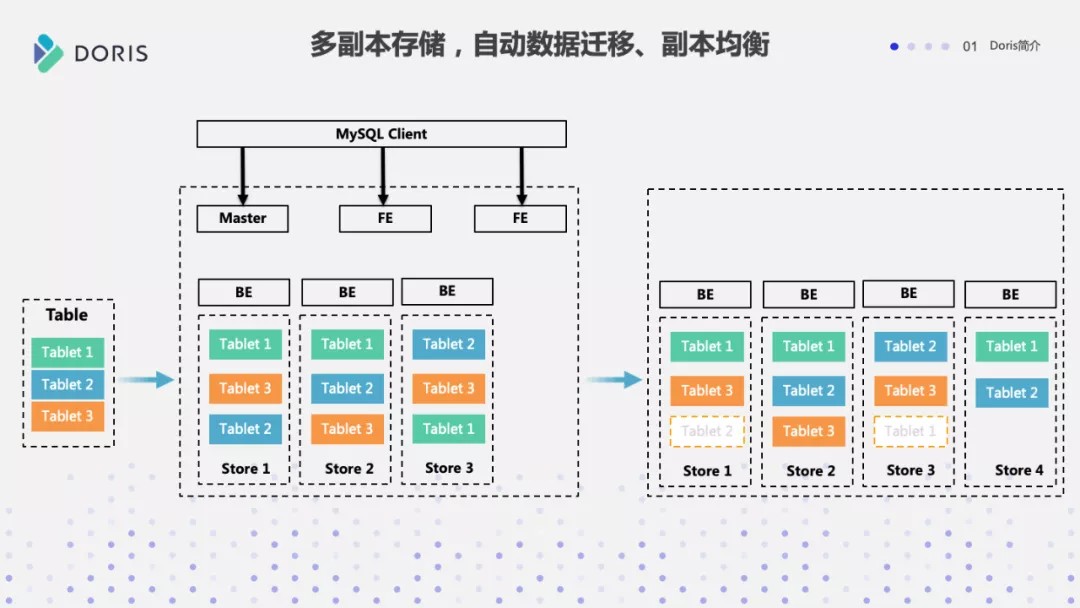
数据分片存储和均衡
Doris Join 实现机制
Doris 支持两种物理算子,一类是 Hash Join,另一类是 Nest Loop Join。
- Hash Join:在右表上根据等值 Join 列建立哈希表,左表流式的利用哈希表进行 Join 计算,它的限制是只能适用于等值 Join。
- Nest Loop Join:通过两个 for 循环,很直观。然后它适用的场景就是不等值的 Join,例如:大于小于或者是需要求笛卡尔积的场景。它是一个通用的 Join 算子,但是性能表现差。

Join 的物理算子
作为分布式的 MPP 数据库, 在 Join 的过程中是需要进行数据的 Shuffle。数据需要进行拆分调度,才能保证最终的 Join 结果是正确的。举个简单的例子,假设关系S 和 R 进行Join,N 表示参与 Join 计算的节点的数量;T 则表示关系的 Tuple 数目。
Doris 支持 4 种数据 Shuffle 方式:
BroadCast Join
它要求把右表全量的数据都发送到左表上,即每一个参与 Join 的节点,它都拥有右表全量的数据,也就是 T(R)。
它适用的场景是比较通用的,同时能够支持 Hash Join 和 Nest loop Join,它的网络开销 N * T(R)。
Shuffle Join
当进行 Hash Join 时候,可以通过 Join 列计算对应的 Hash 值,并进行 Hash 分桶。
它的网络开销则是:T(R) + T(N),但它只能支持 Hash Join,因为它是根据 Join 的条件也去做计算分桶的。
Bucket Shuffle Join
Doris 的表数据本身是通过 Hash 计算分桶的,所以就可以利用表本身的分桶列的性质来进行 Join 数据的 Shuffle。假如两张表需要做 Join,并且 Join 列是左表的分桶列,那么左表的数据其实可以不用去移动右表通过左表的数据分桶发送数据就可以完成 Join 的计算。
它的网络开销则是:T(R)相当于只 Shuffle 右表的数据就可以了。
Colocation
它与Bucket Shuffle Join相似,相当于在数据导入的时候,根据预设的 Join 列的场景已经做好了数据的 Shuffle。那么实际查询的时候就可以直接进行 Join 计算而不需要考虑数据的 Shuffle 问题了。

Join 数据的 Shuffle 方式
下面这张图是 BroadCast Join,左表的数据是没有移动的,右表每一个 BE 节点扫描的数据都发送到对应的 Join 节点上,每个 Join 的计算节点上都有右表全量的数据。
第二种就是 Shuffle Join,每个数据扫描节点将数据扫出来之后进行Partition 分区,然后根据 Partition 分区的结果分别把左右表的数据发送到对应的 Join 计算节点上。
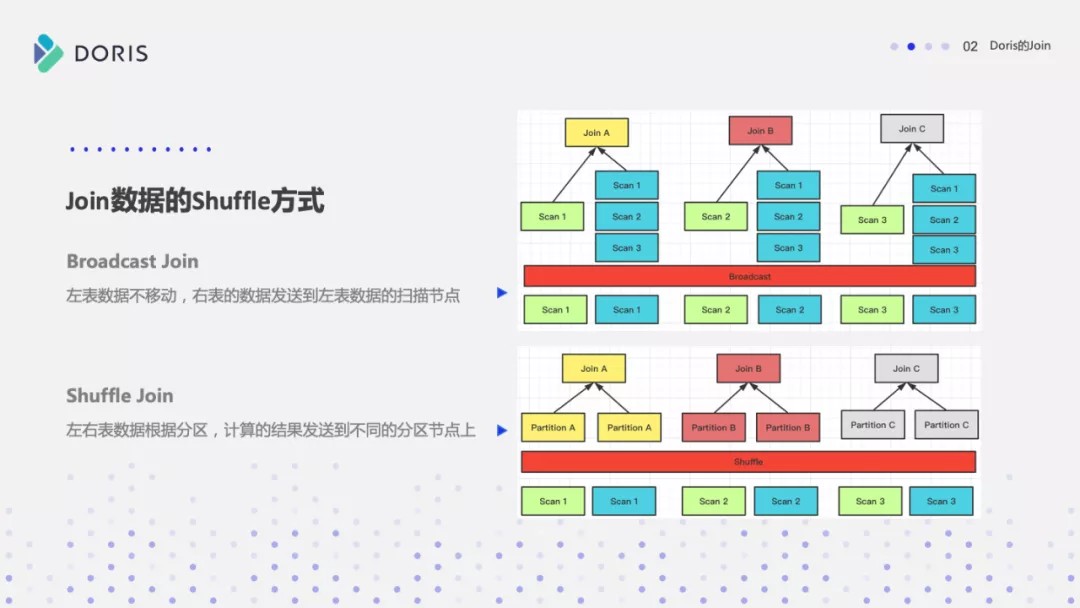
Join 数据的 Shuffle 方式
第三张图是 Bucket Shuffle Join,右表数据扫描出来之后进行数据分区的 Hash 计算,根据左表本身的数据分布发送到对应的 Join 计算节点上。
最后就是 CoLocate Join。它其实没有真正的数据 Shuffle,数据扫描之后进行 Join 计算就OK了。
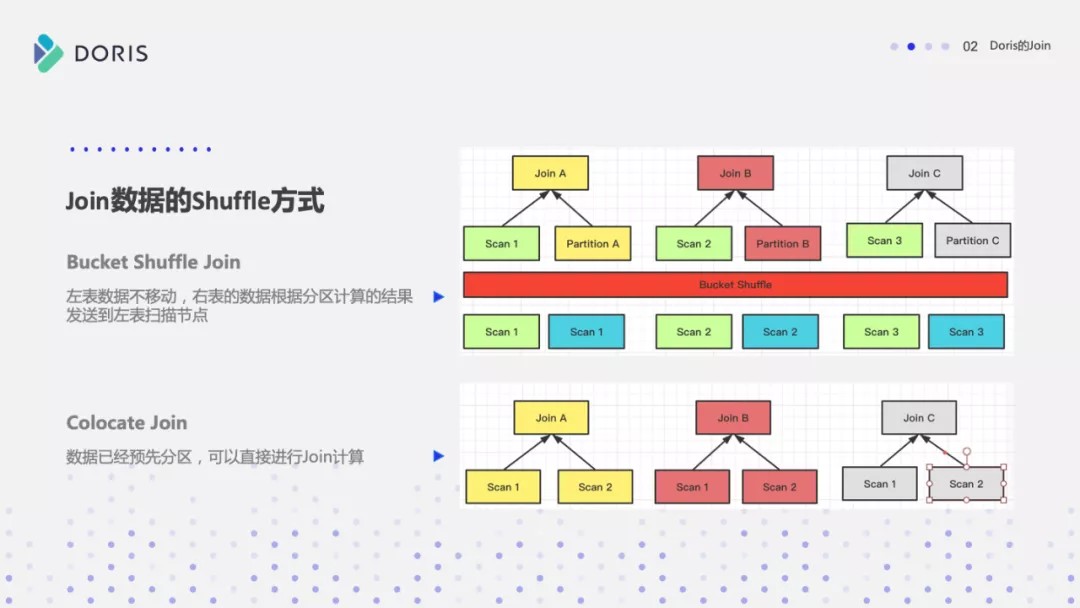
Join 数据的 Shuffle 方式
上面这 4 种方式灵活度是从高到低的,它对这个数据分布的要求是越来越严格,但 Join 计算的性能也是越来越好的。
接下来就要分享的是 Doris 近期加入的一个新特性—— Runtime Filter 的实现逻辑。
Doris 在进行 Hash Join 计算时会在右表构建一个哈希表,左表流式的通过右表的哈希表从而得出 Join 结果。而 RuntimeFilter 就是充分利用了右表的 Hash 表,在右表生成哈希表的时,同时生成一个基于哈希表数据的一个过滤条件,然后下推到左表的数据扫描节点。通过这样的方式,Doris 可以在运行时进行数据过滤。
假如左表是一张大表,右表是一张小表,那么利用左表生成的过滤条件就可以把绝大多数在 Join 层要过滤的数据在数据读取时就提前过滤,这样就能大幅度的提升 Join 查询的性能。
当前 Doris 支持三种类型 RuntimeFilter
一种是 IN—— IN,很好理解,将一个 hashset 下推到数据扫描节点。
第二种就是 BloomFilter,就是利用哈希表的数据构造一个 BloomFilter,然后把这个 BloomFilter 下推到查询数据的扫描节点。。
最后一种就是 MinMax,就是个 Range 范围,通过右表数据确定 Range 范围之后,下推给数据扫描节点。
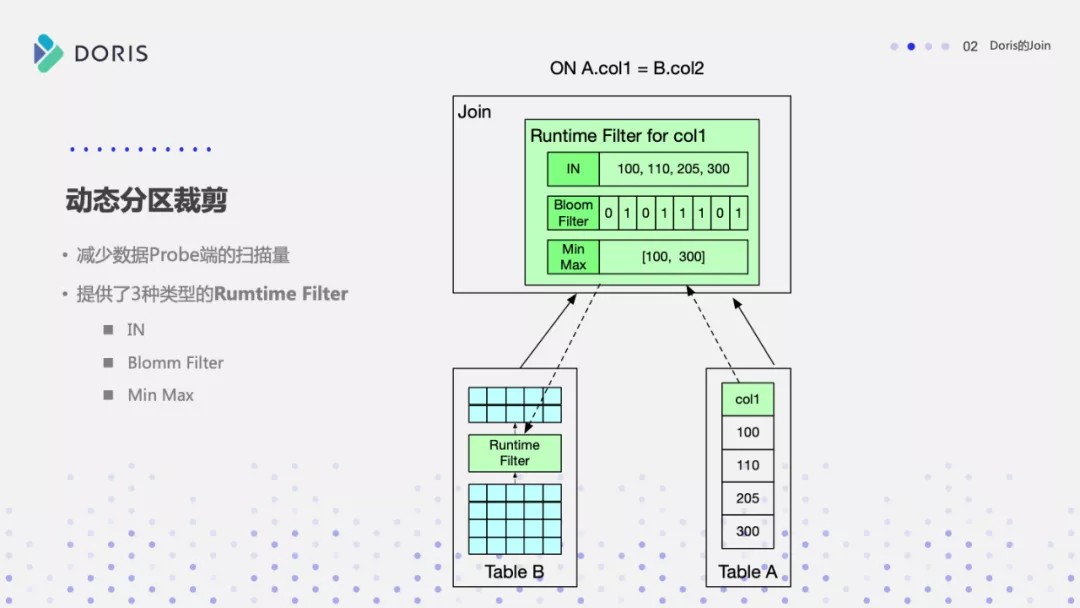
RuntimeFilter 类型
Runtime Filter 适用的场景有两个要求:
第一个要求就是右表大左表小,因为构建 Runtime Filter是需要承担计算成本的,包括一些内存的开销。
第二个要求就是左右表 Join 出来的结果很少,说明这个 Join 可以过滤掉左表的绝大部分数据。
当符合上面两个条件的情况下,开启 Runtime Filter 就能收获比较好的效果。
当 Join 列为左表的 Key 列时,RuntimeFilter 会下推到存储引擎。Doris 本身支持延迟物化,延迟物化简单来说是这样的:假如需要扫描 ABC 三列,在 A 列上有一个过滤条件: A 等于 2,要扫描 100 行的话,可以先把 A 列的 100 行扫描出来,再通过 A = 2 这个过滤条件过滤。之后通过过滤完成后的结果,再去读取 BC 列,这样就能极大的降低数据的读取 IO。所以说 Runtime Filter 如果在 Key 列上生成,同时利用 Doris 本身的延迟物化来进一步提升查询的性能。
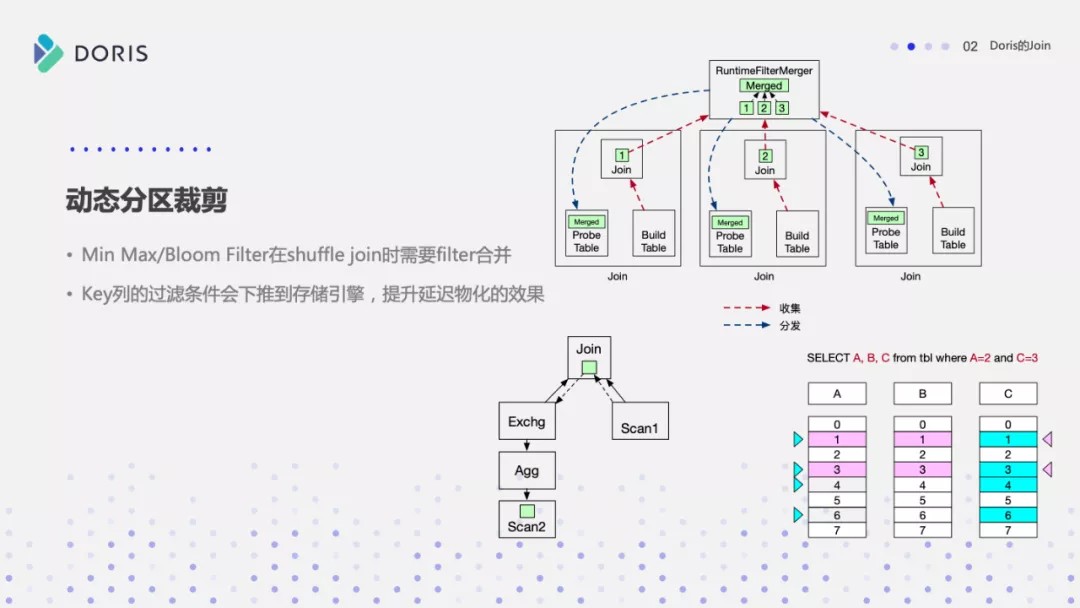 RuntimeFilter 实现机制
RuntimeFilter 实现机制
下面简单对比一下三种不同类型的 Runtime Filter 。
IN 的优点就是效果过滤效果明显,且快速。它的缺点首先第一个它只适用于 BroadCast,第二,它右表超过一定数据量的时候就失效了,当前 Doris 目前配置的是1024,即右表如果大于 1024,IN 的 Runtime Filter 就直接失效了。
MinMax 的优点是开销比较小。它的缺点就是对数值列还有比较好的效果,但对于非数值列,基本上就没什么效果。
Bloom Filter 的特点就是通用,适用于各种类型、效果也比较好。缺点就是它的配置比较复杂并且计算较高。

RuntimeFilter 的比较
最后就是 Doris Join 的一个重要机制—— Join Reorder ,在进行 Join 调优的时候会常常用到它。
数据库一旦涉及到多表 Join,Join 的顺序对整个 Join 查询的性能是影响很大的。假设有三张表 Join,参考下面这张图,左边是 a 表跟 b 张表先做 Join,中间结果的有 2000 行,然后与 c 表再进行 Join 计算。
接下来看右图,把 Join 的顺序调整了一下。把 a 表先与 c 表 Join,生成的中间结果只有 100,然后最终再与 b 表 Join 计算。最终的 Join 结果是一样的,但是它生成的中间结果有 20 倍的差距,这就会产生一个很大的性能 Diff 了。
Doris 目前支持基于规则的 Join Reorder 算法。它的逻辑是:
让大表、跟小表尽量做 Join,它生成的中间结果是尽可能小的。
把有条件的 Join 表往前放,也就是说尽量让有条件的 Join 表进行过滤
Hash Join 的优先级高于 Nest Loop Join,因为 Hash join 本身是比 Nest Loop Join 快很多的。
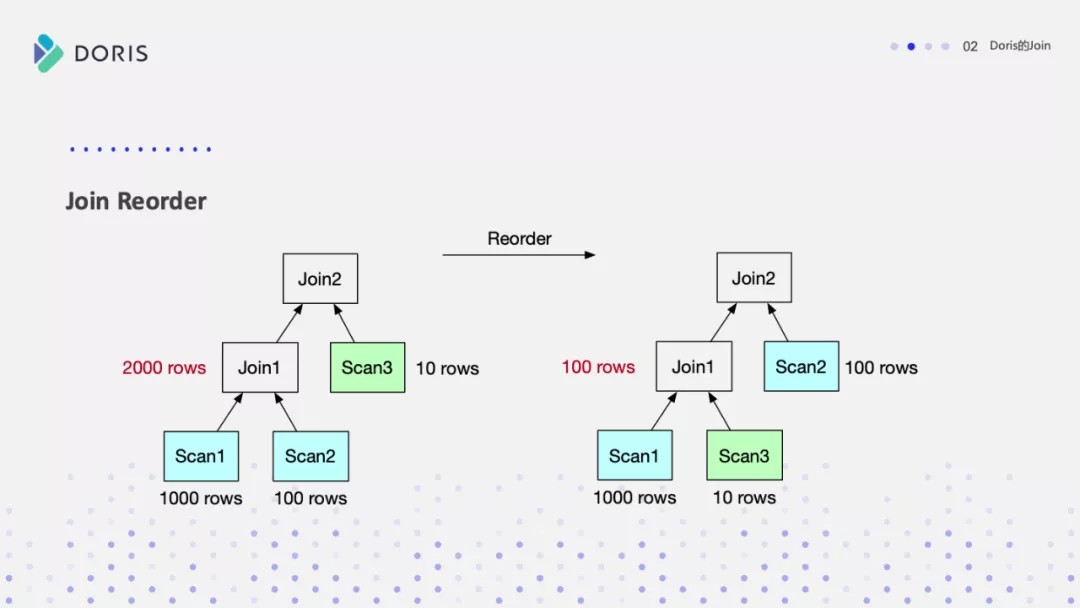
Join Reorder
Doris Join 调优实践
接下来就进入第三部分,Doris Join 的调优实践。第二部分分享了 Join 的机制之后,第三部分就需要利用 Doris 本身的一些 Join 特性,包括 Doris 提供的机制来做 Join 调优。
下面是 Doris Join 调优的方法论:
利用 Doris 本身提供的 Profile,去定位查询的瓶颈。Profile 会记录 Doris 整个查询当中各种信息,这是进行性能调优的一手资料。。
了解 Doris 的 Join 机制,这也是第二部分跟大家分享的内容。知其然知其所以然、了解它的机制,才能分析它为什么比较慢。
利用 Session 变量去改变 Join 的一些行为,从而实现 Join 的调优。
查看 Query Plan 去分析这个调优是否生效。
上面的 4 步基本上完成了一个标准的 Join 调优流程,接着就是实际去查询验证它,看看效果到底怎么样。
如果前面 4 种方式串联起来之后,还是不奏效。这时候可能就需要去做 Join 语句的改写,或者是数据分布的调整、需要重新去 Recheck 整个数据分布是否合理,包括查询 Join 语句,可能需要做一些手动的调整。当然这种方式是心智成本是比较高的,也就是说要在尝试前面方式不奏效的情况下,才需要去做进一步的分析。

Join 调优方法论
接下来通过展示几个实际的 Case,来分享一下 Join 的分析调优流程。
看下面图上的 Profile ,一个四张表 Join 的查询,通过 Profile 的时候发现第二个 Join 耗时很高,耗时 14 秒。
进一步分析 Profile 之后,发现 BuildRows,就是右表的数据量是大概 2500 万。而 ProbeRows ( ProbeRows 是左表的数据量)只有 1 万多。这种场景下右表是远远大于左表,这显然是个不合理的情况。这显然说明 Join 的顺序出现了一些问题。这时候尝试改变 Session 变量,开启 Join Reorder。
set enable_cost_based_join_reorder = true
这次耗时从 14 秒降到了 4 秒,性能提升了 3 倍多。
此时再 Check Profile 的时候,左右表的顺序已经调整正确,即右表是大表,左表是小表。基于小表去构建哈希表,开销是很小的,这就是典型的一个利用 Join Reorder 去提升 Join 性能的一个场景。

Join Reorder 典型场景
第二个 Case,存在一个慢查询,查看 Profile 之后,整个 Join 节点耗时大概44秒。它的右表有 1000 万,左表有 6000 万,最终返回的结果也只有 6000 万。
这里可以大致的估算出过滤率是很高的,那为什么 Runtime Filter 没有生效呢?通过 Query Plan 去查看它,发现它只开启了 IN 的 Runtime Filter。

RuntimeFilter 典型场景
前面介绍了,当右表超过1024行的话, IN 是不生效的,所以根本起不到什么过滤的效果,所以尝试调整 RuntimeFilter 的类型。
这里改为了 BloomFilter,左表的 6000 万条数据过滤了 5900 万条。基本上 99% 的数据都被过滤掉了,这个效果是很显著的。查询也从原来的 44 秒降到了 13 秒,性能提升了大概也是三倍多。

RuntimeFilter 典型场景
下面是一个比较极端的 Case,通过一些环境变量调优也没有办法解决,因为它涉及到 SQL Rewrite,所以这里列出来了原始的 SQL 。
这个 Join 查询是很简单的,单纯的一个左右表的 Join 。当然它上面有一些过滤条件,打开 Profile 的时候,发现整个查询 Hash Join 执行了三分多钟,它是一个 BroadCast 的 Join,它的右表有 2 亿条,左表只有 70 万。在这种情况下选择了 Broadcast Join 是不合理的,这相当于要把 2 亿条做一个 Hash Table,然后用 70 万条遍历两亿条的 Hash Table ,这显然是不合理的。

SQL ReWrite 典型场景
为什么会产生不合理的 Join 顺序呢?其实这个左表是一个 10 亿条级别的大表,它上面加了两个过滤条件,加完这两个过滤条件之后, 10 亿条的数据就剩 70 万条了。但 Doris 目前没有一个好的统计信息收集的框架,所以它不知道这个过滤条件的过滤率到底怎么样。所以这个 Join 顺序安排的时候,就选择了错误的 Join 的左右表顺序,导致它的性能是极其低下的。
下图是改写完成之后的一个 SQL 语句,在 Join 后面添加了一个Join Hint,在Join 后面加一个方括号,然后把需要的 Join 方式写入。这里选择了 Shuffle Join,可以看到右边它实际查询计划里面看到这个数据确实是做了 Partition ,原先 3 分钟的耗时通过这样的改写完之后只剩下 7 秒,性能提升明显。
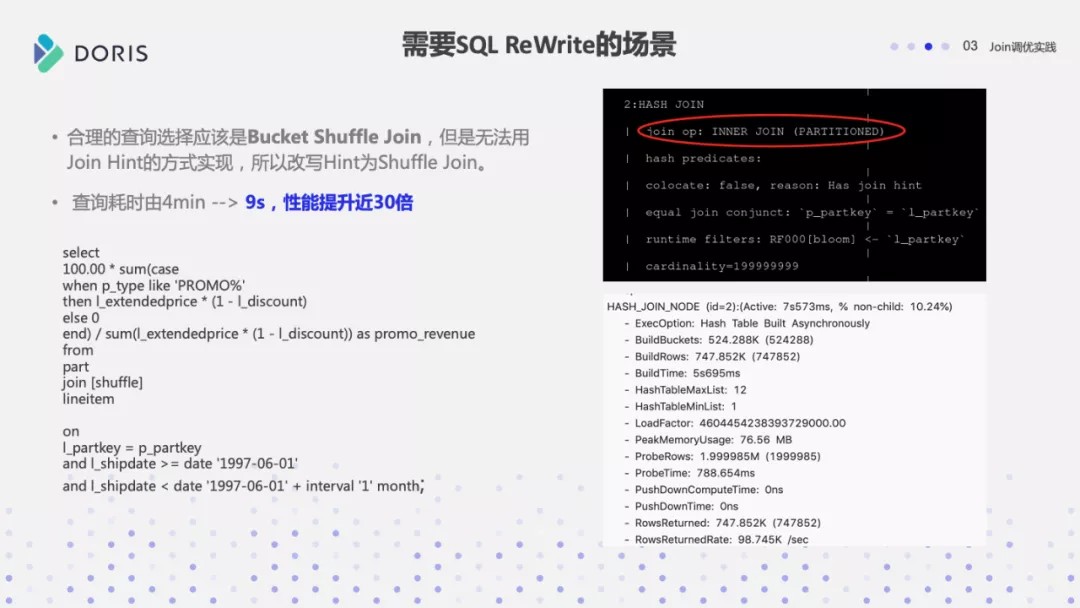
SQL ReWrite 典型场景
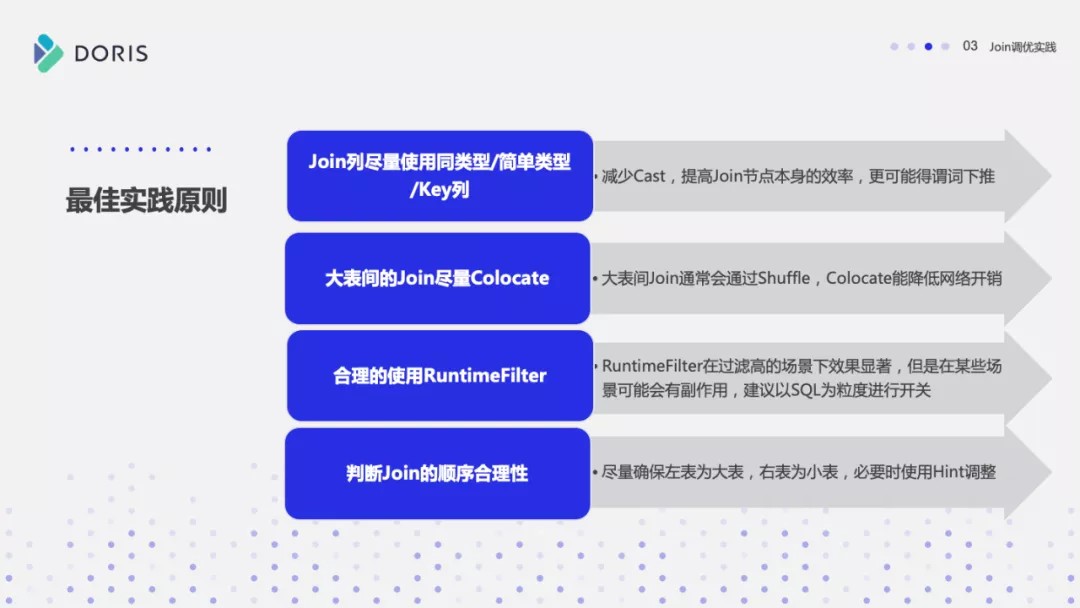
接下来就根据今天分享的内容做一个 最佳实践原则总结。主要分为 4 点:
第一点:在做 Join 的时候,要尽量选择同类型或者简单类型的列,同类型的话就减少它的数据 Cast,简单类型本身 Join 计算就很快。
第二点:尽量选择 Key 列进行 Join, 原因前面在 Runtime Filter 的时候也介绍了,Key 列在延迟物化上能起到一个比较好的效果。
第三点:大表之间的 Join ,尽量让它 Co-location ,因为大表之间的网络开销是很大的,如果需要去做 Shuffle 的话,代价是很高的。
第四点:合理的使用 Runtime Filter,它在 Join 过滤率高的场景下效果是非常显著的。但是它并不是万灵药,而是有一定副作用的,所以需要根据具体的 SQL 的粒度做开关。
最后:要涉及到多表 Join 的时候,需要去判断 Join 的合理性。尽量保证左表为大表,右表为小表,然后 Hash Join 会优于 Nest Loop Join。必要的时可以通过 SQL Rewrite,利用 Hint 去调整 Join 的顺序。
Join 调优最佳实践原则
本文来自公众号: ApacheDoris
作者:李昊鹏

发表评论
登录后可评论,请前往 登录 或 注册