对视觉任务更友好的Transformer,北航团队开源Visformer!
作者:苏大泽2021.09.13 15:03浏览量:753简介:本文通过逐步改变模型结构,将基于Transformer的模型逐步过渡到基于卷积的模型。
▊ 写在前面
目前,将基于视觉任务的Transformer结构正在快速发展。虽然一些研究人员已经证明了基于Transformer的模型具有良好的数据拟合能力,但仍有越来越多的证据表明这些模型存在过拟合,特别是在训练数据有限的情况下。
本文通过逐步改变模型结构,将基于Transformer的模型逐步过渡到基于卷积的模型。在过渡过程中获得的结果,为提高视觉识别能力提供了有用的信息。
基于这些观察结果,作者提出了一种名为Visformer(Vision-friendly Transformer)的新架构 。在相同的计算复杂度下,Visformer在ImageNet分类精度方面,优于基于Transformer和基于卷积的模型,当模型复杂度较低或训练集较小时,优势变得更加显著。
▊ 1. 论文和代码地址

Visformer: The Vision-friendly Transformer
论文:https://arxiv.org/abs/2104.12533v4
代码:https://github.com/danczs/Visformer
▊ 2. Motivation
在过去的十年里,卷积在视觉识别的深度学习模型中起着核心作用。当源自自然语言处理的Transformer被应用到视觉场景中时,这种情况就开始发生改变。ViT模型表明,一张图像可以被分割成多个patch网格,Transformer直接应用在网格上,每个patch都可以看做是一个视觉单词。
ViT需要大量的训练数据(ImageNet-21K或JFT-300M数据集),因为Transformer建模了长距离的注意和交互,因此容易发生过拟合。后面也有一些工作基于ViT继续做改进,但是效果依旧不佳,特别是在训练数据有限的情况下。
另一方面,在大量数据训练下,视觉Transformer可以获得比基于卷积的模型更好的性能。也就是说,视觉Transformer具有更高的性能“上限”,而基于卷积的模型性能“下界”更好。上界和下界都是神经网络的重要特性。上界是实现更高性能的潜力,下界使网络在有限数据训练或扩展到不同复杂性时表现更好。
基于对Transformer-based和基于卷积的网络的下界和上界的观察,本文的主要目的是探究差异背后的原因,从而设计出具有较高下界和上界的网络。基于Transformer的网络和基于卷积的网络之间的差距可以在ImageNet上通过两种不同的训练设置来揭示。
第一个是基本设置(base setting) 。它是基于卷积的模型的标准设置,即训练周期更短,数据增强只包含基本的操作,如random-size cropping、 flipping。将此设置下的性能称为基本性能(base performance) 。
另一个设置是精英设置(elite setting) ,它对基于Transformer的模型进行了专门的调整,即训练周期更长,数据增强更强( RandAugment、CutMix等)。将此设置下的性能称为精英性能(elite performance) 。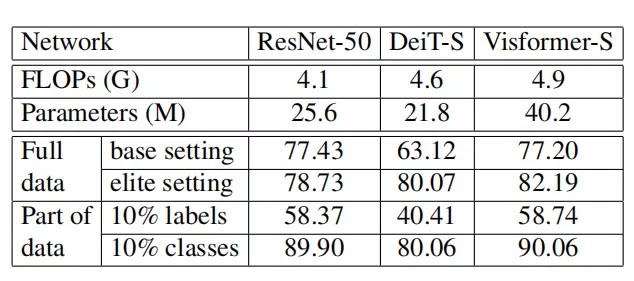
在本文中,作者以DeiT-S和ResNet-50作为基于Transformer和基于卷积的模型的代表。在不同数量训练数据和训练设置下的两个模型结果如上表所示。可以看出,Deit-S和ResNet-50采用了相近的FLOPs和参数。
然而,在这两种设置下,它们在完整数据上的表现非常不同。Deit-S具有更高的精英性能,但从精英到基础会导致DeiT-S的精度下降10%以上。ResNet-50在基础设置下表现得要好得多,但对精英设置的提升仅为1.3%。这促使作者去研究这些模型之间的区别。
在这两种设置下,可以大致估计模型的下界和上界。作者使用的方法是执行一步一步的过渡操作,以逐步将一个模型变成另一个模型,这样就可以进一步认知这两个网络中的模块和设计的特性。作者将转换的过程分为8个步骤。
具体来说,从DeiT-S到ResNet-50,应
(i)使用全局平均池化 (非分类token)
(ii)引入逐步的patch embedding
(iii)采用多阶段 的主干网络设计
(iv)使用Batch Norm (非Layer Norm)
(v)利用3×3卷积
(vi)放弃position encoding 方案
(vii)用卷积替换Self-Attention
(viii)调整网络形状 (如深度、宽度等)
在深入分析了结果背后的原因后,作者采用了所有有助于视觉识别的因素,并提出Visformer(Vision-friendly Transformer)。
如上表所示,在ImageNet分类评估上,Visformer比DeiT和ResNet的性能更好。在精英设置下,在类似的模型复杂度下,Visformer-S模型分别比DeiT-S和ResNet-50高出2.12%和3.46%。
当使用10%的类和数据训练时,Visformer-S甚至表现优于ResNet-50,这揭示了Visformer-S的高性能下界。此外,对于tiny模型,Visformer-ti的性能超过Deit-Ti 6%以上。
▊ 3. 方法
3.1. 基于Transformer和基于卷积的视觉识别模型
识别是计算机视觉中的基本任务。本文主要考虑图像分类,其中输入图像通过深度网络传播,得到输出类标签。大多数深度网络都是以分层的方式设计的。
在本文中,作者考虑了两种结构:Transformer和卷积。卷积用于捕获可重复的局部特征,它使用许多可学习的卷积核来计算输入对不同模式的响应。在本文中,作者将研究限制在残差块(卷积+残差)内,并在相邻的卷积层之间插入非线函数(激活函数、normalization)。
另一方面,Transformer起源于自然语言处理,其目的是捕获任何两个token之间的关系,即使它们彼此相距很远。这是通过为每个token生成三个特征来实现的,分别称为query、key和value。
然后,将每个token的响应计算为所有value的加权和,其中权重由其query与相应key之间的相似性决定。这个操作被称为多头自注意(MHSA)。Transformer Block中还包含其他操作,包括归一化和线性映射。
在本文中,作者考虑DeiT-S和ResNet-50分别作为基于Transformer和基于卷积的模型的代表。除了基础架构之外,这两个网络在设计上也有一些不同,比如ResNet-50有一些向下采样层,将模型划分为多个阶段,但在整个DeiT-S中,token的数量保持不变。
3.2.基础(base)和精英(elite)设置
虽然DeiT-S的准确率为80.1%,高于ResNet-50的78.7%,但我们可以注意到DeiT-S显著改变了训练策略,例如,训练周期的数量增加了3×以上,数据增强变得更强。
有趣的是,DeiT-S似乎严重依赖于精心调整的训练策略,其他基于Transformer的模型,包括ViT和PIT,也说明了它们对其他因素的依赖性,例如,大规模的训练集。接下来,作者对这一现象进行了全面的研究。
作者在ImageNet数据集上评估了所有的分类模型,该数据集有1K类、1.28万训练图像和50K测试图像。每个类的训练图像的数量大致相同。
对每个识别模型的优化都有两个设置。
第一个为基础设置 ,并被基于卷积的网络广泛采用。使用SGD优化器进行90个epoch的训练。batch大小为512的学习速率从0.2开始,然后随着余弦退火函数逐渐衰减到0.00001。采用随机裁剪和翻转等简单的数据增强策略。
第二种为精英设置 ,它已被验证可以有效地改进基于Transformer的模型。batch大小为512,优化器为初始学习率为0.0005的Adamw优化器。为了避免过拟合,采用了更强的数据增强策略:Mixup、Mixup、 Random Erasing、Repeated Augmentation等等。相应地,训练持续300个epoch,比基础设置的时间要长得多。
模型在这两个设置下得到的分类精度分别称为基础性能 和精英性能 。
3.3.从DeiT-S到ResNet-50的过渡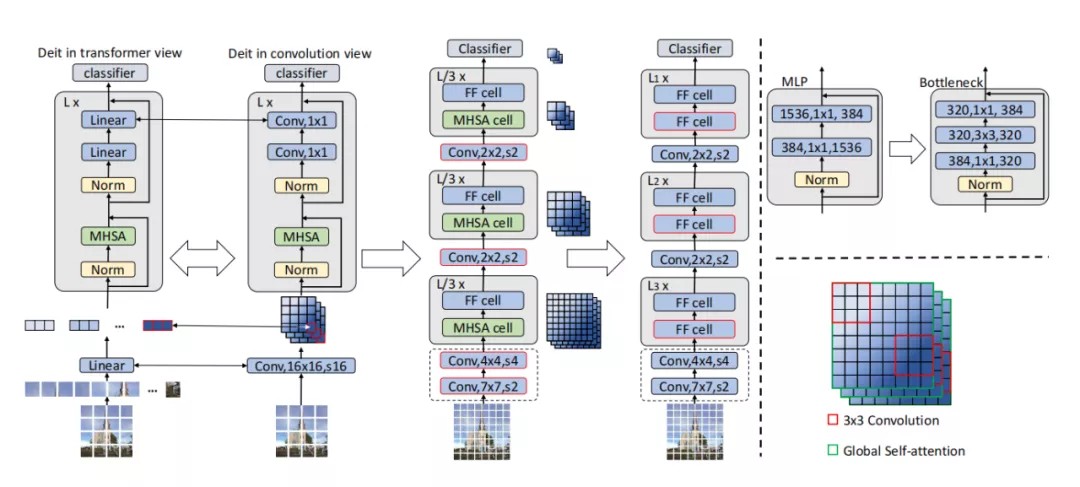
本节显示了从DeiT-S到ResNet-50转换的分解过程,共有八个步骤。关键步骤如上图所示。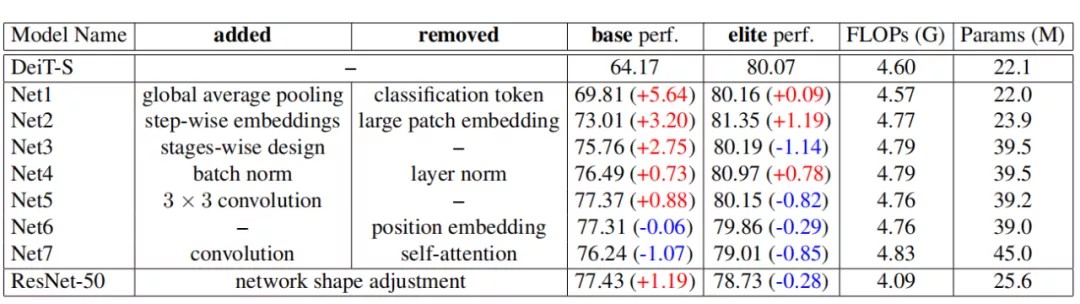
分解过程中得到的网络性能如上表所示。
3.3.1使用全局平均池化来替换分类token
转换的第一步是删除分类token,并向基于Transformer的模型添加全局平均池化。与基于卷积的模型不同,Transformer通常会在输入中添加一个分类token,并利用相应的输出token来执行分类。相比之下,基于卷积的模型通过空间维度的全局平均池化获得分类特征。
通过删除分类token,Transformer可以等价地转换为卷积版本。patch embedding操作等价于其卷积核大小和步长是patch大小的卷积。MHSA和MLP块中的线性层等价于1×1卷积。(如上图所示)
通过这些操作得到Net1,这个结构的performance如上表所示。可以看出,这种转变可以极大地提高基础性能。作者进一步的实验表明,添加全局池化本身可以将基础性能从64.17%提高到69.44%。此外,这种转变可以略微提高精英性能。
3.3.2用 step-wise patch embedding替换patch flattening
DeiT和ViT模型直接用patch embedding层对图像进行编码,这相当于核大小和步幅等于patch size的卷积。然而,patch flatten操作会损害每个patch内的位置信息,使得提取patch内的信息变得更加困难。为了解决这一问题,现有的方法通常在patch embedding之前附加一个预处理模块。这个预处理模块可以使用卷积网络或者Transformer。
作者采用有一个相当简单的解决方案,即将大patch embedding分解为逐步的小patch embedding。具体来说,作者首先将ResNet中的stem层添加到Transformer上,这是一个7×7的卷积层,步幅为2。
由于原始DeiT模型中的patch大小为16,所以还需要在stem层后embed 8×8的patch。作者将8 × 8 patch embedding分成了4 × 4 embedding和 2 × 2 embedding,由4×4和2×2的卷积层实现。
此外,作者还添加了一个额外的2×2卷积,以便在分类前进一步将patch大小从16×16进一步升级到32×32。这些patch embedding层也可以看作是下采样层,在每次下采样的时候,作者将通道数增加了一倍。
通过利用step-wise patch embedding,patch内的先验位置被编码到特征中。从上表可以看出,Net2可以显著提高网络的基础性能和精英性能。这表明,在基于Transformer的模型中,step-wise patch embedding是比更大的patch embedding更好的选择。此外,这种转换具有计算效率,只引入了大约4%的额外FLOPs。
3.3.3多阶段设计
在本节中,作者将网络分成了多阶段。同一阶段的block具有相同的特征分辨率。由于step-wise patch embedding已经在embedding的时候将网络分成了不同的阶段,因此本节中的转换是将Transformer Block重新分配到不同的阶段,如上图所示(中)。
在这种转变下,基础性能得到了进一步的提高。这种设计利用了图像局部先验,因此在轻量的数据增强下模型能表现得更好。然而,该网络的精英性能明显下降。为了研究原因,作者进行了消融实验,发现 self-attention在很大的分辨率下不能很好地工作。作者推测大分辨率特征包含太多的token,而self-attention很难学习它们之间的关系。
3.3.4用LayerNorm替换BatchNorm
与BatchNorm相比,LayerNorm与Batch大小无关,对特定任务更友好,而BatchNorm在适当的Batch大小下通常可以获得更好的性能。作者用BatchNorm替换所有的LayerNorm,结果表明BatchNorm的性能优于LayerNorm。它可以提高网络的基础性能和精英性能。
此外,作者还尝试在Net2中添加BatchNorm,以进一步提高精英性能。然而,该Net2-BN网络存在收敛性问题。这就解释了为什么BatchNorm在纯Self-Attention模型中没有得到广泛的应用。但对于本文的混合模型,BatchNorm是提高性能的可靠方法。
3.3.5引入3×3卷积
由于网络的token以特征图的形式存在,因此引入核大小大于1×1的卷积是很自然的。大核卷积的具体含义如上图的右下角所示。全局 self-attention试图建立所有token之间的关系时,而卷积将局部邻域内的token联系起来。
因此,作者选择在feed-forward中的1×1卷积之间插入3×3卷积,从而将MLP块转换为bottleneck块,如上图的右上角所示。所获得的bottleneck块与ResNet-50中的bottleneck块相似,但它们的bottleneck比例不同。作者在所有三个阶段中都用bottleneck块替换MLP块。
3×3卷积可以利用图像中的局部先验,进一步提高了网络的基础性能。基础性能(77.37%)与ResNet-50(77.43%)相当。但精英性能下降了0.82%。作者进行了更多的实验来研究其原因——没有向所有阶段添加3×3卷积,而是分别向不同阶段插入3×3卷积。
作者观察到3×3卷积只在高分辨率特征上有效。作者推测,利用局部关系对于自然图像中的高分辨率特征是很重要的。然而,对于低分辨率的特征,在配备了全局self-attention时,局部卷积是不重要。
3.3.6移除position embedding
在基于Transformer的模型中,position embedding对token间的位置信息进行了编码。在本节的过渡网络中,作者删除了position embedding。
结果如上表所示,基础性能几乎没有变化,精英性能略有下降(0.29%)。作为比较,作者测试删除了DeiT-S的position embedding,精英性能显著下降了3.95%。
结果表明,position embedding在过渡模型中的作用不如基于纯Transformer的模型重要。因为过渡模型中的卷积操作已经利用了位置信息,这也解释了为什么基于卷积的模型不需要position embedding。
3.3.7用feed-forward来代替self-attention
在本节中,作者删除每个阶段的self-attention,而使用feed-forward层,使网络成为一个纯基于卷积的网络。所得网络(Net7)的性能如上表所示。基于纯卷积的网络在基础性能和精英性能都要差得多。
这表明,self-attention能够驱动神经网络获得更高的精英性能,并且不是导致ViT或DeiT的基础性能差的原因。因此可以设计一个具有高基础性能和精英性能的self-attention网络。
3.3.8调整网络的形状
Net7和ResNet-50之间仍有许多区别。但是,这两个网络都是基于卷积的网络。这两种网络之间的性能差距可以归因于网络架构设计策略。
上表的结果表明,ResNet-50具有更好的网络架构,并且可以在更少的FLOPs下表现得更好。然而,ResNet-50的精英表现更差。这表明,基本性能和精英性能之间的不一致性不仅存在于self-attention模型中,而且也存在于基于纯卷积的网络中。
3.4. Visformer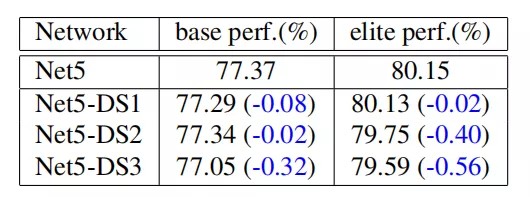
作者的目标是建立一个具有高基础性能和精英性能的网络。过渡研究表明,基础性能和精英性能之间存在一定的不一致性。
第一个问题是阶段性设计,它提高了基本性能,但降低了精英性能 。为了研究其原因,作者将Net5的每个阶段的bottleneck块分别替换为Self-Attention块,从而估计不同阶段的Self-Attention的重要性。
结果如上表所示,在所有三个阶段中,Self-Attention的取代都降低了基础性能和精英性能。此外,取代第一阶段的Self-Attention几乎对网络性能没有影响。更大的分辨率包含更多的token,作者推测Self-Attention要学习它们之间的关系更困难,因此低分辨率的Self-Attention比高分辨率的Self-Attention发挥着更重要的作用。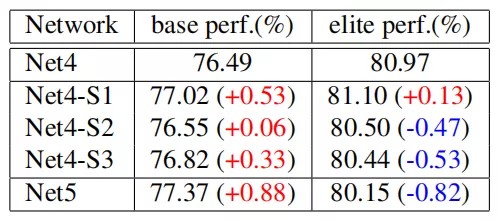
第二个问题是在前馈块中添加3×3卷积,这使精英性能降低了0.82% 。基于Net4,作者在每个阶段分别用bottleneck块替换MLP块。如上表所示,尽管所有阶段都在基础性能上得到了改进,但只有第一阶段精英性能得到提升。
当Self-Attention在这些位置上已经有了一个全局视图时,3×3卷积对于其他两个低分辨率的阶段是不必要的。在高分辨率阶段,Self-Attention难以处理所有的token,3×3卷积可以提供改进。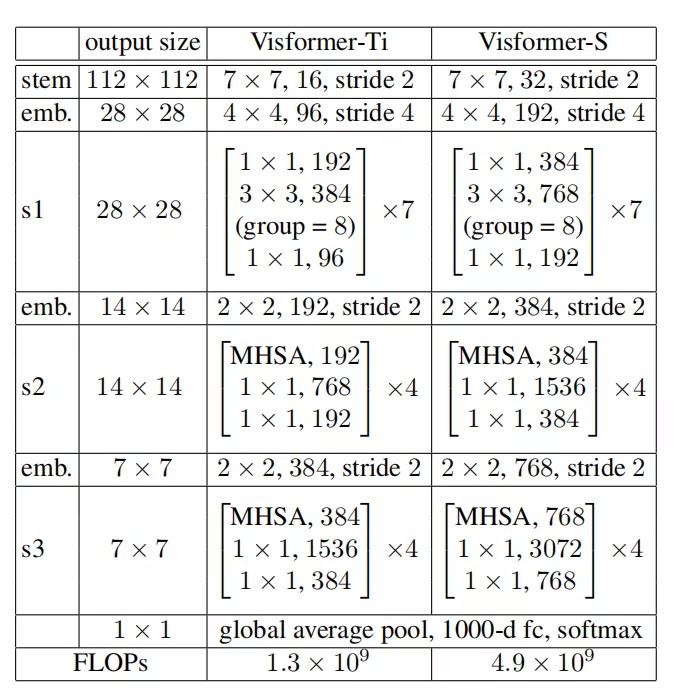
结合上述观察结果,作者提出了Visformer,结构如上表所示。
▊ 4.实验
4.1. Comparison to the state-of-the-arts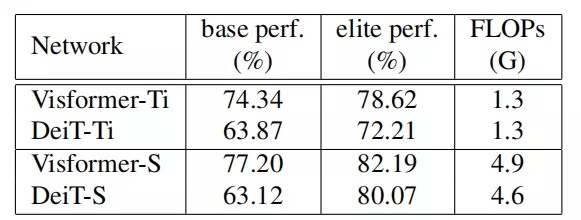
上表比较了Visformer和DeiT的性能,在基础设置和精英设置下,Visformer都优于DeiT,并且在基础设置下优势更显著。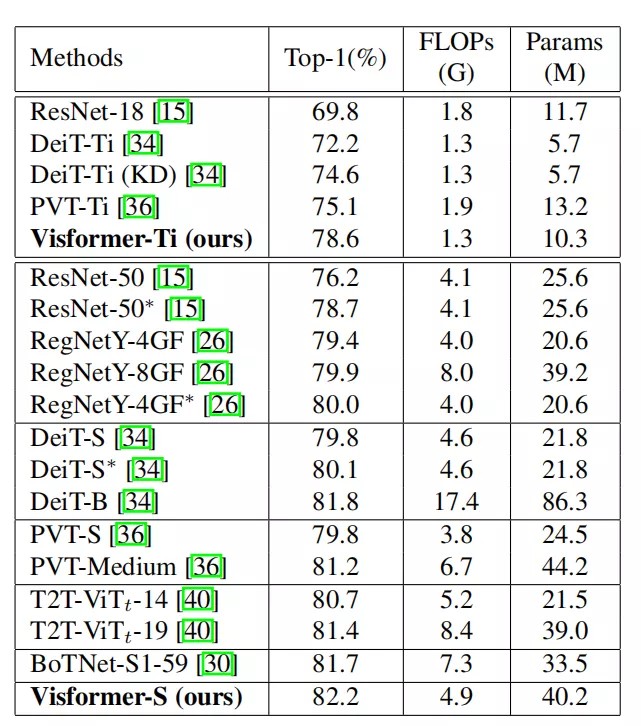
上表比较了Visformer和其他Transformer-based模型性能。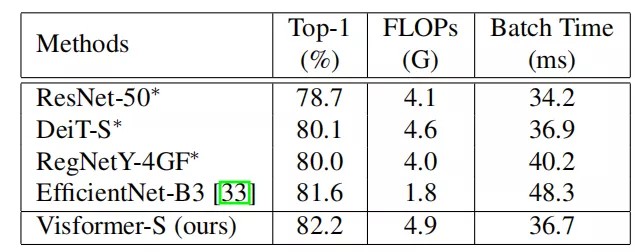
上表比较了Visformer和CNN模型性能。
4.2. Training with limited data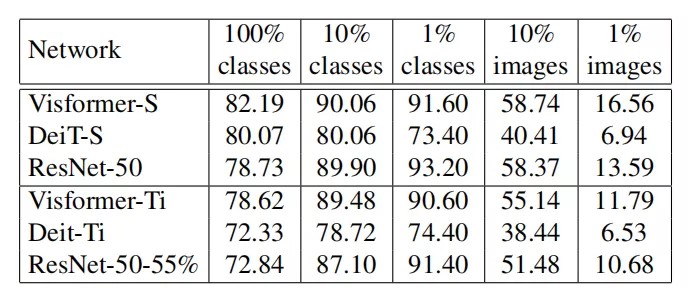
上表比较了在有限数据集下,三种模型的对比,可以看出Visformer都取得了不错的结果。
▊ 5. 总结
本文提出了一种的有利于视觉识别Transformer模型——Visformer。作者使用两个设置,基础和精英设置,来评估每个模型的性能。为了研究基于Transformer的模型和基于卷积的模型表现不同的原因,作者分解了这些模型之间的差距,并设计了一个八步过渡步骤,以研究DeiT-S和ResNet-50之间的差距。
通过吸收优点并丢弃缺点,作者得到了同时优于DeiT-S和ResNet-50的Visformer-S模型。当被转移到一个紧凑的模型和在小数据集上进行评估时,Visformer也展现出了不错的性能。
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV
本文来自于公众号:我爱计算机视觉
作者:小马
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册