无监督算法在虎牙风控的探索实践
作者:原野2021.09.23 15:00浏览量:574简介:本文会简单介绍虎牙主要的业务场景以及存在的风险,其次是黑产常见的攻击技术手段以及传统应对方法的不足。
导读:本文的主题为无监督算法在虎牙风控的探索实践,首先会简单介绍虎牙主要的业务场景以及存在的风险,其次是黑产常见的攻击技术手段以及传统应对方法的不足。第二部分会分享无监督算法在虎牙风控中的落地实践,详细介绍我们如何从全局出发挖掘数据之间的关联,并结合聚类技术发现黑产的攻击模式。
01 背景介绍
首先和大家分享下虎牙风控的背景。
1. 虎牙的业务场景和风险

现在虎牙的主要业务场景及其潜在的风险有几种:第一种是营销活动作弊,比如百宝箱、藏宝图、平台的商业银豆等;第二种是内容违规风险,包括直播违规、视频违规、文本违规等;第三种是刷量刷榜,比如虚假搜索问题、虚假人气问题;第四种是充值作弊和渠道流量作弊。
2. 黑产常见的攻击手段

黑产有哪些常见攻击手段呢?
账号维度:我们知道单个账号能够薅的羊毛是非常少的,而且影响不大,所以黑产要有批量收益必须要有批量的账号资源,而账号资源主要通过批量注册以及盗号来实现。批量注册账号需要通过(1)虚拟运营商购买手机号或者购买海外黑手机卡;2)接码平台接码服务。
设备维度:现在很多平台都会对账号关联的设备个数进行限制,黑产会通过协议挂、多开设备、设备农场等躲过平台检测。
IP维度:通过ADSL拨号、代理服务器等方式躲过平台IP频次的监控。
欺诈工具维度:提供自动破解验证码的打码平台、通过按键精灵模拟用户操作的工具等。
3. 传统黑产对抗方案

我们可以看到,黑产攻击的手段变化多端。针对黑产的攻击,传统的对抗方案主要有以下几种:
专家规则:业务人员从以往黑产对抗经验中提取有效规则进行拦截
黑、灰、白名单:构建IP、设备等的黑白名单
有监督风控模型:通过收集历史黑样本,训练有监督模型
4. 黑产对抗:目标和挑战

传统的对抗方案存在一些问题:
第一,依赖于专家业务经验,被动的预防欺诈;
第二,更多关注单个个体的识别,对团伙作案效果较差;
第三,误杀率高,会对正常用户的体验造成不良影响。
所以我们在构建自己的风控体系时,希望首先做到主动检测和预防新型黑产攻击,事前风控;其次是提高精准率,并减少对正常用户的影响;第三我们希望结果具有可解释性,便于业务人员使用。
5. 无监督算法

基于上述目标,我们将无监督算法应用在我们风控体系中。我们的模型不依赖于标注样本,而是从全局出发,通过数据之间的关联挖掘新型的攻击模式。如左图,单看某一个点,并不能发现什么特别的地方,但如果从全局出发(如右图)我们会发现有规律的图像。黑产风控中无监督算法的核心就是通过关联来发现攻击模式。
02 无监督算法在虎牙风控的实践
下面我们详细分享下无监督算法在虎牙风控的实践。
1. 系统框架
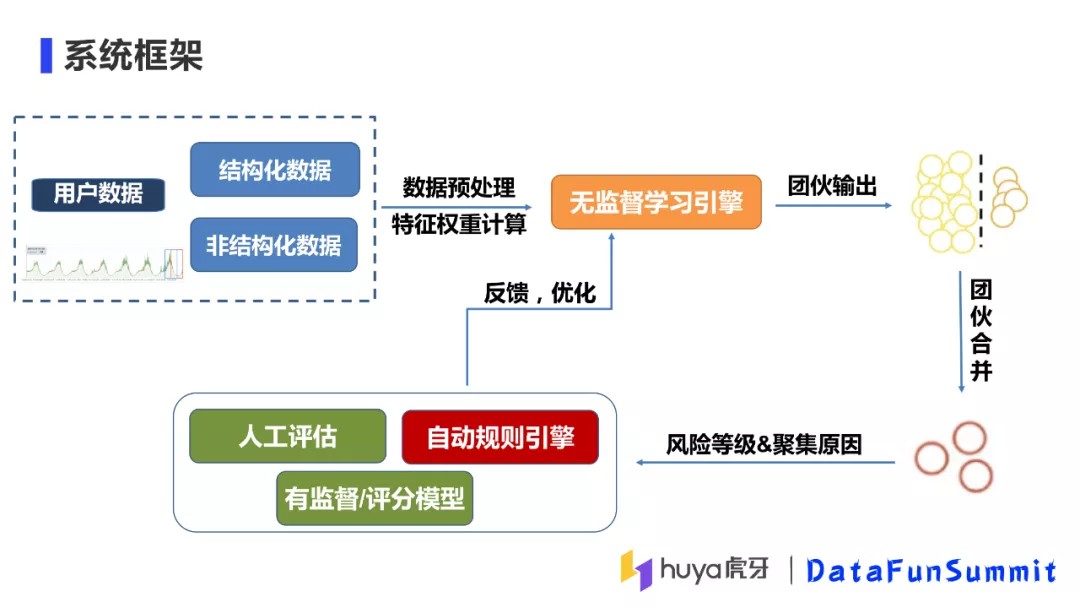
上图是整体的系统框架,我们首先会收集一定时间窗口内数据,包括结构化数据和非结构化数据,再进行数据预处理、特征工程,最后将数据输入到到无监督学习引擎。无监督学习引擎会输出团伙信息,这些团伙会与系统现有团伙进行合并,最终输出每个团伙的风险等级及其聚集原因。这些输出结果的用处有三个:第一个是自动化规则引擎会根据团伙的信息做自动化风控,比如生成策略、进行拦截等等;第二个我们会对团伙进行人工抽检评估,检验是否有误杀情况,并将结果反馈到算法,进行迭代优化;第三个是将用户所属的团伙信息作为用户的画像因子,提供给后续的有监督评分模型。
以上是整体的系统框架,下面详细介绍下在算法落地时遇到的技术问题。
2. 技术细节
① 如何计算相似度
在利用用户之间的关联发现攻击模式过程中,如何计算用户的关联或相似度?

一种naïve的方式是默认所有特征的权重一样,直接计算两个用户的jaccard距离,用该距离来表示用户之间的相似度。但是这种方式是不合理的,因为不同特征的重要程度不同,比如ip相同的两个用户显然比手机号城市相同的两个用户的关联程度要大,所以在实际计算中我们会给不同的特征赋予不同的权重,通过带权重的jaccard距离来表征用户之间的关联。
② 如何自动计算特征权重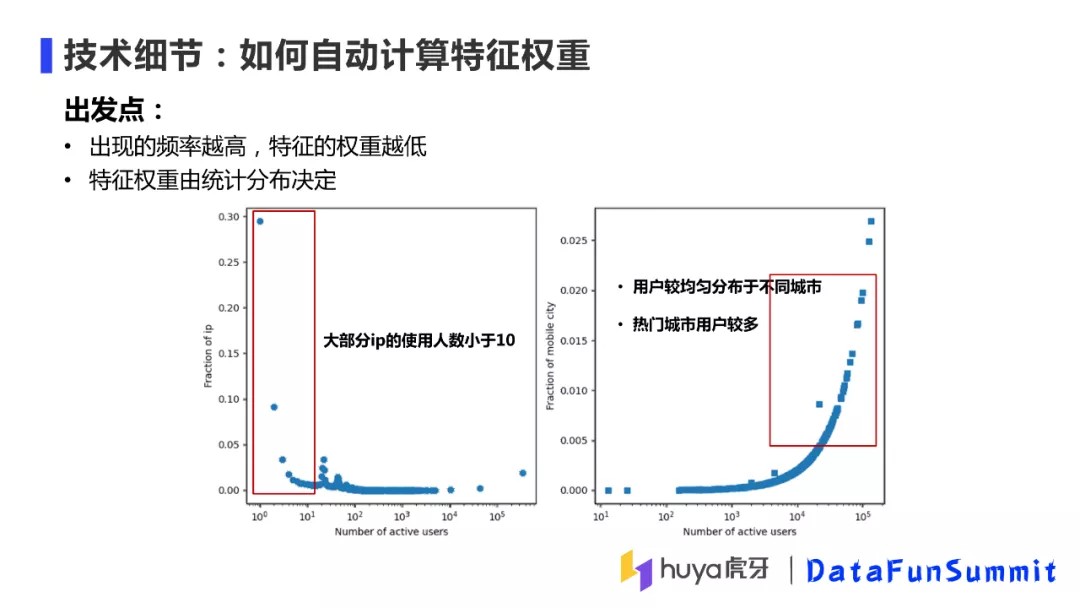
不同特征的权重如何确定呢?在实际处理的时候,如果一个特征出现的频率越低,那么它的权重应该越高,比如单个IP出现的频率很低,则IP的特征权重应该比较高。但是类似手机号城市这种特征,出现的频率高,则权重则相应比较低。其次,特征的权重也受其统计分布影响,上图中分别给出了IP和手机号的分布图,大部分IP的使用人数小于10,使用人数成指数衰减分布,而手机号分布相对均匀,热门城市用户会多一些。综上两点,我们会根据特征出现的频率及分布情况确定特征的权重。
③ 算法选取 I
确定了用户的关联后该如何做聚类呢?我们在业务实践中主要尝试了两类算法,第一类是基于图的算法,如下图。

基于模块度的算法:如louvain,该算法是基于模块度的社区划分算法。它定义了模块度Q来刻画社区内节点的连边数与随机情况下的边数的差值,Q越大,表示社群划分的越好。
基于最小熵聚类:如infomap,该算法从信息论的角度出发,想解决的问题如下:假设在图上做随机游走,如何用最少的编码长度来表示游走的路径。如果节点存在社区结构,那社区内节点就可以共享社区的比特位,因此可以得到更小的平均比特,所以可以通过不断优化L(用来描述随机游走的平均每步编码长度)来进行社区划分。
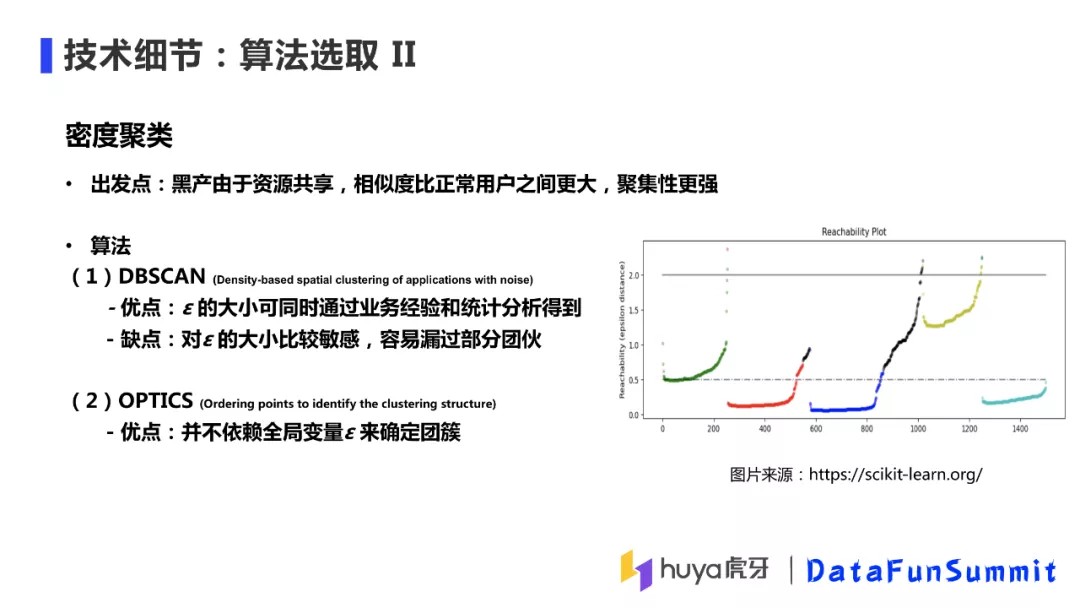
④ 算法选取 II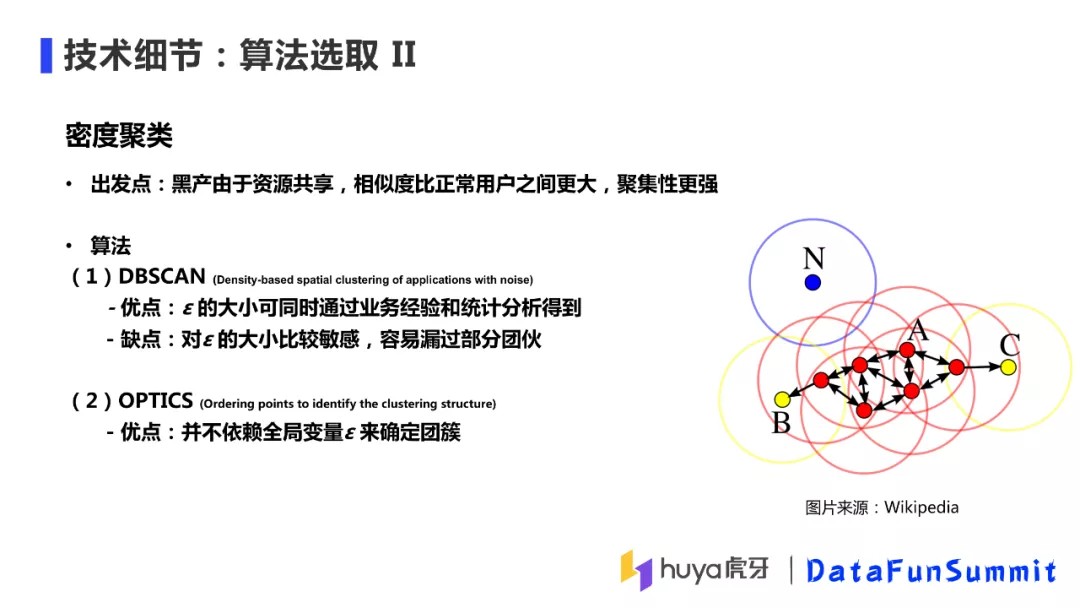
第二类尝试的算法是密度聚类,我们的出发点是黑产攻击过程中由于资源共享,黑产用户之间的相似度会比正常用户相似度要大,聚集性更强,所以密度聚类能有效捕捉这种攻击方式。我们主要是试验了以下两种算法:
DBSCAN:
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是比较有代表性的基于密度的聚类算法。该方法的核心是从某个核心点出发,不断向该核心点的密度可达区域内扩张,最终得到包括核心点及边界的区域。这里涉及到两个概念,一个是密度可达区域,是由参数ε决定,一个点的密度可达区域是指所有与该点距离小于ε的一个区域;第二个概念是核心点,是由参数n确定的,一个点密度可达区域内的邻居点个数大于或等于n,则该点就是一个核心点,否则就是边界点。
DBSCAN的优点:在实际应用中DBSCAN的效果是比较好的,契合业务场景;ε的大小也可以根据场景来调整,算法的精准度较高。
DBSCAN的缺点:对ε大小很敏感,容易漏掉部分团伙。比如下图中场景,在图上有三个密度比较大的团簇,还有两个密度比较小的团簇,如果要把密度大的三个团簇找出来,则需要将ε设置的小一些,这个时候就会失去右上角密度稀疏的簇;如果将ε设置的大一些,就会识别出密度稀疏的团簇,但是原来两个密度大的簇会变成一个簇。
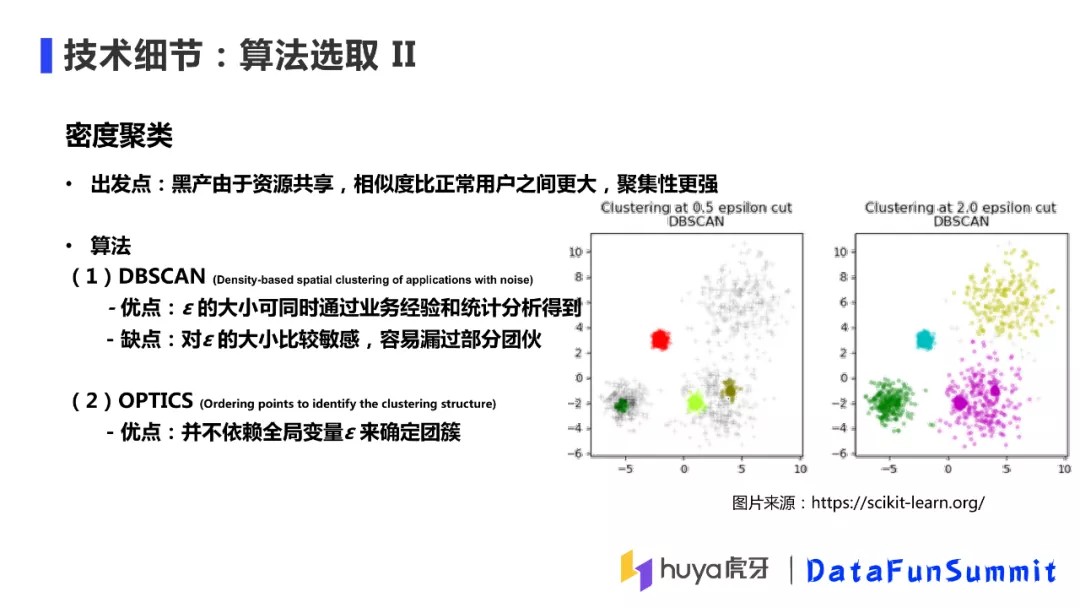
OPTICS:
OPTICS是为了解决DBSCAN对ε的敏感依赖问题而提出的,该算法是将ε设定为无穷大之后来做聚类,最终的输出是一个有序的队列,从这个队列里可以获得任意序列的聚类,如图,将ε设置为0.5,则输出和DBSCAN(ε=0.5)的结果一致。
⑤ 如何计算团伙分数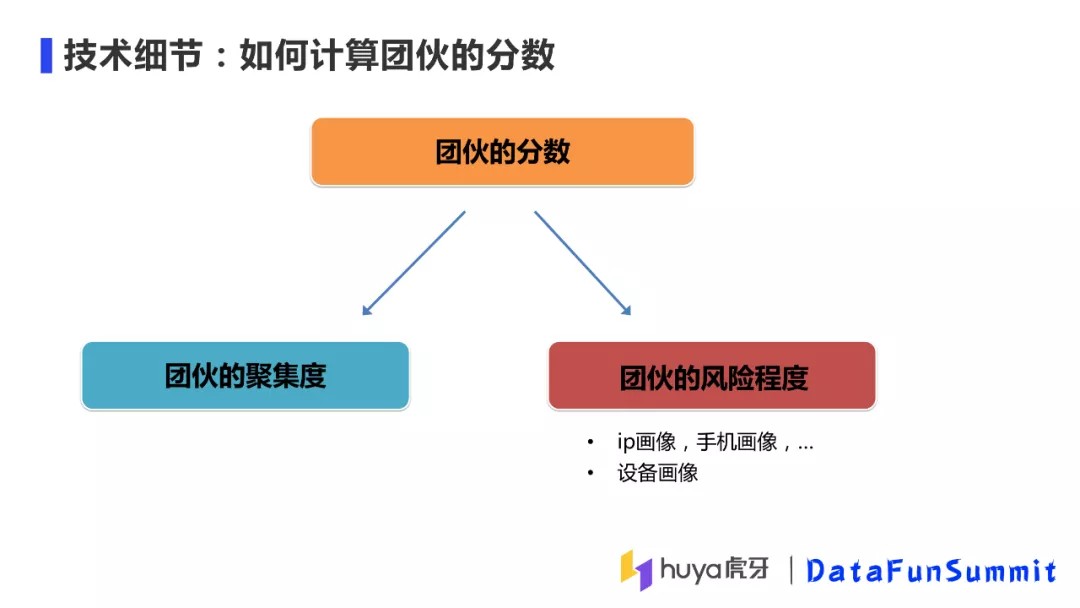
如何对算法输出的团簇进行打分呢?团伙分数由两部分组成,一个是团伙的聚集度(由团伙内成员参数的聚集度决定),一个是团伙的风险程度(团伙内成员使用IP、设备画像等决定)。
⑥ 如何自动拦截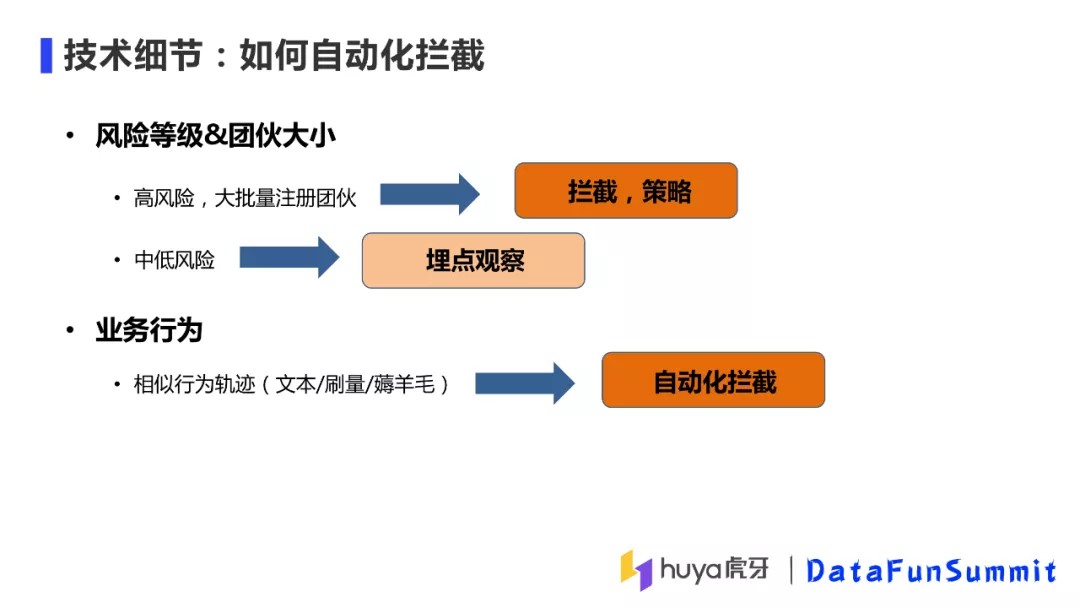
算法输出的团伙信息会应用到后续环节,主要有以下两方面应用:
根据团伙的风险等级和团伙的大小做限制。如:对高风险的、大批量的注册用户直接做拦截或在后续业务中出策略;对可疑程度相对较低的用户做埋点观察。
结合业务行为做限制。比如发现团伙都是薅平台羊毛或刷量,那么我们会进行自动化拦截。
⑦ 如何提供检测原因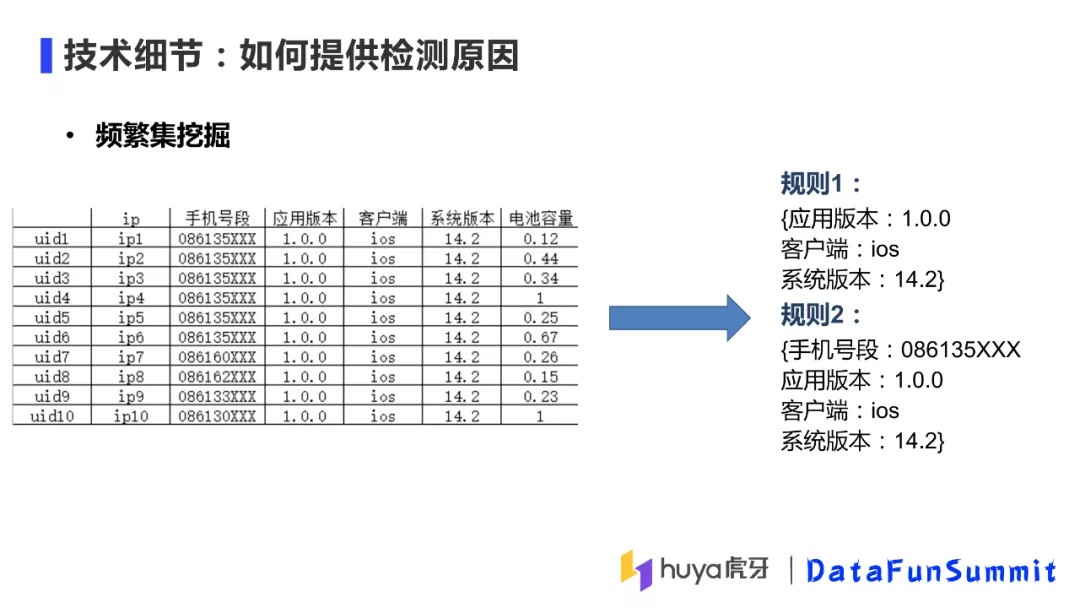
我们不仅需要算法输出可疑团伙,同时还需要输出黑产团伙的聚集原因。在可解释性方面我们使用了频繁集挖掘方法,即找到数据集中出现的频率不小于某一阈值的子项目。比如上图中,若设置频率阈值为1,则得到规则1。如果将阈值放宽到0.5,则可以得到规则2。
⑧ 算法效果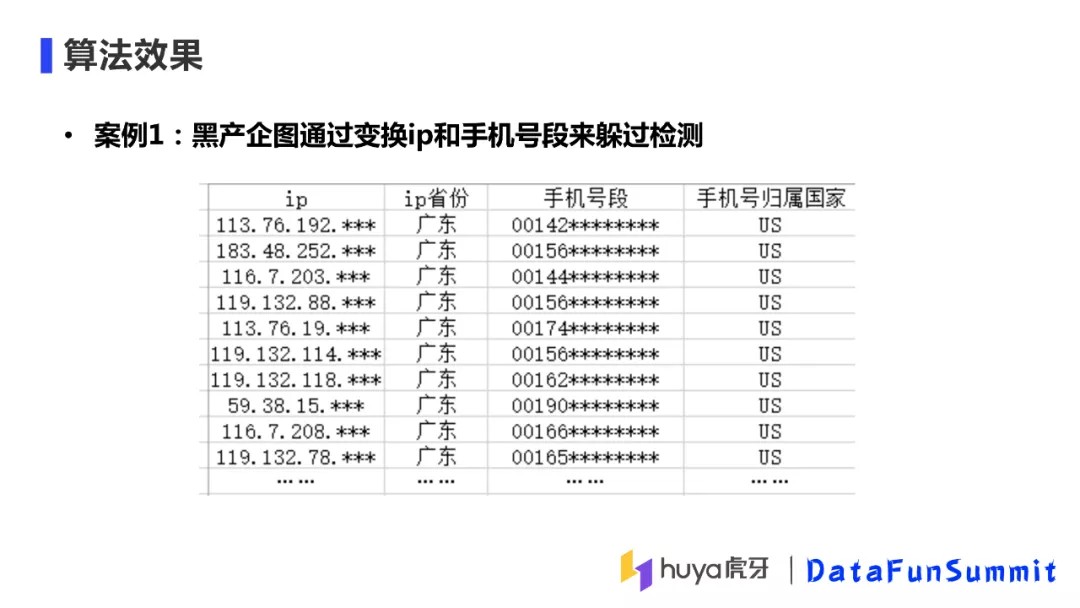
最后,与大家分享在实际操作中算法找到的两个黑产团伙。第一个案例中,团伙的IP十分分散,手机号段也不重复,所以仅从IP、手机号段的频次检测是无法找到这个的团伙的。但是我们发现虽然用户使用的IP都不一样,但是IP都属于广东,手机号都是美国手机号,所以通过综合分析我们找到了该团伙。

第二个案例中,黑产同样通过不断变化IP及手机号段来躲过检测,但是该团伙还有一个的特点是ip省份分散,手机号段也比较正常。但是通过设备维度的分析发现,这批用户的设备型号都比较新,但系统版本相对较老,而且电池电量都是1,说明手机一直处于充电状态,所以我们推测这是一个通过篡改设备来进行注册的团伙。
今天的分享就到这里,谢谢大家。
分享嘉宾:吴淑媛博士 虎牙
编辑整理:李菲 神州数码
出品平台:DataFunTalk
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册