百度数据联邦平台及其应用研究
2021.10.08 15:41浏览量:693简介:本文由百度资深研究员刘吉博士分享,主题为百度数据联邦平台及其应用研究。
分享嘉宾:刘吉博士 百度 资深研究员
编辑整理:Hoh Xil
出品平台:DataFunTalk
导读:本文由百度资深研究员刘吉博士分享,主题为百度数据联邦平台及其应用研究。主要内容包括:① 数据联邦平台的架构;② 基于数据联邦平台的应用研究;③ 联邦学习;④ 可解释性。
01 数据联邦平台的架构
1. 问题描述
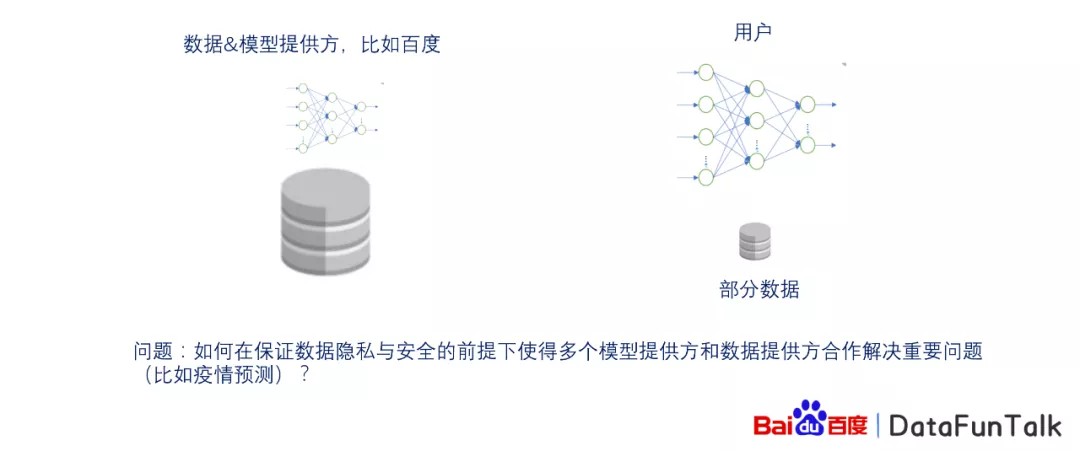
在研究百度数据联邦平台的工作中,我们发现在疫情出现时,有非常多的研究,比如在nature/science期刊上发表的文章,使用的很多数据是百度的地图数据,以及某些不公开的数据,如何使用?针对这样的问题,我们提出了百度数据联邦平台。
它解决的问题:用户想训练模型,或者搭建模型,但是用户只有部分的数据,而对于数据以及模型的提供方,可能有些数据是非常保密或者隐私的,这样的数据不能直接发送给相对应的用户,如果发送或者泄露这些隐私,会产生非常严重的后果。在这样的情况下,我们解决的问题是如何在保证数据隐私与安全的前提下,使得多个模型的提供方,或者说数据的提供方可以合作解决重要的问题,比如疫情的研究,
2. 基本技术能力框架
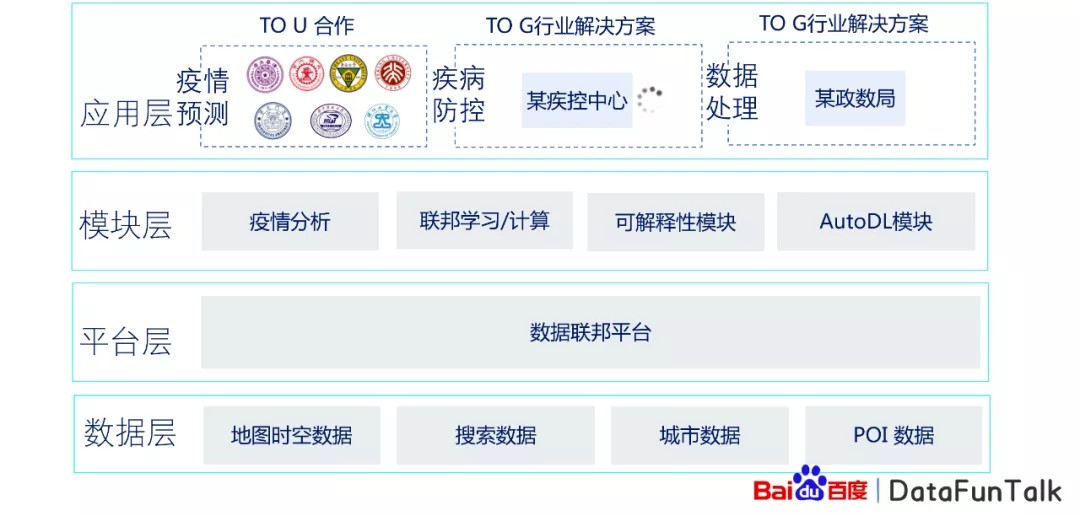
大概介绍下我们的基本技术能力框架。
数据层:在百度,我们有很多的数据,这样的数据集中在数据层,包括:地图时空数据、搜索数据、城市数据、POI数据。
平台层:基于数据层之上,我们建立了数据联邦平台,可以基于数据层提供非常好的算力支持和数据处理来支持上层的模块层。
模块层:在平台层之上有模块层,分为不同的模块,包括:疫情分析、联邦学习/计算、可解释性模块、AutoDL模块等。
应用层:最后基于模块层可以支持很多的应用,比如跟高校、研究机构、政府部门的合作。
接下来,为大家详细介绍下。
在数据层,我们有不同类型的数据,这里介绍四种类型的数据:
地图时空数据:举个例子,我们可以想象全国有非常多的城市,每天有很多的人从一个城市到另一个城市,那么哪一天从哪个城市到另一个城市,有多少人进行了迁徙,这样的数据是非常重要的。
搜索数据:在搜索行业中,百度是首屈一指的,积累了很多的搜索数据。比如在疫情爆发时,很多人对疫情非常感兴趣,会通过百度进行相关的搜索。
城市数据:比如城市一个区域内有多少人在这个区域内,或者在另一个区域内。
POI数据:比如在一个城市的区域内,这块区域是什么样的建筑,是学校的建筑还是医院的建筑,还是车站的建筑,这些相对应的特征对最后的模型有非常大的影响。
基于这些数据,我们建立了数据联邦平台,可以提供相对应的算力支持和数据处理,来支持其上的模块层。
在模块层我们有四个模块:
疫情分析:在疫情最开始时,很多研究机构希望借助于百度的大数据的优势,进行疫情分析。在这样的情况下,如果他们拿不到数据,进行相关的研究,是非常困难的。因此,我们提供了相对应的支持。
联邦学习/计算:是最近非常火的话题,联邦学习相对应的定义是当数据分布在不同的地方时,大家怎么使用分布在不同的地方的数据进行联合计算,使得最后的结果或者模型比只用某一方的数据得到的结果更加精确、准确。
可解释性模块:有了这些模型之后,我们发现非常难理解某些模型的行为。而对于一些比较重要的行业或者领域,比如说医疗健康和金融领域,对于某些模型或者软件是需要它的可解释性,或者说了解它内部的工作原理。在这样的情况下,可解释性就比较重要了。所以,我们的可解释性模块就是在解决相对应的问题。
AutoDL模块:对于有些模型来说,它的结构或者参数是非常多的,在调参的过程是非常耗时而且枯燥的,那么我们可以交给计算机自动的去调整。
基于这样的模块层,我们提供了不同的解决方案。对于高校或者研究机构,我们提供了疫情的预测以及相关的其他的研究方向。对于政府部门,我们可以提供疫情的防控方案以及数据的处理方案。
3. 数据联邦平台架构
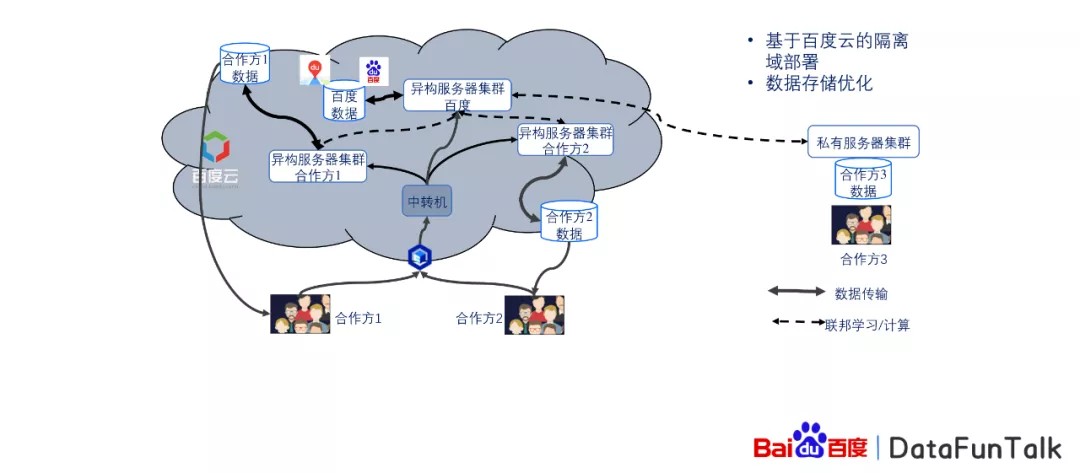
数据联邦平台是基于百度云端的一个搭建,这里可以分为两个两类的合作用户:
一类是用户有自己的相对应的私有的服务器集群
一类是用户没有这样的服务器集群,或者说用户需要用它的数据也可以进行计算。
对于这样的用户来说,用户可以把自己的数据放在百度的云端,然后经过一个百度的公开的接口接入百度数据联邦,在数邦平台上我们会动态地产生易构的服务器集群,而相对应的,百度的集群也会动态的产生,然后相对应的数据也会做成对应的处理,进行联合建模,最后结果经过审查之后会发送给合作方或者合作方可以直接进行下载。这样的机制可以保证在合作方不看到数据的情况下,可以对数据进行处理。
而对于有私有服务器集群的用户来说,比如说像金融,或者说有一些医院,它的数据是非常重要的,对于这样的能保护用户隐私的数据来说,很有可能不愿意把这样的数据放在云端。对于这样的合作单位来说,我们可以把它的服务器与百度的服务器进行保密的打通,只有双方可以进行通信,而其他人是没有办法接入的,这样可以保证在安全的情况下,进行联合建模。
4. 通过数据联邦平台进行合作研究
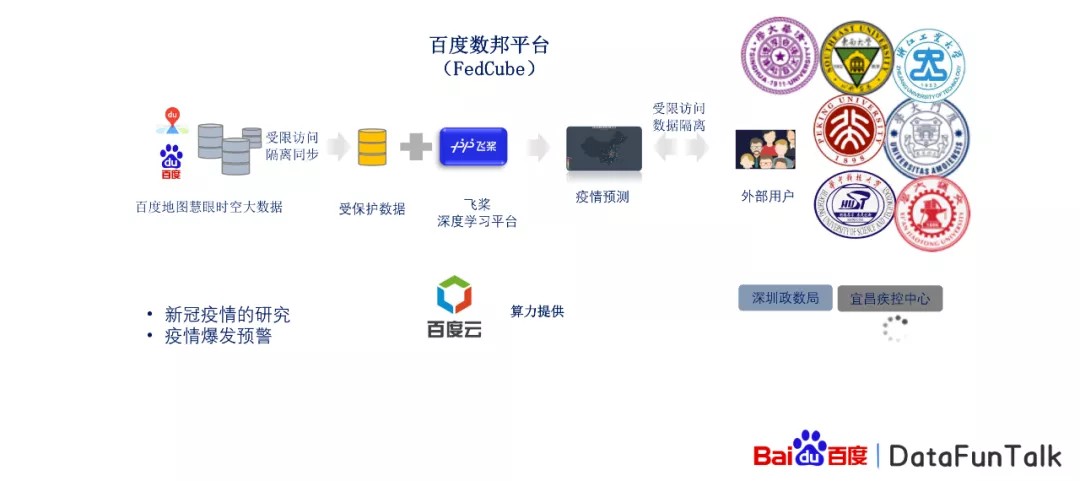
我们通过百度数据联邦平台进行了合作研究,以疫情预测为例:首先我们使用的是百度地图的慧眼时空大数据,这样的数据为什么重要?因为在疫情的研究过程中,发现这个人或者说旅行者,他进行的迁徙对疫情的传播是非常重要的一个特征。
第二就是百度的搜索数据,大家都会使用百度进行搜索,那么这样的搜索数据肯定不愿意让其他人知道你搜过了什么。而且大家在使用地图时,也不愿意把自己的行踪让其他人知道,对于这样的数据会进行保护,而且我们会抽取相对应的统计数据,也就是说我们并不关心个体的数据,而是对一个群体的数据进行研究,这样的话会保证原始数据的安全隐私。对于这样的数据,我们会加密进行存储,在百度云端直接进行存储,同时我们会搭建深度学习平台,并为合作的用户提供支持,然后我们的合作用户就可以基于这样的平台进行疫情研究,或者疫情爆发的预警。
5. 数据安全共享
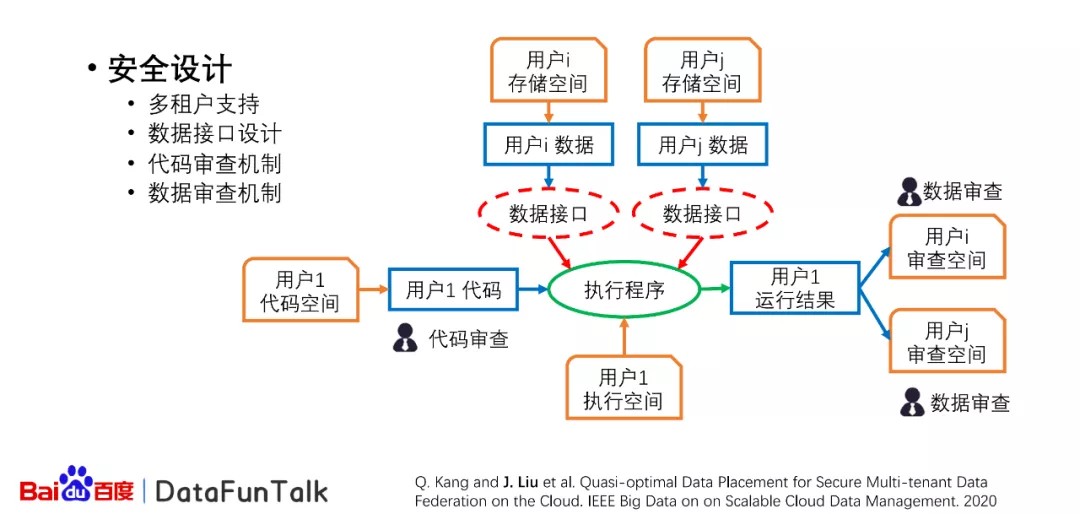
接下来,介绍下在百度数据联邦平台上进行的安全的数据共享。在这个图中表示了这样的一个执行的流程。首先,假设有一个用户1,需要使用到其他用户的数据资源,比如平台有用户i和用户j,这两个用户是相对应的,有自己的数据和相应的数据接口,这样的数据接口可以保证数据不会直接无限制的被其他用户所使用,而且在用户使用其他的用户数据之前,也需要对方通过。对于用户1产生的代码进行执行的过程当中,可以在云端直接进行执行,最后产生的结果需要经过原始数据的拥有方进行审查,审查之后发现在最后的结果当中,并没有透露原始数据隐私安全的一些问题的话,这样的数据可以直接发送给用户,那么这样的数据可以支持多用户的设计,也就是说同时可以有多个用户进行执行程序,或者提交他的任务。
第二个是我们提出了数据的接口设计,这样的话可以保证它的数据是在受控制的进行输出,而且我们提出了代码以及数据的审查机制来保护安全隐私。
6. 动态数据存储调度
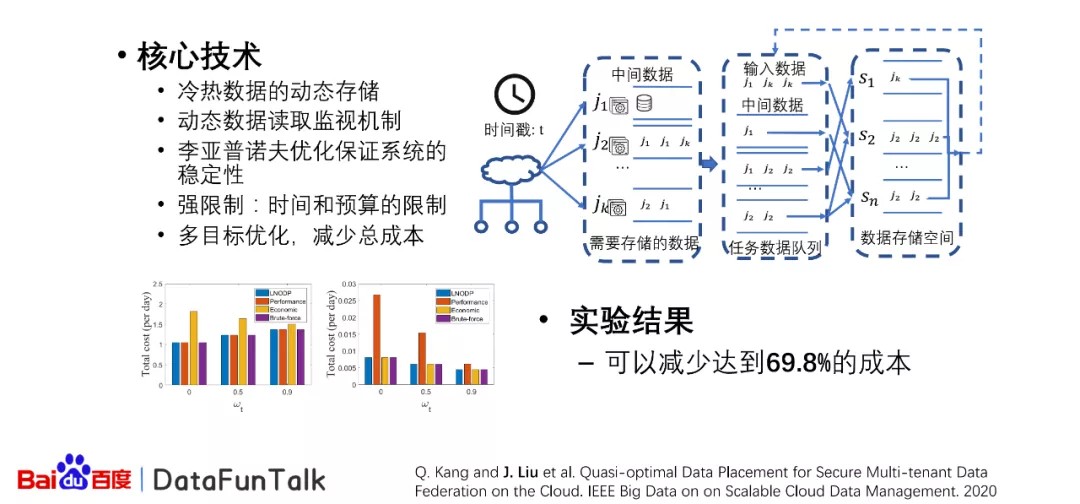
在存储的过程当中,当数据量非常大的时候,这样的数据在云端存储是非常消耗资源或者成本的。那么对针对于这样的经济情况,我们提出了动态的数据存储调度。我们都知道在程序运行的过程当中,或者说在数据存储在云端的时候,有些数据它的读写频率是非常大的,非常高的,但是有些数据它的读写频率并不是非常高,那么对于这样的情况我们可以动态地监视这样的数据的读写频率,从而可以知道哪些数据使用读写频率比较高,哪些数据读写频率不是那么高。相应的在云端有不同的存储方式,有些存储方式它的成本特别高,但是它的性能特别好,也就是说读取的时候延时特别短,但是有些存储的方式它的费用比较低,而它的存储性能不是特别高。在这样的情况下,我们需要解决的问题就是对于哪些数据需要放在什么样的存储方式中,我们对于这样的问题,结合不同的方法进行优化。首先,我们最开始使用李亚普诺夫的优化来保证系统的稳定性,在这样的优化的前提下,我们需要对所有的数据增加一个可以使用的时间,这样可以保证不会有特别多的数据积累在这个系统中,而使这个系统没有办法保持使用。
第二,我们对于强限制,也就是说有些任务它是有非常强的时间的一些限制或者预算的限制。那么在这样的情况下,我们提出了多目标的优化,从而减少总共的成本。我们提出的这样的方法,最后可以通过实验果可以达到高达69.8%的成本的节约。
02 基于数据联邦平台的应用研究
1. 基于数邦平台的疫情研究
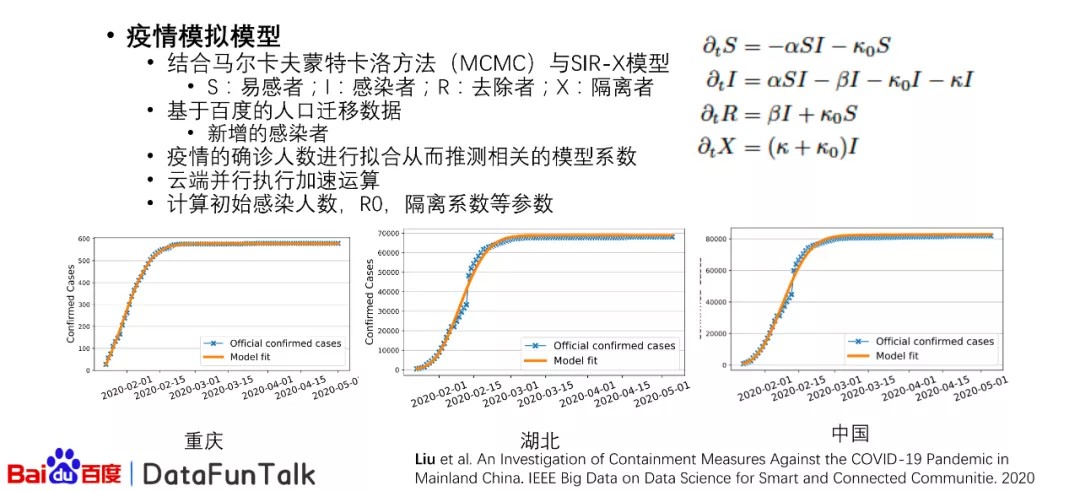
基于联邦平台提供的数据,以及执行的能力,我们进行了相应的疫情的研究。首先,我们使用了一个比较传统的模型,也就是SIR-X模型。这个模型是去年发表在science上的一篇文章的模型。但是这个模型我们需要推测它一些长处。我们结合了马尔卡夫蒙特卡洛的方法。在这里S代表易感者,I代表感染者,R代表去除者,X代表隔离者。这样的模型,可以模拟在动态系统当中是如何从最开始的,少数的感染者慢慢演化成比较多的感染者,然后我们在这个过程当中结合了百度的人口的迁移的数据,比如说从哪个城市到另一个城市的数据,以及新增的感染者人数的数据。
基于这样的数据,我们可以对确诊人数进行拟合,从而推测出相关的模型系数。但是在运行马尔卡夫蒙特卡洛方法的过程当中,我们发现这个过程非常耗时,那么对于这样的问题,我们在云端进行了并行的加速,也就是说,对于一些城市,我们今天使用部分的计算资源,对于另一些城市使用其他的计算资源,从而进行加分加速运算。基于这样的设计,我们可以计算出最初始的感染人数以及R0隔离系数等参数。R0就是相对一个传一个患病的人,可以平均传染给多少人。在上图当中,我们可以从城市、省份、国家三个层面来看我们的模拟结果。从这些结果来看,我们可以发现重庆、湖北以及全国进行模拟的结果还是非常准确的。当然这只是一个例子,其他的城市也要有相应的结果。
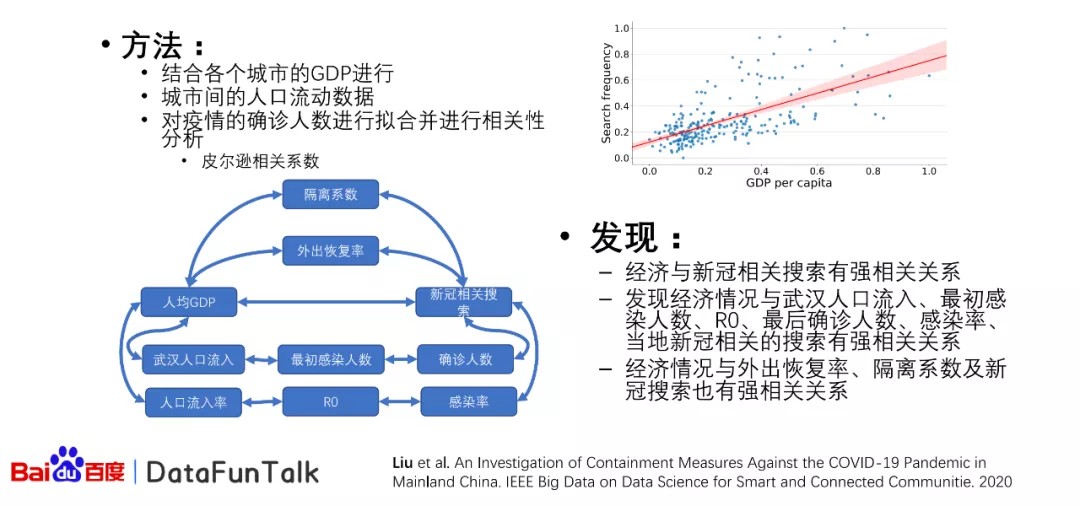
结合各个城市初始的参数,我们可以得到相对应的相关性的分析。我们结合各个城市当地的GDP进行相对应的相关性分析的研究,基于皮尔逊相关系数,我们可以得到对应的左下角的图片。右上角图片是指当人均的GDP比较高的情况下,它的搜索概率是比较高的。
搜索频次主要是指新冠相关的搜索,我们有一个关键词的列表,包括口罩、新冠疫情、核酸检测等的一些跟新冠相关的关键词,我们以这个来当搜索频次,然后左下角我们可以发现,当人均GDP比较高的情况下,发现它跟武汉的人口流入,或者说人口的流率是成非常高的正相关性关系的。在这样的情况下,我们又发现人在19年12月到2020年2月或者三月时,武汉人口流入跟该城市最初的感染人数也是呈比较高的正相关关系以及最后的确诊人数。在这样的情况下,该城市新冠的相关搜索量比较高。经过搜索以后,居民知道新冠是比较严重的,为了避免外出时被感染的情况,那么外出的恢复率就比较低,而且这些人群会自发地进行隔离。这样的情况相对应的,我们也发现了新冠相关的搜索以及外出恢复率隔离系数有非常高的正相关公共关系,这样我们就可以得到一个闭环的一个不同的关系之不同的因素之间的关系认同。
① 第一款基于飞桨的疫情预测深度学习模型

接下来我们针对疫情研究还进行了相对应的研究,我们和厦门大学合作提出了基于飞桨图模型的时空卷积网络,我们基于百度的城市之间的人口数据和官方的公布的各大75个主要城市的是确诊人数进行了预测,基于之前20天内的人口迁移数据,然后预测未来的一天或者几天的新增感染数据,最后得到的结果,是比较准确的。
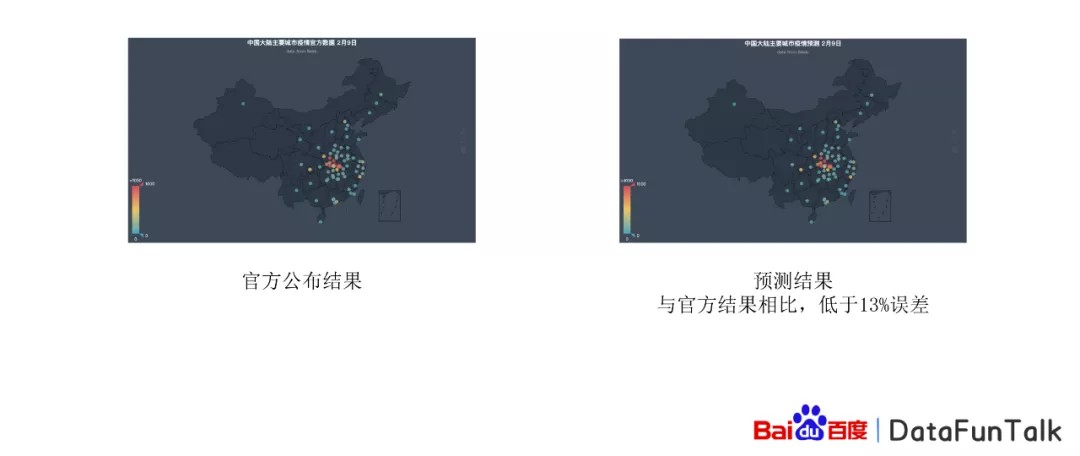
左图是官方公布的结果,大家可以看到相对应的不同的城市,在2月9号的时候,确诊人数是跟预测的结果相对比来说,还是非常接近的。这样的结果和官方结果相对比来说,低于13%的误差。
② 疫情早期的研究

第三个研究是疫情跟早期的群体免疫的研究。这个研究主要的背景是当时有一篇文章大家讨论比较多,是哈佛的研究人员发表文章,认为中国的疫情从2009年8月开始,然后使用了卫星的图片以及百度腹泻的症状的搜索指数,一般大家用腹泻的搜索量,但是它使用的是腹泻的症状,跟腹泻结果是不太一样的。
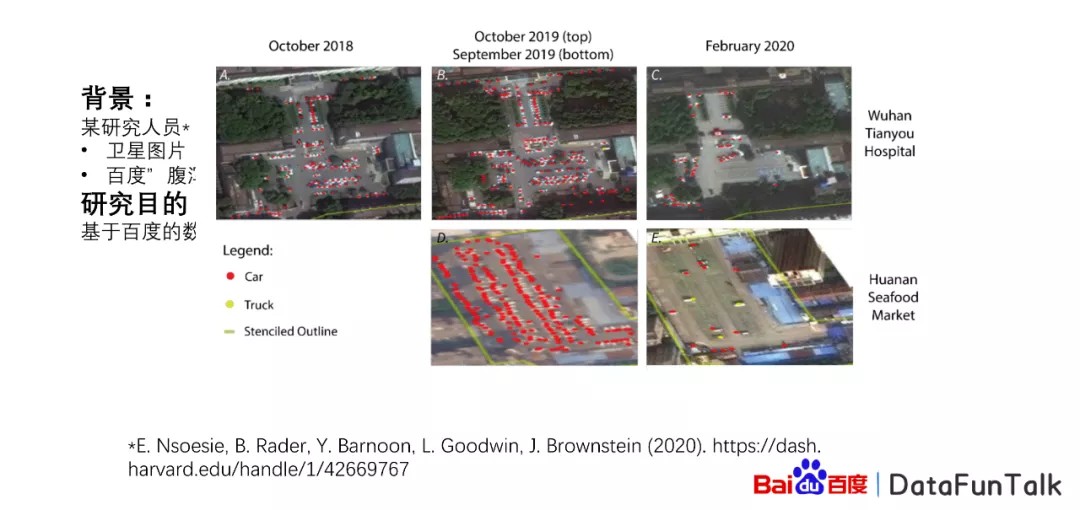
大家可以看到这个是卫星图像,当中有武汉的天佑医院和武汉的海鲜市场,有很多的停车场,有很多的车辆在上面,他认为在2019年9月或者10月的时候,人数就比较多。
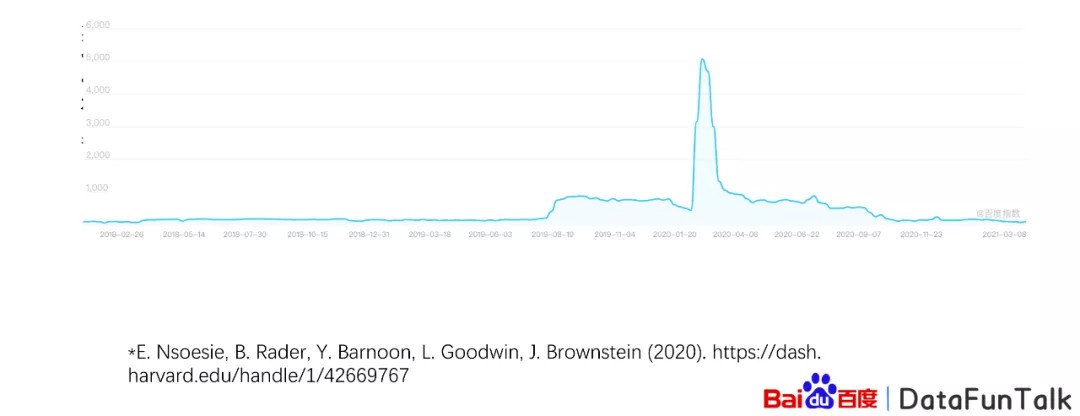
而且在相对应2019年9月的时候,搜索量也比较高。然后我们的研究目的主要是基于百度的数据,研究疫情群体反应开始的时间。
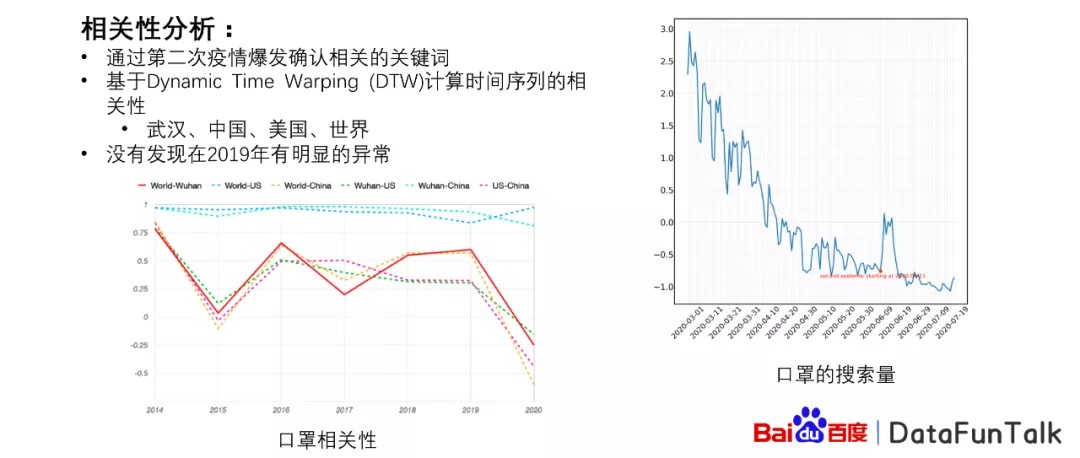
我们使用方法是通过第二次疫情爆发,然后确认相关的关键词,比如说口罩的搜索量,我们可以从右图看到口罩的搜索量,在这个点的时候,它相对应的搜索量突然增高,这个点刚好就是北京第二次疫情爆发的时间点。
然后对于这样的关键词,我们进行了DTW的计算,从而计算相关性。我们对四个区域进行了计算,其中包括武汉,中国,美国以及世界范围。在计算的过程当中,我们发现计算武汉或者中国或者美国以及世界几个区域之间,在2019年的时候并没有特别大的变化,但是在2020年的时候它的变化非常大,可以发现在2020年的时候,其实是大家比较公认的一个群体反应比较明显的时间点。
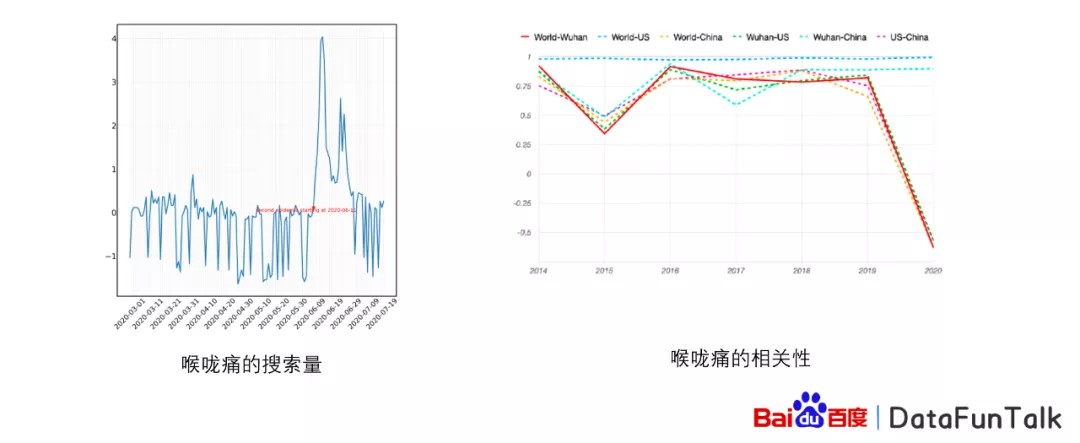
同样的,我们发现喉咙痛也有相对应的结果。喉咙痛是也是一个非常相关的关键词,它在北京第二次爆发的时候,搜索量急剧上升,而且在这个之前已经有比较明显的态势,但是它的相关性也是在2020年的时候出现了特别明显的变化,2019年的时候并没有出现。
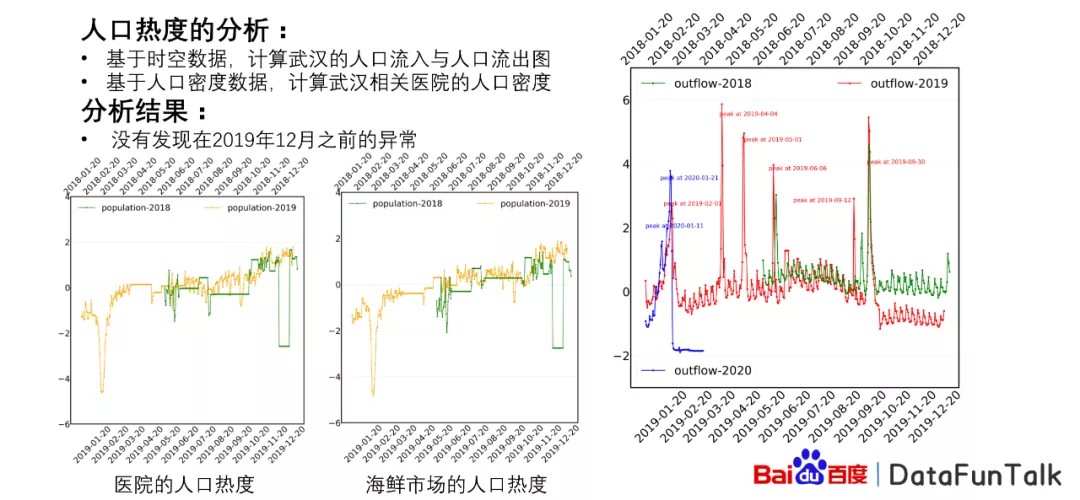
同时我们对人口的热度进行了分析,其中包括基于时空数据计算武汉的人口流入与人口流出的图。如右图所示,是人口流入的图,在封城之前,人口流入并没有特别大的变化,或者说在2019年的时候完全没有变化,绿线是2018的,红线是2019的,但是在封城或者说群体有变化的时候,其实流入量是有一定的减少的,封城之后减少特别大。
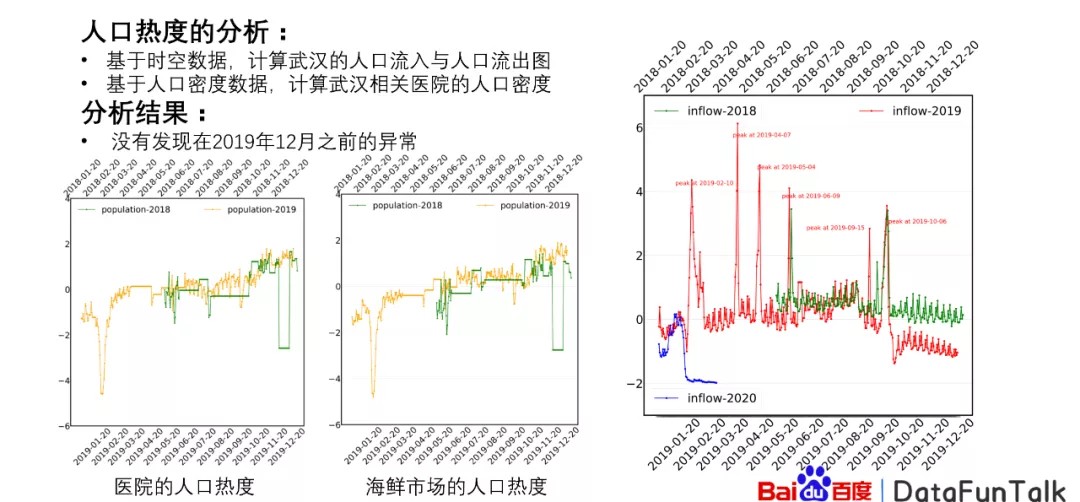
而相对应的流出量,我们可以看到在封城之前有明显的群体反应的时候,流出量是非常高的,变化的特别大,但是在2019年的时候,流出量并没有特别高,可以说明从流入流出来说并没有明显的变化,起码在2019年的时候并没有特别大的变化,但是在2020年的时候变化量特别高。
另外,我们曾经对医院的人口热度以及海鲜市场的人口和热度进行了相对应的分析。通过这个分析过程,我们得到的结果是2019年整个下半年的时候,其实它的变化不是特别明显,跟往常的2018年是非常类似的。凹形是指的我们当时处理的数据的过程当中,有一部分的数据提供缺失的问题,这个跟议题没有关系。最后我们发现的结果就是并没有发现在2019年12月之前有明显的异常反应。
③ 基于数邦平台的某疾控中心合作
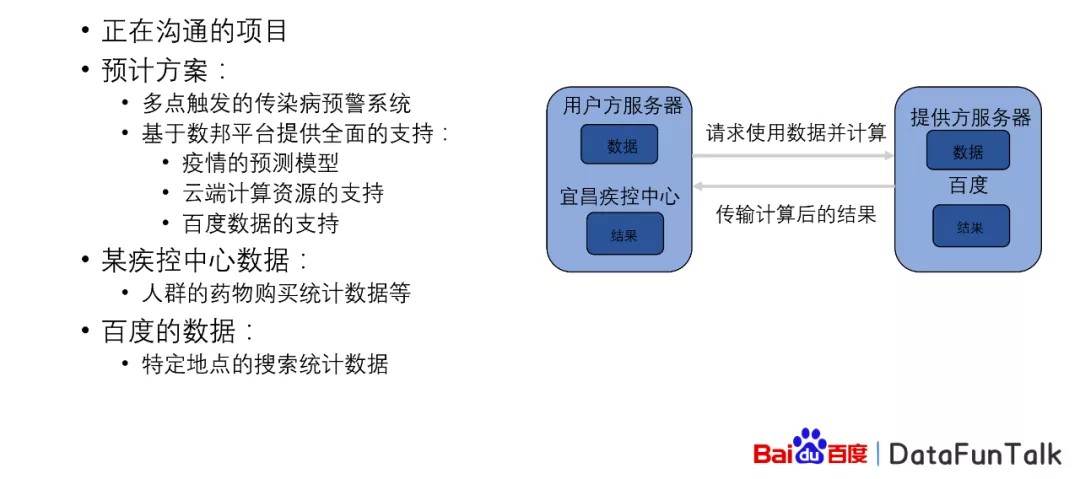
基于百度的数邦平台,我们还跟政府的一些单位进行合作,比如说某个疫情的疾控中心进行合作,这样的项目正在沟通,预计方案是这样子的,我们进行多点触发的传染病预警系统。百度数据联邦平台可以提供疫情的预测模型,云端的计算资源,以及百度的数据的支持。当然这样的数据支持只是体验,数据是不会出百度的,而数据得到的结果经过审查之后,结果可以和对方进行共享。而疾控中心可以有相对应的人群药物购买统计等等,百度的数据有特定地点的搜索统计数据等等的一些数据。
2. 基于数邦平台的共享车辆研究
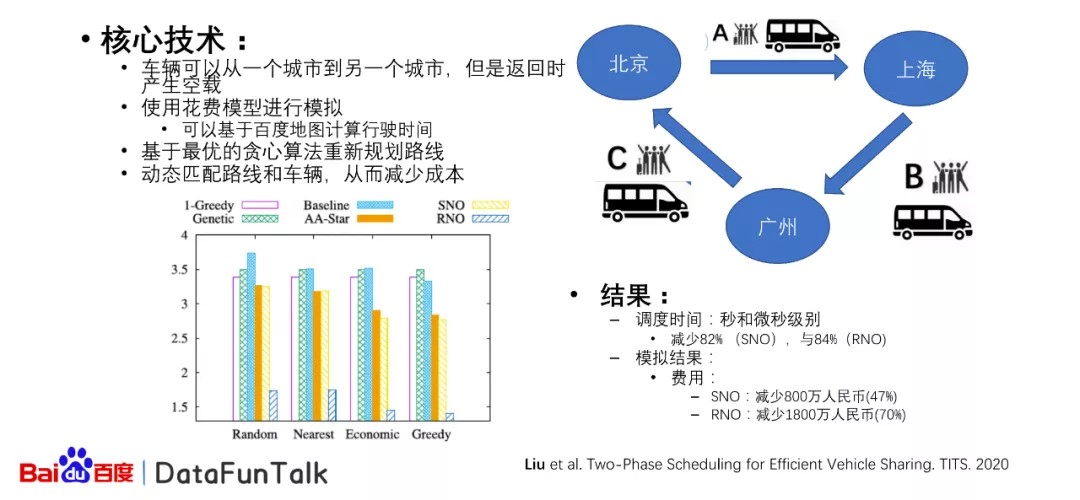
接下来介绍下基于百度数据联邦平台,我们进行了一个共享车辆的研究,为什么做这样的专业研究,是因为我发现在使用车辆的时候,当车辆从比如说北京到上海去的时候,会有比较多的人在坐,但是如果去了以后,把车辆返回到北京,那么它的使用或者说它的空载是非常高的,非常消耗成本。同时比如有些旅客从北京到上海,然后有些旅客从上海到广州,然后有旅客从广州到北京,那么这样的旅程可以形成一个环,在环的促进作用之下,车辆可以搭载不同的乘客,从而实现不同的旅程,但是在这个过程当中可以有效地避免空载的产生。那么对于这样的情况,如果这只是三个城市,如果在很多的城市都有这样的情况发生的话,哪些车辆应该分配给哪些旅客?这就是一个非常典型的全局优化问题:在有限的时间之内,当问题的规模变大的时候,很难求解,我们提出了相对应的花费模型进行模拟,可以基于百度的地图进行计算行驶的时间,然后我们提出了最优化的贪心的算法,重新动态的规划路线,动态匹配路线和车辆,从而减少成本。
最后,这样的调度方式可以减少82%的调度时间,它可以做到秒或者微秒级别,而且它的费用也可以减少47%或者70%。这两种方法是对于针对不同的情况的。SNO和RNO是分别对于某些乘客来说,它的时间是固定的,那么我们不能变化他的出行的时间,但是对于某些乘客来说,它是可以愿意改变他的出行时间,比如说把它的出发时间退后,或者到达时间提前,这样的情况可以动态地调整调度的系统,从而产生更优的结果。
03 联邦学习
1. 联邦学习类型
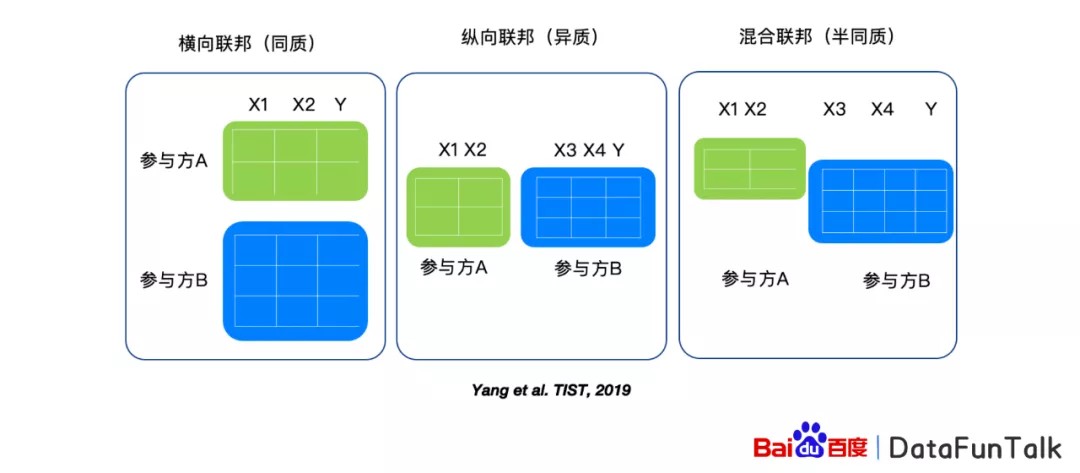
联邦学习主要解决的是当数据分布在不同的地方的时候,我们怎么样可以基于分布式的数据,联合训练一个模型。基于数据的分布的不同,我们有三类的联邦学习。第一类联邦学习是横向的联邦学习,比如参与方,或者说某公司,它有很多的数据,包括用户的数据,以及最后的标签数据,参与方B也有同样的特征的数据以及标签的数据,但是它的用户个体是不一样的。对于这样的这些数据,我们可以进行横向的联邦学习。
对于纵向的联邦学习是指的参与方A和参与方B,他们有部分的用户是同样的用户,但是这样的用户有不同的特征值放在不同的参与方内。那么这样的情况我们可以使用纵向的联邦学习方法。
最后一个是混合联邦学习的方式,这样的联邦学习方式是结合前两个联邦学习的方式。
2. 基于PaddleFL的横向联邦学习
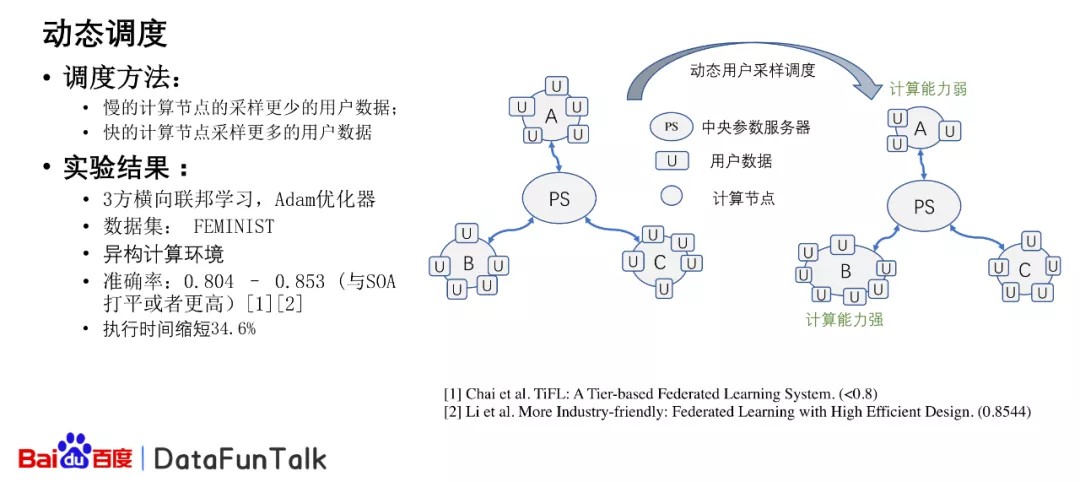
对于横向联邦学习,一般使用的是参数服务器的架构,但是之前的工作有很多情况下,我们的假设是相对应的参数服务器所连接的执行的服务器,它的计算能力是大概相同的,或者计算资源,它的计算能力是大概相同的,那么在那样的情况下,很多算法是比较有效的。但是当部分的计算资源它的计算能力比较强,但是有些计算资源它的计算能力较弱的情况下,就会出现比较严重的负载均衡问题。
针对这样的问题,我们提出了可以动态地调整用户的采样方式来实现动态的负载均衡的调整。比如说在计算能力强的计算资源,我们可以采用更多的结果或者数据,对于计算能力弱的可以采用更少的这样的情况,我们进行了研究,最后的实验结果可以发现执行的时间缩短了很多,但是它的准确率并没有改变。
3. 纵向联邦学习
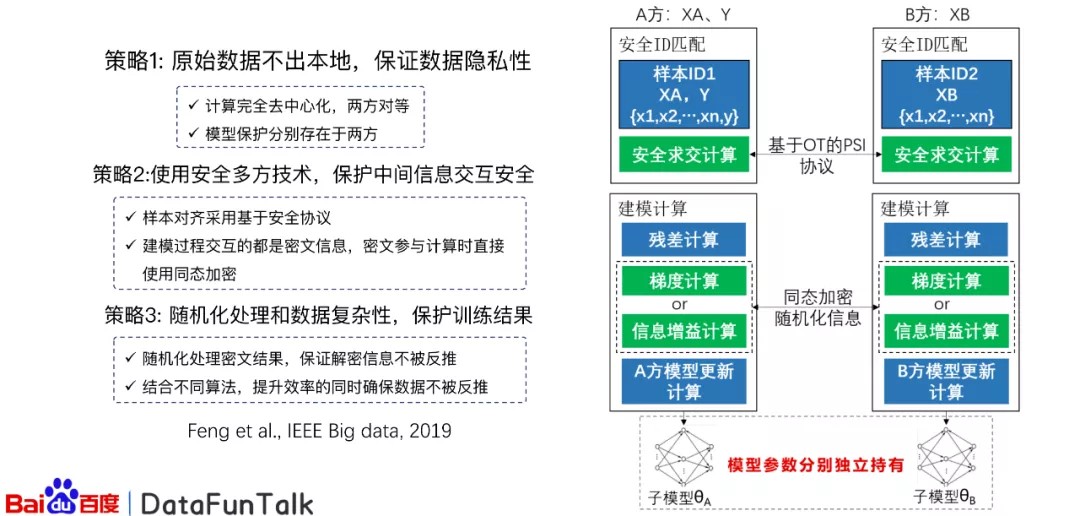
对于纵向的联邦学习来说,我们提出了Secure-GBM的方法,这样的方法如右图所示。最开始我们可以基于OT进行隐私的PSI求教,这样的话可以保证相对应的用户进行对齐,然后对于求交的之后的数据,我们进行残差的计算或者梯度的计算,对于残差或者中间的数据,进行传输的时候,我们会使用同态加密的方法,而且随机化信息,从而保证数据的隐私安全。之后我们会进行模型更新,在多次迭代之后,我们就会得到相对应的结果。而整个这样的方法,它是完全的去中心化的,也就是说参与方都是平等的,没有一个参与方可以支配另一个参与方,这样可以保证同等的地位。
另外,最后得到的模型会分配在AB双方,当我们使用的时候,必须使用AB双方的模型进行稳定预测,这样可以有效地保证模型的安全隐私。
04 可解释性
1. 可解释性:解释模型
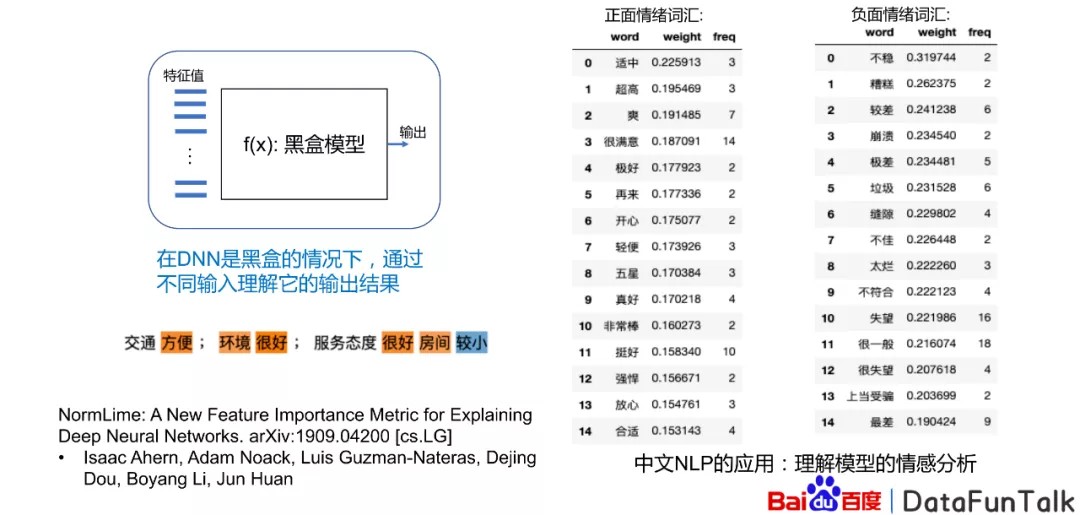
而对于可解释性能来说,我们发现对于深度神经网络,它是一个黑盒模型,我们很难知道它的行为是什么,那么我们就需要知道对应的特征值以及输出之间的相关的关系。一个例子是中文的NLP的应用里边,我们可以发现某些词它跟它是有正面的情绪的词,有些词它是负面情绪的词,比如说交通方便就是正向的,而像房间因比较小是负面情绪的词,这样的情绪可以解释。对于模型来说,可以通过这样的方法判断出相对应的一些对文字的处理。
2. 应用案例:结构化数据可解释性
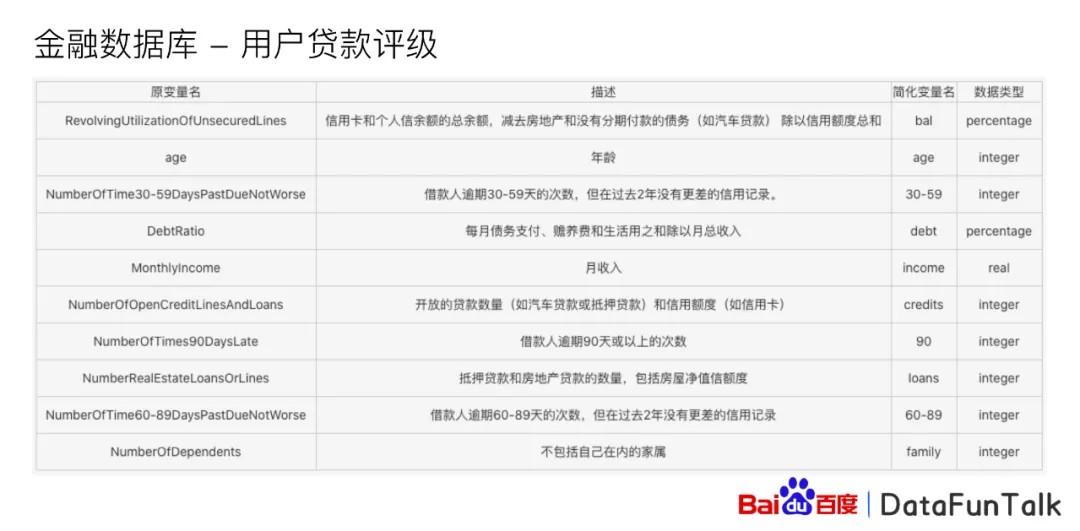
接下来我介绍一个在金融领域相对应的案例,比如说对于用户贷款,我们有比较多的特征来进行预测,比如说像信用卡和个人的信用余度、年龄,然后月收入,借款人的逾期90天以上的次数等等的这些特性,但是当我们基于这样的特征进行模型建立的时候,我们发现我们很难确定哪些特征是非常有用的。
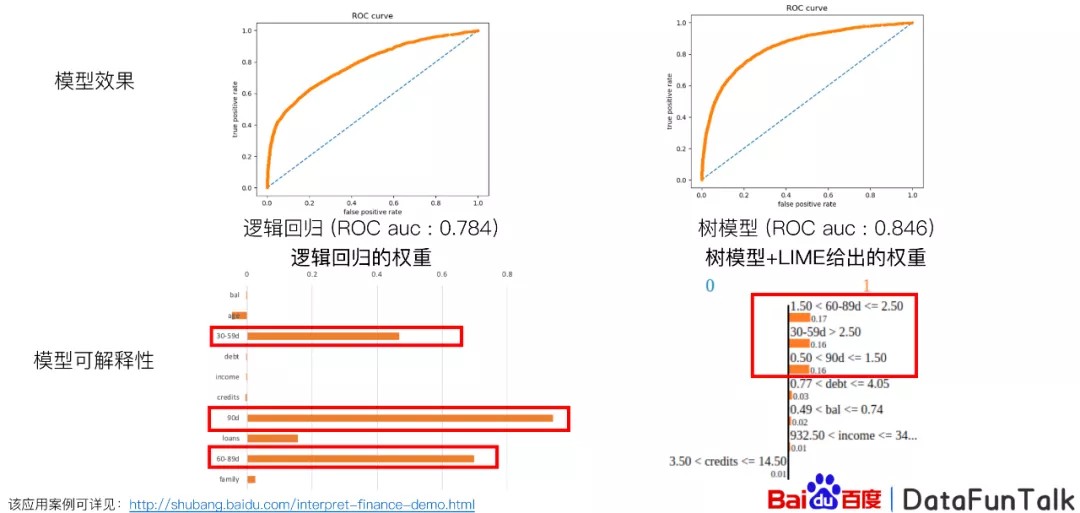
我们可以看这张图,我们基于像逻辑回归这样的比较线性的模型,它的效果不是特别好,但是它有比较好的解释性,也就是说哪些权重我们可以真的比较重,或者正向的我们就可以使用,我们就知道这些特征是非常重要的。我们可以使用树模型,它的效果比较好,比逻辑回归好很多,但是对于树模型来说,我们就不知道它的特征跟最后的结果相对应的关系。
我们提出了树模型+LIME,给出相对应的权重,比如说对于某些特征来说,我们可以给它正向的权重,然后我们就知道哪些权重,哪些特征对最后的结果产生了比较大的影响。
总结:
本文首先介绍了百度数据联邦平台架构,其次介绍了基于百度数据联邦平台在疫情和共享汽车上的应用研究,最后介绍了联邦学习及可解释性。
今天的分享就到这里,谢谢大家。

发表评论
登录后可评论,请前往 登录 或 注册