文字识别技术在内容安全中的应用
作者:雨润静荷2021.10.12 11:32浏览量:943简介:本文的主题为文字识别技术在内容安全场景应用实践。
分享嘉宾:王语斌 同盾科技 算法专家
编辑整理:王毅 斗鱼
出品平台:DataFunTalk
导读:文字在日常生活中发挥着重要的作用,甚至在考古发现中文字也作为识别文明的重要标志。特别是在当前短视频和内容爆炸的时代,文字广泛应用于人们观点的表达和传播以及商品营销等各个领域。这些内容中肯定会存在一些不良的行为。而内容安全是基于AI技术,从中识别出不良的信息,净化网络环境。
本文的主题为文字识别技术在内容安全场景应用实践,主要内容包括:① 内容风险举例;② 防控基本流程;③ 主流算法;④ 部署优化。
01 内容风险举例
常见的图片文字内容违规风险举例:

图片中的文字违规风险主要分为:涉黄、涉暴、涉政、低俗、广告等几个大类。
涉黄主要是一些小卡片、小电影、常见聊天场景中的违规内容以及打印违规图片等一些场景。涉暴场景主要涉及到一些集会、游行、武装力量等场景的文字描述或者是一些武器的贩卖信息。涉政场景主要涉及一些反动、分裂、搞独立或者是一些不友好媒体的出版物,同时也会存在一些辱骂、抹黑、调侃领导人或者革命英烈的现象。低俗场景主要是赌毒相关,比如赌场、棋牌这样的一些场景,包括一些违法商品的售卖、导流的现象。
上述场景中的涉黄、涉暴、涉证、低俗等涉及到违反国家法律法规或者违反社会公序良俗。
广告场景主要涉及平台内容生态治理,虽然不会违反社会法律法规,但是在内容生态治理上发挥着重要的作用。例如微信号、QQ号、手机号以及它们常见的变体、拼音首字母缩写、变异的同音字等。还有短视频、图片内容中存在的水印信息,这些水印存在着导流情况,特别是在竞争激烈的平台生态中,不希望平台中出现竞争对手的导流信息;
广告法中规定的限制词,比如第一,百分之百等这一类的词,也会存在违反广告法的现象。
02 防控基本流程
1. 针对图片文字违规风险的基本防控流程
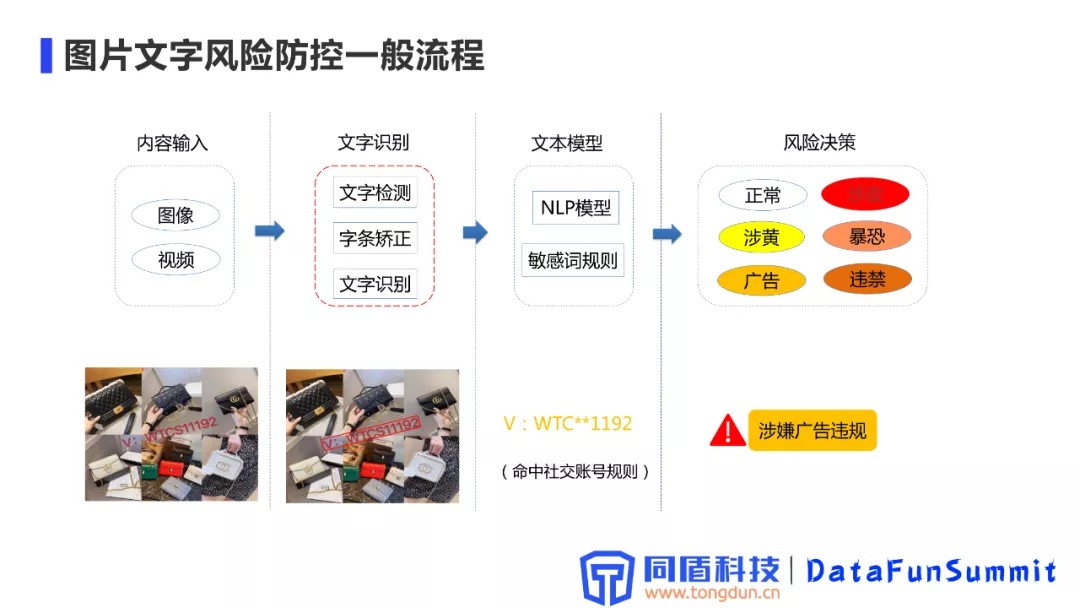
内容输入:主要以图片输入为主,针对视频输入可以通过截帧、关键帧算法等方式转化为图像,然后输入到识别系统。
文字识别:文字识别子系统包括文字检测、字条矫正、文字识别等子模块,用于提取出文字信息,这些文字信息会输入到后续的文本安全算法模型中,进行处理。
文本模型:包括常规的一些NLP算法和比较丰富的关键词规则库。关键词库实现分级、词库分类存储。
风险决策:文本模型输出的结果最终会通过综合判断的方式做出风险决策。包含正常、涉证、涉黄、暴恐、广告、违禁等分类。
2. 文字识别阶段细分流程
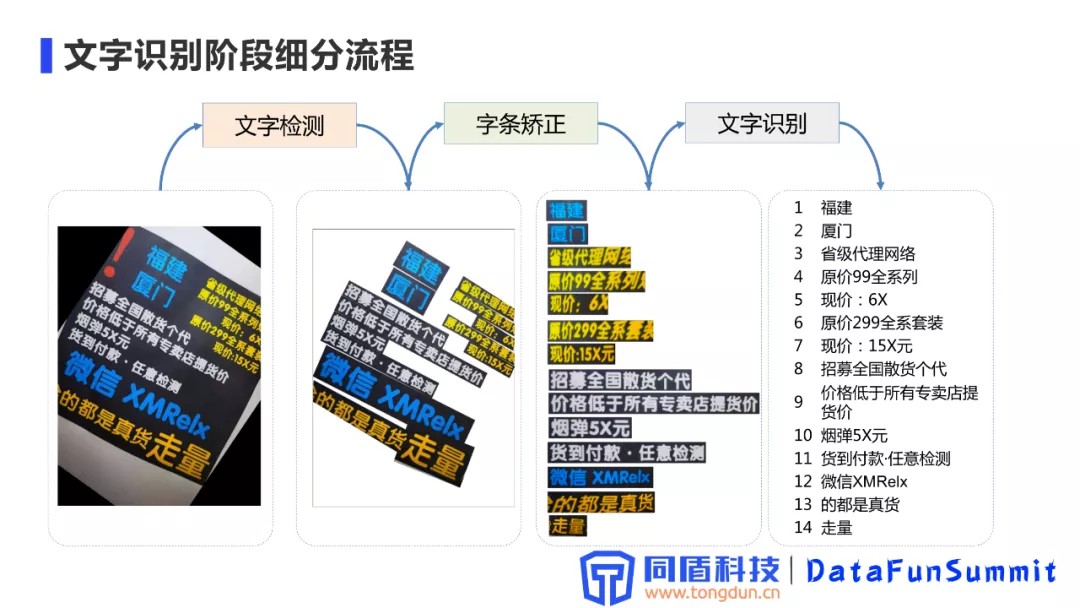
文字检测模块:输入是原始图像,通过检测环节定位出图像中文字的具体位置,产生出字条。
字体矫正模块:识别出的字条,通过字体矫正模块,方向调整,最终以水平方式展现。
文字识别模块:接收到矫正后的字条之后,通过识别,最终将图像翻译成一段具体的文本内容。
03 主流算法
文字定位、文本识别的主流算法介绍:
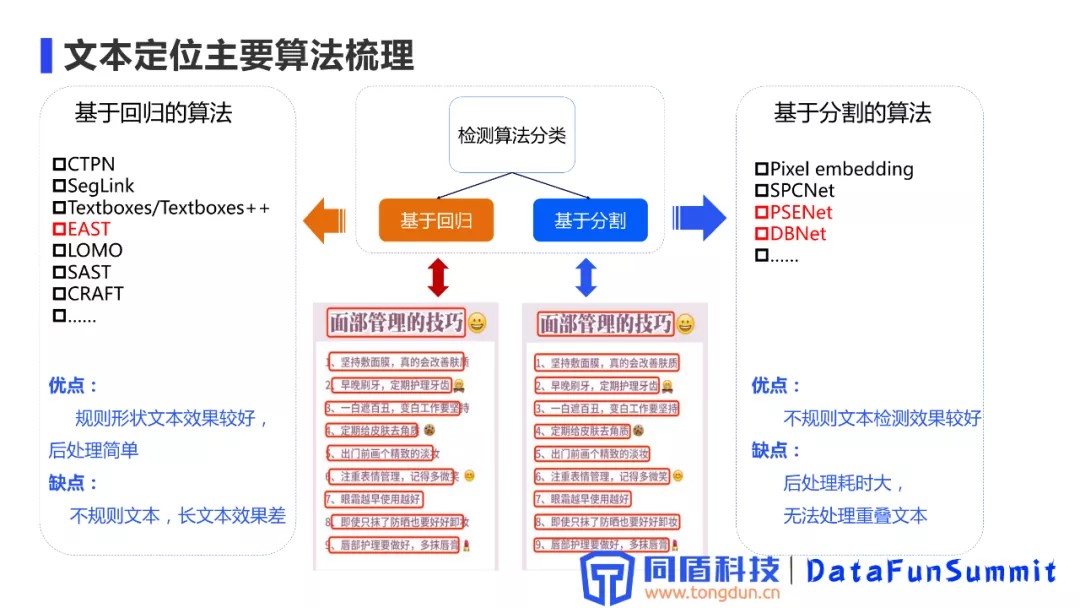
1. 文本定位主要算法梳理
目前主流的文本定位算法分为两大类:基于回归的算法和基于分割的算法。
基于回归的算法:借鉴通用目标检测的一些方案,通过网络直接回归计算出文本行的包围框信息。主要算法:CTPN、SegLink、Textboxes/Testboxes++、EAST、LOMO、SAST、CRAFT等。
优点:规则形状的文本效果较好。
缺点:不规则的文本,特别是长文本效果较差。例子:1、上图中使用回归的方案对于长文问两端的定位不是特别准确,对后续的识别会造成较大的影响。2、使用回归方案对于曲线文本、不规则的文本识别都会存在一些问题。
基于分割的方案:借鉴了通用深度学习算法中的语义分割方案,主要是将文本定位转化为一个二分类的问题,将文本中的每一个像素点都进行是否是文本的二分类预测。主要算法:Pixel embedding、SPCNet、PSENet、DBNet等。
优点:适用于各种形状的文本,整体的检测效果较好。
缺点:后处理耗时大(由于模型输出的是概率图,通过概率图计算出每一个文本框的耗时比较长)、无法处理重叠文本。
2. 文本定位算法BDNet简介
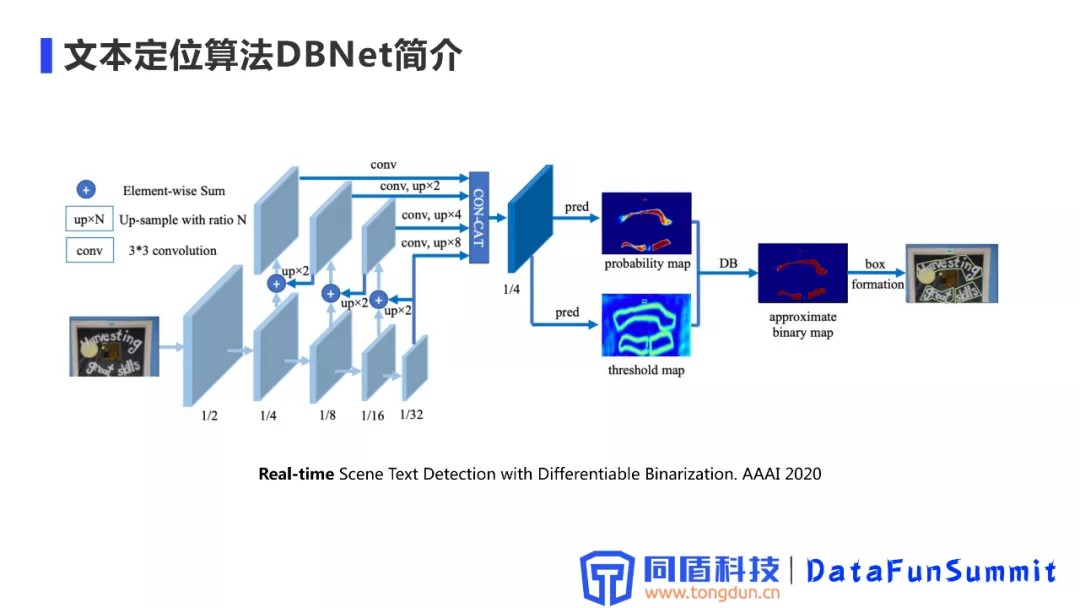
DBNet发表于AAAI 2020,核心思想是对后处理流程的速度进行优化,简化了文本检测方案的流程,在检测速度上得到了一个比较大的提升,在定位效果和速度上实现了一个比较好的权衡。
DBNet整体的结构,网络的Backbone部分是一个标准的FCN结构。从上到下逐层的一个下采样,然后进行逐层的上采样,融合不同尺度的特征,结合多尺度的特征,做一个CON-CAT,输出一个预测的概率图,这些流程和常用的分割算法大致相同。
分割得到概率图之后,之前的方式是做一个标准二值化的操作,然后得到一些联通域,再对这些连通域做一些形状的处理,得到最终的文本框,这里也会涉及到多个文本框合并的问题;DBNet创新之处在于引入了一个threshold map的分支,通过一个预测threshold实现了一个自适应阈值的二值化过程。之前标准的二值化过程为全图采样同一个二值化阈值,这样会造成对不同区域的鲁棒性不是特别好,对后续的定位精度产生影响。DBNet中引入一个可微分的二值化算子(类似于sigmod函数)进行一个二值化计算过程,同时对概率图、threshold map、近似的二值化图进行有监督的学习,最终得到一个比较好的文字边界识别效果。
论文中也进行了一些实验,发现在推理阶段可以直接去掉threshold map这条分支,直接通过一个标准的二值化操作,就可以得到一个比较好的效果。这是因为有监督的信息加入之后使得概率图中文字边界更加清晰,文字区域的概率值变高,非文字区域的概率值变低。
总结:目前DBNet是业界主流的一个方案,主要还是在性能和效果上进行整体权衡之后,识别效果比较好。
3. 文字识别基本流程
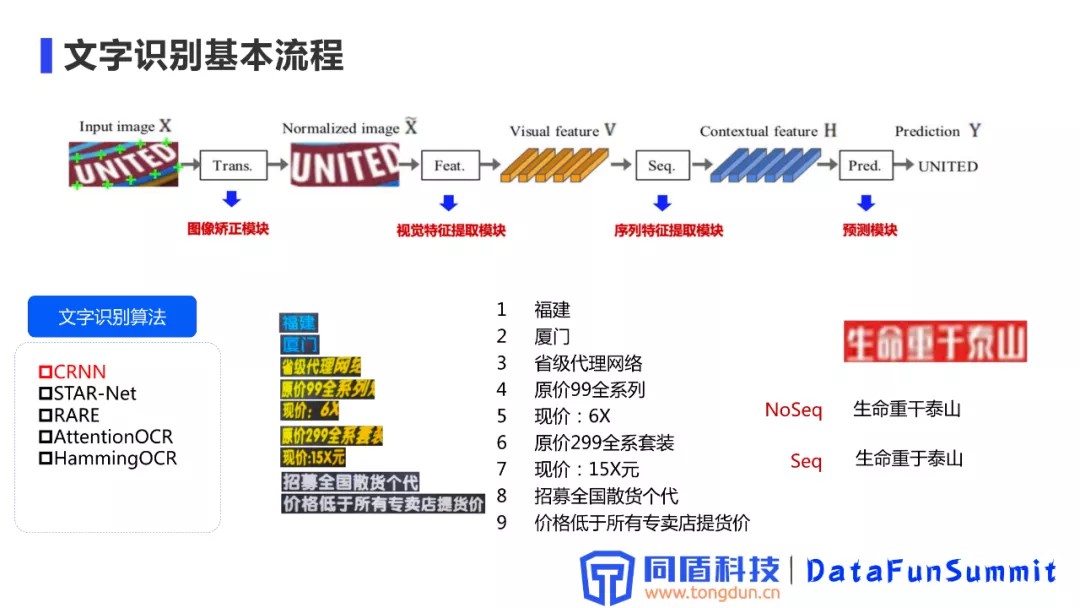
首先是图像进入图像矫正模块进行处理,输出的图像再输入到视觉特征提取模块得到一些视觉feature,后续会结合一些序列特征,最终通过预测模块输出结果。
文字识别算法目前主流的方案包括CRNN、STATR-NET、RARE、AttentionOCR等,当前比较通用的方案还是以CRNN为主,主要是通过综合性能和推理速度权衡之后,从中选出的最佳方案。文本识别算法的输入为归一化之后的文本词条,通过文本识别整个流程之后,输出就是具体的文字信息。
4. 文字识别主流算法CRNN
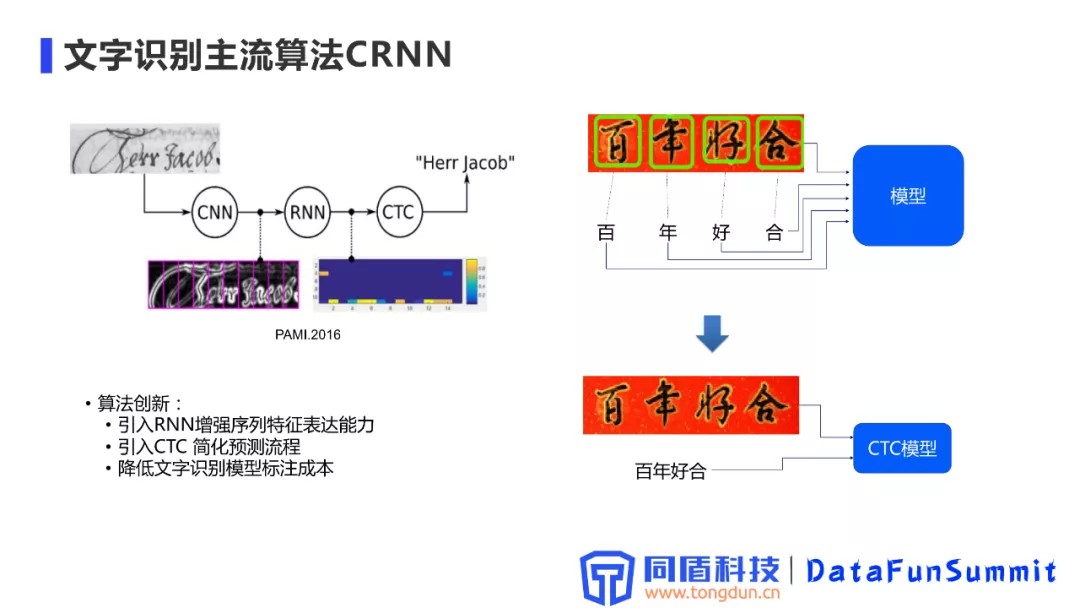
CRNN 模型是通过CNN + RNN + CTC 三个模型组合,把文本识别看成一个图像序列的预测。
CRNN模型的优点:
通过引入RNN模型增强序列特征的表达能力。
引入CTC识别模块简化预测流程。
进入CRNN时代之后,文字识别从单词的预测变为文本行的预测,实现预测流程的简化,同时文字识别模型的标注成本得到了极大的降低。
举例:在CRNN之前文字模型的识别过程,需要进行文本单个字的精确定位,每个字定位出来之后,再进行具体的单个字预测;进入CRNN之后,可以进行整个字条的输入,包括训练的监督信息也是整个字条的输入,所以它的标注效率得到了极大的提升。CRNN出现之后,整个文字识别流程也得到了非常大的促进。
04 部署优化
生产环境具体部署过程中的加速优化实践,识别效果举例。
1. 性能优化
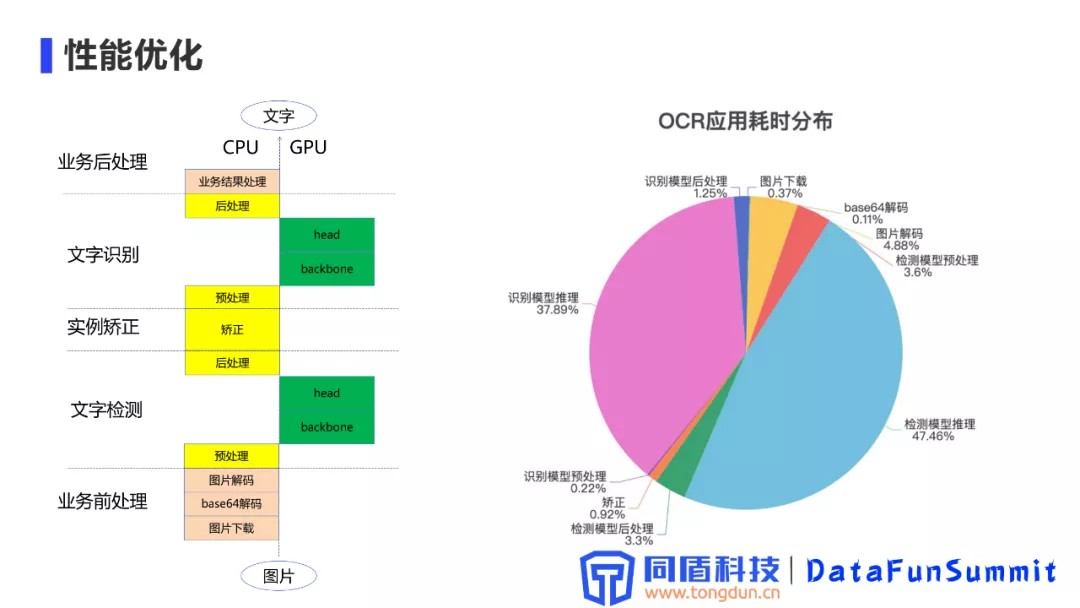
将整个文字识别流程进行模块化分,对每个模块进行耗时统计,找出耗时的性能瓶颈,明确优化的目标,对性价比较高的模块进行针对性的优化。
文字识别模型作为微服务,整体对外提供能力,整体划分为CPU计算、GPU计算。CPU计算主要包括文本预处理、后处理操作以及实例矫正模块;GPU处理主要负责模型具体推理工作。
通过在对收集的数据集上进行耗时统计分布测试,通过统计发现识别模型和检测模型的推理耗时是整个OCR的主要耗时,同时图像解码和检测模型的预处理也占用8%左右的耗时,其他环节的整体耗时比较少,因此我们把优化的重点放在耗时较高的这几个方向。
2. 性能优化方法梳理
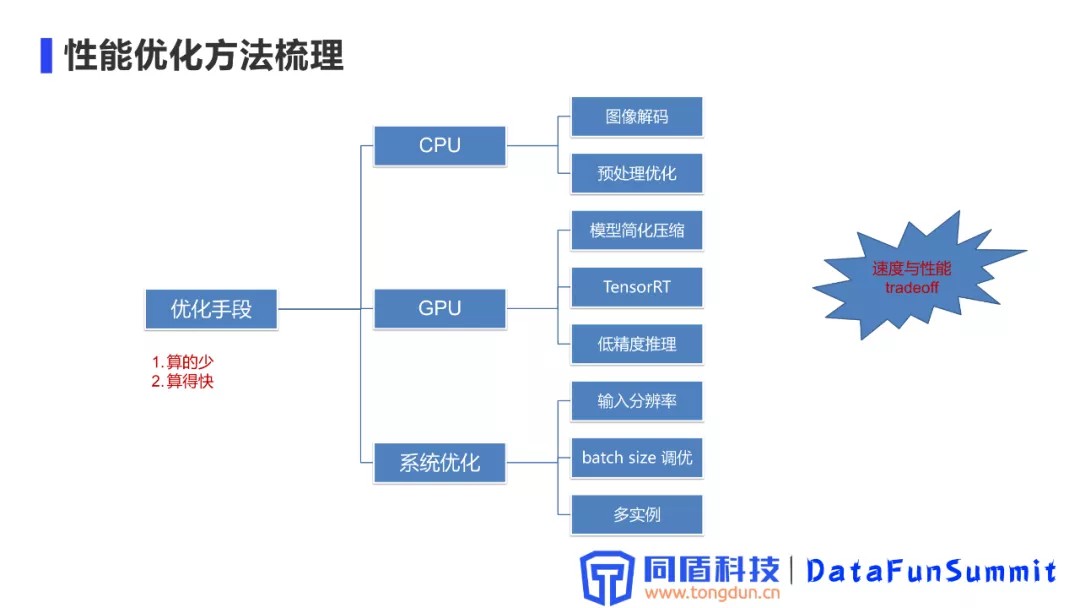
通过性能耗时整体分析,梳理了整体的优化手段,优化策略:算的少(减少计算量),算的快(同样计算量情况下,算的更快,加快计算效率)。
主要的优化手段,分为三大部分:CPU计算、GPU计算、系统优化。
CPU 图像解码,通过大量的调研和比较,发现opencv的图像解码库的特点是更加倾向于利用多线程的并行能力,对于CPU的低级指令相对较弱,同时在图像解码的过程中加入了一些额外的校验操作,导致整体的解码过程变慢;在通过调研和比较之后,选用了Pillow的一个分支,Pillow-SIMD作为我们的主要图像解码库。
CPU 预处理优化,主要是对输入图像的缩放,归一化操作进行优化。基于SIMD的图像编解码库本身也会在图片预处理,尤其是在一些大图缩放上有一些优化,另外将一些预处理的归一化过程(减均值、除方差等)合并到网络模型的第一个卷积上,类似于BN的一个合并操作,减少CPU上的一些耗时。
GPU模型简化压缩优化。我们对模型的backbone和 neck部分进行一些通道数量的压缩优化,在保证性能没有太多降低的情况下,提高优化推理的速度。
借鉴了业界比较通用的TensorRT推理引擎,TensorRT会做很多模型融合的操作,除了做一些通用的BN融合之外还会做一些更深层次的融合,如卷积,bias,relu操作等都可以合并到同一个OP中执行, 因为对于一些简单的操作,它的一个内存提取耗时与计算的耗时是相当的,所以可以把它们合并到卷积结果存储之前这样的一个过程当中,减少一次显存的访问。TensorRT会根据当前部署的硬件资源去选择最合适的OP实现方式,从而最大效率的利用显卡的硬件资源。
TensorRT提供的低精度推理方案,Fp16和Int8来一步加速模型的效果。低精度推理对原始结果也会有一定的影响,所以需要在效果和速度上进行具体的实验,进行权衡。
系统优化,模型输入分辨率的调整,这个需要结合整体的一个性能进行调整,检测阶段和识别阶段的输入都可以进行相应的分辨率调整;图片当中经常会出现多条文本行,使用多batch方案提高整张图片整体的推理效率。同时我们在优化过程中发现,GPU的整体利用率可以通过多实例的方案得到进一步的提升。
3. 识别效果举例


效果举例说明:“正品保证”这种字条是通过艺术字体实现,有一些颜色渐变的方案进行识别能力对抗,目前的识别效果还是比较好的。还有一些部分缺失、颜色很淡、虚化、颜色对比度很低、特殊的字替、上下文字部分缺失等情况,这些都会对文字的定位、识别有很大的挑战。图中对于RELX这种广告文本,也有对抗的特性存在,例如倾斜、过度的颜色、水印、对比度比较低等,整体上我们的识别效果还是不错。
上图中也有对竖排文字、繁体字支持的情况,目前对诗句和对联整体的识别效果还是不错的,图中对于龙凤呈祥中的龙识别失误,主要是因为整体的颜色和繁体字的影响。
手写体整体的识别难度还是比较大的,尤其是对于一些手写的比较夸张的字体,类似于草书、连笔比较严重的一些字体,对于这些字体的识别目前还是有一些问题;对于一些手写不是那么夸张的字体,识别效果还是比较理想。
05 问答环节
Q:横竖排的文字识别有什么区别?
A:横竖排的文字在排列上有一些差异,我们模型也会通过数据增强的方式来对模型识别能力进行补充;有几种情况,一种是文字旋转型的竖排,可以通过字条矫正的方式,把它变成横向的文字排列;另外一种就是图像中的文字本身排列就是竖向的,因为目前很多文字识别模块都是通过生成数据来进行训练的,所以针对竖排文字识别可以通过一些针对性的数据生成,相当于对文字进行一个90度的旋转形成竖排文字来进行训练,来补充模型的能力。
Q:手写体的识别对比于印刷体的识别,需要额外的做哪些工作?
A:我们目前主要是通过数据增强的方式来进行手写体的支持,主要还是通过数据的方式来进行模型能力的提升,现在都是进行一个统一的处理,印刷体和手写体在识别流程上是一致的。在进行数据生成的时,首先需要真实场景下的一些手写体的数据,另外还需要一些类手写体的一些字体,通过借鉴这些实现内容的自动生成。
Q:在系统的调优阶段对于batch size的优化,详细介绍下
A:图片当中通常会出现多条文本,此时对于文字识别模型,我们可以选择同时输入6条、8条或者更多的Batch Size实现一个批次的预测,这样对于系统整体的吞吐率会有一个提升。由于多行文本中的每一个词条的尺寸可能不一样,我们需要做一个padding,把它们拼接成相同的长度。
Q:数据集是自己做的吗?
A:数据集是自己做的,因为现在整体上来说,文字识别领域中业界公开的数据集还是比较小,包括像一些知名的比赛中,整体的数据量都不是特别多。所以我们肯定要基于一些业务场景做一些数据的收集,但文字识别阶段,目前主要的方案还是通过数据生成的方式,来扩充模型的训练样本。
Q:OCR未来的发展方向
OCR未来的发展方向我觉得还是在当前的一些识别难点上,像现在比较关注的任意形状的文本行识别,曲线文本,印章等这种大家比较关注的一些点。另外我觉得数据集的生成,或者是模拟真实场景的数据生成这种在工程实践上也是有比较实际的意义。尤其是对于一些复杂背景,包括风格迁移的一些方案。
Q:手写体识别有什么好的方法?手写体有一些背景,比如春联,繁体字对于这种识别有没有什么好的办法?
A:由于我们目前是采用的是自然场景下的文字识别技术,它本身就支持一些复杂背景的方案,它跟传统的文档类的OCR或者是一些票据、证件类的OCR相比,本身会对复杂背景会有一些鲁棒性;复杂背景会增加识别的难度,模型现阶段对于背景的鲁棒性还是比较高的,像有一些银行卡的识别,银行卡本身背景也有一些比较复的图案同时还有压印、突起,光照影响等,像这种识别其实都是有比较好的方案。但是如果你的场景越固定,我们通过数据的支持,它的整体的识别效果就会越好。
Q:对于手写公式的识别
A:手写公式应该跟手写体差不多,因为它整体的符号数还是比较限定的,是一个相对较小的集合。主要难度应该和手写体字的难度是一样的,手写的潦草度和印刷体的一个差异。如果连笔太多的化,也可能存在一个比较大的识别难度。
今天的分享就到这里,谢谢大家。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册