Databend:新一代云原生数仓的架构与展望
2021.10.19 17:10浏览量:1440简介:我们期望Databend的出现可以让用户重新审视数据,从而挖掘数据中存在的更大价值。
分享嘉宾:张雁飞 Datafuse Labs
编辑整理:张德通 数数科技
出品平台:DataFunTalk
导读:Databend名字渊源于相对论。由于物质的存在,时间和空间会发生弯曲,这就是相对论的Time Bend。我们期望Databend的出现可以让用户重新审视数据,从而挖掘数据中存在的更大价值。
https://github.com/datafuselabs/databend
本文会围绕下面三点展开:① 传统的数据仓库架构为什么不满足当今需求?② 现代数仓架构有哪些优势?现代数仓架构给用户带来了什么便利性?③ Databend面向云架构的设计。

在介绍现代数仓前,我们首先看一下数据仓库在整个数据库领域内的应用场景:
最左边的OLTP的应用场景,在电商大促的交易场景中,希望数据库有低延迟、高并发的能力。这类数据库使用行存存储,在OLTP领域是比较合适的数据结构。
OLAP适合处理复杂查询,追求的是查询速度、快速返回查询结果。例如一个SQL中有Join或者复杂的子查询,我们追求的是单个查询SQL的快速返回。OLAP底层存储结构一般使用列存结构,这种结构可以在复杂查询中尽量减少和数据的交互。
OLAP和OLTP的中间态是HTAP,例如TiDB。TiFlash和TiKV分别是列存和行存,针对的是既有事务性又有复杂查询的场景。
Databend解决的场景是OLAP场景。
01 现代数仓的几个需求层次
不需要管理硬件和机器配置
不需要管理数仓软件和软件的配置
不需要管理软硬件资源、不需要管理升级、不会遇到因为数据量增长而引发的数据查询速度变慢的问题
秒级的弹性扩缩容能力
资源不需要的时候可以关闭,只为使用付费
云原生数仓没有明确定义,如果可以满足了上面的5个需求,可以认为这个数仓是现代的、云原生的数据仓库。因为这些需求在云基础设施下才可以更好、更容易的得到满足。
02 现代数仓
- 在针对上述5点需求,传统数仓的结构有何局限性?
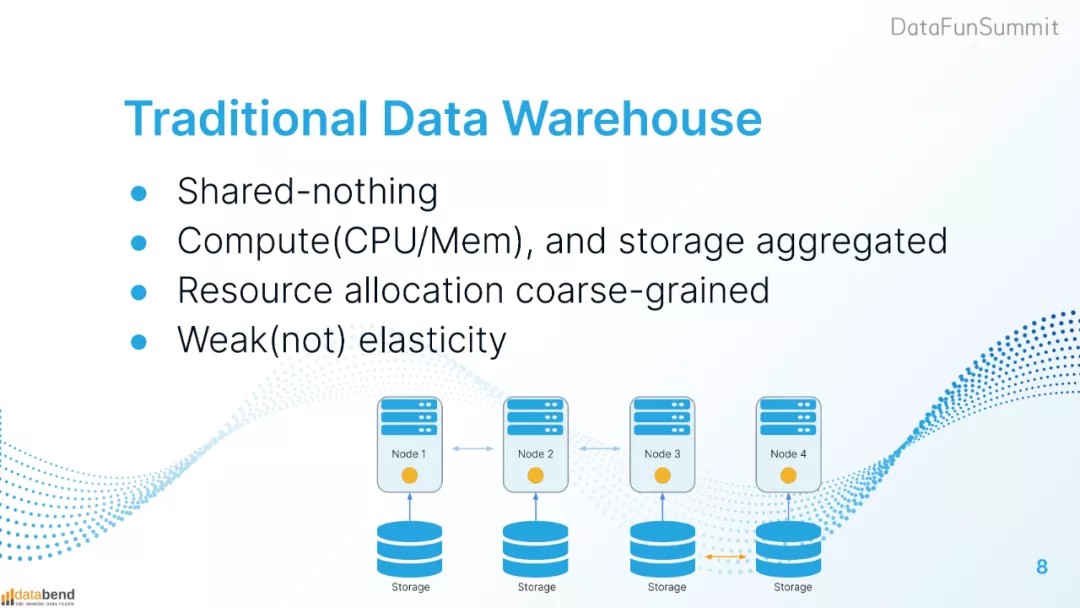
传统数仓特点是计算和存储一体化,即计算和存储都在同一台机器上。对cpu、内存、磁盘进行数据分区,把整个数据打散,每个节点负责一部分数据、各个节点之间的数据也没有关联。
这种架构计算和存储要在一起,算力不够和存储不够扩容时,增加节点数量时候需要向新增节点做数据迁移。迁移的数据热度未知,因此新增节点的配置需要不低于原有节点。扩容可能会使硬件要求越来越高。
传统数仓资源分配粒度低,秒级的弹性很难做到。传统数仓虽然可以扩容,但是时间很长。例如下图中增加node4后数据均衡操作可能会耗时很久,且扩容过程中新增节点不能对外服务,而资源的收费已经开始了,产生了资源浪费。
- 现代数仓架构如何满足上述5点需求?
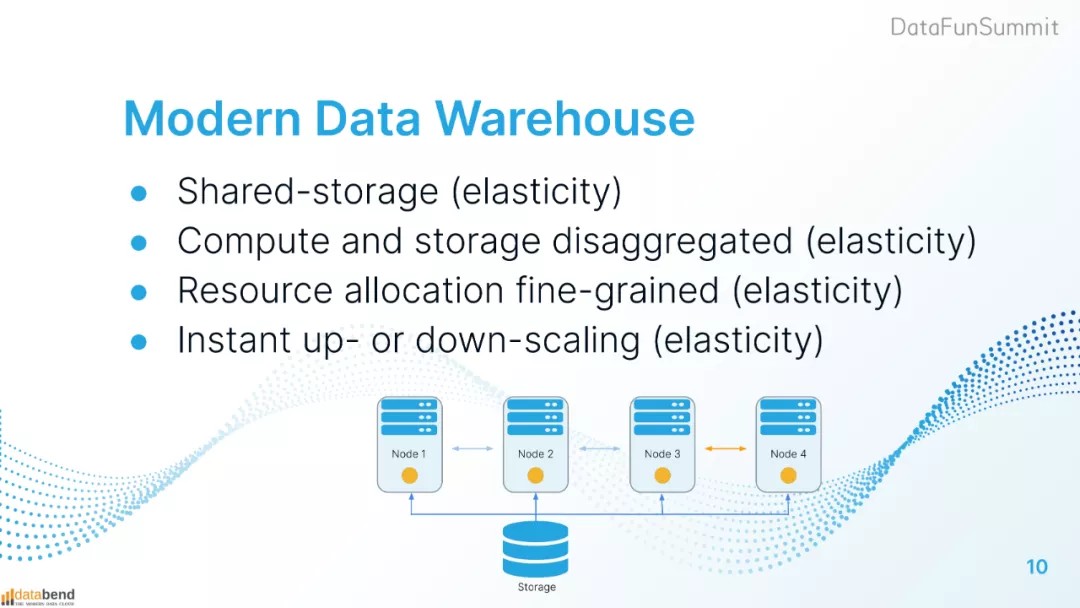
共享存储(弹性)
存储计算分离(弹性):存算分离后,增加计算节点时不需要做数据迁移,可以达到秒级增加计算资源的效果。算力的扩张很快。
计算资源可以根据不同的业务做划分(弹性):例如下图中的node4可以作为数据导入专用节点,node3作为BI计算专用节点。
资源扩张秒级弹性(弹性):这样的架构计算节点异构化,资源分配粒度更细,资源控制更加灵活。
只有每一层级都做到了弹性才可以满足上面的5点需求。
“尽快查出来结果,只为使用的资源付费”,传统的数仓很难满足这个需求和下面的公式:
使用成本=资源*使用时间
03 Databend如何满足现代数仓需求
针对现代数仓几点需求,Databend实现了弹性的完全面向云架构的设计,它强调状态和计算的分离。相比传统数仓,用户使用Databend会获得更低成本、更易用、按量付费的体验。
- Databend架构
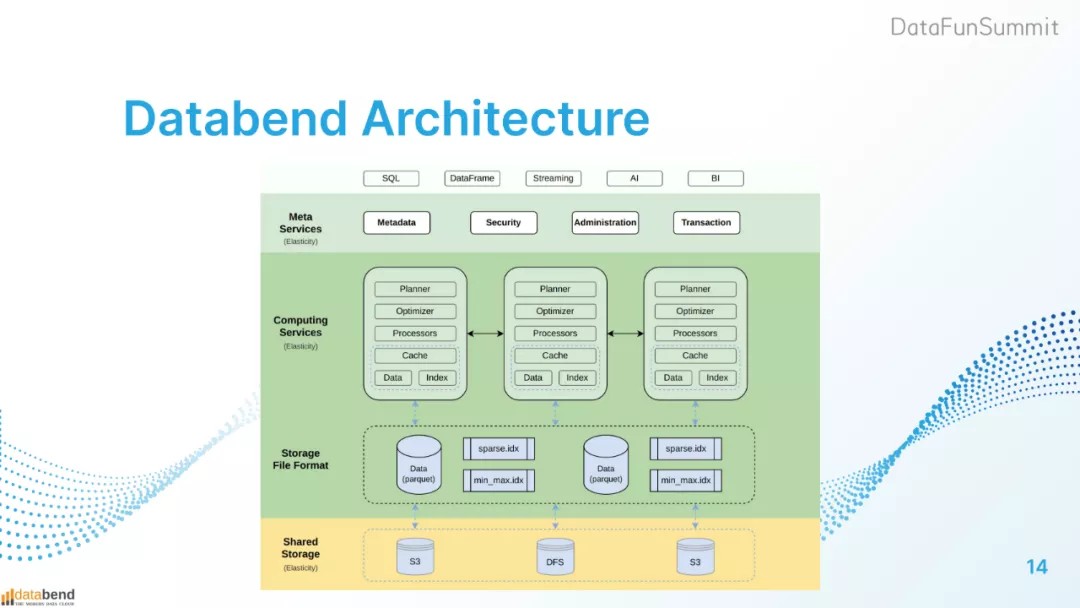
Databend的架构图可以见到,Databend从上到下分为了4个模块:
数据接入:数据接入支持SQL,例如Mysql、Clickhouse等,可以很方便地使用已有的生态连接入数据。Databend在架构的设计上对这一层做了很多抽象。很容易通过已有的生态接入数据。
Meta Service层:元数据和meta信息存储在这一层,这一层相当于Databend 的大脑。这是一个弹性的多租户隔离的服务。
计算层:每个计算结点对于一个sql解析都是独立和完整的。计算结点会对SQL做解析,做逻辑和物理执行计划并执行。每个计算结点有自己的Cache、索引、数据层访问结构。这些节点很容易组成一个集群,用户可以定义集群对外提供的服务。
存储层:存储层主要使用云存储,本地DFS、S3、Asure blob等块存储,基于共享存储打造了databend。
- Databend架构——Meta Service
Databend不只有存储计算分离,更是存储与状态分离的。Meta Service是负责存储状态信息的服务,是一个多租户的服务事务性key-value存储。Databend计算节点则是无状态的。
Meta Service负责数据库用户信息认证,存储 Database、Table、Index的Schema信息,并作为集群内节点的namespace注册中心工作。分布式计算时需要感知集群内节点时会调用Meta Service取得其他节点的信息和状态此外,为了让Meta Service保持轻量,大量的数据不会存储在Meta Service上。
- Databend架构——计算
① 查询计划Query Planning
首先生成逻辑执行计划。对用户的SQL做解析,根据解析的SQL生成逻辑执行计划,再根据SQL执行计划通过优化器深度优化执行计划、确定执行计划是否需要分布式执行和re-shuffle。
下面是一个执行计划的例子:

执行计划从下向上看,首先是最下面要读取的数据源信息。上面例子中显示,读取8个分区、读20行数据。倒数第二行是做过滤,满足年龄>13条件的数据会先筛选出来,且Filter语句是一个下推语句。再上面是Group by,会看数据扫描的区间大小。如果扫描区间是成百上万的,这个操作会是一个分布式地执行的操作;或是根据数据的字段做shuffle,例如city字段在某几个节点上只计算北京、某几个只计算上海。
② 物理执行计划 Processor Pipeline
逻辑执行计划会指导物理执行计划的编排。做物理执行计划即pipeline时首先会生成有向无环图。有向无环图的顶点是一个计算结点,边是一个通道。边通过InPort OutPort进行连接。
下面是pipeline执行语句例子,图中是物理执行计划:
explain pipeline SELECT avg(age) FROM class WHERE age > 13 GROUP BY city

依然从下向上看,节点是8cpu,即8并行。做filter时也是8个并行。GROUP BY 分两步,第一次partial的GROUP BY 是中间态、8并行。Merge后最后把partial的结果进行聚合,Final步骤就从8个并行回到了1路并行。
物理执行计划上关注连接性和并行性。
③ 执行计算任务
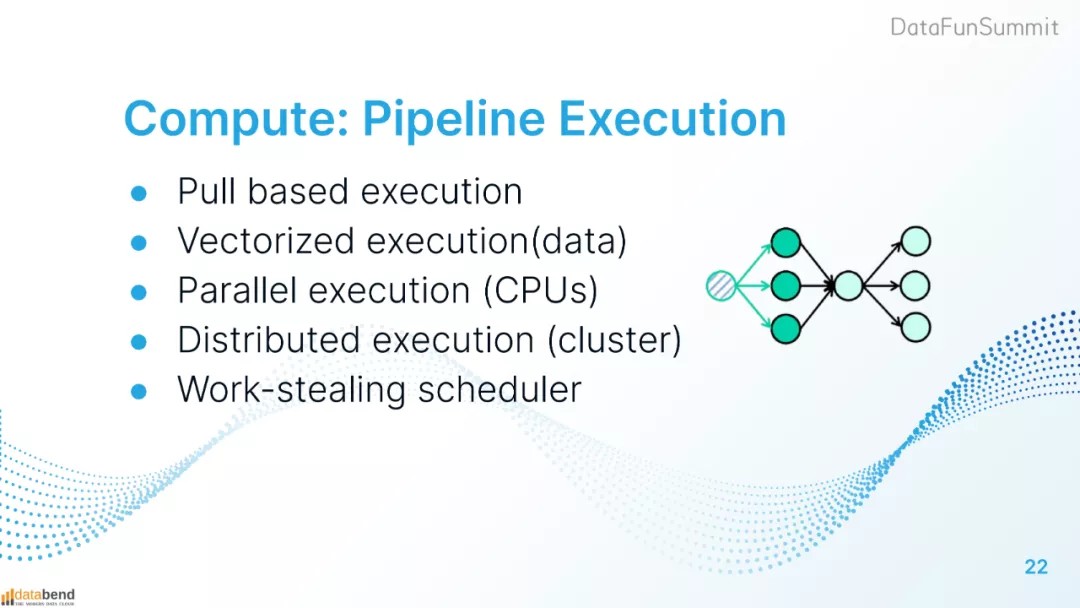
在调度层面,pipeline的任务执行是基于Pull模式执行的。
在数据层面上是以大块数据的形式、达到向量化执行的效果。
单节点CPU指令做并行执行,集群层面做分布式并行。
Databend的任务调度器采用work-stealing机制。每个节点、每个CPU都会从Databend的全局任务队列中取任务,一旦单个节点或CPU上没有处理的任务,就会从集群内队列中窃取任务,这样始终保持了节点和CPU的繁忙状态,不浪费计算资源。
Databend在资源弹性和高性能中最重要的设计就是调度的设计。
④ 集群操作
如果基于传统的gRPC 数据传输,序列化和反序列化会消耗很多时间和资源。Databend使用了Arrow Flight RPC,这是一个针对ap场景的RPC,不需要做序列化反序列化,免去了序列化反序列化时间消耗。
- Databend架构——存储层
Databend没有自己的存储层,底层存储使用的是云端的共享存储、对象存储。Databend为了更快地从共享存储、对象存储中取得数据,对存储有一系列设计:
使用列式存储
Parquet格式
索引:MinMax值和稀疏索引
共享存储、对象存储并不是针对高吞吐、低延迟场景设计的。Databend为了更快地读取数据,计算节点会对数据做索引,定义了MinMax值和稀疏索引。查询数据时首先通过MinMax定位数据文件位置,在文件比较大的情况下使用稀疏索引定位更细粒度的数据块。从云存储中读取的数据越少,需要计算任务就越轻,网络传输也会更少,计算速度加快。
- 支持多云
Databend对云存储做了统一视图,云厂商的存储接口统一封装成我们的数据存储层。用户可以无感知地使用跨云存储。
- 存储层自动聚集
数据量大的情况下数据变慢,是数据库中经常要面对的问题。业务上某一类数据很热时Databend会实现在热点数据上查询速度加快的能力。
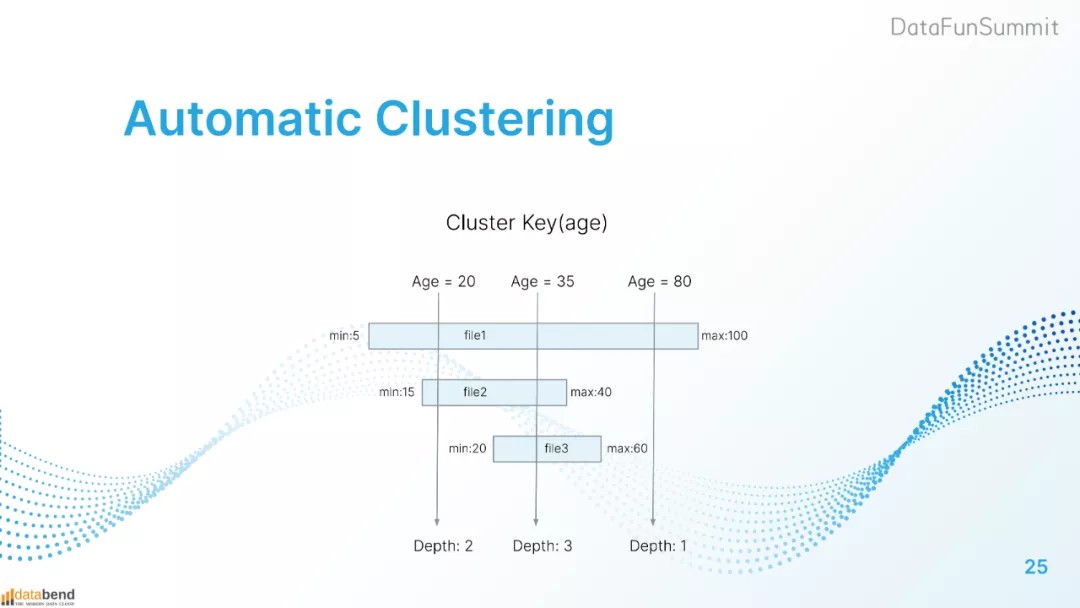
例如下图中的查询。查询年龄20时,击穿(查询)了2个文件,深度为2。当查询年龄为35时,击穿文件数量为3,深度为3。当查询年龄为80时,击穿文件数量为1,这种状态比较理想。如果业务上经常需要查询年龄35,且文件击穿的深度较深,这种情况下databend会感知到文件需要合并。文件1、2、3和文件35相关的内容会被合并成1个或深度更薄的几个文件。再次查询年龄35时读取文件变少,读取数据速度变快。
04 Databend 未来计划
Databend从2021年3月开源并开始研发,目前正在早期的研发阶段,会尽快推出Alpha版本。推荐大家在Alpha版本推出后进行试用。
Databend的目标不会改变,始终追求性能和弹性。随着云基础设施越来越完善,大家对按量付费和弹性的需求非常强烈。Databend既可以云端部署也可以私有化部署。
最后Databend会向着Serverless方向迭代。Serverless意味着把资源的调度做到更加精细化,云数据库的计算结点可以和一个函数一样,使用的时候拉起,使用完毕后销毁,只需要用使用付费,资源调度会非常精确。
今天的分享就到这里,谢谢大家。

发表评论
登录后可评论,请前往 登录 或 注册