AI在度小满征信解读中的应用
作者:萧萧慕雨2021.10.22 15:53浏览量:1365简介:本文主要介绍我们针对金融征信数据以及面向信贷领域模型在技术上的优化实践。
分享嘉宾:正兴 度小满金融 算法高级专家
编辑整理:张春越 哈尔滨金融学院
出品平台:DataFunSummit
导读:本文的主题是AI技术在征信解读中的应用,主要介绍我们针对金融征信数据以及面向信贷领域模型在技术上的优化实践。
01 背景
1. 征信数据介绍

征信数据主要指的是人民银行征信中心给出的个人信用报告。人民银行个人征信是从1999年在上海开始实践的,经过20多年的发展,现在已经是世界上最大、全国统一的一个个人和企业征信系统。目前,基本上主要的金融机构都比较大地依赖征信数据。征信数据的主要内容包含了6个方面,其中最主要的是4大块,包括个人基本信息,信贷交易明细,非信贷信用信息,以及查询记录。个人基本信息主要是来源于公安部个人信息、共享平台,各类金融机构自己的信息,比如说,某个人的学历学位、已婚未婚、户籍地、居住地址以及工作地的历史列表;信贷交易明细主要是贷款、贷记卡的一些历史的信息和当前的信息。这里的贷记卡主要是指信用卡。另外还有准贷记卡明细的信息。贷款信息主要包含个人的贷款时间、额度、期数、类型、贷款机构和机构类型、当前的每月应还多少,已还多少等等单月信息以及历史逾期情况;非信贷信用信息主要包括公积金的缴纳信息,这个信息是官方的,包括缴纳的金额、比例、公司等;查询记录主要是贷款或申请贷记卡的时候允许查询征信信用报告,个人信用报告,能够反映个人的户头借贷的信息。基本上看,征信报告记录了强金融相关的数据,并且和官方是一致的。
2. 信贷模型场景介绍

可以说,主要的信贷业务都会比较强地依赖于征信的数据。在数据上,通常征信数据一大块,自有数据一大块,相对于产品数据的话,征信数据可能更强一些,因为征信数据是直接金融相关的。因此,信贷模型的效果会影响到各业务指标。如何充分利用和挖掘征信数据来提升效果是一个比较重要的问题。在利用征信数据方面,历史上和现如今各机构传统上主要使用的是评分卡模型。该模型一般是基于专家经验来加工几个或者几十个特征之后,最后处理成一个加和模型。这种模型具有一个非常好的可解释性,以及对样本规模较低的依赖,效果相对于复杂模型会差一些。复杂模型有两个基本的思路,一个思路是去加工提取更多的特征,进一步用更复杂的模型;另外一个思路是基于原始数据,做非结构化特征来构建端到端的模型,端到端模型也会使用复杂特征。这三个方向度小满金融都有去做,并在持续优化。今天主要分享端到端的模型。一般来讲,端到端模型是三种建模方式里面效果最好的。因为它能充分利用不太好加工的数据,比如说文本类的数据。
02 主要内容

本文主要包括以下几个部分:首先,因为数据是一致的,会分享针对数据的特点来做模型的优化,以及如何充分利用和挖掘这个数据;其次是介绍利用预训练的方法来进一步提升模型的效果;第三,会简单介绍排序模型的应用;最后分享一下对复杂模型的可解释性的理解和研究现状。
1. 模型结构优化
① Model1
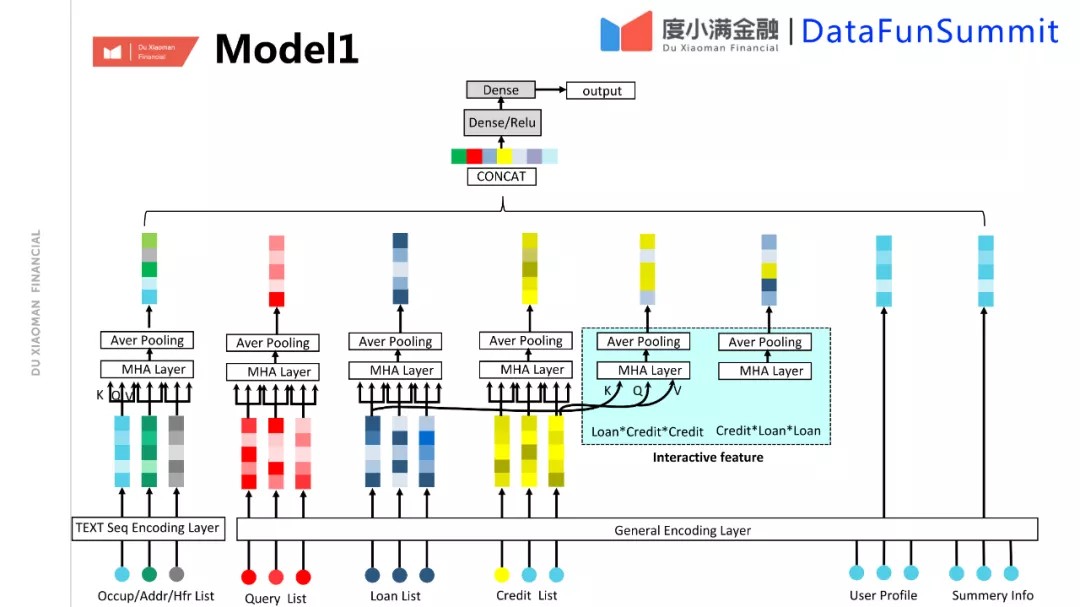
以风控模型为例,这个任务的学习目标是非常清楚的,就是对整个数据里的风险信号进行有效的捕捉,把好人和坏人尽量分开,在相同的用户集合里面识别更多地可经营的好人。基于征信报告的端到端的建模主要面临以下几个问题:第一个是数据是半结构化的。不同于比较规整的数据,比如说贷款和贷记卡粒度的数据,里面会有一些文本信息,这部分数据也是半结构化的,和纯粹的自然语言还不太一样;第二个问题是在征信数据里面,一些比较强的风险特征会在前置规则里面应用,一旦触发就会直接过滤掉相关数据,并不会进入到我们的系统里面。比如征信中历史逾期现象比较严重的,他已经逾期了,根本就不会进入到我们的系统中。因此,模型要从弱一点的信息中以及不同的信息交叉里面来学习风险排序。此外,上面提到的征信报告中的文本是相对稀疏和弱相关的。针对这些问题的优化和组合,我们提出一个技术模型方案Model1。由于基本信息都有数值和类别的特征,因此我们会在底层做基本信息整合。在此之上,大量使用类似self-attention的结构,左联两个交叉之后的信息汇聚,比如贷款内部的序列信息交叉,贷记卡内部的序列信息交叉,以及它们之间的交叉;对于文本信息同样也使用两层的multi head attention结构,因为它是两层序列关系,一个是文本序列本身,然后是序列之间。我们也尝试使用更深的transformer模型,实验中发现效果不好,不如浅一点的模型,我们推测是由于文本比较稀疏,以及在相对比较强的场景下,征信信息,可能是在一定程度上,对组合记忆能力强的模型会优于在更高维度上泛化的模型。
② Model2
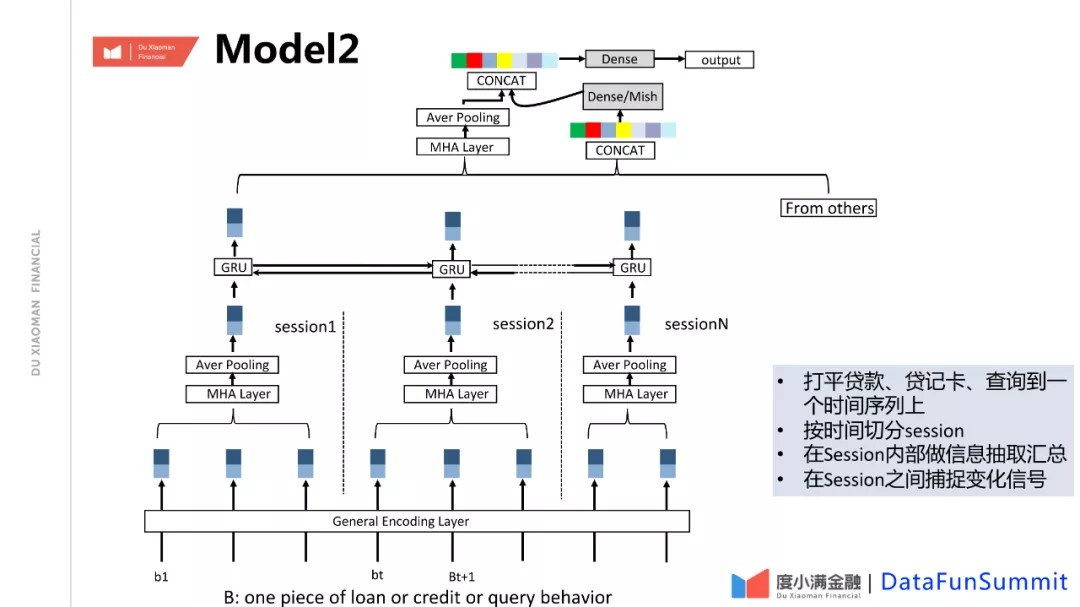
针对前面的基础模型,虽然我们做了4路维度的交叉和信息整合,在效果上已经大幅度超过了之前的xgb复杂模型,但是我们认为对趋势信息的捕捉还是不充分的。在用户的贷款数据上看,贷款的行为具有时间聚集性的,在某段时间会比较集中,在某段时间会又比较空窗,同时贷款、查询、贷记卡申请这三者之间是内部高度相关的。比如贷款、贷记卡,在申请贷款或者贷记卡发卡的时候,会有贷款的查询,在查询之后,会产生贷款或贷记卡。有的可能没有借,可能没有通过,基于这个理解,我们对模型的结构上进一步优化,对贷款、贷记卡各自编码后,组成一个整体的序列,前面是分开的编码,内部做交叉;做成一个完整的序列后,我们做一个内部的组合,Session之间做一个序列模型,对趋势信息做一个建模。
③ Model3
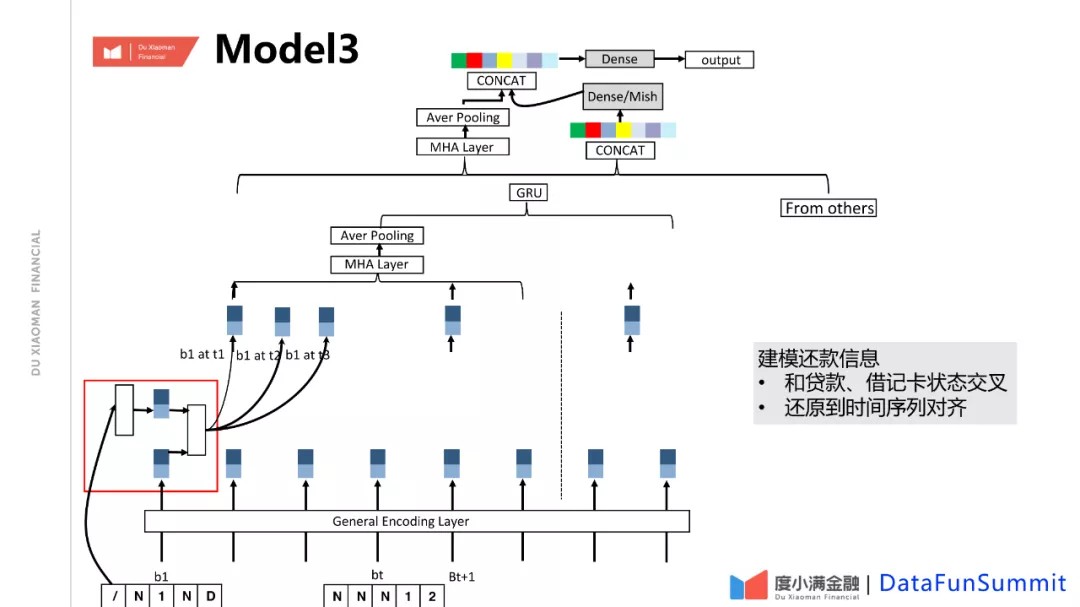
进一步的,在时间维度下,征信报告上有两个维度,一个是前面介绍过的贷款发生时间,以及贷记卡发卡时间;另一个是还款时间,是一个嵌套子序列。举例,对每笔贷款,在5年的历史内,每个月的还款状态,这个时间序列和贷款时间是两个维度,还款序列直接放在贷款维度下面其实不利于学习整体还款趋势变化的。我们基于这一点进行了优化,把贷款的还款序列和基本信息做交叉。之所以这样做是因为贷款这个序列本身是不充分的,它只能体现这个月有没有发生逾期,逾期多少钱,但是贷款是什么类型的贷款以及期数是多少,这些信息也都很重要。我们的一个基本优化策略就是把它们两个做一个结合之后,放在一个序列之上,从而对前面的模型做一个增强。
④ Model4
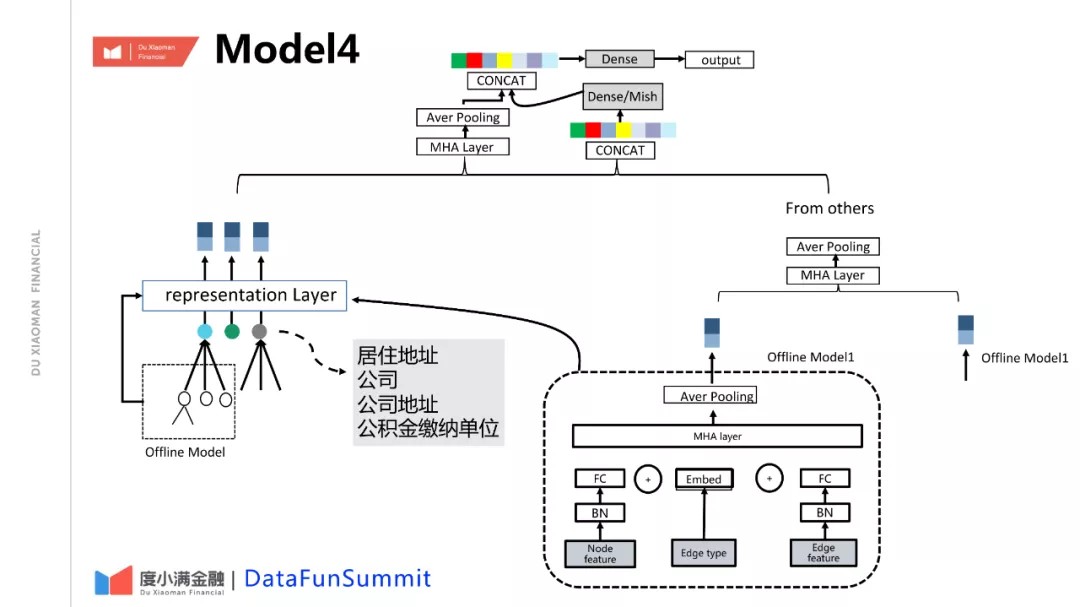
同样的,对于征信数据中的文本信息的利用上我们也做了很多优化的工作。基本的思路是建立关联网络,使用图神经网络进行挖掘。原因是征信文本信息和常见的自然语言的分布不完全一致,征信文本里面的信息主要是地址信息、公司信息等,包含大量的偏长尾的专名,比如某个地理位置,公司名。这个公司名具有一定的含义,如果没有额外的知识的话,很难理解它的信息。前面的几种直接对文本的建模只能识别浅层的相关性,这个可能也是使用传统的transformer模型在这里不工作的原因。对于这部分信息,我们的优化思路是把这些作为一个节点,构建关联网络侦测背后隐藏的信息。这里举一个例子,比如有个公司名,叫华工正源光子技术,如果直接建模可能会学到里面的一些含义信息,比如说光子技术。但对于前面的专名华工正源,很难积累到足够的样本去学习它的风险,但是通过关联网络,关联它和其他用户、以及真实世界的其他信息,综合去汇集华工正源的风险信号,进一步去推断这个用户的风险。整个模型可以是一个端到端的方式进行训练,找到一个可以优化的整体的特征组和参数,以上是我们对于文本的优化的一个工作。
2. 预训练方法的优化
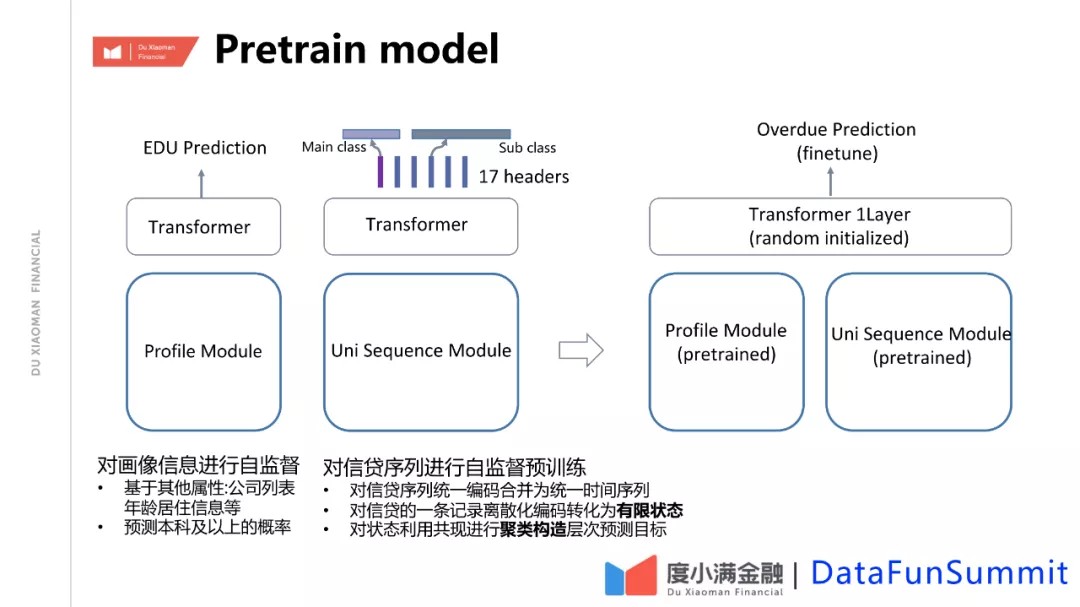
前面分享了在模型结构方面如何充分挖掘数据信息和优化的工作,接下来介绍在预训练上和优化目标的改进优化所带来的提升。在NLP、CV里面预训练模型取得了很大的成功,原因是模型容量足够大和利用了海量的数据去做预训练。而在金融里面,有类似的情况,存在大量的无标签数据。比如以度小满为例,申请的用户,通过率只有20、30%,通过了以后,真正发生了贷款的用户可能不到一半。实际上,只有真正发生了贷款,才会有真实的逾期还是不逾期的标签。这样算起来,只有10%的用户才有标签,90%多的用户是没有标签的。要么被拒绝掉了,要么是他申请但是没有入信。整体的数据构成了一个无偏的分布,我们希望通过预训练的方式来充分利用这部分的数据,然后通过模型来学习里面各项信息本身的相关性。因为数据自身里面会有相关性,从而成为整个信息的一个完整表达,然后在有标签数据上进行finetuning。一开始我们的基本思路是借鉴了BERT的方式,通过对征信报告里面的信息随机Mask掉一些信息,通过其他信息来预测mask信息。由于征信数据要远比自然语言的数据要复杂,因此在实现上有很大不同,但整体上是类似BERT的思路。但是最终发现,这样做了效果不好,原因是因为不同的局部信息有较强的相关信息,无法学习整体的相关性,而是直接去拟合局部的相关性。例如贷款额度和期数是和本月应还是相关的,如果mask掉本月应还这个数据,再去预测,模型可能就会直接去学习这个关系,但这个关系实际上是没什么用的,因为本身强相关。我们希望学习的是有其他贷款情况下,可能会产生什么贷款啊,本月应还是多少等。因此,我们做的优化是,对整体相关的信息做离散化整体组合编码,变成整体空间里的一个点,比如把贷款,整体映射到贷款空间里的某个点,对整体进行预测;同时也要对预测做优化,因为组合起来的数非常多。我们采用类似hierarchal softmax这种层次化优化,根据它的相关性做聚类,做两级的预测,实际上,我们做了优化后,对比不做预训练的模型,新的模型大幅超过之前的模型,效果有明显提升。
3. 风险排序模型的应用
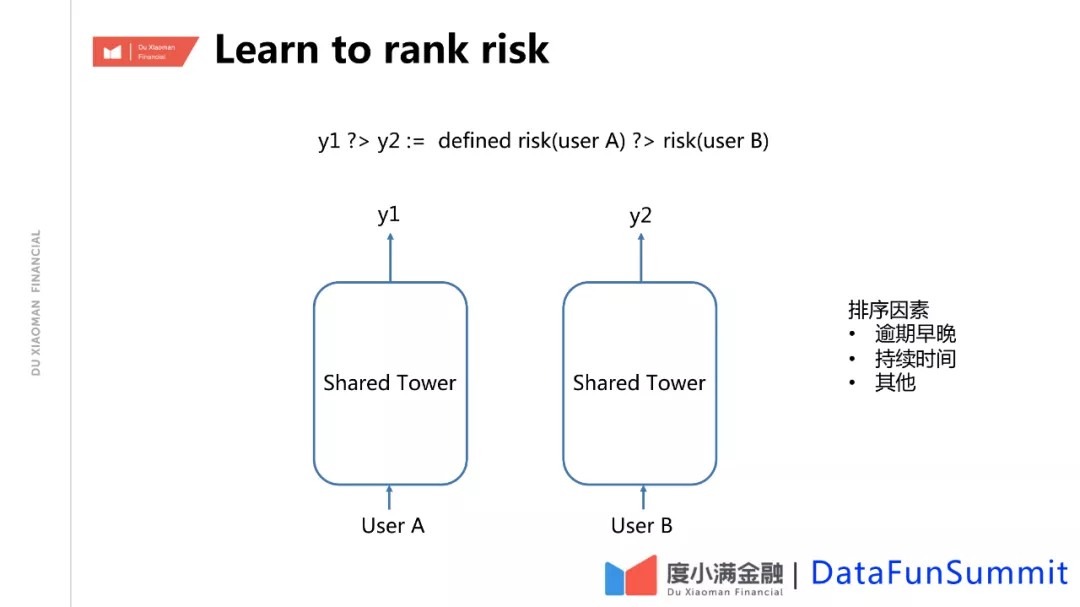
通常,对于分类模型,最终会输出一个类似概率的分布。对于风险因子模型,最终要的并不是最大化预估准确的条件概率,而是要区分用户风险的排序,因为具体到每个用户上,他逾期不逾期是离散的。我们希望知道整体的相关关系后,因此更直接地去优化目标。我们用的auc或KS来衡量效果本身对应是一种排序的能力。虽然说排序模型,在最后的序列优化过程中,理论上差异并不大,但把优化目标转成排序模型后,可以有引入更多的信息,来定义排序的优化目标,使得模型更符合我们的需要。比如说,我们可以定义坏人,也就是逾期的人, 的排序,把逾期时间早的人放在前面,认为他是一个更坏的人,也可能有其他协议的,逾期比较往后的这些人排到后面一点,他可能是有一定的偶然因素。类似这种方式,我们实践下来会有这样一个结果,我们在长期逾期区分能力差不多的情况下,可能会明显提升短期逾期风险人的区分能力。因为通过排序会利用后面逾期的信息。因为一般来讲,早期逾期的人会少一点,把他们排到后面逾期的人的前面,在分类面上会累积后面逾期特征上的组合。比如说疫情影响的处理,我们可以结合蒸馏学习的思路。对疫情影响的逾期,我们可以人工定义某个好坏的程度,比如可以利用一个非疫情影响的样本,训练一个大模型的排序,作为子模型排序的一个优化目标。通过蒸馏排序,整个优化目标是无偏的,整体上一致的。这样做不像其他的方式,比如在损失函数上定义权重会引入超参,但我们不知道如何定义这个权重等问题,就会打破原有的样本分布。而我们的方式可能还是在整体的一个框架下做这个事情,这样处理会比较平滑。
4. 复杂模型的可解释性

最后聊聊模型可解释的问题。模型可解释的出发点是当前我们目前常用一个复杂的模型,模型有更好的性能,但是它是一个黑盒难以解释,不知道发生了什么。而且我们现在的模型一般都是学习到了关联关系,而不是因果关系,实际中会有可解释模型的需求,包括自身的debug或者给出依据,都会有可解释的需求。对于复杂模型,可解释的方法有很多,这里介绍两个主要的和实际中比较有效的方法,一个是IG方法,就是Integrated gradients,另一个是SHAP类方法。IG是基于梯度的,SHAP是一类方法,它可以在不同场景下实现这种方式。SHAP是从博弈论来的,输入在不同的组合下,比如有这个特征和没这个特征组合下,结合要解释的这个特征,得到所有组合下的边界,它在理论上可以得到一致的结果。实际上,SHAP类方法目前在树模型上实现的比较好,它可以根据树的Gain来直接算出结果。对于神经网络模型,目前有一些近似的实现,但是复杂度较高,笨重一些。IG这个方法是对于梯度方法的改进。梯度是对某个输出,可以算出输入的梯度,梯度代表了输出对输入的斜率,也就是影响幅度的大小,但是直接算梯度有个问题,会存在饱和的区域。因为它只算一个点,可能本身已经处在饱和的点,算出来的梯度比较小,虽然某个输入比较重要,比如在图像里面,红色很重要,模型本身学到有一点红色就可以得到结果了。但是比较红的时候,在计算梯度时却比较小,因为梯度比较大的点是在比较Low的地方。IG方法提供一个baseline,从一个baseline变化到当前样本的梯度的积分去算,这样来说,相对baseline,特征最终起作用的是什么。这样解释也会有一些问题,baseline的选择很重要。还是拿图像举例子,一个黑色图片做baseline,假如最终模型里面黑色是一个重要的样本,如果用黑色就算不出重要性。对于自然语言里面,则可能好一些,可以不存在就不算梯度。这两种方式都可以归因到某个输入对结果的影响。实际上,在模型比较复杂的情况下,解释的结果本身也不容易理解。一方面确实是给出了一个解释,是线性累加的解释,解释本身也很复杂。实际应用中,模型debug的时候去算影响,但是在业务上会使用一个代理模型,对一些高级特征去做计算。
03 问答环节
Q:征信报告中的文本都是居住地,工作单位之类的,这类数据怎么更好的编码?
A:今天我分享的主要是端到端的模型,这种模型是直接编码的,把字或者词直接变成embedding,再映射到低维连续空间里,再做进一步的组合。
Q:征信表现N123C这种信息,神经网络采用哪种编码模型?
A:这些可以理解为一种类别元素,1表示逾期1个月,2 表示逾期两个月,但是里面可以做一个分段,大于10做一个分段,因为比较稀疏。其实在一个信息厚度情况下,可以将离散的编码做embedding。
Q:一份征信报告中是一个样本,还是一个征信报告按时间拆成多个样本?
A:我们是对用户来做风险判断,因此一个征信报告是一个样本。
Q:征信报告有的是数据是状态数据有的是行为数据,怎么构建神经网络结构?
A:行为数据指的是什么?行为也可以理解历史的行为,也是状态数据,因此处理方式类似。
今天的分享就到这里,谢谢大家。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册