DSTC10 放榜,百度 PLATO 勇夺知识型任务口语对话赛道双冠军!
作者:三里河2021.10.26 10:46浏览量:572简介:百度在DSTC10中斩获了知识型任务口语对话赛道两项任务的全部冠军
近日,第十届对话系统技术挑战赛DSTC10落下帷幕。作为全球人工智能顶级学术竞赛之一,DSTC比赛持续受到国内外知名企业和机构关注。百度在DSTC10中斩获了知识型任务口语对话赛道两项任务的全部冠军,并以大幅优势领先对手。
在上一届DSTC比赛中,百度PLATO-2 模型夺得多个任务冠军;本次比赛,百度结合了最新发布的全球首个百亿参数对话生成模型PLATO-XL,在赛题难度加大的情况下,凭借强大的技术实力再次拿下多个冠军。
加入错误干扰数据 知识型任务口语赛道难度空前
任务型对话基于知识为用户提供口语化的信息查询、指令执行等智能服务。今年DSTC的知识型任务口语对话赛道由对话状态追踪和知识对话两项核心子任务构成,这两项任务是判断对话系统能否在多轮对话中准确理解用户意图、正确传递信息的关键。为了更接近真实场景,该赛道首次在竞赛中使用了带有自动语音识别(Automatic Speech Recognition, ASR)错误干扰的口语对话数据。下图展示了验证集中的一个对话片段,口语的表述更加复杂多样,且ASR错误带来的干扰很大(作为参考,灰色部分为人工再次核查录音,校正后的对话内容)。相比于传统对话系统中采用的众包数据,该赛道不仅训练数据缺乏,而且数据噪音大,这对正确理解用户信息并保持高质量的回复是一项极大的挑战。

- 知识型任务口语对话赛道ASR错误示例:灰色字体为专家根据对话内容恢复的准确文本。红色字体为ASR错误内容
那么在激烈的竞争中,百度是如何在这一赛道拿下两项任务全部冠军的呢?
对话状态追踪任务大幅领先 创新提出多层级数据增强框架
在任务1对话状态追踪任务中,参赛系统需要完成多领域对话状态追踪,正确识别出用户意图和槽位。首先,针对训练数据匮乏的难题,百度团队创新地提出了多层级数据增强方法,通过对已有对话进行实体替换、基于对话动作随机游走、口语模拟增强等技术,自动构造了数十万的多轮口语对话。然后,依托对话生成预训练模型PLATO,进行对话追踪任务端到端建模,即根据多轮对话上文自动生成意图和槽位,大幅提升模型鲁棒性。最终联合目标准确率(Joint Goal Accuracy)达到0.4616,超越第二名十个百分点,以绝对的优势夺得第一。

- 对话状态追踪任务示例:将用户的口语文本转为结构化的对话状态描述同时,还需要修复相关ASR错误
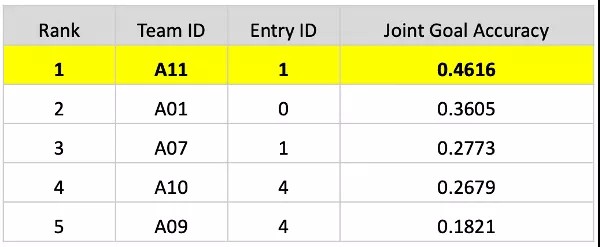
- 对话状态追踪任务榜单(前五名), A11为百度团队
知识对话任务夺冠 实体增强辅助知识精准定位
第二项任务为知识对话。传统任务型对话以知识为基本支撑,一旦用户的诉求超出知识范畴,对话系统就无法做出正确的回复。针对该问题,通常会在对话系统中引入大量的外部知识,来进一步提升对话系统的能力。在该背景下,第二项任务设置了三个级联的子任务:
- 判断当前对话是否需要使用外部知识;
- 选择跟当前对话内容匹配的知识;
- 根据选取的知识进行回复生成。
针对这些子任务,百度创新地提出了知识增强的对话策略:首先,在多领域任务对话的复杂场景下,准确识别与对话意图相关的知识需求;然后,知识召回模型从大规模知识库中高效召回合适的知识;最后,利用PLATO-XL的灵活可扩展性,基于对话上下文内容以及召回的外部知识,自动生成回复。从系统回复的人工评估结果来看,百度在回复的准确性和合适性两个指标都取得最好成绩。
值得一提的是,任务结果评估也引入了人工标注的结果(Ground-truth)。百度提交的结果与人工标注结果差距最小(百度系统得分3.4235vs人工标注结果得分3.5291),验证了上述知识增强的对话策略更接近人的认知过程,相比于其他系统,具有更好的可解释性。
如同人在回答一些不了解的专业问题也需要查阅资料,知识增强的方法使对话系统具备了“临时查阅”的能力,能够更加专业、更加精准地回答问题。知识增强的对话不仅成功应用于知识对话任务,在百度近期发布的PLATO-KAG等相关的工作上也取得了不错进展。可以说,知识增强已经成为对话系统的必备能力。
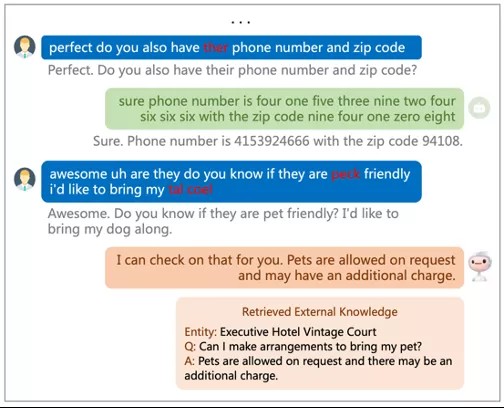
- 知识对话任务示例:系统需要判断是否需要引入外部知识库,并利用外部知识(External Knowledge)来准确响应用户需求
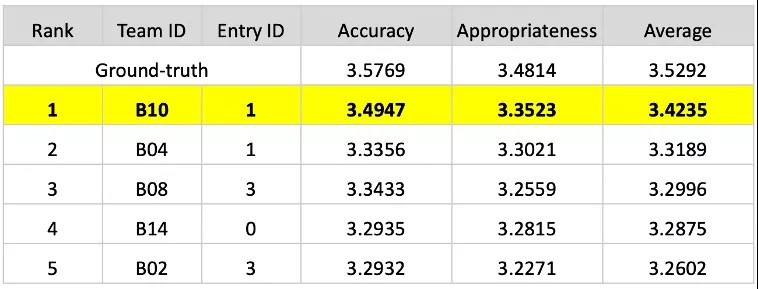
- 知识对话任务榜单(前五名),B10为百度团队。第一行(Ground Truth)为人类标注。对话从准确性(Accuracy), 合适性(Appropriatenesss)两个角度进行评估
对话系统是自然语言处理领域最具挑战性的技术之一,尤其是实际应用场景下,数据高噪声、多歧义,比学术研究数据更复杂、更具挑战性。通过此次DSTC10竞赛,百度再次锤炼了PLATO模型的鲁棒性,同时验证了知识增强策略的应用效果,并为解决产业应用中的实际问题提供了全新思路。未来,百度AI还将持续技术创新与突破,实现让对话更有知识、有情感、有逻辑的目标。
百度PLATO系列模型完全基于百度自主研发的深度学习平台飞桨。DSTC10的冠军解决方案也会陆续开源到GitHub,对智能对话感兴趣的小伙伴千万别错过。同时,百度也推出了“百度PLATO”的微信公众号,大家可以体验基于PLATO的中文对话效果。
GitHub链接:
https://github.com/PaddlePaddle/Knover
体验方式:打开微信搜索【百度PLATO】或扫码关注公众号,开启深度畅聊。
百度自然语言处理(Natural Language Processing,NLP)以『理解语言,拥有智能,改变世界』为使命,研发自然语言处理核心技术,打造领先的技术平台和创新产品,服务全球用户,让复杂的世界更简单。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册