可视化神器背后的奥秘
作者:小小小芭比2021.12.14 17:08浏览量:2114简介:本次分享将介绍BI分析背后的技术架构与流程,及可视化图表的智能推荐策略。
本文由百度智能云资深研发工程师——张军在百度开发者沙龙线上分享的演讲内容整理而成。本次分享将介绍BI分析背后的技术架构与流程,及可视化图表的智能推荐策略,帮助大家深入理解智能化可视化BI的技术与实践。
文:张军
视频回放:https://developer.baidu.com/live.html?id=13
本次分享的主题是:智能化可视化BI与大屏揭秘。内容主要分为以下4个方面:
- 产品介绍
- 可视化分析技术
- 智能图表推荐
- 智能语音交互
01初识Sugar BI
百度大数据体系产品架构全景图

百度智能云大数据产品架构全景图共三层:
底层通过湖仓数据基础设施(包括湖仓引擎和治理开发)为企业提供数据存储、数据处理、数据开发等能力;
中层的数据价值挖掘平台,充分利用百度智能大数据技术,实现企业数据资产价值最大化;
顶层:即基于底层和中层的技术,帮助各行各业落地大数据应用落地。
Sugar BI作为数据价值挖掘平台之一,
它是作为数据与用户最直接接触的一个连接。
快速搭建专业化BI分析平台
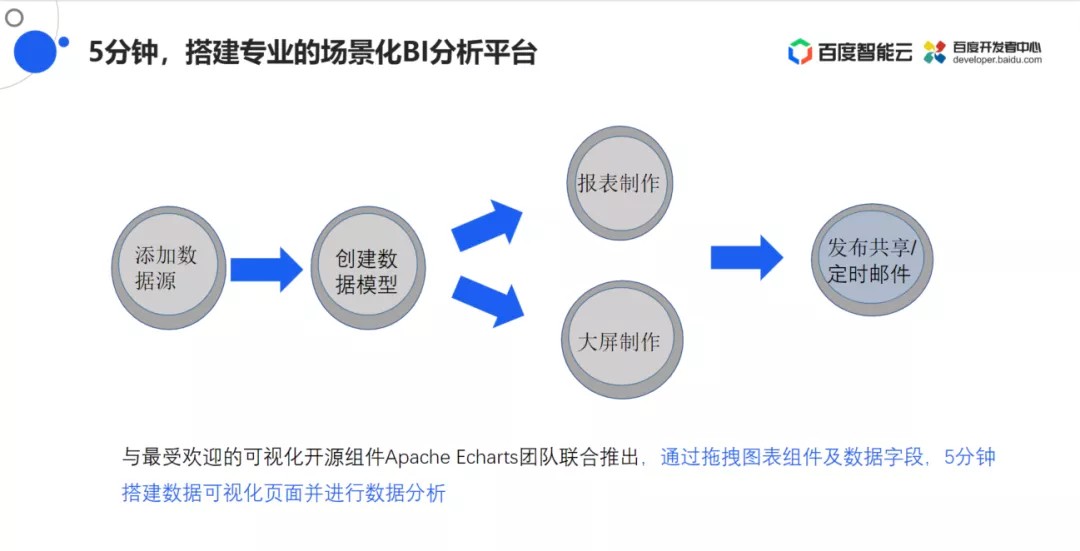
设计目标:让用户在5分钟之内就能搭建专业的场景化的BI分析平台
搭建流程:添加数据源→创建数据模型→可视化效果制作(包括报表制作&大屏制作)
这样简单的步骤让用户非常容易就能搭建一个可视化平台。在这个过程中利用了百度可视化开源组件Apach Echarts,通过拖拽图表组件及数据字段的方式,在5分钟之内就可以搭建数据可视化页面并进行复杂的数据分析操作。
对接多种数据源
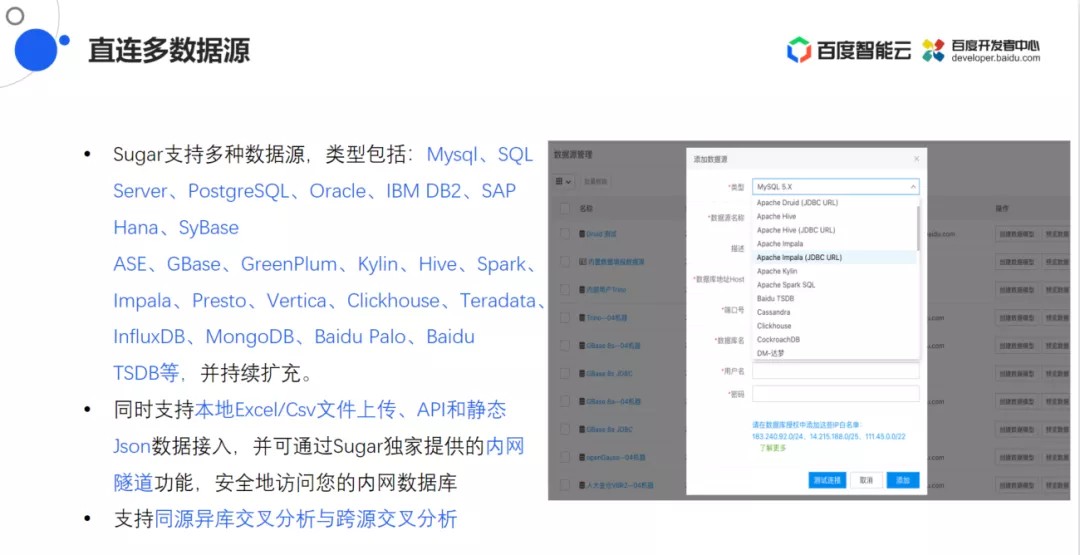
在数据源层面,Sugar BI可以对接的数据源包括:
- 开放性的数据库:MySQL、SQL Sever、 PostgreSQL、Oracle等。
- 大数据的数据源:国产麒麟(Kylin)等。
- 其他场景中经常会用到的大数据的组件:Hive、Spark、Impala、Presto等。
该平台还可以支持Excel/Csv数据的上传,同时还支持对接已有的API并且允许用户静态的输入Json代码来做效果展示。最后还开发内网隧道的功能,可以让内网中数据源的数据通过内网隧道的方式直接对接到云上Sugar的产品中。对于不同的数据源,比如MySQL和SQLserver,还支持两种数据源的跨源交叉分析。
零代码+拖拽式制作报表
- 在产品报表的主编辑页面,所有的组件都是拖拽式的。
- 使用拖拽字段的方式进行数据绑定、全界面化的添加和修改图表组件,简单易用。
- 丰富的图表配置项,可以让用户零门槛上手。
- 移动端报表布局自动适配,可以让用户随时随地多端查看SugarBI产品。
- 帮助真正懂业务的人完成分析。
大屏展示
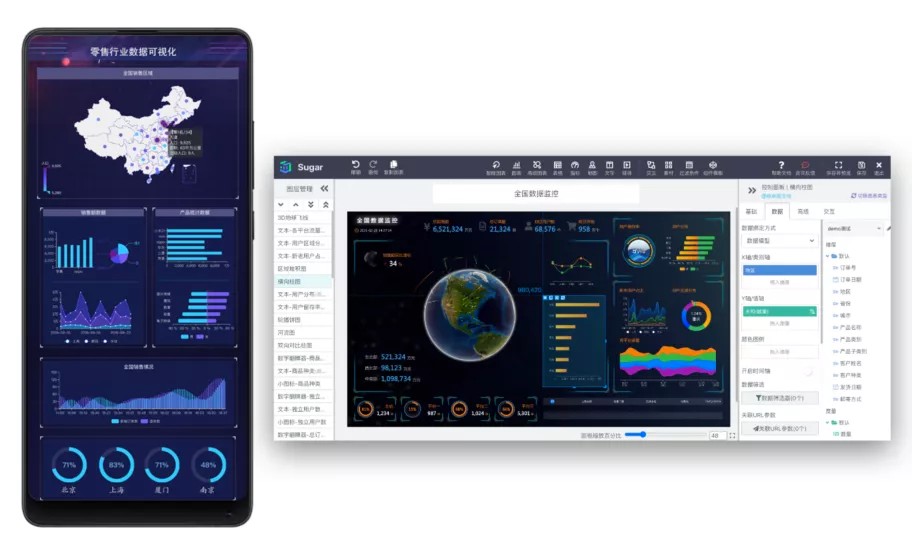
在大屏页面中通过内置数十种大屏模板,Sugar将百度内部专业的UE/UI设计资源赋能给客户,模板包括政务、教育、零售、金融、制造等各行业,整套设计涵盖移动端与PC端。客户只需简单修改,即可使用。
02可视化技术分析
Sugar BI架构——有AI特色的可视化+BI分析平台

SugarBI在设计的定位是做一个有AI特色的可视化分析平台。其中主要突出的三个特点分别是AI、BI和可视化。SugarBI的整体架构图都是围绕这三大特点来构建的,它将AI、BI、可视化这样的三个能力进行融合,最终使用容器化的技术进行打包和部署。
BI能力:数据模型+灵活交互+数据计算
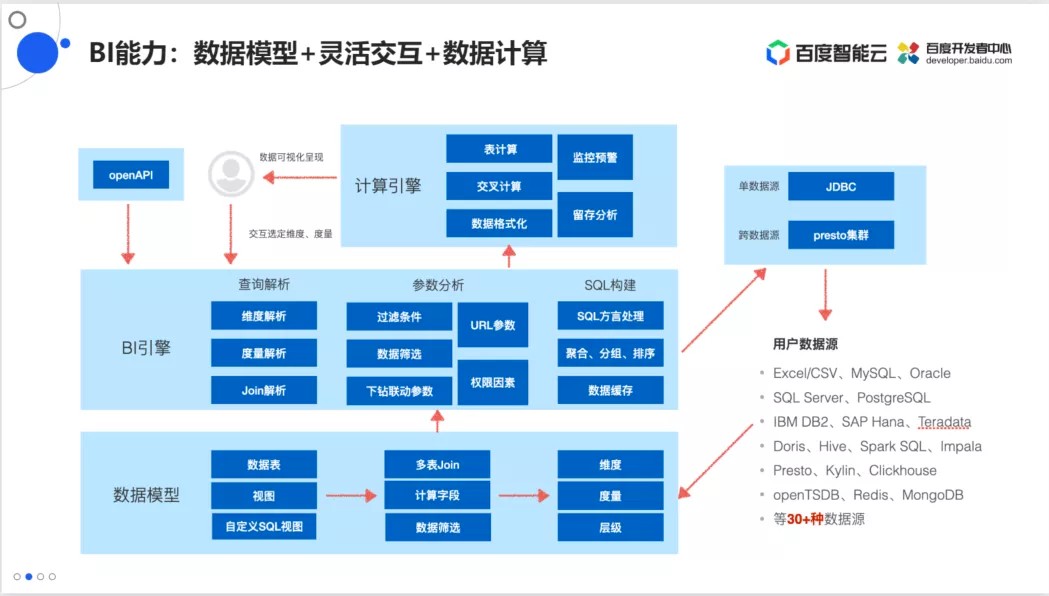
BI能力方面,Sugar支持对接丰富的数据源种类,包括excel、各种关系型数据库mysql、oracle等、以及大数据数仓Doris、clickhouse等,一共超过30种数据源,目前在国内是最全,并且支持了 达梦、人大金仓、南大通用、华为GaussDB等国产数据库
数据模型:可以单表、多表join,支持视图以及用户自定义的SQL视图,并能够对字段进行自动的维度和度量的划分。
BI引擎:以在数据模型的技术上去解析用户的交互、进行过滤条件和数据筛选,最终生成能够在数据库上运行的查询语句,包括支持数据的筛选,下钻,联动,还可以支持和URL的参数来做联动。
计算引擎:包括表计算,交叉计算、数据格式化,并且在数据层面也能做监控预警和留存分析这样的一些比较深层次的计算。
数据模型
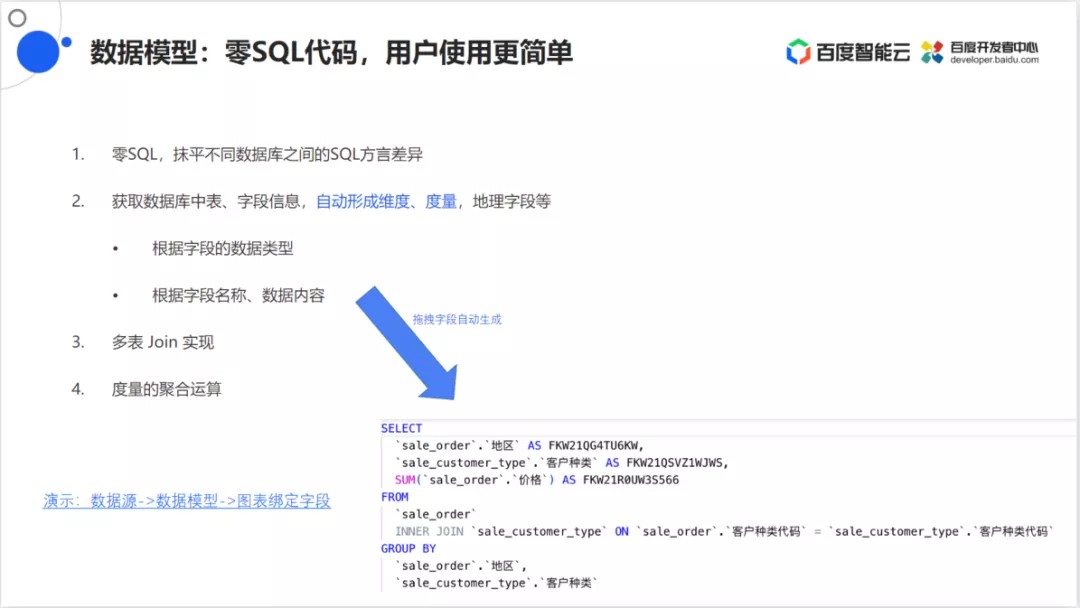
市面上其他数据可视化的平台的缺点是需要用户去写SQL语句,然后将SQL语句查询的结果绑定到图标上,这对非技术的人员非常不友好,因为需要用户懂SQL语句的书写,而且在开发的过程中需要反复的修改SQL语句,这样会导致效率降低。
而在Suger BI产品中,借鉴了BI的做法,将BI与可视化大屏的进行融合。用户是可以选择写SQL语句,也可以通过数据建模将数据通过拖拽的方式绑定到可视化图表上,所以Sugar产品的定位就是一个产品满足两个产品的需求。
总结起来,Sugar数据模型有以下的优势:
- 可以做到用户不需要写任何的SQL语句。
- 可以根据不同的数据源抹平其中不同数据库之间SQL语句的差异。
- 可以在获取数据表字段的时候会自动形成维度和度量的差别,还会自动取识别地理字段。维度和度量的识别策略是根据字段的数据类型,而地理字段是根据字段的名称和数据内容来区分。并且在过程中可以支持手动去调整,可以将度量转化为维度,也可以将维度转化为度量。
- 可以对度量进行常规的聚合操作,其中包括Sum,Average,Max,Min,等。
讲师在分享过程中,以“销售订单数据的展示“为例,演示了建立数据模型、数据可视化等操作。详细步骤可通过:https://developer.baidu.com/live.html?id=13 回顾。
数据雪花模型
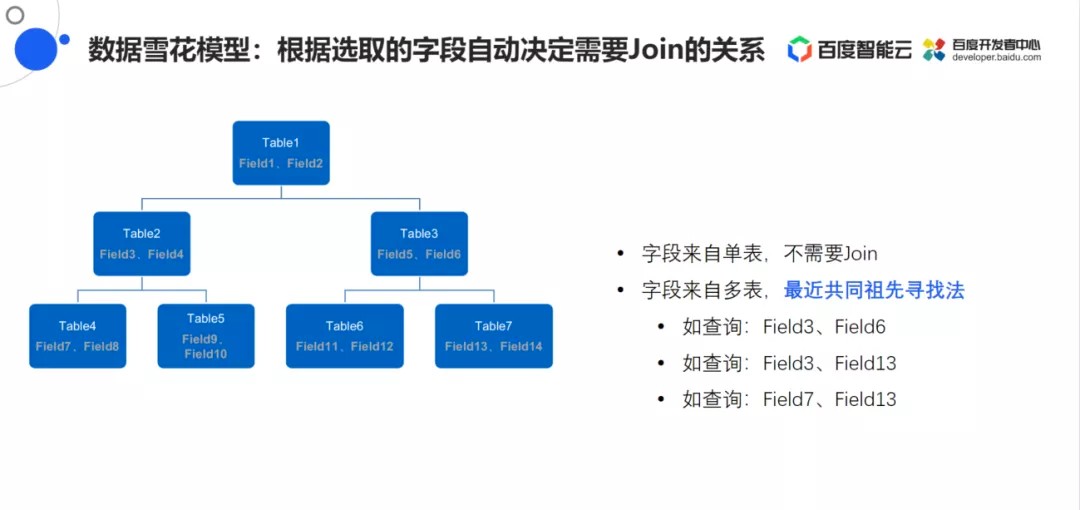
在Sugar中多表的Join使用的是雪花模型,可以自动的根据字段来选择Join的方式。使用最近共同祖先寻找法来解决查询的字段来自多个不同表的问题。
数据筛选
- 满足超复杂场景的Where筛选
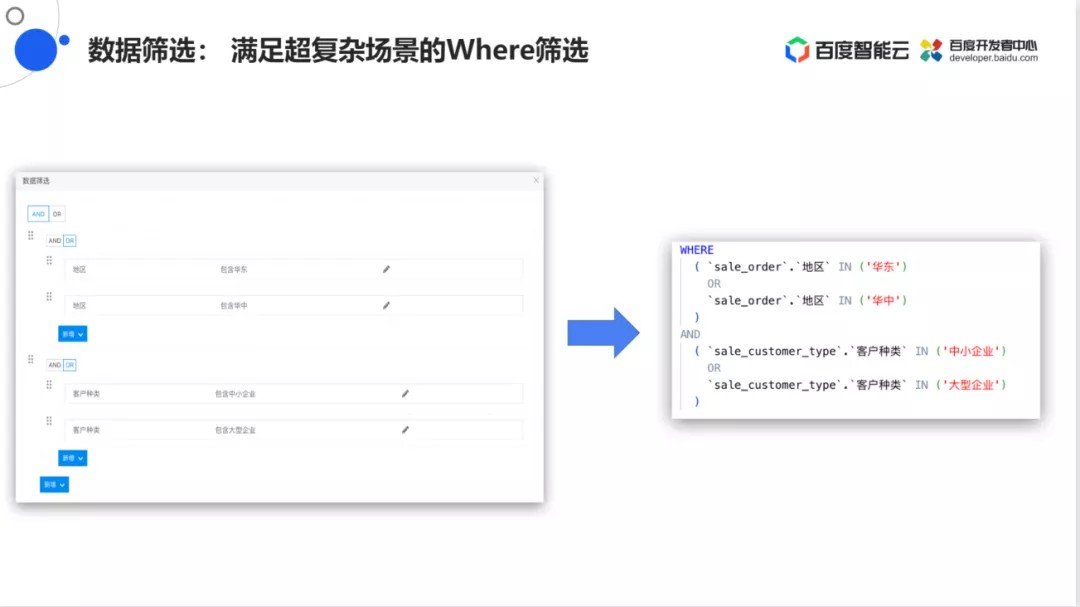
在复杂场景下做SQL的Where筛选,就是要对数据进行过滤,对于右边非常复杂的Where筛选,Sugar设计了左边的功能能够满足用户非常复杂的交互场景。
- 聚合查询后的Having筛选
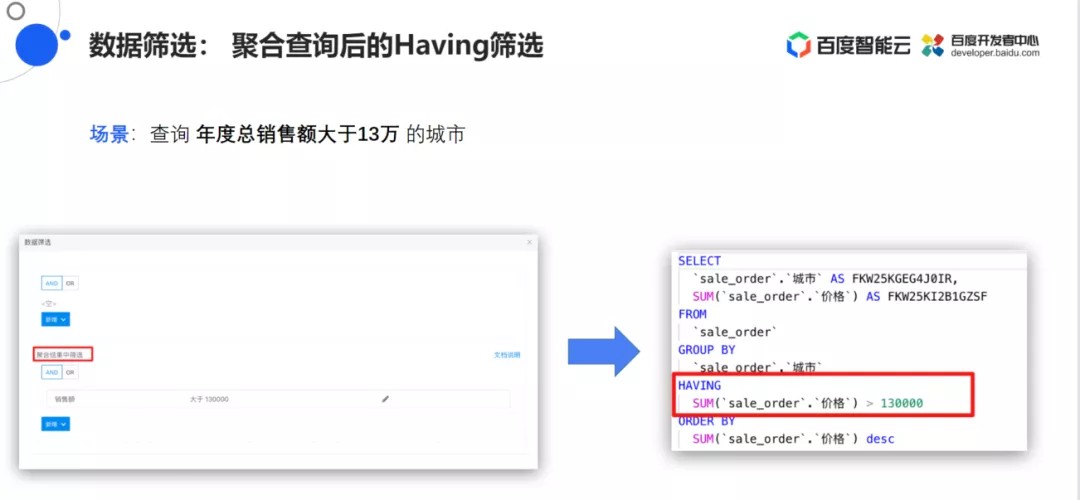
Sugar还支持聚合查询后的Having筛选,例如场景是查询年度总销售额大于13万的城市,对应到SQL语句的Having场景,是对数据聚合后再做一个筛选。
- 过滤组件
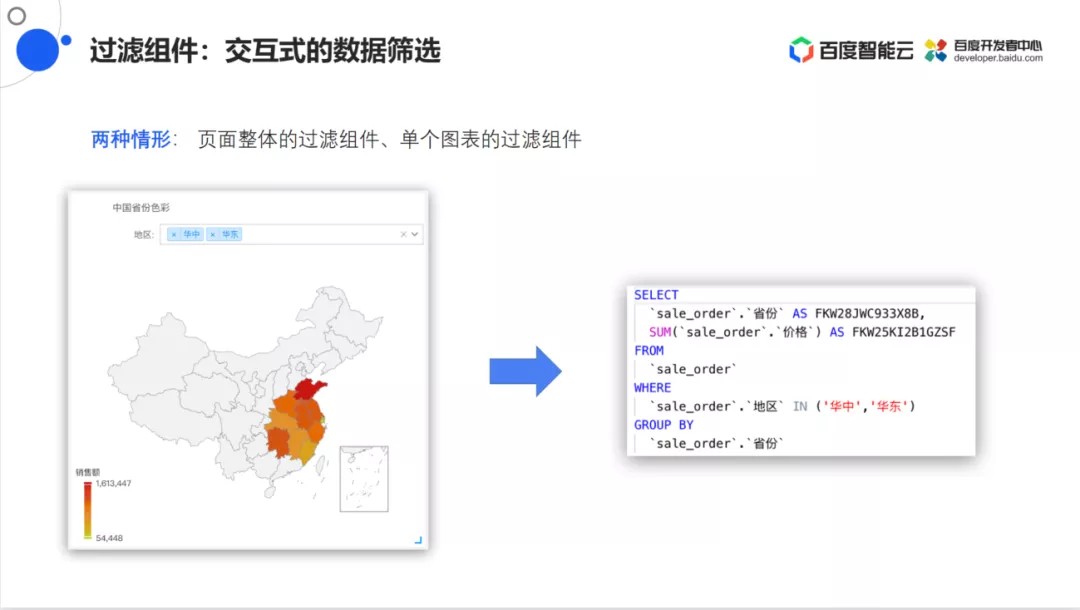
交互式的数据筛选其中分为页面整体的过滤组件和单个图表的过滤组件。
SQL查询层面的数据计算
特点:最终都转化为SQL语句,在数据库层面进行计算。具体可做的计算操作包括:
- 数据格式转换
- 日期时间的聚合计算
- 计算字段
- 分桶分组
二次计算
二次计算是指在SQL查询结果后的再次计算,该计算发生在内存中。具体包括:
- 数据值映射
- 交叉透视表
- 合计、均值
- 表计算、快速表计算
性能优化
- Sugar在性能优化方面做了如下尝试:
- 数据缓存:可以利用Redis,确保同一个SQL只执行一次。
- 针对不同数据源的特殊优化,如Clickhouse的留存计算Retention
- 异步多线程的表计算
03智能图表推荐
智能图表目的
- 根据数据自动推荐最适合的图表类型
- 图表类型的切换
- 作为智能语音交互的基础
智能图表流程
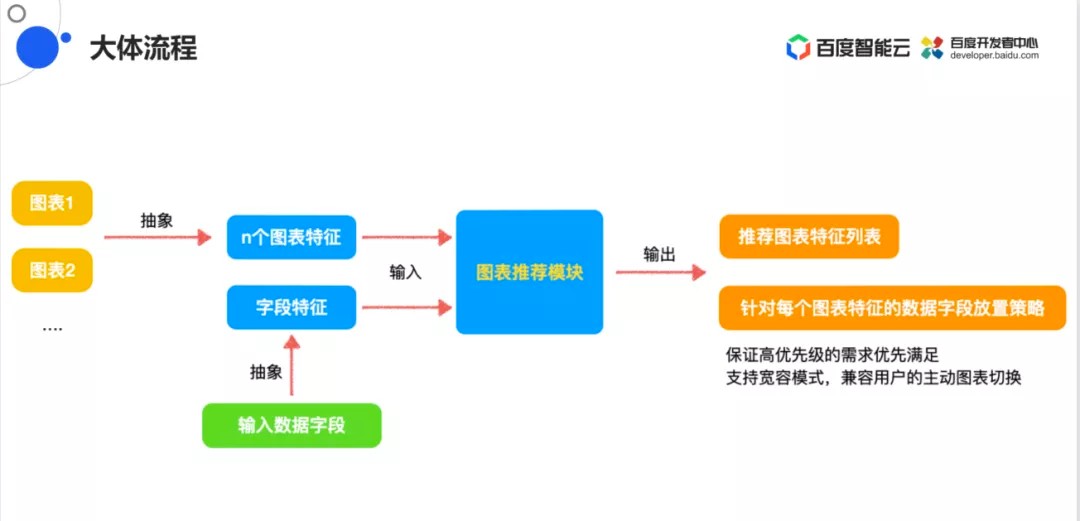
智能图表首先是对系统内部100多种的图表进行抽象,从图表中提取特征。然后在图表推荐模块将图表的特征与当前用户输入的特征做一个匹配,之后推荐的图表有一个列表,并对列表中对每一个图表进行打分,最后进行排名将得分最高的图表推荐给用户。
推荐策略
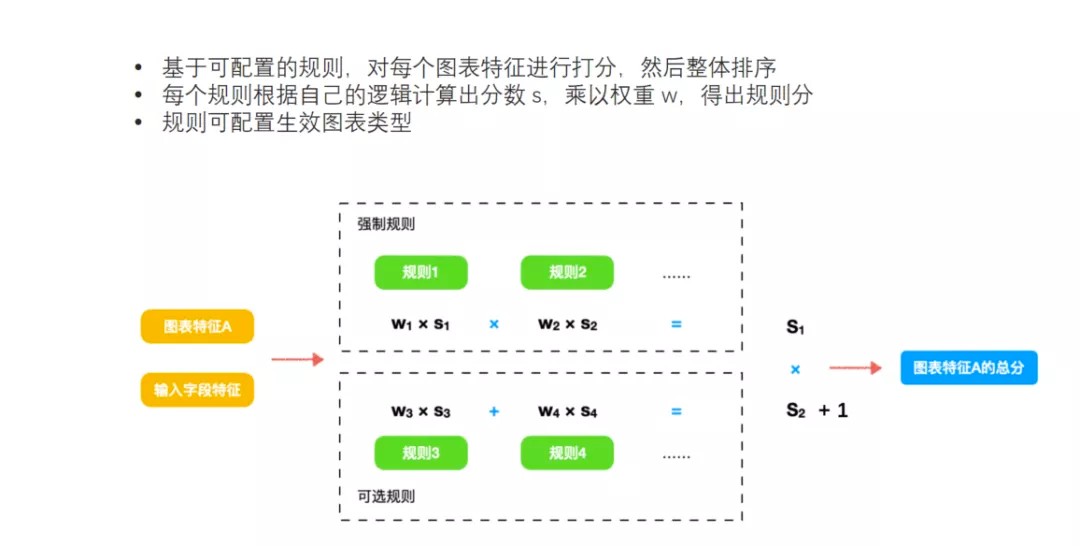
图表推荐策略设计,是针对每一个图标设计的,有两个规则:
第一个强制规则,是必须要满足的
第二个是可选规则,是有这个规则就可以加分。
推荐策略是硬性条件和加分条件的组合,强制规则之间做乘法,可选规则之间做加法,然后在每一个规则里面都会设计相应的权重。
规则设计
强制规则只有一个,就是为了确保用户需要分析的每个字段都能在被推荐的图表中有所体现。
可选规则针对不同的图表就会不一样,它描述的是:
- 计算输入字段特征和图表特征对字段需求的相似程度
- 和日期字段有关的规则
- 和度量单位有关的规则
04智能语音交互
Sugar BI就是要成为可视化BI分析界的智能助理的角色,可以在智能图表的基础上做智能的语音交互。
讲师在分享过程中,演示了报表中的智能问答交互演示,可通过:https://developer.baidu.com/live.html?id=13 回顾。
语音问答整体方案
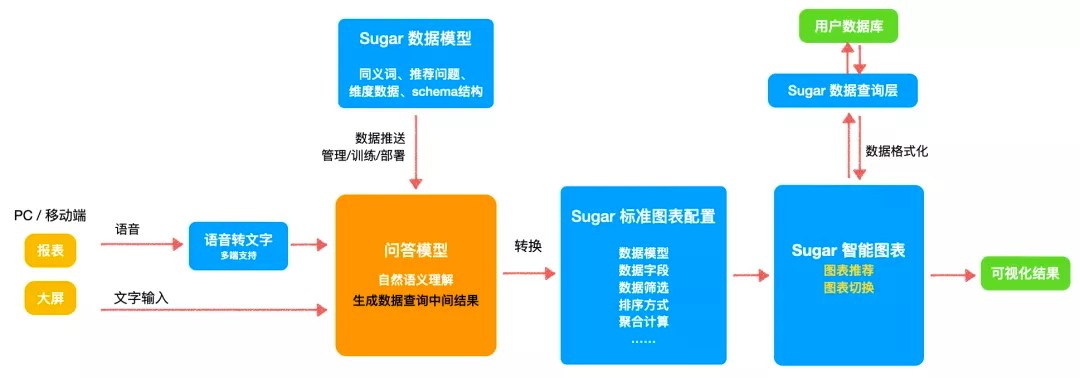
问答模型基于数据模型实现的。数据模型中的同义词、推荐问题、维度数据、Schema结构可以送入问答模型,紧接着问答模型就会做NLU(自然语言理解)将数据模型理解透彻。
在用户问答的模型中包括两种方式:
第一种是可以通过直接的文字输入方式;
第二种是可以通过大屏或移动端的语音输入然后转换为文字。最终问答模型里面是一个文字理解的过程。
问答模型最终的输出结果,会将问题自动理解为要查询数据模型的哪些字段并且要做一些什么样的数据筛选比如:排序、聚合运算,最后通过Sugar智能图表的转换过程最终呈现一个可视化的结果。
05下一步计划及BI未来方向
BI分析的趋势
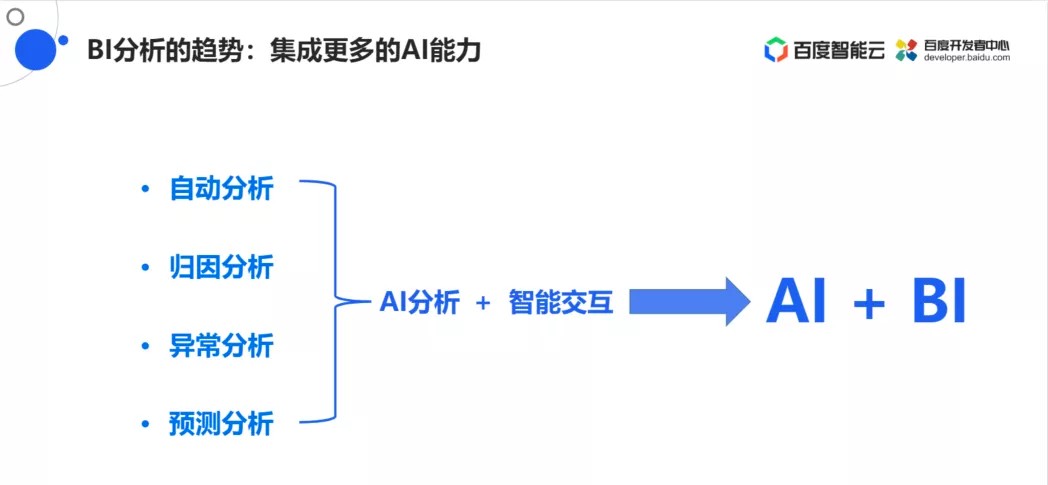
下一步计划聚焦在智能化分析的过程上,主要可以分为以下四个种类的分析:
自动分析:可以根据数据模型,用户只给定一些维度和度量,就可以自动生成可视化的报表或者大屏页面,然后页面中会自动的生成图表,也会自动添加一些过滤组件,最后用户可以在这个效果的基础上做一些可视化的修改。
归因分析:指某一指标发生的较大的变动的时,能够帮用户自动找到是哪些维度引起的,每个维度的分别影响的贡献度是多少,都可以通过归因分析来进行量化。
异常分析:指的是数据发生剧烈变化时需要找到原因,后续会和归因分析一起进行。异常分析一般都是系统主动分析然后自动地将异常报出来,所以会结合数据预警,出现异常的时候就主动给用户发预警。
预测分析:指的是在历史数据的基础上,利用机器学习、AI算法等一些策略,对后续的数据走势做出一定的预测,相当于是一种对未来数据的分析。这样Sugar就能更好的帮助用户总结过去,并且还要展望未来,为用户的决策做更好的数据支撑。
有了AI分析和智能化的交互,百度认为传统BI的发展趋势就是“AI+BI”的能力融合!
以上是老师的全部分享内容,有问题欢迎在评论区提出。
往期推荐
6000字,详解数据仓库明星产品背后的技术奥秘
扫描二维码,备注:大数据开发,立即加入大数据产品&技术交流群。

相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册