我们正在进入大模型认知智能时代,算法工程师将被取代
作者:白桃酱酱2021.12.16 16:27浏览量:839简介:大模型认知智能时代的新架构的思考
原载于公众号:AI 前线
编辑 |邓艳琴
作者 |张家兴
近些年迅速发展的大规模预训练模型技术,正在让机器逐渐具备像人一样的认知智能,但是也对算法、系统、算力提出新的需求和挑战。那么,未来 AI 的架构将会是怎样的?在 11 月举办的 ArchSummit 全球架构师峰会(深圳站)2021 中,IDEA 研究院讲席科学家张家兴博士,与我们分享了他对大模型认知智能时代的新架构的思考,本文整理自此次演讲。

在刚刚得到 ArchSummit 全球架构师峰会邀请的时候,我很惊讶。因为在过往十多年的工作经历中,我做过学术研究,也做过算法专家,可怎么会跟架构师有联系呢?然而后来一想,其实我好像真的跟架构有点关系。因为现在一提起架构,大家必然会谈到大数据架构,而在 Hadoop 这套系统出来之前,我在微软开发这种大数据架构。在现在的深度学习架构出来之前,比如 PyTorch、TensorFlow,我也开发过这样的深度学习架构。所以说,我的过往经历跟架构还是很有渊源的,但是今天我要谈的内容不是这些,而是在当下这个人工智能蓬勃发展的时代,尤其是当人工智能进入了大模型时代,我们的架构到底会发生哪些新的变化,未来的架构又可能会产生哪些大家可能意想不到的一些新的趋势。
大家可能注意到了,我现在所在的单位叫做粤港澳大湾区数字经济研究院,又叫 IDEA 研究院,它是由前微软全球执行副总裁沈向洋院士创办的,聚集了很多像我这样的,兼具学术研究和工业落地经验的专家,我们聚在一起,想要打造一家国际顶尖的人工智能和数字经济的研究院,我们在做一些前沿的技术的研究,同时我们也想推动一些技术的产业落地。
认知智能演进:大模型时代的崛起
接下来进入正题。在讲大模型之前,我想先讲一下整个认知智能演进的范式。
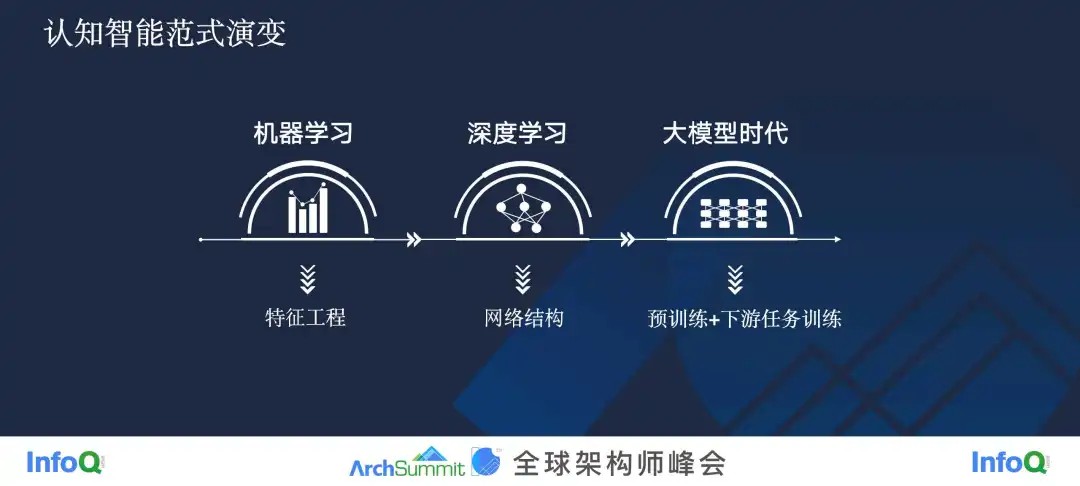
如果我们倒退到十年前,那个时候大家在讨论怎么做一个自然语言系统、图像识别系统或者推荐搜索这样的模型的时候,我们往往会提一个词,机器学习。那个年代的机器学习,其实更多强调的是特征工程,尤其是在推荐搜索这样的场景里,特征可能会非常大。所以经历过那个时代的人应该都知道,当时在机器学习架构中出现了一个叫做 Parameter Server 的新物种,这在当时来说是一个新兴的方向,就是为了应对可能大到几十亿、上百亿的特征规模,给特征工程带来的挑战。
大概就是从十年前开始,我们真真正正进入了深度学习时代,我们不需要人工构建特征,模型可以自动从原始数据中提取特征。这个时候,我们思考的核心问题就发生了转变——我们不再需要去思考特征是什么样的,而是我们该用怎样的网络架构来更好地适应这些原始特征和任务。
这是过去十年、二十年间发生的故事。
大概从去年,尤其是 OpenAI 的 GPT-3 这个事件开始,我们进入了另外一个新的时代——大模型时代。在大模型时代,在做机器学习任务的时候,没有人能从头开始训练一个模型了,现在的范式整个变成了我们要依赖于一个预训练模型,在这个基础之上,我们再去做下游训练任务。
那么什么是预训练大模型呢?主要体现在三个“大”。
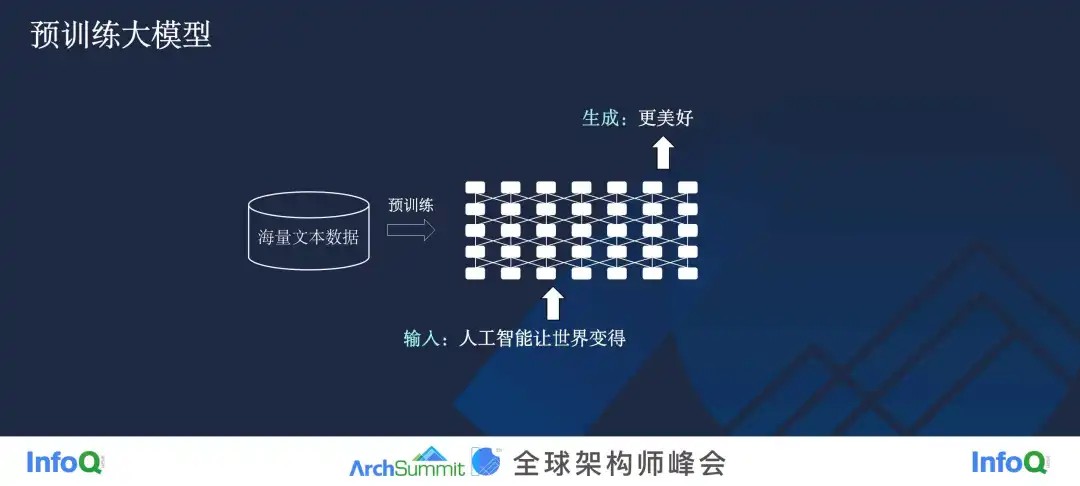
第一,它依赖于大的数据,也就是海量文本数据。
第二,模型比较大,从几十亿、几百亿,甚至几千亿、几万亿的参数规模都有。
这个大模型能做哪些事呢?打个简单的比方,对于一个自然语言的预训练大模型来说,你输入一段文本“人工智能让世界变得”,它能够把“更美好”这段文本给你续写出来。
那么,这样的模型到底能给我们的架构带来怎样的改变?
如之前所说,预训练大模型目前已经变成了整个认知领域机器学习的基础,任何事情都是从预训练大模型开始的,你可以认为它是一个中心的整合,它整合了很多领域的数据,各种各样的下游任务都基于同一个预训练大模型,只需要经过少量的微调就可以满足各种任务。
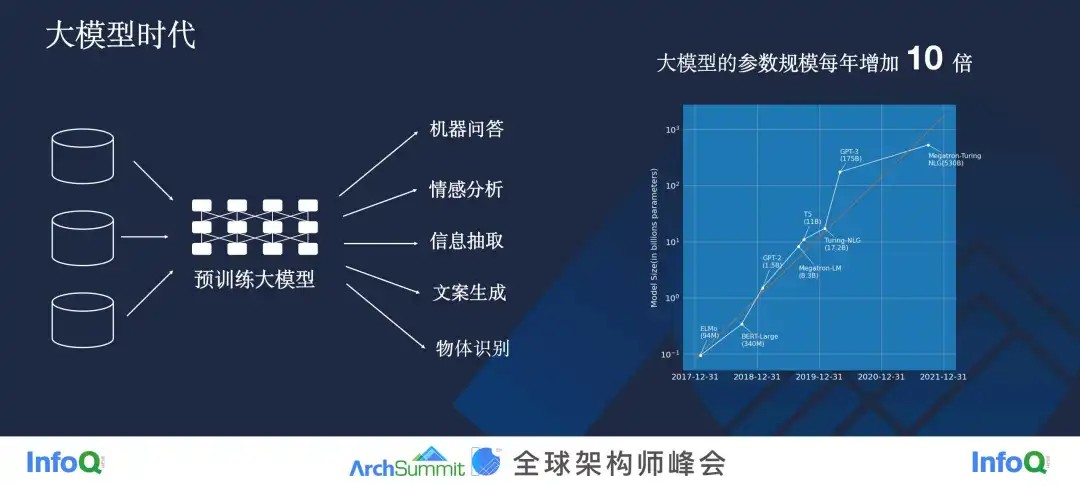
第三,预训练大模型还在变得越来越大。在 2017 年,预训练这个概念刚刚推出来的时候,模型大小只有 96M,而在一两个月前,NVIDIA 和微软共同推出了一个大模型,它的大小达到了 5000 亿,这也就仅仅过去三四年的时间,可见模型规模增长速度之快。通过上图,你将对这一切有更为直观的感受。它的纵坐标是一个指数坐标,你可以看到基本上是每年增加 10 倍。如果我们说芯片领域有 1 个摩尔定律,18 个月芯片的集成规模翻一倍,那么我们到了大模型的时代,这个规模非常的夸张,现在它的模型规模已经变成了每一年要增加 10 倍。
刚刚列出的数据还不是最新的数据,因为最近也有一些团队发布了高达 10 万亿参数的模型。我们可以畅想一下,到了明年,10 万亿参数的大模型会不会就成为主流了?10 倍的趋势到底能够持续多久?这也是值得我们想象的。
大模型到底给认知智能带来了什么?
现在,我们回到一个根本问题,为什么要做大模型,或者说,大模型到底给认知智能带来了什么?
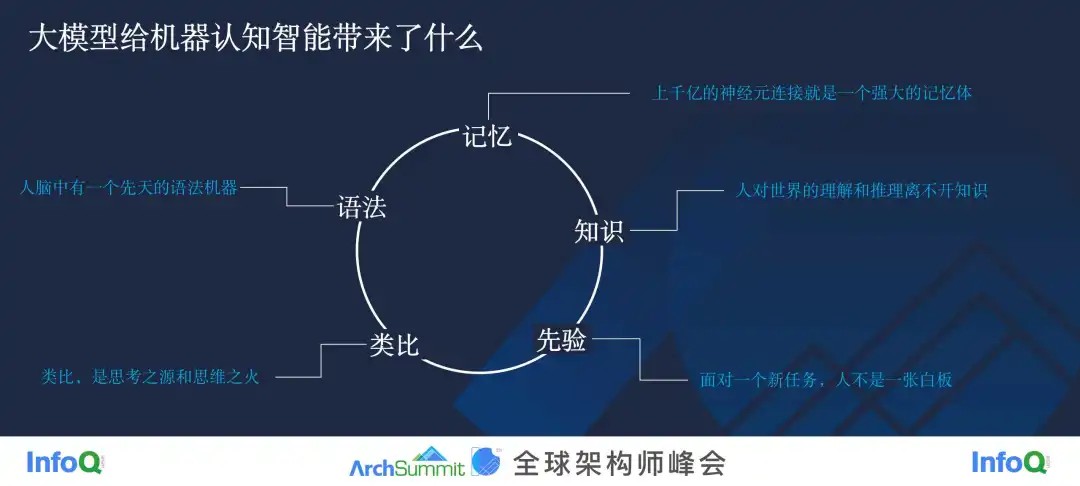
语法、记忆、知识、先验、类比,当这几个词出现的时候,大家可以想一下自己在认知的时候是不是也用到了这些要素。而大模型在这些方面都会带来一些 fundamental 的改变。因为今天我们讨论的不是认知,也不是算法,而是架构,所以接下来我们将围绕记忆、知识、先验和类比这四个方面一起探究大模型到底给 AI 架构带来了怎样的思考。
记忆:模型即数据(Model as Data)
大模型具有记忆能力,它会给我们的架构带来怎样的思考?

我们做了一个实验,我们用 100GB 的文本数据训练了一个含有 35 亿参数的 GPT-2 模型。大家可以看到,在训练数据中有这样一条原始数据,它实际上就是讲利率的。前面我们说大模型可以续写文本,对吗?现在,我们就把原数据的前半段给这个大模型去续写,最后,它生成的文本和原始数据白色那部分一字不差,最让我们惊讶的是大模型还生成了一些原始数据中根本就没有的文本,也就是上图中红色字体的部分,这是原始数据中没有的,但是你会发现数字的增长比例其实非常的合理。
由此,我们是不是可以想到,大模型可以在用户给定一个起始文本情况下,把原来数据中存在的数据 Recover 出来。再进一步想一想,我们如果在硬盘上存储这个数据,顶多可以对数据做各种压缩、索引、引擎,可以更好地访问。但是,既然大模型能够完美恢复出数据,它本身就是参数,比如这一次实验中,原本的数据是 100GB,但是大模型只有 3.5 亿个浮点数,它在一定程度上已经在等价于这个数据,所以,大家可以思考一下到底什么是数据。
我认为,不要管数据的存在形式是什么,只要它的结构是可查询可枚举的,我们就能将之称作数据。也就是说,硬盘上存储的东西可以叫做数据,大模型本身也可以被叫做数据,这就给我们一个很大的启发。
在十多年前,我做大数据框架的时候,都是存算一体,因为当时的网络带宽实在是不够,而处于云时代的今天,网络速度远高于硬盘,所以大家都搞存算分离。模型即数据(Model as Data)最典型的优点是存算一体,那么我们现在如果用大模型来做的话,它就是另外一种意义的存算一体。也就是说,在大模型里边,一切数据都是用模型参数和模型结构来表示的,它相当于是一个黑盒,你不知道这个数据到底是怎么存的,也不知道它是怎么查询出来的,我们真真正正地把查询跟计算混在了一个大模型里边。
用大模型来存数据,有一个特点就是比较模糊。我不只可以查询出已有数据中存在的信息,还可以查询出一些数据中不存在的信息,甚至不必用原始的文本去查。
模型即数据(Model as Data)还有一个特点是检索高效。试想一下,如果让你去高效查询 100GB 的数据,你肯定要建一个 ElasticSearch 索引,为了更好的效果,你同样可能要用一些文本相似度的模型。但现在有了存算一体的大模型,只要算一次,数据就出来了,我们就可以告别以往的先召回再精排的复杂过程了。
我给这种存储起了个名字,叫 Impression Store,印象存储。这个词实际上不是我新造的,大概七八年前,我在一篇 Paper 中提出过 Compressive Sensing,用压缩感知技术做了一个这样的 Impression Store,但是现在我想把这名字借用在大模型上面,它不是一个精确的存储,却可以比精确存储更好。
知识:模型即知识(Knowledge as Model)

接下来我们要聊的也很有意思,知识。同样的,我们又来看一个例子。
我们找了 50GB 的医疗领域文本,训练出一个 35 亿参数的 GPT-2 模型。这个模型训练只训练了 7 天,完全没有任何人工干预,我们全交给了算力。
大家可以看到,我们第一个输入的文本是“我得了流感,症状是”,得到的输出是“发烧、咳嗽、头痛、肌痛、喉咙痛、鼻塞和头痛。”第二个输入文本是“流感的治疗方法是”,输出是“抗病毒药物扎那米韦、奥司他韦和拉那米韦。”经查询,这些答案都是正确的。你看,这个模型已经开始对理解知识并且可以回答你的问题了。
再来看更有意思的一件事情,大模型可以做一些原本知识图谱可以干的事,比如实体关系判定。你给一个三元组,扎那米韦、可以治疗、流感,它们的关系是可以治疗。然后,你可以构造两个文本,一个叫可以治疗,一个叫不可以治疗,送到大模型里边去看它们各自成立的概率,这个概率我们用 PPL 来表示,也就是困惑度。困惑度越低,表示这句话越有可能成立。我们看到,“可以治疗”的 PPL 是 62,“不可以治疗”是 79,说明可以治疗的概率更高。而现实里,“扎那米韦可以治疗流感”这个事实确实是成立的。
这是一次初步的定量化的实验,而我们在某些关系判定上的准确率可以做到接近 90%。在这个过程中,我们只是把文本灌进去了,没有构建任何的知识图谱。其实,哪怕是知识图谱,准确率想做到 90% 也不是一件容易的事。所以我就提出了下面的一个观点——模型即知识。
过去的十几年,为了让机器理解并使用知识,我们花了很大的人力物力去做知识图谱,这里面需要很多复杂的算法。今天,我们有一个机会去重新思考,到底要不要做知识图谱,是不是可以用大模型来代替知识图谱?
所以,我在这里提出了一个新的概念叫做 Knowledge as Model,模型即知识。这样的知识大模型就跟前面提到的数据大模型类似,实际上就是把知识的存储、表示、查询和推理都整合到一个大模型里面,这也是一种存算一体,甚至可以说是存算表示推理一体。这就是大模型可能给知识带来的改变。
先验:用计算追上几百万年的差距
先验也是人的认知中很重要的一个方面,因为人是在有先验的情况下才去做认知的。同样,我们又做了一个实验。我们把一个自监督预训练模型,经过有监督预训练,生成了一个通用模型,这样的话,有监督运行链就相当于是一个先验。在经过先验之后,我列出的三个 ZeroCLUE 零样本学习任务都有了不小的提升,而且这三项任务在 ZeroCLUE 榜单上全部排名第一。
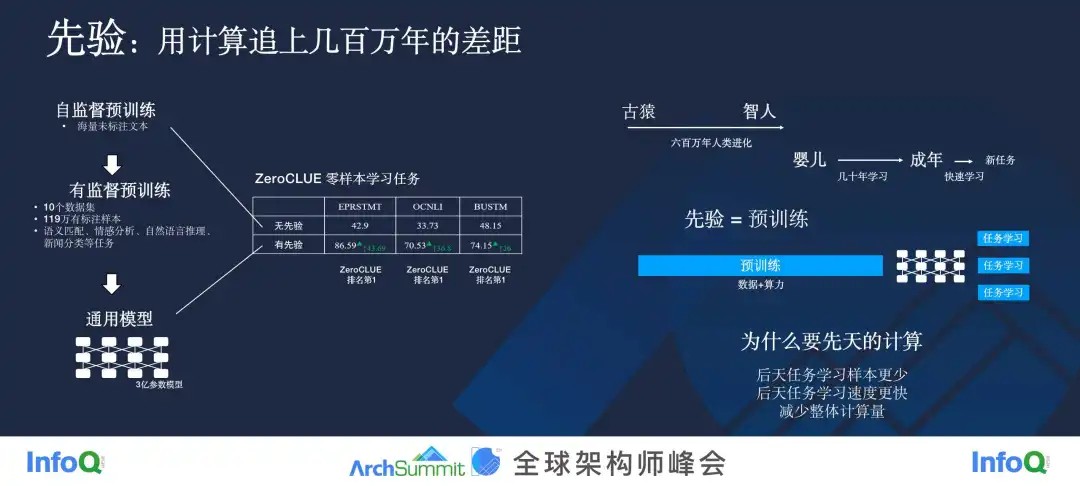
你看,针对这类自然语言理解任务,对大模型进行一定的先验之后,它可以表现得有多么的好。
人之所以有这么强的学习能力,可以通过很少的样本甚至是不通过样本,只要你给我描述一下任务是什么,我就能学会。这里面一个很重要的原因就是人的大脑不是一个白板,从古猿到智人,我们经过了 600 万年的进化,再加上一个人出生之后得到的后天的学习,所以当你面对任何一个新任务的时候,你都已经有了很多先验。而整个预训练的逻辑就在于我们要在见到任务之前就要把先验灌到模型里去,这就是我们想做的事情。

基于这样的想法,我们还做了一些更进一步的工作。就在最近,我们 IDEA 研究院发布了一个 13 亿参数的预训练大模型,它有一个很中国化的名字,二郎神。
这个大模型在中文小样本学习 FewCLUE 榜单上获得了第一名,其中两项任务全部超越人类,三项任务刷新了最新的记录。它的每一个分类任务,我们都只给大概几个或者十几个样本。人拿到这一点样本可能都学不会,但我们的大模型却可以学得比人更好。
类比:突破数据稀缺瓶颈
最后一个对架构的思考是类比。不知道大家有没有意识到,你在思考自己的认知过程的时候,其实你的大脑一直在做着类比,所以目前的认知智能研究中有一个观点就认为类比才真正是人在认知中的最基础的能力。
如果没有了类比,我们根本就没法说话。举个例子,我说“这个指标上升了”,“上”这个字就是一个类比,因为你在用空间的概念去解释数量的概念。放到人工智能里面,我们做一个文本分类器,就是根据样本之间的相似度去做划分,这是一个类比过程。
大模型在这方面也有很好的表现,我们可以拿它来做样本的生成,尤其是相似样本的生成。
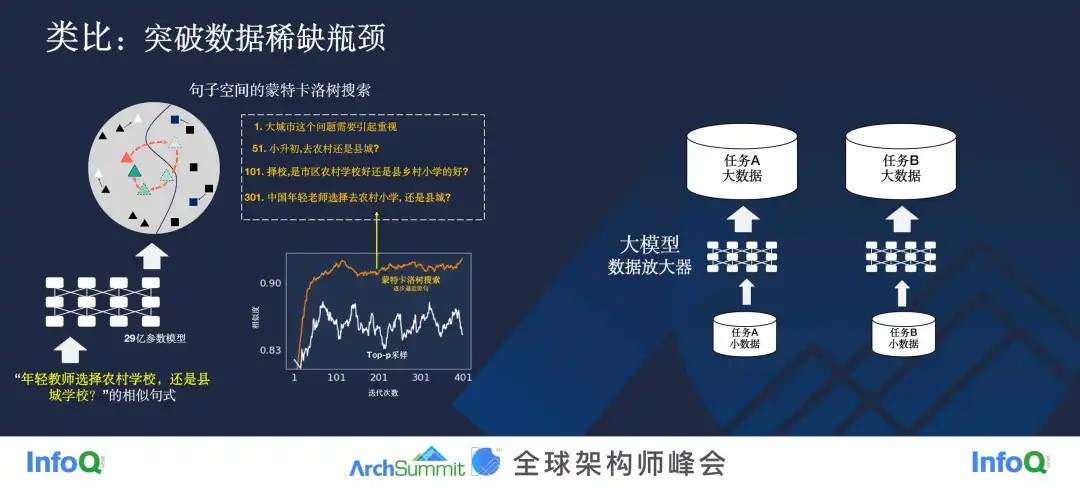
上图左边展示的是我们做的一个实验,我们用了一个 29 亿参数的模型,输入了一句话——“年轻教师选择农村学校,还是县城学校?”的相似句式,这个模型就会续写出它的相似句。因为大模型可以输出很多句子,我们要在这个很大的句子空间里挑出最好的,所以我们做了一个蒙特卡洛树搜索,让句子生成的质量越来越高。我没有把它生成的 300 多个句子都列出来,只列出了中间几个采样,但你可以在上图中看到,最开始它生成的句子还跟输入的句子很不一致,但是到了第 300 多句的时候,它生成的“中国年轻老师选择去农村小学, 还是县城?”跟我输入的句子已经很相似了。
我们做这件事的目的是什么呢?我们想把大模型当做一个数据的放大器。
其实,数据在很多场合都是非常稀缺的,如果你是做架构的,尤其是涉及到数据的方面,对这一点应该深有体会。以前大家经常会说,所谓的人工智能,就是有多少人工就有多少智能,所谓的机器学习,就是先标数据再去训练模型,但是在有些场合下,你想标数据都没数据,连 Unlabeled Data 都没有。在这种情况下,我们可以用刚才我说的相似样本生成,你只要给我少数的样本,我就可以给你生成更多的数据。
也就是说,我们可以用大模型来解决数据稀缺的问题。
在大模型出现之前,大家可能从未想过大模型可以代替数据和知识,甚至可以代替知识图谱,而大模型在加了先验之后,效果可以极大地提升,大模型甚至可以做数据放大。这些新东西的诞生也导致我们做机器学习的认知智能的方式发生了改变。
GTS:大模型时代的机器学习新框架
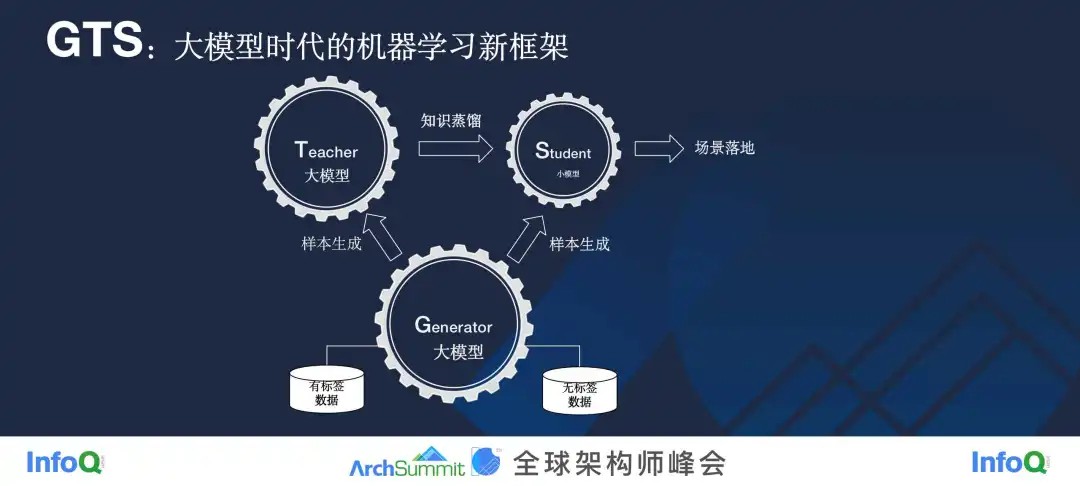
因此,我们提出了一个概念,GTS,即大模型时代机器学习的新框架,Generator,Teacher,Student,三位一体。
Generator 在最下边,用于接收用户给的数据,无论这些数据是有标注还是无标注的,Generator 都会把它放大,生成更多的样本,让一个数据稀缺的问题变成数据丰富的问题。它上面还有一个 Teacher,这也是个大模型,负责做 Few-shot Learning,即使给很少的样本,也能把任务学习得很好。而 Generator 和 Teacher 存在的意义就在于它们会帮助 Student 小模型更好地学习。小模型一方面从 Generator 大模型接收更多的样本,另一方面,它会对 Teacher 进行知识蒸馏,最后,我们把 Student 模型作为落地场景去上线。这里面,Generator 和 Teacher 可能都很大,有几十亿、上百亿的规模,但 Student 就很小了,我们可能会选用 1 亿参数以下的模型。
我们相信,这就是目前大模型时代应该有的机器学习的方式,我们可以有大模型,它并不是最终给用户用的,而是作为生产小模型的一个手段而存在。
新范式:从机器学习到学习机器
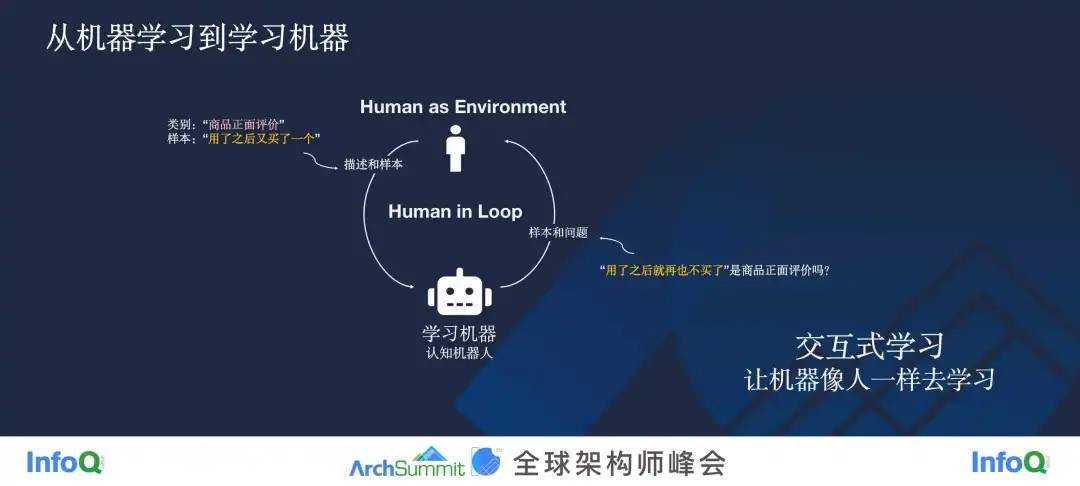
再往后走的话,利用这些技术,我们会进入怎样一个新的范式?我认为是从机器学习到学习机器。那这句话怎么理解呢?
如前文所述,大模型可以生成样本,但它自己也不是特别确信这个结果是否正确,那它完全可以去询问用户。比如,用户给了一个分类任务,类别叫“商品正面评价”,但是这个用户可能就给了一个样本“用了之后又买了一个”,我们知道这是正面评价,但是机器不知道,因为商品正面描述是一个很复杂的东西,不是简单的情绪分析,所以它会懵掉,这到底这是一个怎样的类别,怎样的任务呢?然后这机器就可以根据用户输入的样本“用了之后又买了一个”,生成一句话“用了之后再也不买了”,接着,它去问用户,这是商品正面评价吗?用户可以回答还是不是,然后就形成了这样一个闭环。
那么,我们站在机器的角度来看,这时候人变成了一个环境,是机器在向人这个环境学习。机器学习算法在表现上倒很像是一个机器人,作为一个 Agent 在跟环境做交互,所以我把它叫做学习机器,甚至我会给它起个名字叫做认知机器人,把这种学习方法叫做 Interactive Learning,交互式学习。
只有做到这样,我们才能真正让机器像人一样去学习,这是我们整个业界一直在追求的目标,也是我们 IDEA 研究院的目标。
大模型落地的本质性瓶颈与解法
前面说的是大模型可能给未来带来的一些改变,接下来,我们必须谈谈大模型的落地问题,这里同样也有很多有趣的架构上的思考。
阻碍大模型落地的最本质性的瓶颈无非两样,一个是算力,一个是人才。目前,全球对环境问题的关注与日俱增,中国也提出了碳达峰碳中和的双碳政策,在这样一个目标下,我认为,算力在未来一定会成为一个瓶颈,不可能有大规模的建设,因为它一定会跟我们的双碳形成严重的冲突,这是一个很严重的瓶颈。而人才就更不用说了,人才的培养不是一朝一夕的事情。为了解决以上问题,我们给出了两个方案。
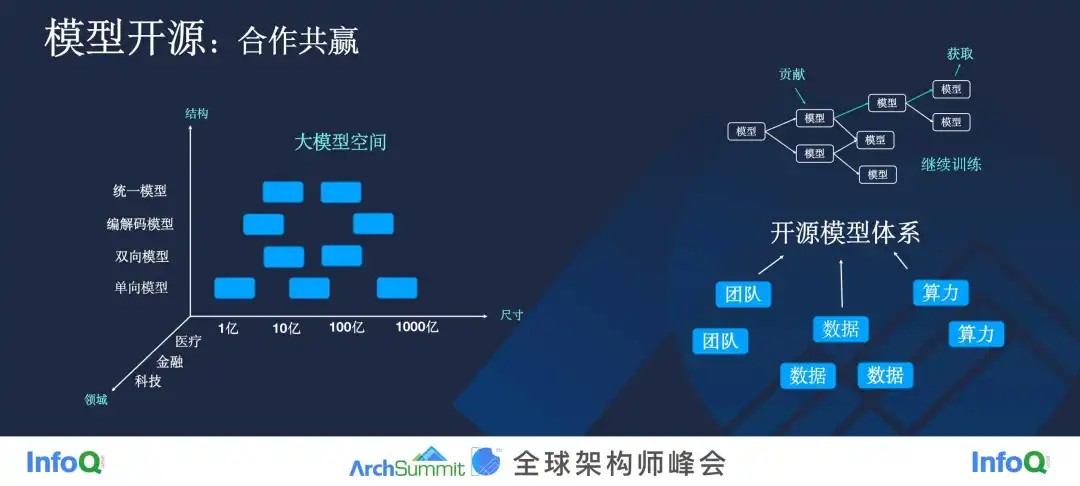
一是坚持模型开源。 大家对代码的开源很熟悉,但模型的开源完全是一个新的模式,一个新的世界。我们可以把所有大模型放在一个空间里边,它们有不同的尺寸,也有不同的模型参数,也有不同的领域。我非常倡导大家一起构建一个大模型的开源体系。在这个体系下,我们每个人都把模型开源出来,当你做一个新的模型的时候,不需要从头开始训练。
当然,很少有大模型能够适用于所有场景,在某一个具体场景下,可能还是需要一些特有的大模型,比如说现在已经有一个医疗大模型了,但我是一个制药公司,想要一个跟制药相关的大模型,它跟医疗大模型非常像,但还是不一样。那么,我完全可以把一些制药相关的文本喂到这个医疗大模型里去训练,没有必要从头开始训练。
如果我们能形成开源体系的话,每个人只需要贡献自己很少的经验、数据和算力,我们就能让大模型开源体系长得更大。相当于我可以站在前人算力的基础上,甚至说站在前人数据的基础上,去训练模型,然后我再把这个训练好的模型开源了,放在这里面,后人就在我的基础上做继续训练,他可能训练出一个比我当年开源的模型还好的大模型。所以说,开源就是一种合作共赢。
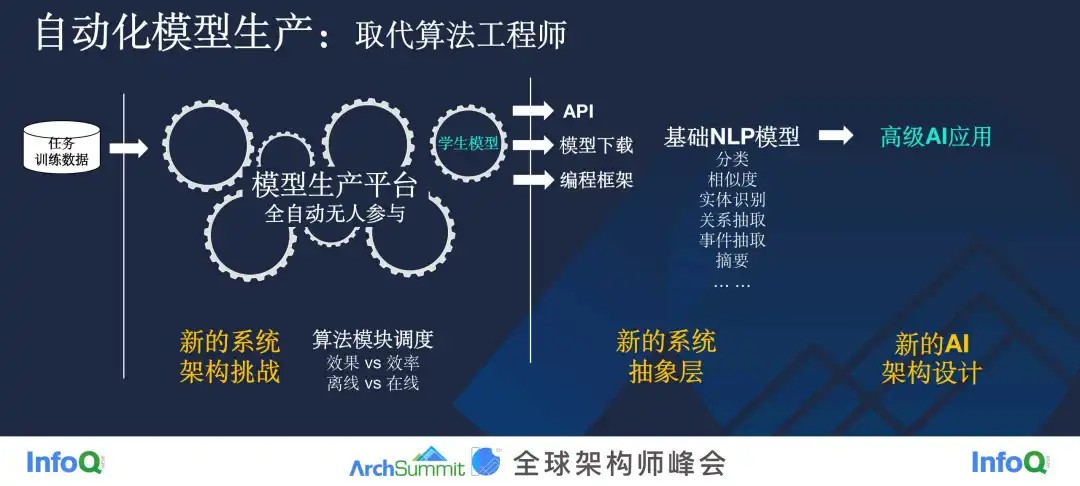
二是自动化的模型生产,这是从人才的角度去考虑的。我这个副标题看起来非常耸人听闻,直接就叫做取代算法工程师。
既然人才这么短缺,我们能不能不要所有的算法都让算法工程师来做,我们能不能做一个模型生产的平台,真正实现一个全自动无人参与的模型生产流程?
基于 GTS 的架构以及交互式学习架构,用户只需要提供很少的任务训练数据,整套系统就能自动生产出一个学生模型,你可以通过 API 访问,可以直接下载,也可以通过一些编程的接口去生产出你想要的学生模型。通过这个平台,我们可以生产一些基础的 NLP 的模型,比如文本分类、文本相似度、实体识别、关系抽取、事件抽取、摘要,等等,只要你提供数据,那它就会针对你的具体任务生产出你想要的模型,让你可以构建高级的更上层的 AI 应用。
这个过程其实也存在着不小的挑战。
第一,自动化模型生产平台架构上的巨大挑战。 因为这里有众多的算法模块,很多算法模块其实本身就是大模型,运行起来消耗的算力非常大,而它最终要生成达到用户要求的模型,在这个过程中,我要如何调度这些算法模块,如何权衡效果跟效率之间的关系?
如果说的用户给的数据,不需要通过 Generator 生成样本就可以训练得很好,那 Generator 是不是就不需要工作?但是你怎么知道你不需要?如果 Student 已经训练完了,你才发现不好,难道要再让 Generator 工作吗?还是说 Generator 就无条件地生成样本?而 Teacher 作为一个大模型,它的学习也要消耗很多算力,那到底要在什么条件下它才工作,它跟 Student 模型之间又是什么关系?
这里边是一个非常复杂的世界,可能会存在多个 Teacher 模型,多个 Generator 模型,其实我更愿意管它叫做一个生态。我们要思考的问题就是,在这个算法的生态中,要如何用最少的算力就能达到我们想要的效果。
第二,AI 领域所特有的离线和在线的问题。 预训练模型显然是一个离线的事情,在具体任务出现之前,我已经离线训练好了所需要的模型,真正到了任务来的时候,我再去在线地 Fine Tone。同样,在模型生产平台里边,我们尽量把一些工作放在离线来做,因为离线的东西是可以共用和分享的。比如,我们离线做好了几十个、上百个预训练模型,再看到底哪个预训练模型更适合,你就在哪个基础上继续训练。
当年,在英特尔出 8086 之前,即使是个人计算机的 CPU 也有非常多的厂家在做,但是最后 x86 这个体系基本上成为个人电脑的一个标准了,可以说,CPU 就是一个新的系统抽象层。而现在我们也想做同样的事情,构建一个新的系统抽象层。模型生产平台其实是把认知智能的偏基础的部分做成自动化了,不仅可以节省人力,甚至也能节省算力。这样的话,无论是底层的基础设施的建设,还是上层的应用系统搭建,成本就降下去了。
未来 AI 新架构
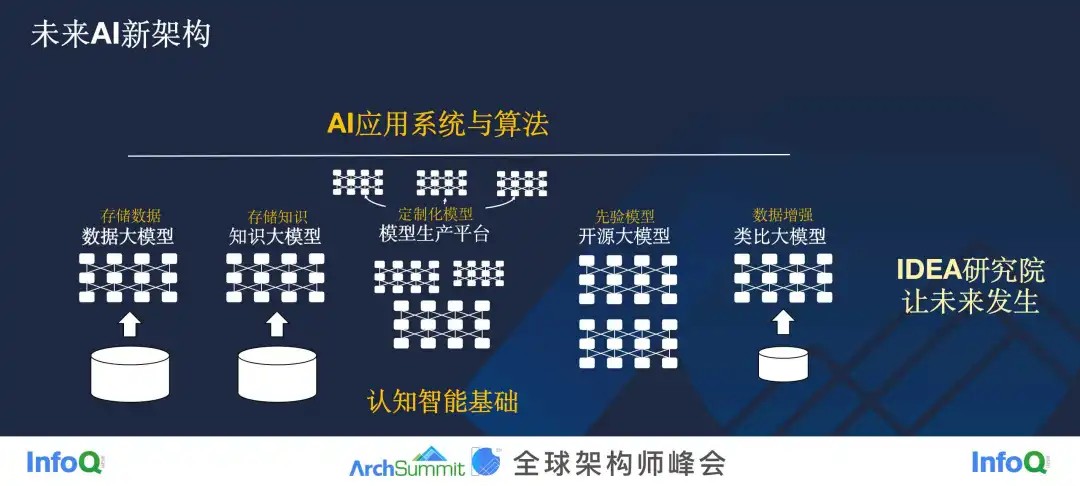
接下来,又引出了一个问题,结合我们前面所讲的内容,那未来 AI 的架构应该是什么样的?
大家可以思考一下,最上层是不是应该就是 AI 应用系统与算法,在它下方的依赖里,我们是不是真的可以不在磁盘里按照 Byte 存储,而是在大模型中靠 Parameter 去存储?是不是真的不需要花费那么大的人力去做知识图谱或者是其他的一些知识结构化,而是把知识直接塞到大模型里边,让它变成一个知识大模型?我们能不能让业务直接在模型生产平台上直接去生产他想要的模型?我们能不能有一个开源的大模型体系,它蕴含了各种不同领域、应对各种不同任务的先验模型,我们需要先验的时候可以直接取用?我们能不能在一些数据稀缺的场景下,利用大模型来增强数据,解决数据本质上的稀缺问题?
这都是正在发生的一些事情,在这些支撑之下,我们真的是要对 AI 架构进行一些新的思考。当大模型给整个架构带来冲击的时候,我们是不是能有一些新的做法?
我们 IDEA 研究院也是在研究整个认知智能的基础部分,以上内容也是我们正在研究的一个方向。我们希望能和业界所有志同道合的朋友共同努力,尤其在开源这个事情上共同合作,一起让新的未来发生。
作者简介:
张家兴博士,IDEA 研究院讲席科学家,认知计算与自然语言研究中心负责人。北京大学博士毕业,曾任微软亚洲研究院研究员、蚂蚁金服资深算法专家、360 数科首席科学家。在自然语言处理、深度学习、分布式系统、物理等领域的顶级学术会议和期刊(NIPS, OSDI, CVPR, SIGMOD, NSDI, AAAI, WWW…)上发表二十几篇学术论文,提交七十余项专利。是大数据框架、深度学习框架、深度学习算法的早期开创者,目前正在带领团队探索基于大规模预训练语言模型的下一代认知智能技术。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册