百度搜索中台海量数据管理的云原生和智能化实践
作者:萧萧慕雨2021.12.17 19:05浏览量:1848简介:通过海量数据管理的云原生和智能化,我们希望低成本的实现让用户找到每一个有价值的数据。
导读:百度搜索中台将搜索核心能力赋能阿拉丁(百度搜索特型结果)、垂直领域搜索、应用内搜索等场景,支撑了数百个检索场景、百亿级内容数据的检索。我们通过智能化的设计理念,在容量自动调整、数据按需存储等方面取得了效率和成本的显著收益,并通过进阶云原生的设计,在海量数据和海量检索方面实现高可用和高性能。通过海量数据管理的云原生和智能化,我们希望低成本的实现让用户找到每一个有价值的数据。
一、背景
1.1 背景简介
百度搜索中台支持的业务线多、业务层面的差异性很大,使得数据的管理、存储和计算的成本,对检索架构形成巨大挑战。比如传统模式下的业务接入,我们要人工评估数据规模进而设计合理的在线部署方案、实现合理的成本,但是业务很难知道自己的数据规模、或者在较短时间内数据有了数倍的增长,需要人工调整部署方案,这个不仅周期长、人力投入大,也会导致稳定性和效果方面的风险。
为了高效支撑众多业务内容数据的接入、迭代,我们设计了云原生时代的内容数据智能架构,通过数据管理的智能化实现人工维护效率的极大提升,并实现按需分配优化成本;在海量数据的检索下,实现高可用和高性能,用创新技术保障用户体验。
本文的主要内容集中在下图中的中间部分: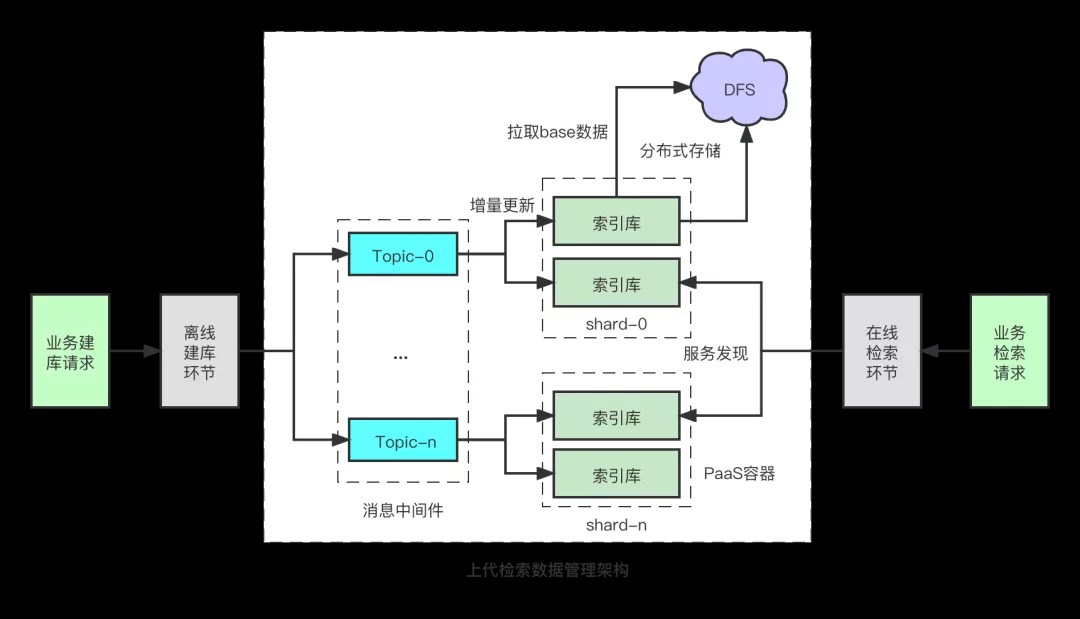
大致流程如下:
- 业务经过离线建库环节产出建库包,并生效到消息中间件中。
- 业务内容数据(比如索引数据、正排数据)按大小拆成相应的分片服务,并通过订阅分片映射的消息Topic数据,实现流式更新。
- 每个分片由PaaS容器承载,启动时从DFS拉取对应的存量数据,并定时将数据持久化上传到DFS中;并从数据中间件读取增量数据,从而实现有状态服务的云原生。
- 业务检索请求通过PaaS层面的服务发现,检索对应业务的内容数据。
和其他业务场景不同,我们搜索业务的特点主要有:
- 存储/计算难以分离:搜索场景的高性能、低延迟要求,计算和存储难以拆开专项优化,需要本地化的存储+计算。
- 全扇出的并发模式:搜索场景是Query到Doc的映射,需要经过语义解析、构建检索表达式、扇出所有的分片服务、合并结果,而常规场景下的Key/Value查询,可以通过Hash关系实现精准的扇出。
- 最终一致性保证:副本间没有通信,通过消息队列增量更新方式,保证秒级别的最终一致性。
1.2 上代内容数据管理架构存在的问题
上述架构很好的完成了PaaS化、自动化运维的历史目标,但随着新业务的接入和存量业务的迭代深耕,差异化/高频化的内容数据需求场景,给这种偏静态模式下的管理架构带来了极大的挑战,具体体现在:
- 效率方面:偏静态模式下的容量调整,需要人工调整数据的分布、分片的大小、扇出的规则,往往需要周级别甚至是月级别才能完成,越来越高频的容量调整需求,使得上述架构无法在效率层面继续满足业务的需求。
- 成本方面:部分业务具有多种场景的内容数据,不同场景的数据访问频度差异是巨大的,静态的数据管理架构难以实现资源的按需分配和rebalance(再平衡)。
- 稳定性方面:单业务数据量级由亿级别突破至50亿级别,全扇出模式下需要扇出数百个分片服务,极大扇出带来的是可用性的急剧下降。
- 性能方面:关联计算(比如join操作)需要上游多次检索查询&合并,性能层面难以满足业务的延迟要求。
为了解决上述问题,我们以云原生化的思路对上述架构进行了改造,通过弹性伸缩和按需分配机制来解决效率和成本问题,然后基于云原生之上引入数据调度策略来解决稳定性和性能问题。
二、整体架构设计
2.1 架构概述
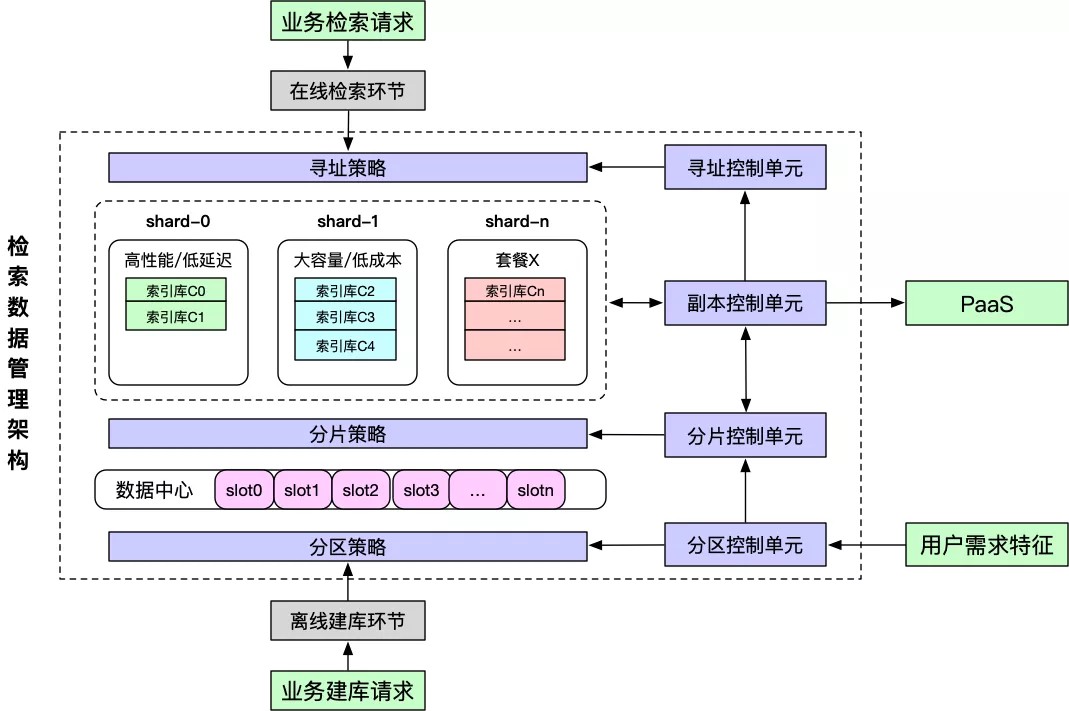
名词解释:
- 分区(slot):数据管理的最小单元(比如一组索引数据),进一步抽象和拆解上代架构中关于消息中间件Topic的概念。
- 分片(shard):承载一组slot数据的引擎服务。
- 副本(replica):分片中的一个实例。
- 套餐类型:预定义的一系列标准化的容器资源规格(比如存储类型可选用RAM/SSD/DISK等介质),满足各类检索场景对资源的匹配诉求。
架构核心组成:
- 分区控制单元:根据业务场景和内容数据的特征,控制建库时的分区策略,比如按某特征汇聚(实现关联计算)、某维度打散(实现冷热分离)等等。
- 分片控制单元:根据检索场景的数据量,控制所需要的分片规模,实现分片的容量调整。
- 副本控制单元:根据检索场景的资源诉求、流量、性能要求,控制分片所使用的套餐类型和副本个数,同时对接PaaS系统,实现套餐资源池的管理。
- 寻址控制单元:根据业务的分区策略和分片策略,结合数据slot层面的服务发现机制,实现数据层面的动态寻址能力。
2.2 核心工作流程
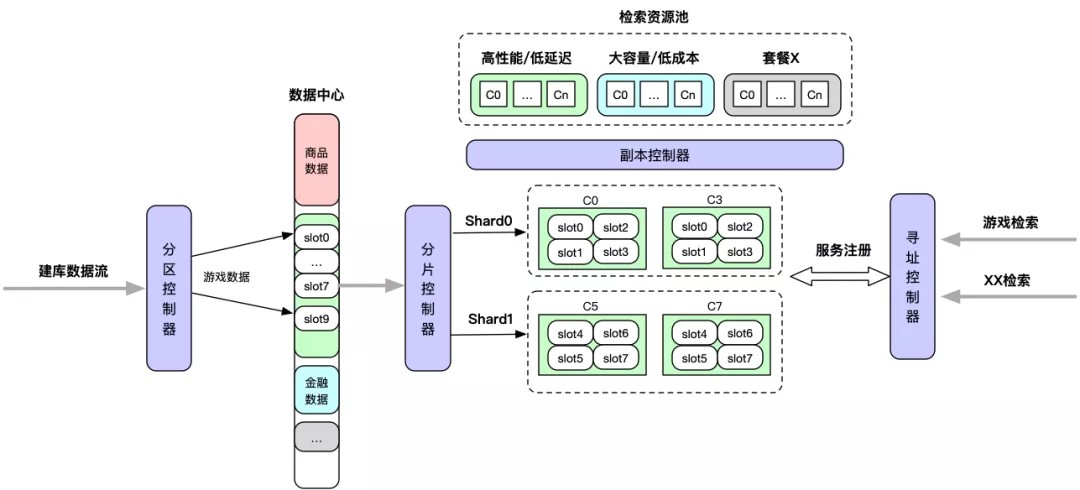
- 评估业务检索场景和内容数据的特征等,生成相关控制策略,比如分区策略、分片策略、副本策略、寻址策略。
- 内容建库数据通过【分区控制器】写入到数据中心。
- 【分片控制器】初始化分片的服务信息,比如分片的个数和要管控的数据分区等。
- 【副本控制器】根据副本策略和分片策略来分配实例、注册服务。
- 【寻址控制器】实现数据层面的服务注册和发现机制。
- 业务通过【寻址控制器】来访问相应的内容数据。
三、云原生化设计
针对容量调整效率低下和冷热差异大导致的成本浪费问题,我们以云原生化的思路对上代架构进行了改造,实现了数据的弹性伸缩和资源的按需分配。
3.1 弹性伸缩机制设计
弹性伸缩包括垂直伸缩和水平伸缩,各自特点简介如下:
- 垂直伸缩:调整物理硬件配置的方式,来增强系统的弹性,比如调大容器的资源配额、更换ssd等。
- 好处:速度快、操作简单等
- 缺点:容器迁移&故障恢复周期长、有瓶颈问题(天花板较低)。
- 水平伸缩:调整副本数来应对流量、数据量的涨幅情况。
- 好处:天花板足够高。
- 缺点:实现困难、门槛较高。
垂直伸缩受限比较多,我们采取了水平伸缩方案,针对搜索场景下如何实现水平伸缩呢?
3.1.1 针对流量上涨场景下的水平伸缩
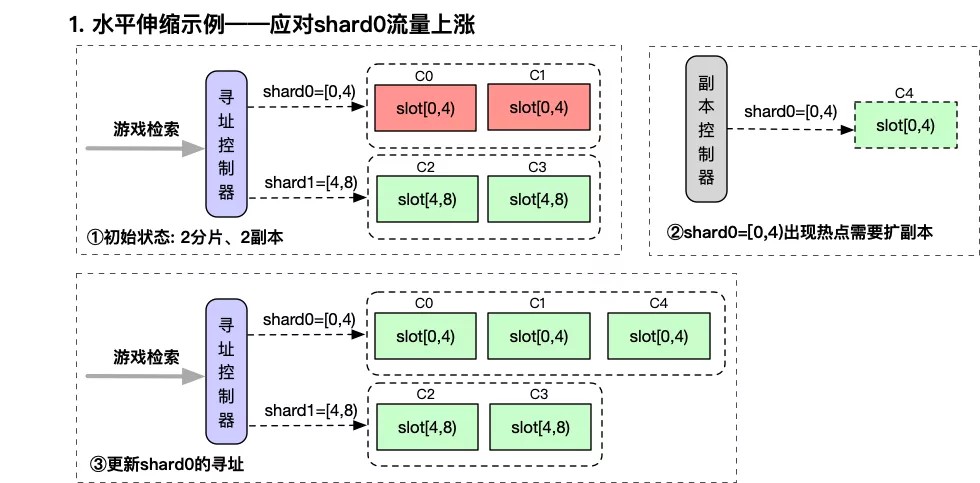
由于最终一致性的前提约束,可以通过增加shard-0副本数的方式,实现水平扩展。
3.1.2 针对数据量上涨场景下的水平伸缩
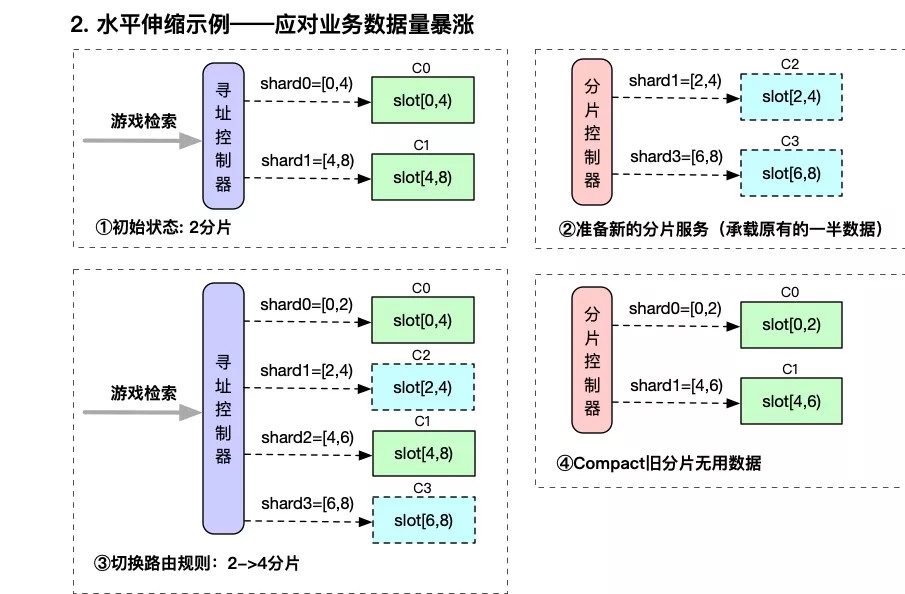
- 系统检测到分片服务容量达到阈值,或者人工发起容量指令,比如游戏检索数据由2分片调整为4分片。
- 分片控制器计算调整后的分片需求,并初始化新的数据分片所绑定的数据区间,shard1=[2,4)、shard3=[6,8)
- 寻址控制器通过服务发现机制,感知到分片调整&新分片服务ready后,开始更新路由规则,由2分片调整为4分片。
- 路由切换后,开始清除旧分片无用的数据,shard0=[0,4) -> shard0=[0,2)、shard1=[4,8) -> shard2=[4,6)。
通过上述流程实现了数据量上涨的情况下,分片原地扩容的方案。
3.1.3 实际效果
通过自动化的弹性伸缩能力,实现了业务数据流量、容量快速变化场景下的极致伸缩,容量调整由周级别降低为小时级。
3.2 资源按需分配机制设计
资源按需分配机制常常出现在离线计算领域,由于它对延迟不太敏感、更注重吞吐,目前有一些比较成熟的解决思路。但对延迟和性能要求比较苛刻的在线检索领域,如何实现资源的按需分配呢?我们目前的解决思路是冷热数据的分离。
3.2.1 冷热分离机制实现资源的按需分配
搜索业务一般包含多种检索场景(比如问答场景、推荐场景等等),每种检索场景的数据量和检索性能特征不尽相同,关键特征如下:
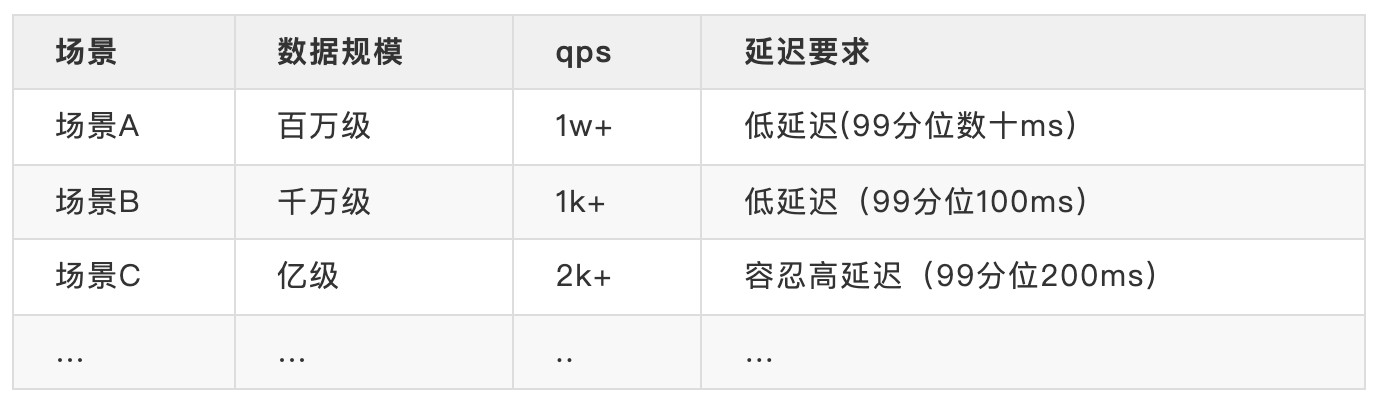
根据业务场景特征决策的数据分布和寻址情况如下图所示:
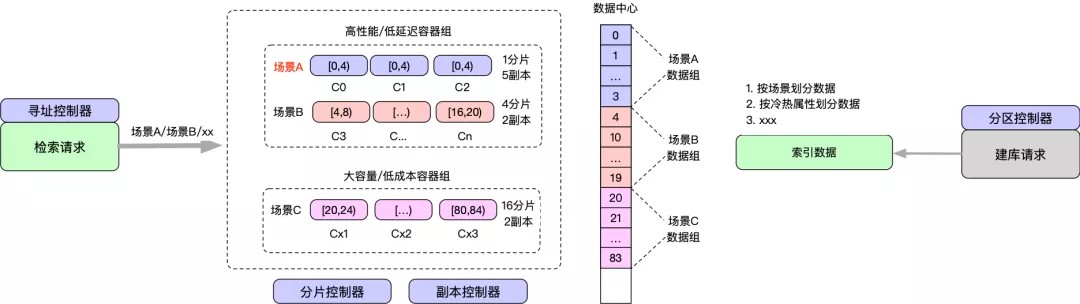
- 【分区控制器】根据业务的数据特征规划数据的分布,比如按冷热属性、按场景属性等,场景A分布在[0,4)、场景B分布在[4,20)。
- 【分片控制器】根据数据规模、拉链长度等特征确定分片规模,场景A划分1个分片,场景B划分4个分片。
- 【副本控制器】根据数据访问qps和延迟特征,挑选不同存储介质和副本数,场景A&B选择高性能/低延迟容器组,场景C选择大容量/低成本容器组,场景A需要5副本,其他仅需要2副本。
- 【寻址控制器】提供业务不同场景数据的服务发现能力。
- 通过冷热分离机制 & 结合业务检索特征,选择相应的资源套餐,实现资源的按需分配。
3.2.3 实际效果
业务平均节省成本30%,典型业务场景下可节省成本80%。
四、进阶云原生
通过云原生化的改造,我们解决了上代架构面临的效率和成本问题,对于极大扇出带来的稳定性问题和典型场景下的性能退化问题,我们的解决思路是引入数据调度策略:控制检索数据分布和计算方向,实现最大化的精准扇出和本地化的计算加速。
4.1 精准扇出数据调度策略
搜索场景是Query到Doc的映射,全分片扇出的并发模式。对于超大规模业务来说,需要划分众多的数据分片,全扇出模式下会带来一些稳定性问题,比如业务A需要划分100个分片,每个分片的服务可用性是99.99%,在全扇出模式下,整体可用性只有99.99% ^ 100 ≈ 99%。
为了解决上述问题,我们设计了精准扇出数据调度策略,针对极大扇出的业务检索场景,抽取业务检索的通用特征(比如按用户ID、按店铺ID),控制数据的分布和计算方向,实现大规模检索场景下的精准扇出。
4.1.1 解决极大扇出带来的稳定性问题
以店铺内检索场景为例,其场景特点如下:
- 业务特征:检索数据均带有店铺ID标识、用户请求是按照店铺级别搜索,整体数据量级十亿级。
- 检索请求:
- 查询某个店铺的商品
- …
- 建库请求:
- 某个店铺商品信息的更新
- …
精准扇出调度策略示例如下:
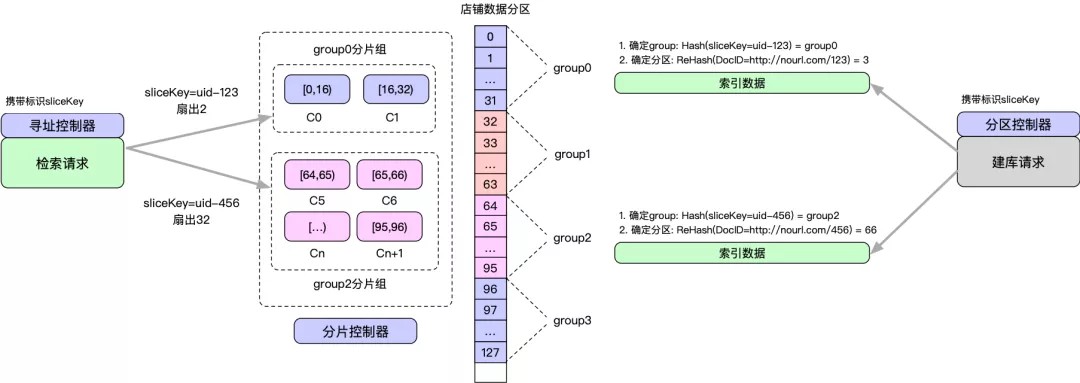
- 【分区控制器】根据业务携带的uid信息,划分数据分区并写入到数据中心,根据sliceKey=uid-123确定group0数据分区组,再根据DocID在group内再次均分数据。
- 【分片控制器】根据各个数据分区组的容量等情况,划分数据分片。比如分区组[0,32)容量小,只需要2个分片服务就能承载所有数据,而分区组[64,96)则需要32个分片服务承载所有数据。
- 【寻址控制器】根据业务携带的uid信息,确定对应的分区组group,并路由到对应的分片服务组。
4.1.2 实际效果
对于店铺内检索场景来说,由数百层的扇出规模,降低为32层扇出,部分情况下可降低为2层扇出。
4.2 本地化计算数据调度策略
针对具有关联检索的场景,抽取关联属性的特征(比如用户和商品的连接关系),业务对具备关联属性的数据携带相同的标识,使得相关联的数据内聚化,从而实现计算的本地化。
4.2.1 直播带货场景下的关联计算问题
什么是关联计算?对于数据库领域来说,关联计算=Join操作,对于检索场景来说,关联计算=检索到A条件情况下,再用A的结果检索B。检索场景常因数据量级的问题,需要触发多次分布式的检索,容易造成延迟突增的性能问题。
以直播电商搜索场景为例,其场景特点如下:
- 业务特征:主播可以选择多个商品售卖,商品能被多个主播带货,主播量级在十万级,商品量级在亿级别。
- 检索请求:
- 查询某个主播所带货的商品列表
- …
- 建库请求:
- 商品的属性变更
- 主播的信息变更
- …
为了支持搜索场景下的主播商品关联需求,一般有如下两种方案:
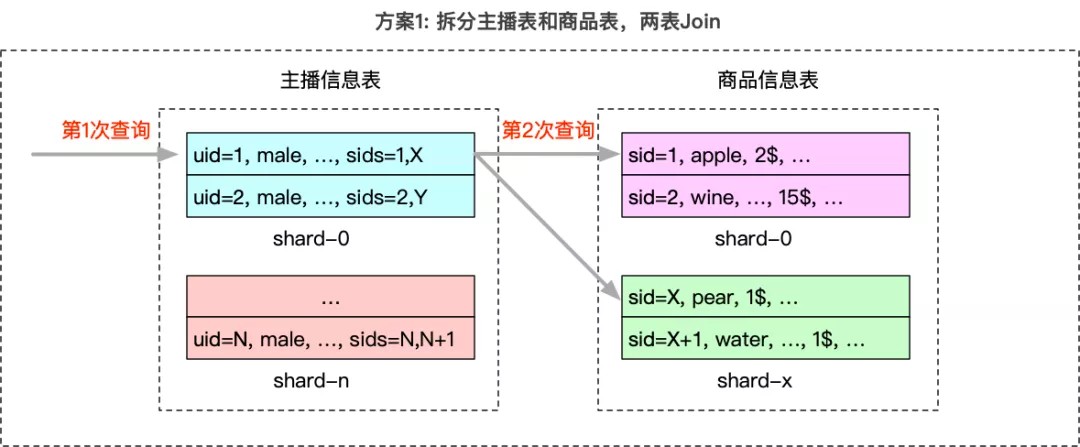
- 拆分两张表:主播信息表和商品信息表
- 主播查询商品:需要先查询主播信息表,再查商品信息表。
- 缺点:需要2次分布式检索,延迟较高。
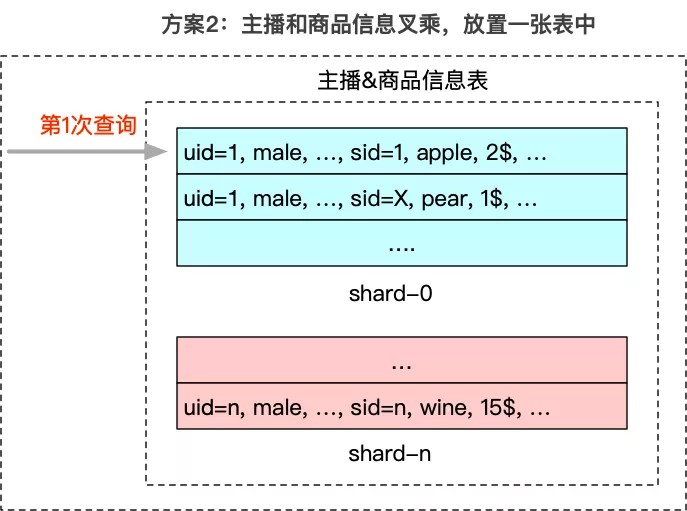
- 只保留一张表:主播信息和商品信息进行叉乘
- 主播查询商品:只需要查一张表
- 缺点:成本浪费严重,更新困难(热门商品更新情况下,需要同步更新10W+主播,延迟不可接受)
4.2.2 本地化计算优化带货场景关联计算的性能
我们的解决思路是将关联数据内聚化,实现计算的本地化,从而优化检索性能,如下图所示:
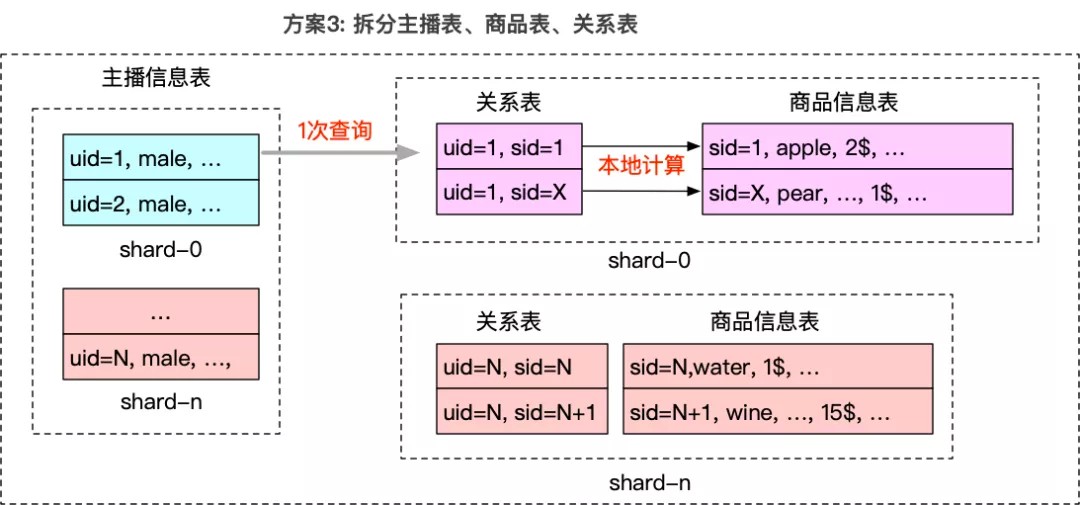
- 建库侧:对于需要关联的关系数据和商品数据携带相同的特征标识,比如sliceKey=sid-1,
- 分区控制器:根据直播带货的关联分区策略,确保关联数据的数据分区是相同的(内聚化)。
- 分片控制器:相同分区的数据被规划到相同的分片服务中(索引计算服务),实现关联数据的本地化和计算的本地化。
- 检索侧:携带特征标识sliceKey=sid=1定位数据分区,通过寻址控制器找到对应的分片服务。
4.2.3 实际效果
- 通过本地化计算,解决了直播带货场景下因分布式检索Join带来的性能下降问题,平均延迟降低50%。
- 提供了一种关联计算速度优化的思路。
五、总结 & 展望
本文以百度搜索中台上代检索数据管理架构面临的问题为出发点,基于云原生设计了数据智能化的弹性伸缩和资源的按需分配,解决了效率和成本方面问题。除此之外,在云原生之上引入了精准扇出和本地化计算的数据调度策略,解决了稳定性和性能方面的问题。
目前业务数据冷热属性评估成本较高,并且随着业务迭代其冷热属性也在不断变化,重新调整需要一定的周期和成本。后续我们会尝试自动化挖掘业务数据的冷热特征和引入更多的目标优化的特征因素,期望在多目标特征因素的约束情况下,最大化程度实现搜索场景下资源的按需分配。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册