深入理解Rocksdb
作者:翟文杰2021.12.30 15:33浏览量:1877简介:深入理解rocksdb
简介
作者简介:翟文杰
TODO:
- rocksdb的KV实体bit图。
- SST中index数据结构。
- block cache的数据结构。
- manifest文件的结构。
- 预写日志WAL的文件结构。
- 掉电后WAL如何恢复memtable内容。
- 合并写入过程与实现。
巨人肩膀:
Optimizing Space Amplification in RocksDB (CIDR 2017)
Characterizing, Modeling, and Benchmarking RocksDB Key-Value Workloads at Facebook (FAST 2020)
rocksdb源码快速跳转
https://github.com/facebook/rocksdb
https://github.com/facebook/rocksdb/wiki/RocksDB-Overview
rocksdb简介
rocksdb是什么?
RocksDB is an embedded, high-performance, persistent keyvalue storage engine developed at Facebook
抓关键字,embedded,kv存储,高性能,Facebook开发(雾)。最初看到这个embedded,以为rocksdb可以用于嵌入式开发平台上的,其实它有更高级的意思。
例如,rocksdb可以作为mysql的存储引擎,替换掉innodb引擎。但是需要提前将mysql中的表转换为kv实例存储,一个开源工具myrocks就是干这个事情的。除此之外,facebook许多存储系统也均采用rocksdb作为存储引擎。如用于存储图片元数据的分布式强一致性存储ZippyDB、专为人工智能机器学习服务提供底层存储服务的UP2X。
这或许就是embedded的真正含义。
rocksdb整体架构
先来看一看rocksdb的整体架构。
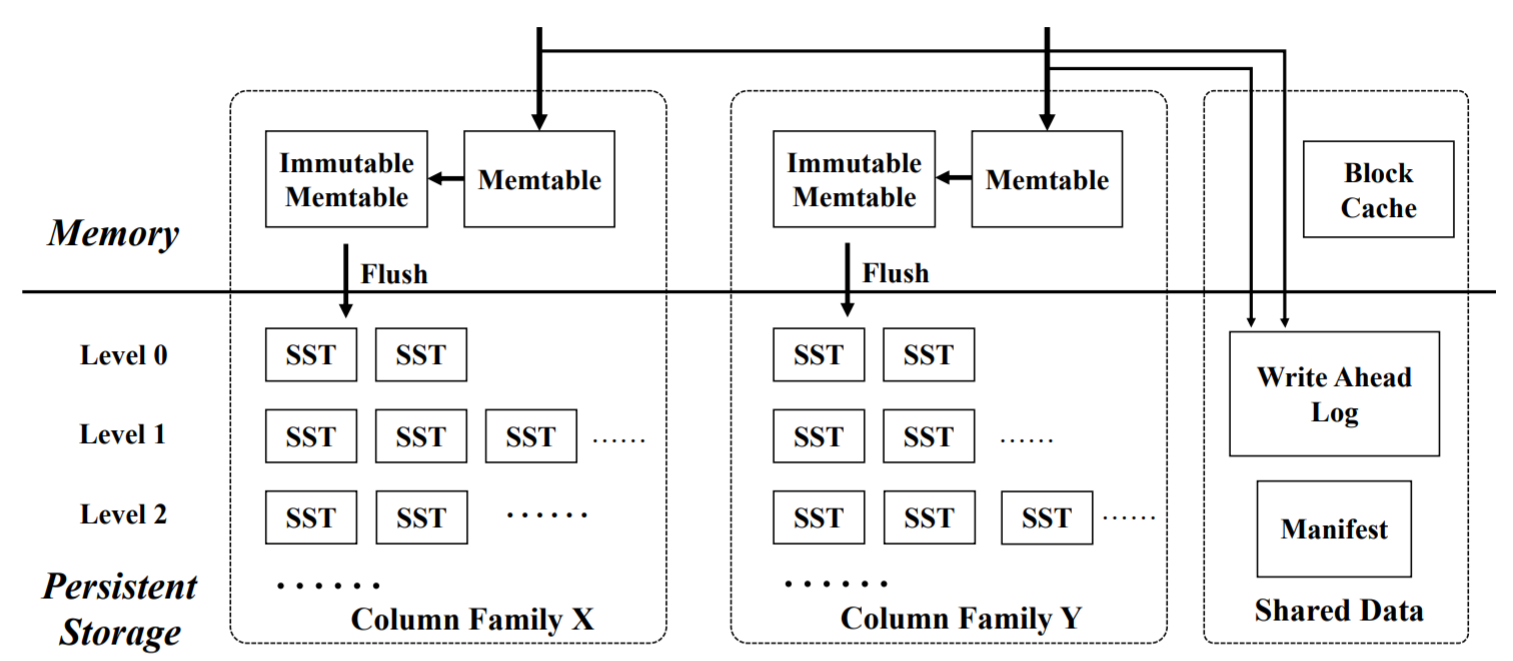
SST:即Sorted Sequence Table,在rocksdb中,所有kv对都被组织为SST文件的方式进行存储。
Memtable:内存数据结构,常常用跳表实现,用于快速查询kv对。至于为什么常用跳表实现,因为value不定长,跳表用规整的slot链可以达到近似的二分查找。另外,在mysql页内存储表数据的时候,也是使用到了跳表一样的结构。
Immutable Memtable:人如其名,不可写的memtable,准备被flush到存储介质上。
WAL:写前日志,几乎DB都会采用的容灾方式。因Memtable中的数据并不是会立即被flush到存储介质上(让memtable承担随机写),因此memtable中的数据是易失的。所以任何一个写操做前,都会先将这个操做记录到wal中,用于恢复memtable中的数据。另外,mysql中innodb的redolog也是干这个的。
Mainfest:记录所有sst文件的元信息,在查询中使用。这个文件的内容通常会被cache,用于快速查找。当然当SST文件发生改变,需要修改元信息的时候需要写存储介质(随机小粒度写)。
Column Family:RocksDB 3.0后的新特性,暂未查询具体做什么用的。但以我有的经验来推断,这玩意儿是用来提升性能的。即rocksdb引擎内部存在多个可读写实例,一个CF就是一个可读写实例。在每次要写入KV对的时候,要么就是将key hash一下看是哪个CF接收,要么就是KV实体数据中只要额外增加CF标签决定这个KV去哪里。阿里的polarDB引擎也存在多个可读写实例。
rocksdb中的SST文件
放大一个SST文件,其长相如下图所示。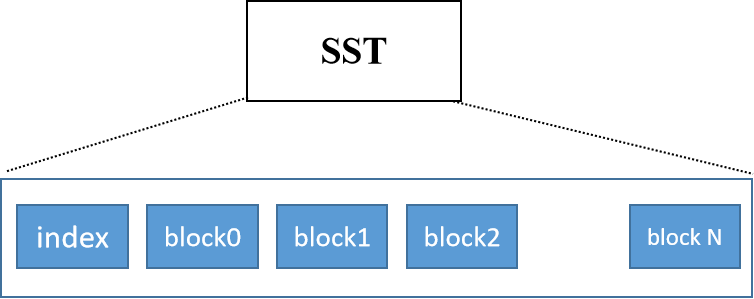
每一个block通常为16kb大小,block有序存储,index用于二分查找block。(暂未知:index是什么数据结构,block中存储kv对还是kv分离存储?)
如整体架构图所示,每一个这样的SST再被组织为一个又一个的level。一个level里存在多个SST。除level0之外,每一个level里的SST都是按key有序排列的,不存在重叠的key区间。
rocksdb中的level
level层级控制
每一个level都有SST固定文件数量限制,这个是可以进行设置的。用当前level的sst文件数量乘上一个系数就是下层文件的数量。这个系数被称为multiplier。这个系数也是可以调整设置的,在大多数Facebook应用中,multiplier=10,少部分应用multiplier=8。
显然,multiplier的设置会直接影响整个rocksdb的层级结构,从而影响rocksdb的效率。具体的来说,如何优雅的设置multiplier(调参)直接影响三个指标,空间利用率,读性能,写性能。
- multiplier越小,存入相同数据量,rocksdb层级越深,下一层和当前层之间的gap越小。一次读需要更多IO操做深入层级,带来读放大。
- multiplier越大,存入相同数据量,rocksdb层级越扁平,下一层和当前层之间的gap越大。带来写放大。
level层级压缩算法
SST文件的内容是可被压缩的,rocksdb支持多种压缩算法,包括LZ, Snappy, zlib和Zstandard,这也是可配置的。不同算法对SST文件的有不同的压缩比率。一般来说,压缩越强的算法压缩率大于压缩越弱的算法,当然具体效果如何这也和SST文件中的数据内容也密不可分。整体架构图中的block cache存储未压缩的SST文件以避免频繁的解压操做降低读性能。当然,这也会导致SST文件内容第一次被读入到block cache中时需要花费额外的解压缩时间。
显然,压缩算法的配置会直接影响rocksdb的读性能和存储空间。具体地来说,压缩率越高(zlib和Zstandard)的算法在压缩和解压时,会显著增加cpu的计算开销。压缩率低的算法的优点是cpu计算开销少,但不会明显的节约存储空间。
rocksdb支持不同层使用不同压缩算法。一般来说,level 0-2不会使用压缩算法进行压缩,本来这两级的存储内容本来就不多,再加之这两级的文件内容被访问的概率较高,压缩解压增加读延迟。level 3-n-1层通常采用轻量级压缩算法(LZ4和Snappy),最后一层level采用高压缩算法(zlib和Zstandard)用于尽可能地压缩存储空间。
rocksdb是如何工作的
对于写入任意一个KV实体,其工作流程如下:
- 对于该实体的写入记录首先会被记录到WAL中,WAL写入完成后,然后该KV会被写入到memtable中。当memtable尺寸达到预设阈值,进行如下操做
- 当前WAL和memtable变为不可改变状态,并创建一个新的WAL和memtable用于接收后续写入KV
- 将当前不可变的memtable flush到存储介质上,待写入完成后,丢掉当前不可变的memtable和WAL。当level0的SST文件数量超过预设阈值,继续进行如下操做
- 将level0中SST文件key范围和level1中文件key范围重叠的那些SST文件进行合并,写入到level1中(合并写入过程如下图所示)。因为该操做会增加level1的SST文件数量,会让level1的SST文件数量超过阈值。因此级联触发该操作,直到满足SST文件数量小于某个level的阈值。
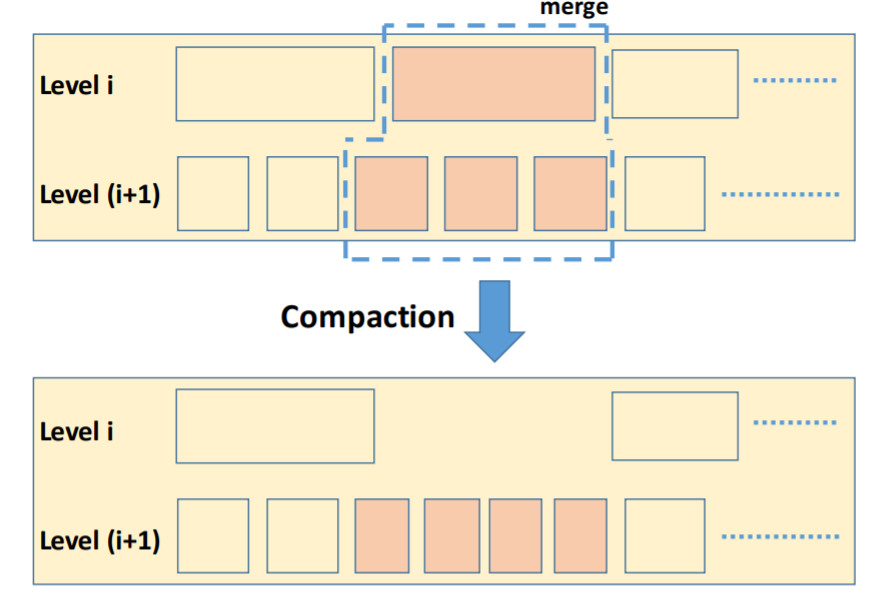
由上可见,当一层level中的SST数量超过阈值,就会触发向下合并操做,这个过程被称作compaction。除此之外,在每一次合并过程中,都会更新Manifest文件中的元信息,用于后续读操做。
对于读任意一个KV实体,其工作流程如下:
- 先在memtable上做二分查找,判断该key是否在memtable上。若不在,则继续
- 单独查该key是否在level0中,因为level0中的key范围存在重叠(具体如何查找暂未知)
- 若未在level0中找到,则使用manifest的信息,二分查找锁定SST文件
- 再使用SST文件中的index信息,二分查找锁定block
- 最后、在block内部查找key,并将该block解压后缓存至block cache中。
由上可见,block cache的大小也会直接影响读性能。能否优雅的配置block cache的大小,也是一个技术活(调参)。除了查询单独某个key之外,rocksdb还支持范围查询。
rocksdb调参
因rocksdb采用lsm tree作其指导思想,lsm tree本身就有许多可配置项,加之rocksdb本身系统实现也有许多可配置项,这使得如何根据应用场景和实际需求来优雅的设置参数是一个技术活。
幸运的是,先辈们为我们留下屠龙宝刀,即数据库中的CAP——space amplification,Read amplification和Write amplification只能三者取二。
Write-amp is the amount of work done per write operation.
Read-amp is the amount of work done per logical read operation
Space-amp is the ratio of the size of the database to the size of the data in the database.
实践出真知
rocksdb的api
打开关闭
#include <assert>
#include "rocksdb/db.h"
rocksdb::DB* db;
rocksdb::Options options;
options.create_if_missing = true;
rocksdb::Status status =
rocksdb::DB::Open(options, "/tmp/testdb", &db);
delete db;
人如其名系列之,PUT,GET,DELETE。PUT默认异步执行,不要以为PUT了db中就一定有数据噢。强制PUT同步执行,可添加在option中设置sync=true。
std::string value;
rocksdb::Status s = db->Get(rocksdb::ReadOptions(), key1, &value);
if (s.ok()) s = db->Put(rocksdb::WriteOptions(), key2, value);
if (s.ok()) s = db->Delete(rocksdb::WriteOptions(), key1);
高阶原子写之,WriteBatch。保证CAS指令不乱序,redis中可用lua脚本实现。
#include "rocksdb/write_batch.h"
...
std::string value;
rocksdb::Status s = db->Get(rocksdb::ReadOptions(), key1, &value);
if (s.ok()) {
rocksdb::WriteBatch batch;
batch.Delete(key1);
batch.Put(key2, value);
s = db->Write(rocksdb::WriteOptions(), &batch);
}
rocksdb进阶API
后续更新
rocksdb tunning
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册