如何评价一个开源项目——价值流网络
2022.01.06 14:29浏览量:647简介:价值流网络
本文由X-lab开放实验室博士生赵生宇原创出品
该篇博客继续之前关于活跃度和协作影响力的介绍继续展开,希望可以在解决协作影响力无法容纳更多数据,从而可以更全面衡量开源生态的同时,也引入一种高可扩展的数学模型,可以在任意时间快速容纳更多元的数据,而不会导致模型的大幅改动。
01背景
之前的两篇博客介绍了一种基于开发者行为加权统计的活跃度指标计算方法,以及基于活跃度的开源协作网络下的项目协作影响力指标计算方法。其中活跃度主要解决指标多元导致的认识困难,同时通过不同的行为权重使这个指标对开发者的行为可以起到正向的激励作用。而协作活跃度则是从整个开源技术生态的角度出发,在考虑项目间的协作关联的同时,某种程度上解决了活跃度可能出现的恶意刷分的问题和人为给定权重导致的排序不稳定的问题。
然而仅仅是上述两个指标,除了存在一些固有度量准确度的问题外,还存在着一个重要的缺陷,那就是在引入新的生态数据后模型需要再次修正,而开源软件生态的数据要远远超出 GitHub 全域行为数据的范畴,所以我们更加需要一个高度可扩展的数学模型,可以在有更多的开放数据时随时融入进来。
02价值流网络
就像 Nadia Eghbal 的新书「Working in Public」中表述的:“消费代码的目的不是为了简单地阅读和研究它,而是为了使用它,开放源代码的价值不是来自于它的静态品质。”、“是,基于依赖关系来衡量代码的价值,只能给我们提供等式的一部分。谁在使用开放源代码很重要,但谁开发了这些代码不也很重要吗?”。这两句话很好的表明的我们对开源软件度量应该遵循的最基本的底层逻辑。
即开源软件或开源数字制品是否有价值最重要的两个需要衡量的点分别在生产侧和消费侧。从生产侧而言,即便两个开发者具有相同的活跃度,但优秀的开发者的行为所产生的价值与刚入门的开发者所产生的价值是完全不同的。而从消费侧而言,如果一个开源软件在持续开发、但从未被人使用过,和一个可能已经长期不活跃、但却被成百上千的人所使用的的项目的价值也是不同的。
所以价值流网络本质上是希望从开源软件产生的社会价值的角度来进行分析,产生一个从生产端到消费端的模型,可以直接衡量出每个软件的社会价值,同时也可以反向推演出每个开发者的价值。这对于构建完整的开源经济生态体系是基础性的工作。
03从协作影响力开始说起
回头先来看一下上一篇的协作影响力模型。
其实在原始的网页排名算法中,是从一个概率模型出发的,即当一个互联网用户浏览到某一网页时,接下来他可能去哪些网页?有较大概率他会在当前页面的外链中随机寻找一个链接继续访问一下,也有可能就关掉网页以后在所有的网页中随机打开一个。最终网页的排名就是可能被访问到概率较大的网页排在靠前的位置。
但同时这个模型也可以从价值流的角度来看,也就是每个网页会向其外链的网页传递一部分自己的价值,而从链入它的网页获取一部分价值,同时所有网页还都具有一个基础价值。那么当在整个网络结构的价值流稳定后,每个网页的价值也就被完全确定一下来,那么价值最大的网页就会排名靠前一些。
而从上一篇的开源协作网络中,也可以认为是每个项目都有一个基础价值,同时根据开发者协作导致的项目之间的关联会带来项目之间的价值流动和传递,直到整个网络稳定时,所有项目的协作影响力也就是被确定了下来。
04
一个简单的示例
从上面的角度来看,事实上我们是可以给出一种更加泛化的方法来进行价值网络的构造和计算的。下面给出一个最简单的例子,在考虑到开发者贡献活跃度的同时加入更多的数据关系,尤其是在生产侧和消费侧的数据。
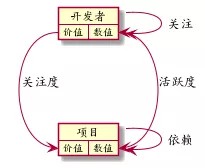
如上图所示,在这个简单的价值网络中,包含了开发者和项目两种节点,开发者和项目具有各自的价值,且开发者之间具有关注关系,类似 GitHub 上的 Follow 关系。而项目之间具有依赖关系,即上下游的使用关系。同时除了开发者对项目的活跃度以外,我们还加入了关注度的概念,也就是那些由开发者对项目发起的单向的行为,例如 star、watch、fork、clone 等表示了对项目的关注,但没有实际反馈到项目中的行为。这个网络中的价值流动可以在下表中展示,每个单元格中的表示从行节点到列节点的价值传递:
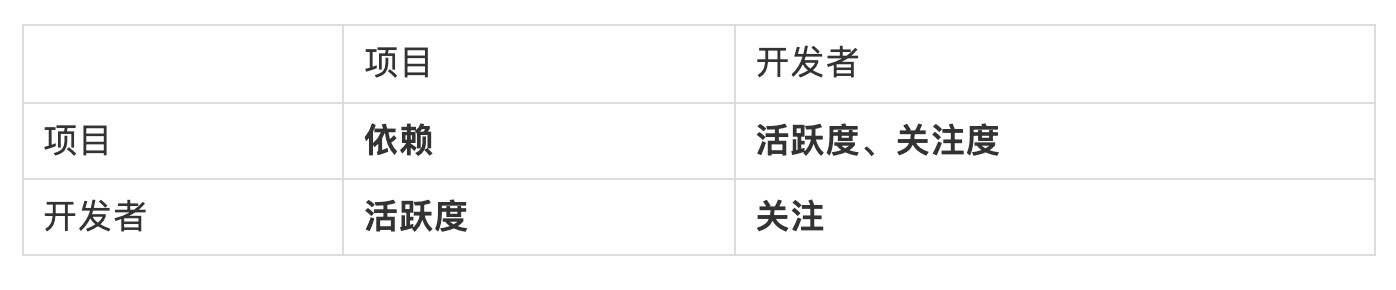
在这样一个模型下,对全域开源项目和开发者的价值流网络中,每个开发者的价值会通过其活跃度、项目关注度和对其他开发者关注关系向外流动;而每个项目的价值会通过活跃度和依赖关系向外流动。即我个人所创造的价值大部分会通过我的具体贡献行为流动到我贡献的项目中,另外有一部分会流动到我关注但没有贡献的项目中,还有一部分会流动到我关注那些开发者身上。而项目的价值一部分会通过贡献关系回归到开发者那里,还有一部分会通过依赖关系流动到给它提供服务的上游项目中。
而由于项目和开发者还会保留自己的一部分价值,那么我们可以将一些不在网络中的固有属性加入到他们的初始价值中,例如开源 KOL 的初始价值更高,那么这部分初始价值事实上会因为具有一定比例的保留持有而持续产生影响。
这个模型是否可以最终收敛并得到稳定解,是一个比较复杂的数学问题,有兴趣的同学可以参考附录部分的内容。
05开源生态价值流网络
上面是一个可以快速实现并验证的数学模型,并且具有很好的可扩展性,但事实上整个开源生态的价值网络要远比上面的网络更加复杂。从生产侧到消费侧所包含的数据是远远超过这个范畴的,事实上尤其在消费端,被其他项目依赖并不是开源项目最终被消费的方式。事实上所有软件最终被消费的方式都是通过变成服务而满足某种现实用户的需求,事实上应该是指其最终的社会效用,而不是是否被集成做二次开发。如果二次开发后的项目同样没有被任何用户使用,没有解决任何现实需求,或换句话说没有产生任何社会效用的话,那其价值就是有限的。
这里可以给出一个更加复杂,但在当下可能还不具备可行性的价值网络供大家参考:
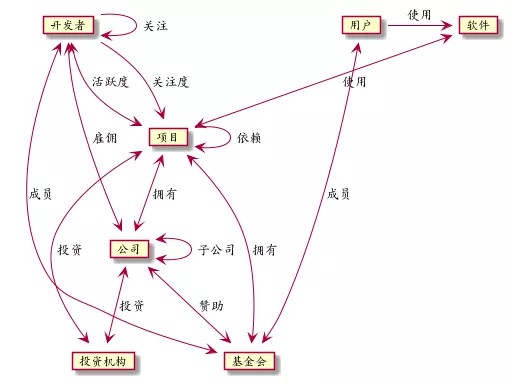
在上图表示的复杂网络结构中,其价值流动可以从下表中观察:
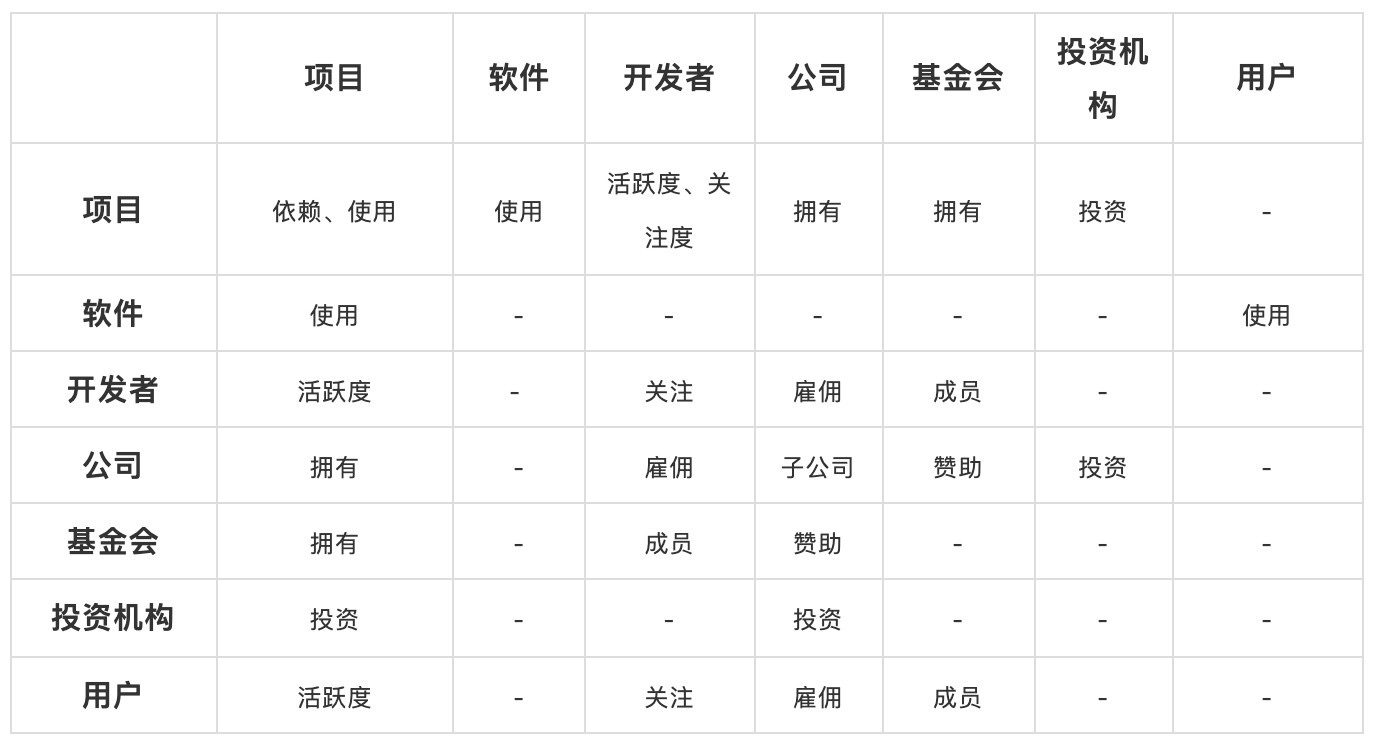
在上图上,大量与软件生态相关的实体都被纳入进来,如软件、公司、基金会、投资机构、用户等。从这个不完整的视角来看,开发者的活跃和用户对软件的使用本质上是所有开源软件生态价值的来源,而投资机构的投资、公司通过对开发者的雇佣关系和对基金会的赞助关系所注入的是外部影响价值,其他的价值均在网络内部按照上述的关系进行流动。
而上述提到的项目之间除了依赖关系,还有软件和项目之间使用关系。事实上传统的项目依赖关系主要是指二次开发,通常以特定语言制品包的方式引入。而软件的使用则是指在最终像用户提供服务时,一定不是单独项目提供服务,还包括该软件运行的底层操作系统、数据库、虚拟机、其开发语言、通过 RPC 交互的其他服务等,都属于软件使用范畴。
在这个网络模型下,如果我们可以很好的量化每一部分的具体价值和流动机制,最终不仅可以很好的评估所有实体的价值,而且在数据不断完善的情况下,这个价值会逐渐趋近于其所对应的真实社会效用。这才是最终的目标所在。而事实上这种方法也经常用于复杂系统的求解,且其解通常就是该复杂系统的稳态解,揭示了该复杂系统应该具有的运行模型。
当然这也不是一个最终的模型,例如对于安全风险的引入,那些长期从事网络安全漏洞监控与分析的开发者或公司同样为开源生态带来了巨大的价值。但外延继续延伸会导致这个网络迅速膨胀,所以这里就不再扩展了。
06思考
价值流网络模型事实上是希望尽可能把开源生态中所包含的数据都囊括其中,更重要的是提供一种上层的模型可以兼容更多的数据。
价值流网络模型通过对数学模型和业务模型的解耦,使得上层的开源生态描述几乎可以在不关心底层数学模型的情况下进行,例如上述较复杂的网络结构,并没有涉及到任何数学模型。
价值流网络模型是否可以得到稳态解,与其底层的数学约束息息相关,感兴趣的同学可以参考附录部分。但业务模型确定后可以由具有底层知识的同学协作调整使其可收敛即可。
价值流网络模型最终希望解决的是整个开源生态的经济体系构建的问题,关于这个问题,将在下一篇文章中展开。
07问题
该模型虽然解耦的数学模型和业务模型,而且具有较好的可扩展性,但如果设计业务模型的人不熟悉底层的数学逻辑,很可能会设计出无法得出稳定解的业务模型,所以对业务模型设计人员有较高的要求。
该模型想要准确的衡量整个开源数字生态的经济体系,需要大量的数据,而其中大部分数据是难以获取和难以关联的,这部分将是一个非常长期,而且是需要大规模协同的工作,也将是我们后续会引出的一部分工作。
08附录
PageRank 的收敛性一般是在其等价的马尔科夫过程视角下,利用随机过程的理论进行证明。其对应的转移矩阵需要满足两个条件:
满足随机过程的要求,即转移矩阵为一个随机矩阵。
转移矩阵需为素矩阵或本原矩阵(primitive matrix),此时该矩阵可以满足不可约(irreducible)和非周期(aperiodic),则根据 Perron-Frobenius 定理,该随机过程一定收敛。
那么在高维的异质信息网络中,类似的随机过程也需要满足上述两个条件,即可满足其收敛性要求。更详细的信息请自行查阅相关内容。

发表评论
登录后可评论,请前往 登录 或 注册