研究表明,有影响力的数据集正在垄断机器学习研究
2022.01.11 14:01浏览量:458简介:在我们的 43,140 个样本中,超过 50% 样本所使用的数据集全部是由 12 个顶尖西方组织引入
作者 | Martin Anderson
译者 | 马可薇
策划 | 凌敏
审校 | 冬雨
来源 | InfoQ
加州大学和谷歌研究院联合发表的一篇新论文称,少数来自高影响力的西方机构所发表的“基准”计算机数据集逐渐开始主导 人工智能 研究领域,而这些机构中不乏政府组织。
研究人员总结,这种倾向于使用常用开源数据集(如 ImageNet)的趋势,将会带来各种现实和道德上,甚至政治层面的困扰。
基于 Facebook 社区项目“论文 + 代码(PWC)”中的核心数据,《减少、复用和回收:机器学习研究中数据集的一生》论文作者得出结论,“广泛使用的数据集仅由少数顶尖机构引入”,并且近几年来,这类现象已逐渐覆盖了 80% 的数据集。
“(我们发现)全球数据集的使用情况愈发不平等。在我们的 43,140 个样本中,超过 50% 样本所使用的数据集全部是由 12 个顶尖西方组织引入的。”
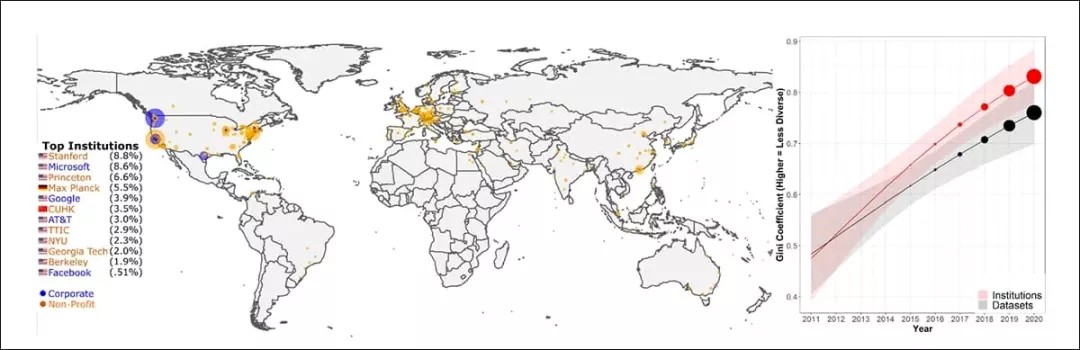
过去十年间非任务特定的数据集使用情况图示。只收录机构或公司占已有数据集使用的 50% 及以上的数据集。右图是随时间推移,机构和数据集二者的基尼系数数据集集中指数。来源:https://arxiv.org/pdf/2112.01716.pdf
其中主导的机构包括斯坦福大学、微软、普林斯顿、Facebook、谷歌、德国马普所,以及 At&T。十大数据集来源中有四个都是公司机构。
论文中还将这些倾向使用精英数据集的趋势描述为“让科学走向不平等的工具”。这是因为研究团队为寻求社区的认同,会更倾向于使用常用数据库以达到顶尖水平(SOTA),而不是自己生成一个全新的,在研究领域毫无地位的数据集,而其结果因为不是标准指标,因此还需要同行们重新适应的新数据集。
就如论文中阐述的一样,无论怎么说,对于资源不是那么充足的机构或团队来说,创造自己的数据集是一个成本高昂的追求。
“人们往往混淆 SOTA 基准所认可的科学有效性,与社会上由可信度高的研究者所展示、在一个接受度高的数据集上所实现的结果,即使更符合上下文的基准可能在技术上来说会更合适。
“我们认为,这些现象创造了一种“马修效应”(穷的越穷,富的越富),出身精英机构的成功基准将注定在研究领域中获得显著地位。”
《减少、复用和回收:机器学习研究中数据集的一生》这篇论文是由加州大学洛杉矶分校的 Bernard Koch 与 Jacob G. Foster,谷歌研究院的 Emily Denton 与 Alex Hanna 合作编著。
该论文针对当前日益增长的整合趋势提出了不少问题,并在开放审查中得到了 普遍的认可。来自 NeurIPS 2021 的一位审稿人评论说,这项研究“与任何参与机器学习研究的人都息息相关”,并预言它将成为大学课程的阅读材料之一。
从必要到腐败
论文作者称,目前这种“超越基准线”潮流的出现是为补偿客观评估工具的匮乏,而正是这种匮乏,导致了 三十年前 由于企业对新兴“专家系统”研究热情的消退,并第二次削减在人工智能领域的投资和兴趣:
基准线的设定通常是数据集在执行特定任务时,以其对应的标准评估后的结果。这种做法最初是在 1980 年代“AI 寒冬”后,由政府资助引入到机器学习研究中的,目的是为更准确地评估获得资助的项目价值。”
论文认为,这种非正式的标准化最初的优势在于降低了参加门槛、统一了评估尺标以及提供更灵活的开发机会。但随着数据体量日益强大足以在实质上定义其“使用条款”和影响范围时,这些优势已经被其自然而然带出的缺点所抵消。
对此,作者的观点与目前行业与学术界的想法一致,任何研究团队所提出的问题,如不能通过现有用作基准的数据库解决,则不能算作是新的发现。
作者同样还指出,盲目坚持少数“黄金”数据集会让研究者的结果过度拟合;研究得出的高性能结果将会更针对于某个数据集,但在现实数据、新的学术研究或是原始数据集中可能不会有太好表现,甚至是在其他的“黄金”数据集中也可能表现欠佳。
“鉴于大量研究高度集中在少数基准数据集中,我们认为多样化的评估形式对避免过度拟合现有数据集,扭曲该领域研究的进展尤为重要。”
计算机视觉研究中的政府影响
论文称,计算机视觉研究相较于其他 AI 研究,更易受前文中描述的现象所影响;而 自然语言处理(NLP)受到的影响则更小。作者认为,这可能是因为 NLP 社区更“连贯”,规模也更大,并且 NLP 数据集无论是访问还是策划,都要容易得多,再加上其在数据收集方面资源密集程度也更低。
作者称,计算机视觉,尤其是面部识别(FR)数据集,更易引起企业、国家以及私人利益间的冲突。“企业和政府机构的目标(如监控)会与隐私相冲突,他们对(隐私与其目标)优先级的判定可能会与学术界或人工智能领域中更广泛的社会利益相关者相悖。”
对面部识别任务来说,研究者发现纯粹的学术性数据集的数量相较平均而言已有大幅的下降:
“八中之四的数据集(占总体用量的 33.69%)是完全由大企业、美国军方或中国政府(MS-Celeb-1M,CASIA-Webface,IJB-A,VggFace2)提供的。由于不同利益相关者关于隐私价值的争执,导致 MS-Celeb-1M 最终被撤回。”
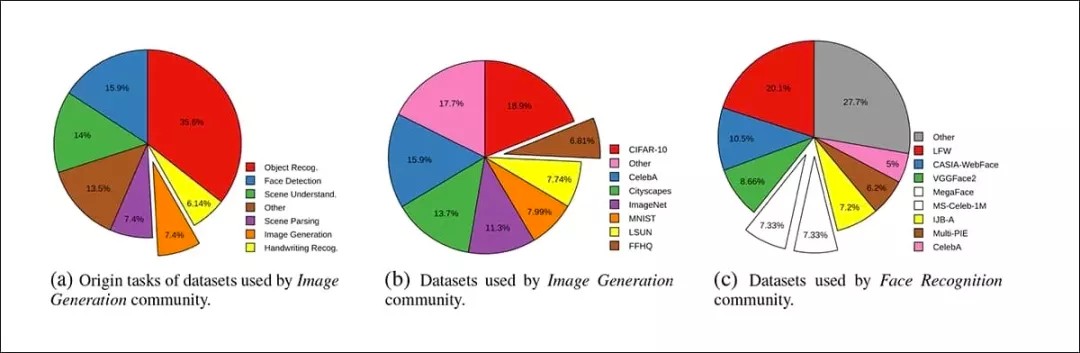
用于图像生成和人脸识别研究社区的顶尖数据集使用分布。
从上图可看出,就如作者所言,近年来的图像生成或 图像合成 领域严重依赖于现有的,也更古老的数据集现象,哪怕这些数据集在当时创建时并不适用于图像生成。
事实上,目前数据集已有“迁离”其预期目的的趋势,令人质疑它们是否还适用于现今或冷门的研究需求。再加上研究经费的限制,研究的雄心壮志可能会被“一般化”到一个仅使用手头材料的狭窄框架,并日益痴迷于基准评级的研究氛围之中,从而导致新诞生的数据集很难获得应有的关注。
“我们的研究还表明,数据集经常在多个任务社区之间转移。最极端的情况下,某个任务社区中主要的基准数据集全部是为其他任务所创建的。”
近年来,机器学习领域包括 Andrew Ng 在内的多位知名人士,不断呼吁业内增加数据集的多样性和策展性,作者对此类倡导表示支持的同时,认为只要当前对 SOTA 结果和已有数据集依赖的研究氛围持续存在,这种努力终将功亏一篑。
“我们的研究表明,仅仅是改善奖励机制并呼吁 ML 研究人员开发更多数据集,让数据集的开发能够收到认可和回报,可能还不足以让数据集的使用以及最终确立 MLR 研究议程的观念真正变得多样化。”
“除了激励数据集的开发,我们主张引入以公平为导向的政策干预;优先为研究资源较少的机构提供大量资金,以创建高质量数据集。这将从社会和文化的双重角度,让评估现代 ML 方法的数据集多样化。”
原文链接:

发表评论
登录后可评论,请前往 登录 或 注册