从小样本学习出发,奔向星辰大海
作者:技术指挥2022.02.10 11:13浏览量:701简介:从小样本学习

本文为大家带来的演讲主题是:从小样本学习出发,奔向星辰大海。主要分为五个部分:
小样本学习方法及其重要性
小样本学习的三个经典场景
小样本学习的应用领域
小样本学习的定义及难题
PaddleFSL助你实现小样本学习
王雅晴,2019年博士毕业于香港科技大学计算机科学及工程学系,研究方向为机器学习,导师是倪明选教授和郭天佑教授,主要聚焦在小样本学习方向。

WAVE SUMMIT+2021深度学习开发者峰会
【科技创新,女姓力量】论坛
自读博以来,有多篇一作成果在ICML、NeurIPS、TheWebConf、EMNLP、TIP等顶会顶刊发表。曾撰写的小样本学习综述,是ACM Computing Surveys 2019-2021年最高引论文,也是今年的ESI高被引论文。
此外,她负责开发的小样本学习工具,在GitHub上获得1.1K+的关注,如果有感兴趣的同学,可以去看一下这个链接:
https://github.com/tata1661/FSL-Mate/tree/master/PaddleFSL
王雅晴加入百度以来,深耕在小样本学习领域,主要是关于如何快速泛化到仅包含少量标注数据的新任务上面。

小样本学习方法及其重要性
三个角度解决小样本学习:
首先钻研相关的理论学习基础,比如说元学习,图学习。
其次在百度我们还需要考虑如何落地实际应用,比如说新药发现、文本分类、意图识别、冷启动推荐、手势识别等等。
最后是为了帮助大家能够快速的上手小样本学习,实现小样本学习方法的快速原型化,还实现了通用小样本学习工具。它是基于PaddlePaddle研发出来的,里面提供了简单易用又稳定的,小样本学习的经典方法,目前已经包含了CV和NLP里面的经典应用。
说到小样本学习,就要先谈一下深度学习。自2015年以来,深度学习实现了屡屡突破,AlphaGo打败了人类围棋冠军。自从ResNet开始,机器学习模型在ImageNet这样的大数据上的标注效果,比人类标注者的误差更低。但是这些深度学习模型的成功,其实是需要大量的标注数据,和高性能的计算设备。
比如说AlphaGo,它训练自一个包含3000万对奕历史的数据库,而且还能不断自我对奕。ResNet训练自ImageNet上,这样一个罕见的,包含上百万标注图片的的大数据集。所以这也使得,在绝大多数场景里面,这两个条件“大量的标注数据”和“高性能的计算设备”是很难被满足的,这也是需要进行小样本学习的原因。
小样本学习的三个经典场景
首先,介绍一下小样本学习的三个经典场景。
1. 为了让人工智能更像人,具备举一反三的能力,以图3中最左边的图片为例。给你一个独轮车,即使一个小孩,也可以轻易从一堆图片当中,识别出来哪张也是独轮车。不管是把独轮车倾斜、翻转,还是把车杆加粗轮子变大,仍然可以看出它还是独轮车。
此外,如果给你独轮车、自行车、摩托车,人类的孩童也很容易看出,不同车之间的共性。比如,都有轮子、车把手。这样的举一反三的能力,现在的人工智能还是缺失的。所以小样本学习,一直是学术界的研究重点,目标就是能够降低人工智能和人类智能之间的差距。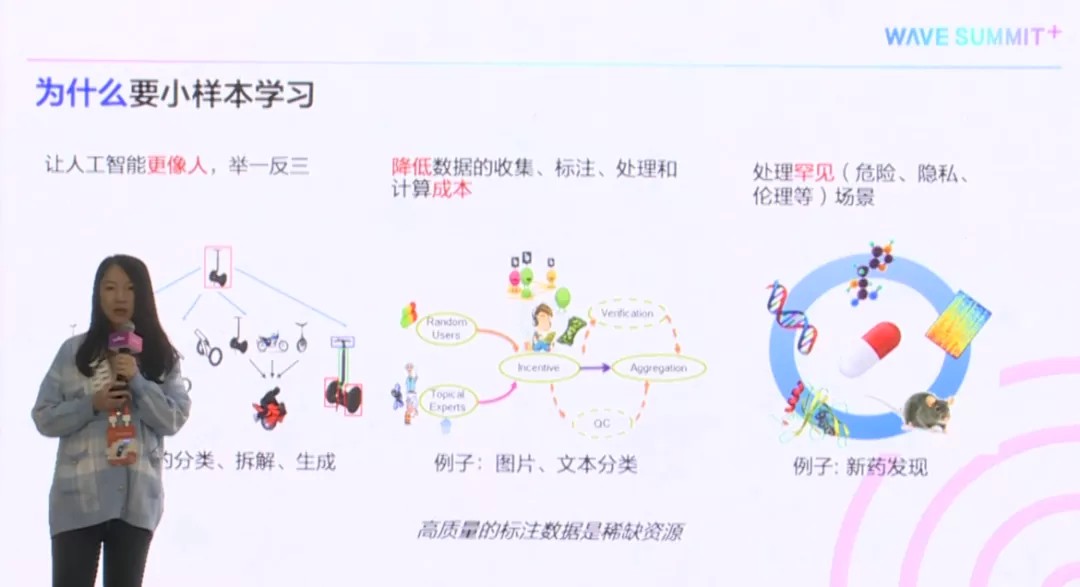
2. 小样本学习的重点场景,就是为了降低数据的收集、标注、处理和计算成本。如今,很多开发者会遇到海量且没有标签的数据,而且包含着大量的噪声。这也使得真正想用这些数据挖掘出一些知识、信息,是件很困难的事情。
一般来说,需要找数据众包的人员,帮助你标数据。但是标数据,首先它需要花很长时间,双方之间需要进行多轮的迭代。最终数据的质量,也仍然会包含,标数据人的一些主观因素。
所以如果能够应用小样本学习,就可以把数据的收集、标注的成本,给大大降低下来。只需要收集很小的数据集,这个数据集只需要包含少量的、高质量的标注样本,就可以训练一个模型,来做回归预测和分类。
3. 处理一些罕见的情况。比如说危险的、涉及到隐私的、伦理的。一个比较经典的场景,就是新药发现。在新药发现里面,希望能够从成千上百万的化合物当中,找到符合想要的性质的那些化合物。比如说有较低的毒性,有较高的水溶性之类的。
但是新药发现,本身是非常耗时的过程。可能要花十来年的时间,还要花很高的费用,去招一些受试者过来进行测试。但实际上到最后,真正能够进入到实验室里面测试的样本,本身数量就很少。这使得新药发现,是一个小样本学习的问题。
小样本学习的应用领域
由于小样本学习,真的是太常见了,所以目前各行、各业、各个领域,都出现了小样本学习的身影。最早出现的就是CV,也就是计算机视觉,如图片分类、物体识别、图片切割。
后来在NLP领域也出现了,比如说会做一些比较经典的关系抽取、NER这些任务。最近随着预训练模型的出现,大家都会想去利用预训练模型。因为这些预训练模型,一般都是训练在一个大的语料库上面,里面有丰富的语义信息和先验知识。
怎样通过微调或者构建一些模板,把它能够调到一些新的任务,即使它只包含少量的标注数据,这也是最近NLP领域的研究重点。
除了NLP领域,还有像知识图谱,比如怎么处理日渐出现的新的实体、新的关系,这都可以通过小样本学习的方法搞定。
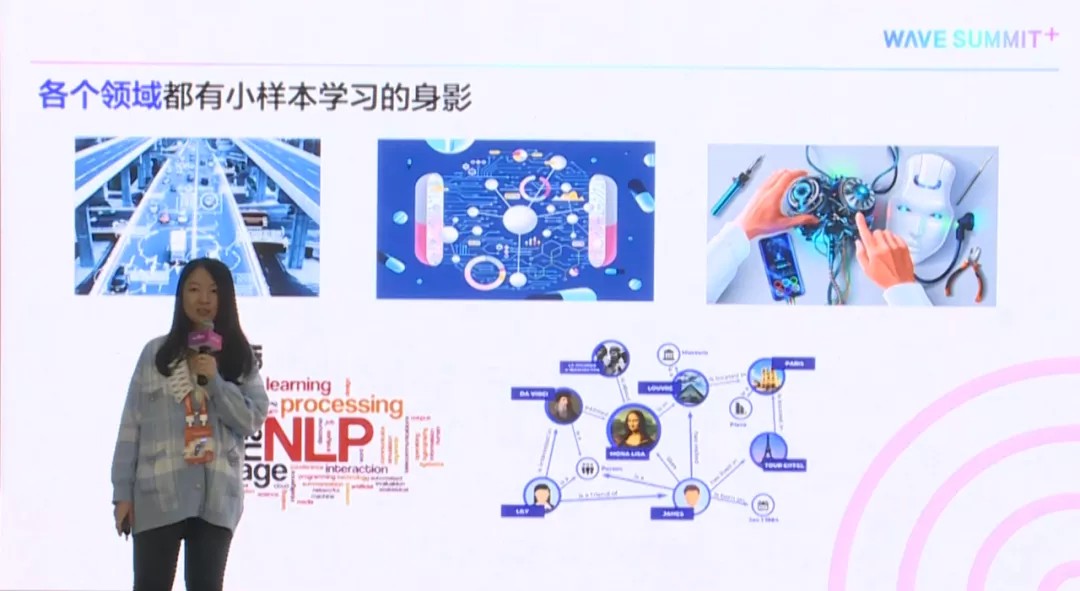
另外还有刚才提到的,新药发现和机器人学。比如说,教机器狗让它往左走两步,或者只展示一两个手势,它就知道我想要干什么,这都是要用到小样本学习的。
小样本学习的定义及难题
下面给出小样本学习的比较严谨的定义,是根据1997年Tom Mitchell教授的经典机器学习定义来定义的。
什么是机器学习?对某一类任务T,如果一个计算机程序,在该任务T上与P度量的性能,随着经验E的增加而提高,就称这个计算机的程序,是在从经验E当中学习。
小样本学习,是机器学习的一种。但是比较特别的是,它里面的经验,只有很少量的监督信号。比较常见的监督信号,就是样本的标签。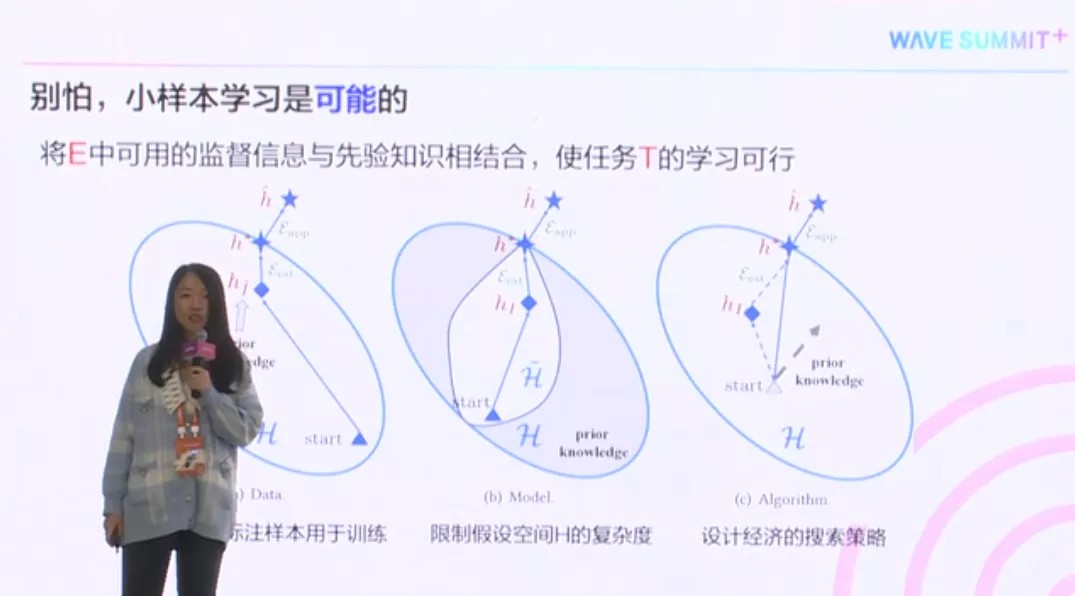
学习的理想,是希望能够降低模型的期望风险。也就是在未来不管有什么样的样本,都能够很好的预测出来。但这个模型的联合分布,一般是未知的,所以就要估计它。
在机器学习里面,一般是优化经验风险。但是,大家看到公式上面的经验风险,是通过训练集里面有多少样本来求的。如果是训练样本里面,只有很少量的标注数据。这个I的数量很小的话,最终只会得到非常不可靠的,最小化的风险经验估值,使小样本学习确实是很困难的问题。
但是,这并不是不能够被解决的,解法就是我们将经验E当中的标注信息,和一些先验知识结合。比如说,刚才提到的NLP领域的预训练模型,把这些先验知识结合以后,就能使得任务T的学习变得可行。一般有三个角度。
通过这些先验知识,来生成更多的标注样本,用于训练。
通过先验知识,限制模型的空间复杂度。
还可以有这样一种先验知识,让它告诉我们,怎样设计一个经济的搜索策略。比如说,在假设空间这个大H上面,应该从哪个点开始搜?往哪个方向去搜?以什么样的速度搜?这些,都会使最终得到的搜索策略,能够更经济有效一点。只有几个样本,就能够得到很好的效果。
这些方法,都被详细总结和梳理在小样本学习的综述里面。这是ACM Computing Surveys最近两年的最高引论文,也是ESI今年的高被引论文。
PaddleFSL助你实现小样本学习
刚才介绍了,通用的小样本学习的方法。这边就介绍一下,怎样通过小样本学习工具包PaddleFSL,来实现小样本学习。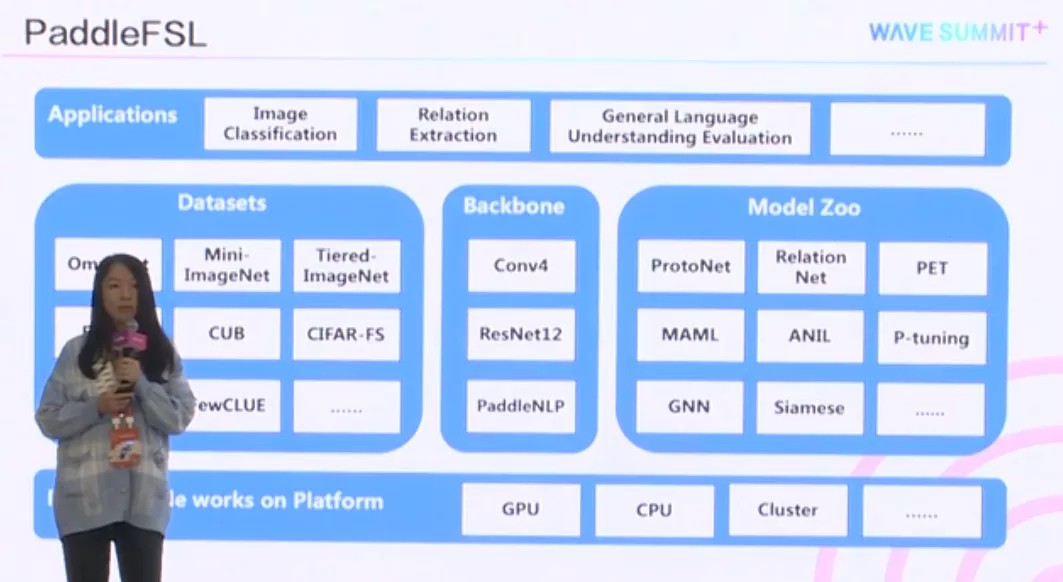
PaddleFSL是一个基于飞桨的小样本学习工具包。在这个工具包里面,提供了简单、易用、稳定的经典小样本学习的方法,并支持拓展新的小样本学习方法。
此外,还提供了统一的数据集处理,使模型效果比较更加容易。而且提供了非常详实的注释,让你可以轻易定制新的数据集。目前已经包含了,CV和NLP小样本的经典应用,并且依托飞桨的繁荣生态,不断扩展到新的领域上。
从这里给出的PaddleFSL的整体框架图上,可以看出现在支持像图片分类、关系抽取、通用自然语言处理等一系列的任务。并包含了这三个任务当中,所涉及到的一些经典数据集。
为了处理不同的应用,也提供不同的特征抽取器,来供大家抽取特征。
比如CNN是用来抽图片的,另外还支持所有PaddleNLP里面提供的预训练模型。此外,在模型库也提供了经典的小样本学习的方法。因为PaddleFSL是部署在飞桨上面的,因此也同样支持跨平台的部署。
这里给出了小样本图片分类结果的复现。使用PaddleFSL在ProtoNet、RelationNet、MAML、ANIL这四个方法上面,在Omniglot、Mini-ImageNet两个经典的数据集上面,都可以复现出比文章汇报更好,或者至少是匹敌的效果。
下面做一个总结,加入百度研究院以来,王雅晴主要是在做小样本学习方向。在理论研究方面,文章现在也被ACM Computing Surveys,还有WWW录用。此外,在小样本的实际应用,特别是新药发现工作,被今年NeurIPS 2021接收为Spotlight Paper。而小样本短文本分类的文章,被EMNLP接收为长文。意图识别和冷启动方面也都在进行推进,目前在审稿阶段。
另外关于小样本手势识别的工作,获得了国家自然科学基金的面上项目支持。最后再提一下PaddleFSL,这个包现在获得了1100多的Star,以及1万多的文章阅读。
借此机会,希望对小样本学习感兴趣的同学可以扫描下方二维码了解更多,并一起进行前沿的研究和实践的落地。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册