美景本天成,妙笔偶得之——“妙笔”是怎样炼成的?
2022.02.11 15:41浏览量:772简介:AI+艺术
项目背景
刚刚过去的冬奥会开幕式,可以说是一场美轮美奂的视觉盛宴。其中,科技与艺术的融合铸造了各种梦幻的视觉效果,让我们看到AI在艺术领域大有可为。而今天分享的项目也是AI+艺术的一个小方向,灵感来源于我的小女儿。
一天,我的小女儿说:“爸爸,我长大要当漫画家,今天我要画哆啦A梦!”。这让人很欣慰,她们这些孩子不必像我和我的父辈小时候那样,学好什么是为了走遍天下都“不怕”,她们学习只是因为“喜欢”。可是,喜欢也是没那么容易能喜欢的。经过半天的“挥墨行空”,“小漫画家”总是觉得自己画的哆啦A梦没有书上的好看,逐渐有点泄气了。眼看孩子梦想还没起飞,翅膀就要折断,都怪这陡峭的学习曲线。突然想起以前介绍的一个叫 GauGAN 的模型,能按图像语义编辑图片。那么,为什么不用这个模型做一个涂鸦游戏,让小朋友们都像小马良一样能够“妙笔生画”呢?
技术介绍
本文介绍的涂鸦应用采用的模型出自文章《Semantic Image Synthesis with Spatially-Adaptive Normalization》。这个模型有个好听的名字GauGAN [1] ,Gau就是梵高的Gau,在风格迁移网络Pix2PixHD的生成器上进行了改进,使用 SPADE(Spatially-Adaptive Normalization)模块代替了原来的BN层,以解决图片特征图在经过BN层时信息被“洗掉”的问题。Pix2PixHD实际上是一个CGAN(Conditional GAN)条件生成对抗网络,它能够通过输入的控制标签,也就是语义分割掩码来控制生成图片各个部分的内容。下面就详细介绍一下GauGAN各个部件的实现细节。
1.多尺度判别器
(Multi-scale discriminators)
所谓“多尺度”判别器,就是将多个结构相同、输入特征图尺寸不同的一组判别器融合在一起使用。其判别图片时,先将图片缩放成不同尺寸分别送入这些判别器,然后将这些判别器的输出加权相加得到最后的判别输出,这样可以增强判别器的判别能力,使得生成器输出的图片更逼真。
Multi-scale discriminators 判别器代码
class MultiscaleDiscriminator(nn.Layer):
def init(self, opt):
super(MultiscaleDiscriminator, self).init()
for i in range(opt.num_D):
sequence = []
feat_size = opt.crop_size
for j in range(i):
sequence += [nn.AvgPool2D(3, 2, 1)]
feat_size = np.floor((feat_size + 1 * 2 - (3 - 2)) / 2).astype('int64') # 计算各个判别器输入的缩放比例
opt_downsampled = copy.deepcopy(opt)
opt_downsampled.crop_size = feat_size
sequence += [NLayersDiscriminator(opt_downsampled)]
sequence = nn.Sequential(*sequence)
self.add_sublayer('nld_'+str(i), sequence)
def forward(self, input):
output = []
for layer in self._sub_layers.values():
output.append(layer(input))
return output
集成的各个判别器分别输入不同缩放尺度的图片计算判别结果,缩放比例通过feat_size = np.floor((feat_size + 1 * 2 - (3 - 2)) / 2).astype(‘int64’)计算得到。
2.逐渐精细化的生成器
(Coarse-to-fine generator)
生成器的思路和判别器差不多,先训练一个低分辨率的生成器,然后再加上高分辨率的生成器一起训练。训练高分生成器时使用低分生成器的特征图做辅助。Pix2PixHD 模型的生成器输入语义标签,输出照片风格图片,所以具有完整的“Encoder-Decoder(编解码器)结构”,而 GauGAN 模型的生成器只需要输入一个正态分布的随机噪声,而不需要编码器部分。它们的结构对比如下图: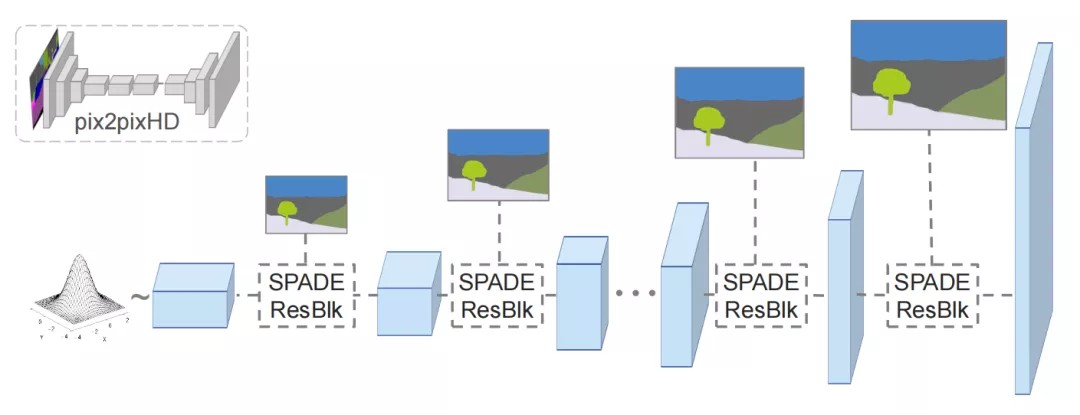
Coarse-to-fine generator 生成器代码
class SPADEGenerator(nn.Layer):
def init(self, opt):
super(SPADEGenerator, self).init()
self.opt = opt
nf = opt.ngf
self.sw, self.sh = self.compute_latent_vector_size(opt)
if self.opt.use_vae:
self.fc = nn.Linear(opt.z_dim, 16 * opt.nef * self.sw * self.sh)
self.head_0 = SPADEResnetBlock(16 * opt.nef, 16 * nf, opt)
else:
self.fc = nn.Conv2D(self.opt.semantic_nc, 16 * nf, 3, 1, 1)
self.head_0 = SPADEResnetBlock(16 * nf, 16 * nf, opt)
self.G_middle_0 = SPADEResnetBlock(16 * nf, 16 * nf, opt)
self.G_middle_1 = SPADEResnetBlock(16 * nf, 16 * nf, opt)
self.up_0 = SPADEResnetBlock(16 * nf, 8 * nf, opt)
self.up_1 = SPADEResnetBlock(8 * nf, 4 * nf, opt)
self.up_2 = SPADEResnetBlock(4 * nf, 2 * nf, opt)
self.up_3 = SPADEResnetBlock(2 * nf, 1 * nf, opt)
final_nc = nf
if opt.num_upsampling_layers == 'most':
self.up_4 = SPADEResnetBlock(1 * nf, nf // 2, opt)
final_nc = nf // 2
self.conv_img = nn.Conv2D(final_nc, 3, 3, 1, 1)
self.up = nn.Upsample(scale_factor=2)
def forward(self, input, z=None):
seg = input
if self.opt.use_vae:
x = self.fc(z)
x = paddle.reshape(x, [-1, 16 * self.opt.nef, self.sh, self.sw])
else:
x = F.interpolate(seg, (self.sh, self.sw))
x = self.fc(x)
x = self.head_0(x, seg)
x = self.up(x)
x = self.G_middle_0(x, seg)
if self.opt.num_upsampling_layers == 'more' or \
self.opt.num_upsampling_layers == 'most':
x = self.up(x)
x = self.G_middle_1(x, seg)
x = self.up(x)
x = self.up_0(x, seg)
x = self.up(x)
x = self.up_1(x, seg)
x = self.up(x)
x = self.up_2(x, seg)
x = self.up(x)
x = self.up_3(x, seg)
if self.opt.num_upsampling_layers == 'most':
x = self.up(x)
x = self.up_4(x, seg)
x = self.conv_img(F.gelu(x))
x = F.tanh(x)
return x
去掉了编码器部分的生成器由head(0),G_middle(0,1)和up(0,1,2,3)三部分组成。head主要处理生成器输入噪声。如果使用VAE(变分自编码器) 进行多模型生成,则输入的是 VAE 从特征图片提取的latent code(潜变量),以控制输出图片的风格。两层 G_middle 处理特征映射。4层up(或5层,依据输出尺寸而定)逐层将特征图上采样,直至达到输出尺寸。
为了进一步改善生成图片的质量,模型还给生成器添加了Instance Map(实例分割标签)作为控制变量:

有了Instance Map提供的边缘信息,模型生成的图片中紧邻的同一类型不同物体的边缘更加清晰合理,如上图中相邻汽车的边缘所示。
3.空间自适应归一化 SPADE
(Spatially-Adaptive Normalization)
为了解决Pix2PixHD在通过语义标签生成照片风格图像时,特征信息通过归一化层被“洗掉”的问题,GauGAN提出了Spatially-Adaptive (De)Normalization,即“空间自适应(反)归一化”,简称SPADE。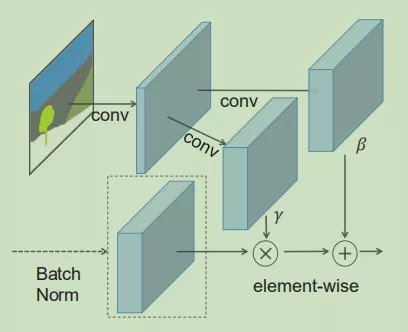
SPADE模块将输入的语义标签分别embedding到两个卷积层上,然后用这两个保留了语义标签空间信息的卷积层代替原来归一化层中的缩放系数和偏置。使用SPADE模块前后的对比如下图:
对比可见,有了SPADE模块的加持,风格迁移网络再也不怕转换大块的的语义标签了。所以,这种按语义掩码生成图片的模型也被称为“语义图像合成网络”。
SPADE空间自适应归一化模块代码
class SPADE(nn.Layer):
def init(self, configtext,
normnc, label_nc):
super(SPADE, self).__init()
parsed = re.search(r'spade(\D+)(\d)x\d', config_text)
param_free_norm_type = str(parsed.group(1))
ks = int(parsed.group(2))
self.param_free_norm = build_norm_layer(param_free_norm_type)(norm_nc) # 此处理须关闭归一化层的自适应参数
# The dimension of the intermediate embedding space. Yes, hardcoded.
nhidden = 128
pw = ks // 2
self.mlp_shared = nn.Sequential(*[
nn.Conv2D(label_nc, nhidden, ks, 1, pw),
nn.GELU(),
])
self.mlp_gamma = nn.Conv2D(nhidden, norm_nc, ks, 1, pw)
self.mlp_beta = nn.Conv2D(nhidden, norm_nc, ks, 1, pw)
def forward(self, x, segmap):
# Part 1. generate parameter-free normalized activations
normalized = self.param_free_norm(x)
# Part 2. produce scaling and bias conditioned on semantic map
segmap = F.interpolate(segmap, x.shape[2:])
actv = self.mlp_shared(segmap)
gamma = self.mlp_gamma(actv)
beta = self.mlp_beta(actv)
# apply scale and bias
out = normalized * (1 + gamma) + beta
return out
SPADE模块首先关掉了归一化层的自适应缩放系数和偏置,然后将缩放后的特征图(以适应前一层不同尺寸的输出)embedding 到 mlp_gamma 卷积层中,然后在分别映射到 gamma 卷积层(缩放)和 beta 卷积层(偏置),这样就完成了“用2d卷积层替换替换标量缩放系数和偏置”的操作,以达到保存“通过BN层的空间信息”的目的。
4.GauGAN的Loss 计算
(hinge Loss、Feat Loss、Perceptual Loss)
GauGAN的多尺度判别器不但集成了多个缩放尺寸的判别器,而且在计算判别 Loss时,不但计算最后一层输出的结果,判别器中间层输出的特征图也参与Loss计算,公式如下:
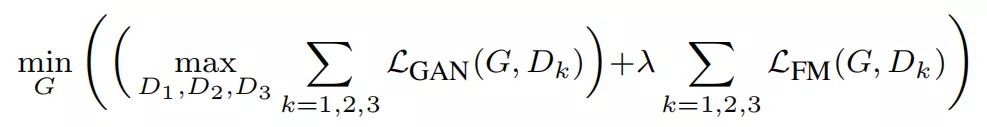
Pix2PixHD还使用了ImageNet数据集上预训练的VGG19模型作为额外特征提取器计算Perceptual Loss,用于比对真假图片。与使用判别器中间层输出的特征图计算Loss时不同,使用VGG19中间层特征图计算Loss时要逐层加权,使得模型对高层的语义特征更敏感。
GauGAN的Loss由“对抗损失”、“判别器辅助损失”和“生成器辅助损失” 三部分组成。
①对抗损失采用Hinge Loss
判别器对抗损失
df_ganloss = 0.
for i in range(len(pred)):
pred_i = pred[i][-1][:batch_size]
new_loss = -paddle.minimum(-pred_i - 1, paddle.zeros_like(pred_i)).mean() # hingle loss
df_ganloss += new_loss
df_ganloss /= len(pred)
dr_ganloss = 0.
for i in range(len(pred)):
pred_i = pred[i][-1][batch_size:]
new_loss = -paddle.minimum(pred_i - 1, paddle.zeros_like(pred_i)).mean() # hingle loss
dr_ganloss += new_loss
dr_ganloss /= len(pred)
生成器对抗损失
g_ganloss = 0.
for i in range(len(pred)):
pred_i = pred[i][-1][:batch_size]
new_loss = -pred_i.mean() # hinge loss
g_ganloss += new_loss
g_ganloss /= len(pred)
df_ganloss和dr_ganloss分别是判别假图片和真图片的Loss,g_ganloss是生成器损失。使用hinge loss计算判别器损失时,每次只用部分样本的损失更新梯度,稳定了生成器的更新。因此,后来的改进模型甚至去掉了用于稳定判别器更新的谱归一化层。
②判别器辅助损失使用判别器中间层输出的特征图计算 L1 Loss 加和而成
g_featloss = 0.
for i in range(len(pred)):
for j in range(len(pred[i]) - 1): # 除去最后一层的中间层featuremap
unweighted_loss = (pred[i][j][:batch_size] - pred[i][j][batch_size:]).abs().mean() # L1 loss
g_featloss += unweighted_loss * opt.lambda_feat / len(pred)
③生成器辅助损失使用 VGG19 预训练模型中间层输出的特征图逐层加权计算 L1 Loss 加和而成
gvggloss = paddle.to_tensor(0.)
if not opt.no_vgg_loss:
rates = [1.0 / 32, 1.0 / 16, 1.0 / 8, 1.0 / 4, 1.0] , fakefeatures = vgg19(resize(fake_img, opt, 224)) , real_features = vgg19(resize(image, opt, 224))
for i in range(len(fake_features)):
g_vggloss += rates[i] l1loss(fake_features[i], real_features[i])
g_vggloss = opt.lambda_vgg
④GauGAN总的损失函数
判别器总损失函数:
d_loss = df_ganloss + dr_ganloss
生成器总损失函数:
if opt.use_vae:
g_loss = g_ganloss + g_featloss + g_vggloss + g_vaeloss
opt_e.clear_grad()
g_loss.backward(retain_graph=True)
opt_e.step()
else:
g_loss = g_ganloss + g_featloss + g_vggloss
opt_g.clear_grad()
g_loss.backward()
opt_g.step()
如果使用VAE控制生成图片的风格,还要加上VAE生成的变分分布与高斯先验分布的KL散度计算的g_vaeloss,以拉近输入的风格图片与生成图片的风格相似性。
工程实践及更多探索
1.项目实现中遇到的一些问题
①数据处理
CycleGAN提出的时候曾经吐槽过Pix2Pix这种像素风格迁移模型严重依赖成对的数据集。但是,幸好“图像分割”作为CV深度学习三剑客(图像分类、目标检测、图像分割)之一,有大量的训练数据集和预训练模型可以用到“风格迁移/语义图像合成”任务中。
训练“妙笔生画”需要的数据就可以使用分割模型进行标注。首先,使用飞桨目标检测套件PaddleDetection在ade20k数据集上训练一个分割模型,然后就可以使用这个分割模型标注从其他数据集或资源中得到的风景图片。当然,如果有预训练模型的话,直接拿来用也可以,只要对分类类别进行相应的处理。除了ade20k上训练的分割模型,我想coco数据集上训练的应该也可以用。
用来标注数据的分割模型精度其实不是很高,但标注的数据用起来效果似乎还可以。也许生成模型拟合概率分布时,那些出现频率低的错误标注像素并没有被表现出来,如果再使用裁剪通道的方式压缩模型,那些低概率的错误表达甚至就被剪掉了。
②部署
“妙笔生画”的后台是使用飞桨预训练模型应用工具PaddleHub部署的,前端展示网页用的是H5写的Web页面,这就要处理JavaScript脚本跨域访问的问题。现在的项目还是通过一个中继的PHP服务端脚本中转了一下http请求,但是这样会导致比较大的数据传递负担。如果能够在服务端通过设置跨域资源共享(CORS)的白名单来解决跨域访问,就更高效了。方法还在探索中,欢迎大家一起讨论。
2.模型改进及正在进行的后续处理
①添加注意力
现在,注意力很流行,但语义图像合成离着上Transfomer还有点遥远,那么就先用21年“上新”的SimAM(Simple, Parameter-Free Attention Module 简单无参注意力模块)试试吧。这个注意力机制借鉴了神经科学理论,使用能量函数评估神经元的重要性。代码如下:
def simam(x, e_lambda=1e-4):
b, c, h, w = x.shape
n = w h - 1
x_minus_mu_square = (x - x.mean(axis=[2, 3], keepdim=True)) ** 2
y = x_minus_mu_square / (4 (x_minus_mu_square.sum(axis=[2, 3], keepdim=True) / n + e_lambda)) + 0.5
return x * nn.functional.sigmoid(y)
果然是Simple,6行代码搞定(上方代码)。这个SimAM模块加在了生成器和判别器的各个残差快的激活后面,详细设置可以参考本文最后整理的AI Studio开源项目。下图是GauGAN使用SimAM注意力前后的对比(左一列为使用SimAM后,左二列为原版GauGAN,左三列为真实图片,右边三列为deeplabv2预训练模型的分割结果)。

②升级SPADE模块
SPADE模块虽然好用,但计算代价巨大,所以,有人出品了个简化版的“自适应(反)归一化模块”
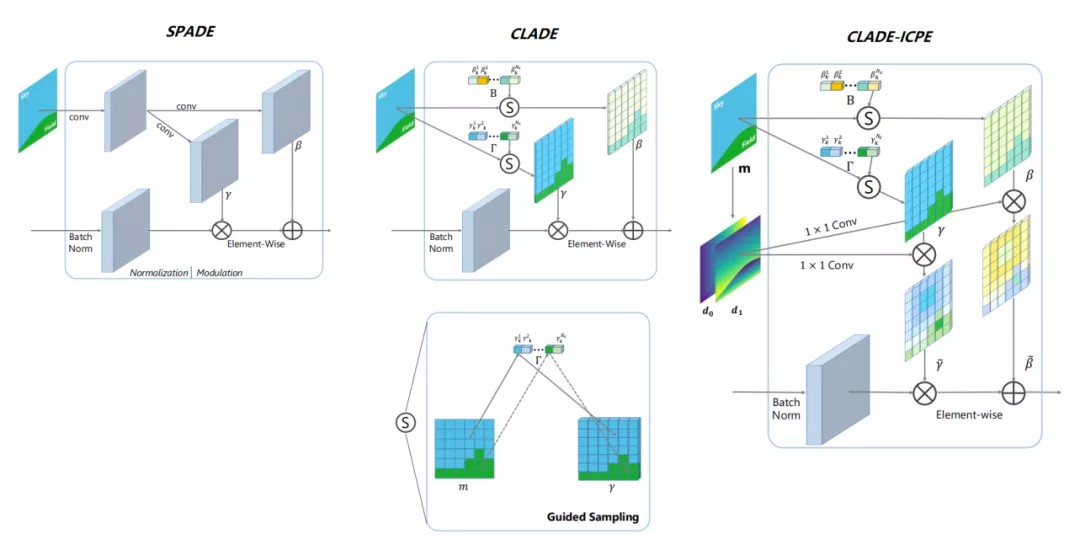
这个开始的思路是:真正使得模型提升效果的是SPADE模块中保留的类别信息,而非空间信息。所以,改进版本的CLADE(Class-Adaptive(De)Normalization)模块只将类别信息映射到了反归一化模块的缩放系数和偏置中,大大节省了参数量和计算量。但后来又发现,保留空间信息还是能使模型的效果提升一些的,就又使用语义标签手动计算了ICPE(intra-class positional encoding类内位置嵌入码)乘到了缩放系数和偏置上。最终版本的CLADE-ICPE 在生成质量与SPADE相当的情况下,大大降低了参数量和计算量。
③压缩模型
除了对SPADE模块进行改进外,最近又出了两篇压缩GAN模型的文章,也正在实验,简单介绍一下。
GAN CAT(Compression And Teaching 压缩和蒸馏)
GAN CAT方法的最大特点是:教师生成器TeacherG除了用于蒸馏,还作为模型搜索空间使用,无需训练额外的Supernet模型。模型结构的搜索空间通过InsResBlocks模块实现。裁剪过程同时选择模型结构与通道。
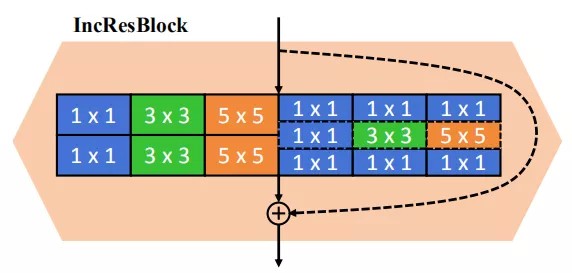
CAT方法裁剪使用的阈值(归一化层的缩放因子)根据压缩目标自动求出,无需迭代裁剪过程。蒸馏使用 KA(Kernel Alignment)衡量不同通道数的卷积结构之间的相似性。
OMGD(Online Multi-Granularity Distillation 多粒度在线蒸馏)
OMGD的思路非常清晰,就是用一个更深的模型和一个更宽的模型来进行蒸馏,一图以蔽之:
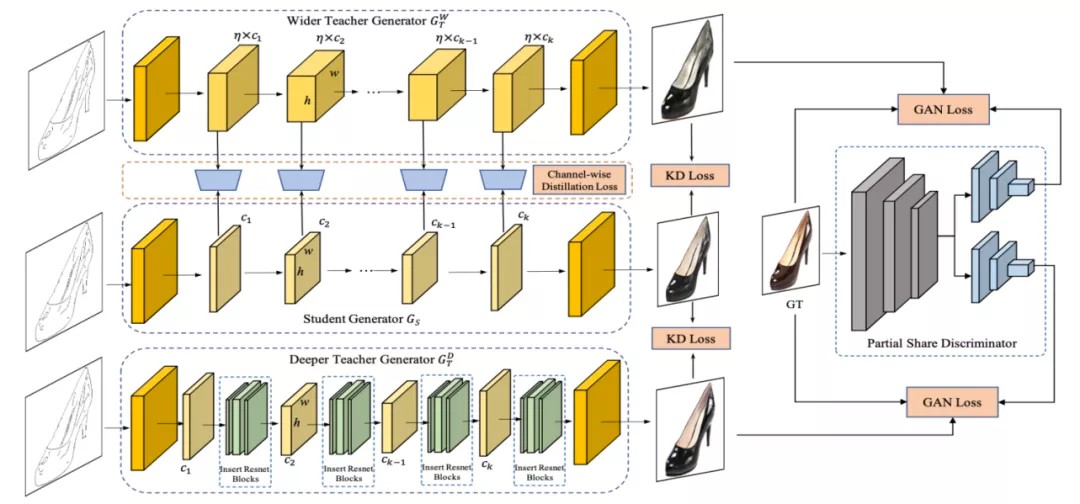
OMGD一边训练两个更深、更宽的教师生成器,一边用其进行蒸馏,能够使过程更加稳定,这就是在线。使用深度相同宽度更宽的教师模型进行蒸馏时,loss函数不但比对输出结果,而且对中间层的特征图也使用Structural Similarity (SSIM) Loss进行比对,是以称之为多粒度。
结语
最后,来看看“妙笔”是怎么“生画”的吧:

近期,更加风骚的GauGAN2发布了,八般武艺样样SOTA的女娲也发布了,甚至 StyleGAN也是啥任务都敢上,统统玩坏了,目测前方一大波好玩的模型来袭,让我们在元宇宙里happy地大GAN一场吧 !
为了便于大家体验各种GAN模型,这里附上一些发到AI Studio上的开源项目:
①GAN的“风格迁移五部曲”
《一文搞懂生成对抗网络之经典GAN》 https://aistudio.baidu.com/aistudio/projectdetail/551962
《一文搞懂GAN的风格迁移之Conditional GAN》 https://aistudio.baidu.com/aistudio/projectdetail/644398
《一文搞懂GAN的风格迁移之Pix2Pix》 https://aistudio.baidu.com/aistudio/projectdetail/1119048
《一文搞懂GAN的风格迁移之CycleGAN》 https://aistudio.baidu.com/aistudio/projectdetail/1153303
《一文搞懂GAN的风格迁移之SPADE论文复现》
https://aistudio.baidu.com/aistudio/projectdetail/1964617
《妙笔生画》
https://aistudio.baidu.com/aistudio/projectdetail/2274565
②GAN“前传”
《一文搞懂卷积网络之一(从LeNet到GoogLeNet)》 https://aistudio.baidu.com/aistudio/projectdetail/601071
《动手学深度学习》Paddle 版源码(经典CV网络合集) https://aistudio.baidu.com/aistudio/projectdetail/1639856
参考文献
[1] Park T, Liu M Y, Wang T C, et al. Semantic Image Synthesis With Spatially-Adaptive Normalization[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2019.

发表评论
登录后可评论,请前往 登录 或 注册