一文跟进Prompt进展!综述+15篇最新论文逐一梳理
2022.02.16 17:58浏览量:4855简介:prompt进展,15+篇论文逐一梳理。
文 | ZenMoore
编 | 小轶
自从 Dr.Pengfei Liu 的那篇 prompt 综述发表开始,prompt 逐渐红得发紫。近期清华、谷歌等单位你方唱罢我登场,涌现了好多好多 prompt 相关的论文。无论是工业界还是学术界,想必大家都在疯狂 follow。不少伙伴肯定从老板那里领到了 “prompt 技术分享” 的任务哈哈!
所以这篇文章先基于 7月份的 prompt survey 做一个简单扫盲,然后再为大家梳理一下其后 4 个月的 prompt 最新进展,共包括 15 篇论文。无论是作为大家调研 prompt 的 starter 也好,还是作为大家技术分享的 checklist 也好,希望都可以帮助到大家!
Prompt 扫盲
论文标题:
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
论文链接:
https://arxiv.org/abs/2107.13586
往期推文:
《Fine-tune之后的NLP新范式:Prompt越来越火,CMU华人博士后出了篇综述文章》
这篇就是入门必看的综述啦,非常精彩。这里做一个简单的概述。
NLP 的范式演进历程大体经历了这样四个阶段:
特征工程—>深度学习—>预训练+精调—>Prompt
后两个范式是讨论的重点:
预训练+精调范式:让预训练模型 (PLM) 去适应下游任务
Prompt 范式:让下游任务适应预训练模型 (PLM)
Prompt, 简单来说就是:将下游任务的输入输出形式改造成预训练任务中的形式,即 MLM (Masked Language Model) 的形式。
比如:对于情感分类,原有的任务形式是:输入:“今天天气好”输出:“正面情绪”标签的判别结果
在 prompt 范式下,这会将输入改造为:输入:“今天天气好,我的情绪是[MASK]的。输出:“开心”当然,具体实现的时候,还需要一个额外的映射将“开心”识别为“正面情绪”标签。这个映射显然是比较简单的。
更加形式化的定义如下图所示:
形式化地讲,在 prompt 范式下,需要通过以下三个步骤建立从输入到输出的 pipeline。

相应地,在使用 prompt 时,主要从以下五个方面进行考虑。在我们阅读 prompt 相关论文时,也要先搞清楚这篇工作是着重解决了以下哪个方面的问题。
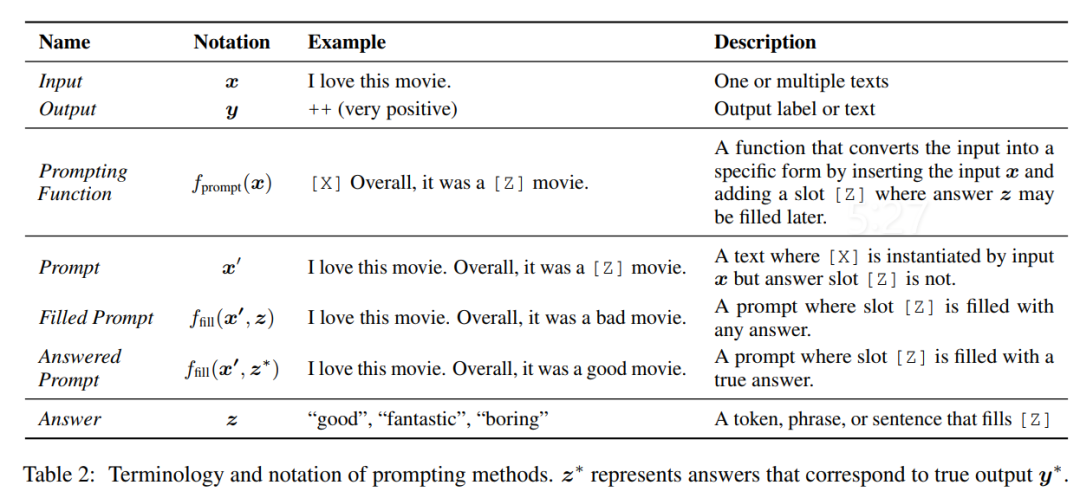
1.预训练模型的选择 :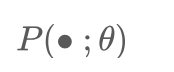
2.Prompt Engineering : 也就是模板
的实现方式,涉及两个方面
- Prompt Shape : prompt (准确地说应该是槽 [X]) 在文本开头叫做 prefix prompt, 在文本中间或者结尾叫做 cloze prompt.
- Prompt 的构建:可以手动设计,也可以自动构建(搜索、优化、生成等)。自动构建 prompt 的方法又可以按照 “离散(通常为文本形式)/连续(embedding space)” 或者 “静态/动态(是否随着输入改变)” 进行分类。
3.
4.Multi-prompt:如何设计多个 prompt 获得更好的效果?常见方式包括以下 5 种
- Prompt Ensembling : 集成学习(利用不同的 prompt 来进行各模型的差异化)
- Prompt Augmentation : 对 prompt 进行数据增强
- Prompt Composition : 把几个 prompt 进行合并
- Prompt Decomposition : 把一个 prompt 拆解为若干 sub-prompt
- Prompt Sharing : 不同的模型、task 等共享一套 prompt
prompt 范式下的训练策略:是否存在 prompt-related 参数? 对 LM 的参数以及 prompt-related 参数要不要进行 tuning ?根据这两个问题的答案进行组合,可得 5 种 parameter 更新方式,如下图所示: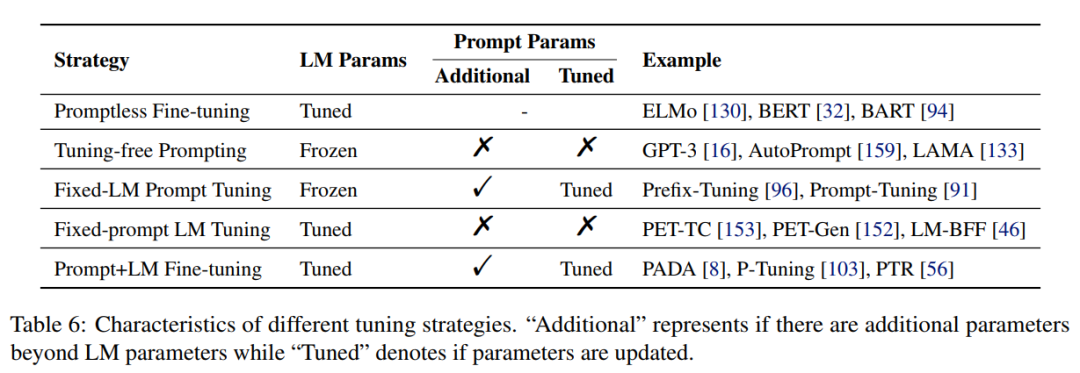
读完这篇 survey,基本就可以算是入门 prompt 了。强烈推荐大家看论文原文更为的详细梳理。
** **prompt 近四个月进展****
继这篇 survey 后,prompting 相关的论文更是层出不穷,常常一经发表就是爆款。相信大家肯定紧紧地跟住了时代的脚步,但难免记忆力跟不上看论文的速度:)
这里先给大家推荐几个 prompt 相关的资源。这几个网站持续更新着 prompt 的最新进展和开源代码,相信能有效帮助各位紧跟时事~
Prompting LeaderBoard
http://explainaboard.nlpedia.ai/leaderboard/prompting/
Homepage NLPedia
http://pretrain.nlpedia.ai/
Timeline of Prompt Learning
http://pretrain.nlpedia.ai/timeline.html
Follow-up : PromptPapers
https://github.com/thunlp/PromptPapers
Open-Source Framework : OpenPrompt
https://github.com/thunlp/OpenPrompt
接下来,我们也为大家梳理了今年 7 月以来的 15 篇最新 prompting 工作。如下表所示:
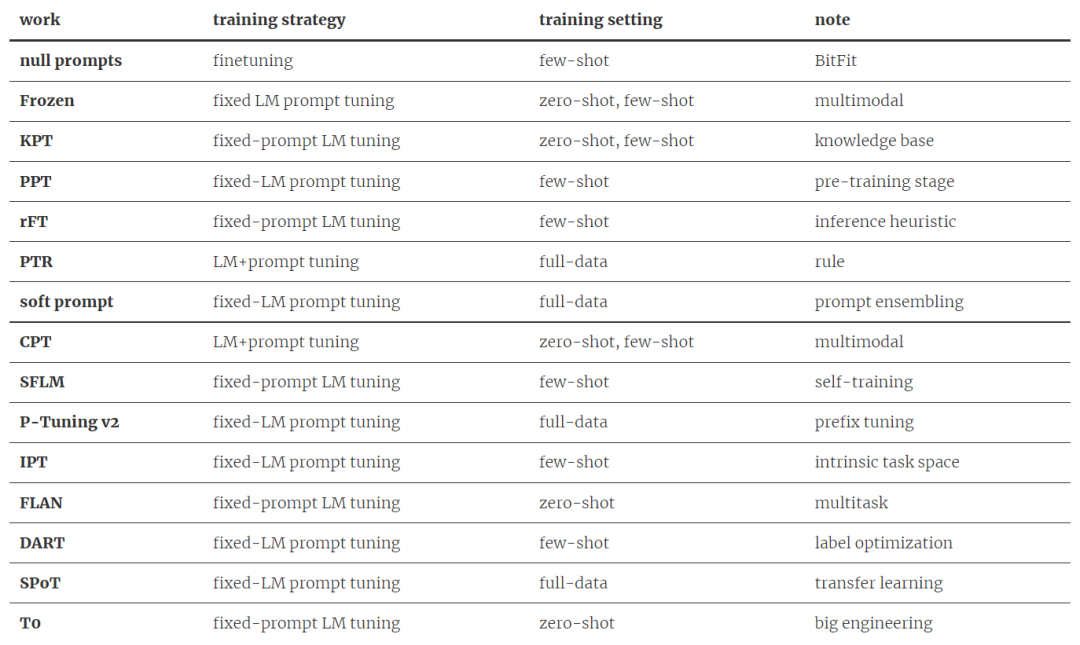
▲一表看尽本文
(注:以下所选工作按照 arxiv 发表时间进行排序。此处论文的选择可能有点主观,而且也不一定完全,仅作参考。相信在笔者所知之外,还有许多精彩工作。)
1.null prompts (07/01)
论文标题:
Cutting Down on Prompts and Parameters: Simple Few-Shot Learning with Language Models
论文链接:
https://arxiv.org/abs/2106.13353
Motivation
1.为每个下游任务都设计一套 prompt 模板费时费力。如何简化 prompt engineering ?
2.原来模型的训练参数量太大了。如何提升 memory efficiency 呢?
Method
既然设计模板那么费事,那么我们干脆就“自暴自弃”不设计模板好了。这篇文章就提出了所谓 null prompt 的方法,其实就是所有任务都用 input + [MASK] 的形式作为 prompt 模板。

▲null prompt 方法示意
Experiments
Simplifying Prompt Engineering
第一个实验是:基于 prompt 的 finetuning (有 prompt, 进行 finetuning)
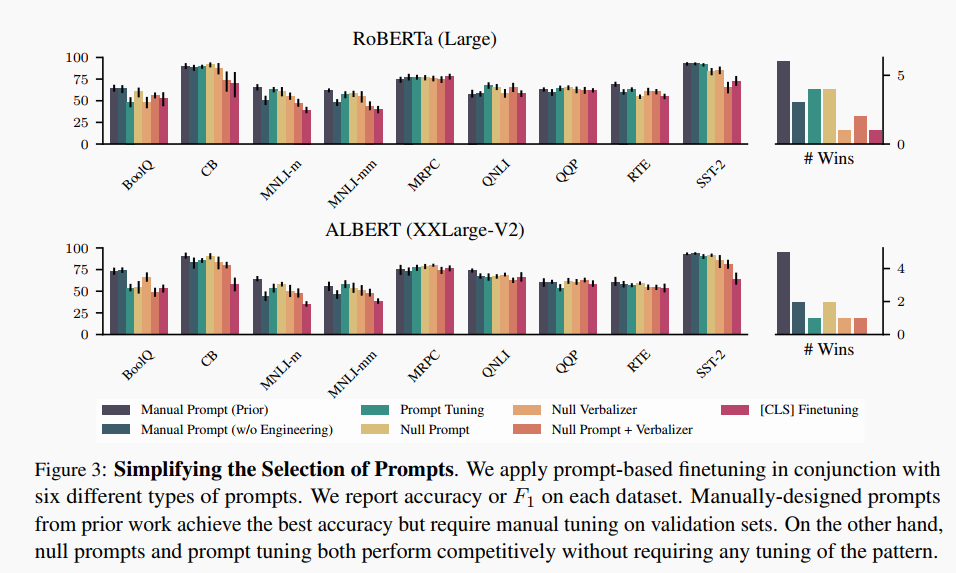
▲基于 prompt 的 finetuning
实验结论:
1.为每个任务手工设计一套 prompt 效果仍然是最好的, 但是太费时费力了。
2.null prompts 比 prompt tuning (fine-tune时对模板部分进行梯度优化)表现要好一点。
Prompt-Only Tuning
第二个实验是:自学习更好的 prompt 标识,不对 LM 进行 fine-tuning
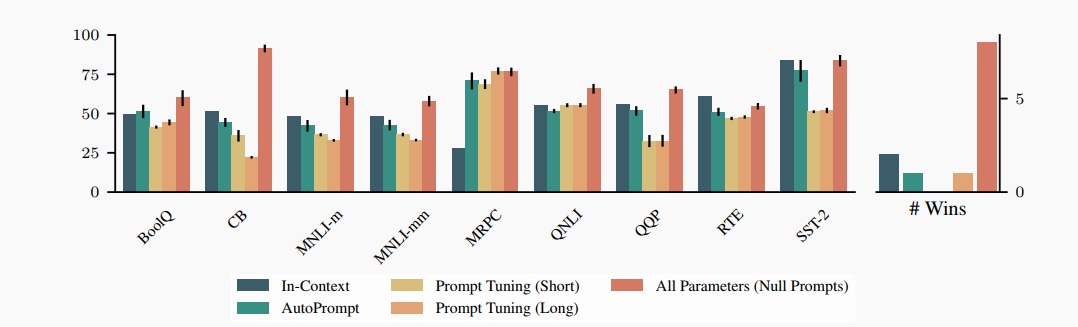
▲仅对 prompt 进行学习
上图中的 AutoPrompt 是指自动搜索离散 prompt。All Parameters 则是对 LM 做了 fine-tuning 的一组对照结果。
实验结论:Prompting 根本打不过 finetuning (不过作者说这可能并不矛盾,可能只是因为没有严格控制实验变量……)
Memory-Efficient
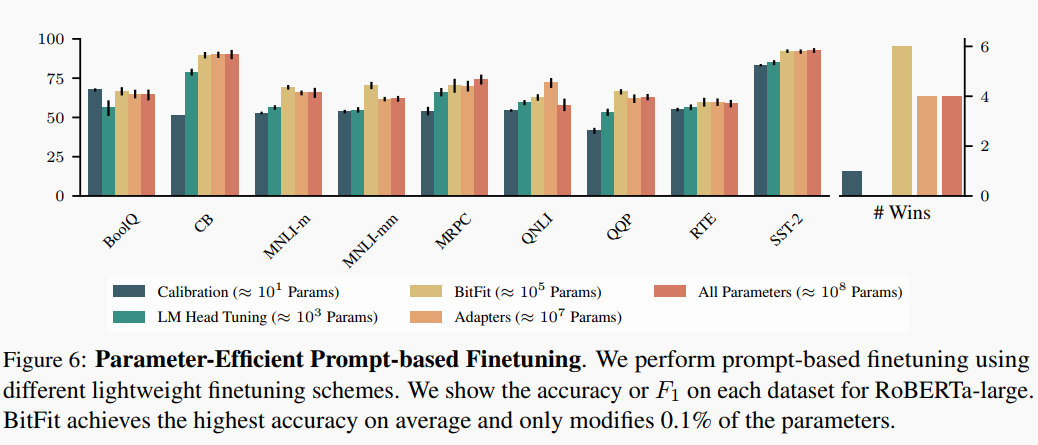
Adapters : 只调插入在 Transformer FNN 中的神经网络层。
Calibration : 在与 Verbalizer Tokens 相关的 logits 之上套一层仿射变换,只学习这个仿射变换。
BitFit : 只调 Transformer 的 bias 项。
LM Head Tuning : 只调与 Verbalizer Tokens 相关的输出层 embedding.
实验结论:BitFit yyds(永远的神) !
Conclusion
在 few-shot settings 下,最好的选择是:finetuning with null prompts and BitFit.
但是,这仅仅针对 MLM 而言。针对超大规模模型或者单向语言模型,需要进一步的研究。
2.Frozen (07/03)
论文标题:
Multimodal Few-Shot Learning with Frozen Language Model
论文链接:
https://arxiv.org/pdf/2106.13884.pdf
往期推文:
《学完文本知识,我就直接看懂图片了!》
Motivation
如何使用冻结参数的语言模型进行多模态任务
Method
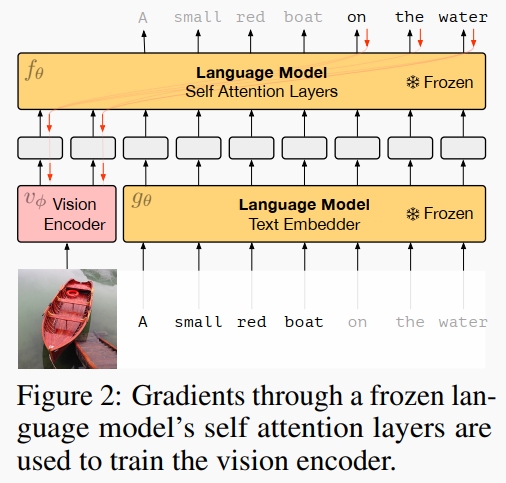
一图胜千言:冻结 LM 参数,只调输出以及视觉的 Vision Encoder(图中粉色部分)。LM 使用的是自回归的语言模型。视觉编码器基于 NF-ResNet-50,但是在视觉编码器之上套了一层线性映射,让其变成 Vision Prefix,类似于 Prefix Tuning [1] 的 Prefix (不过这里的 Prefix 是可以训练的)。这样,Image 就可以转变成 LM 可以理解的形式。
Experiments
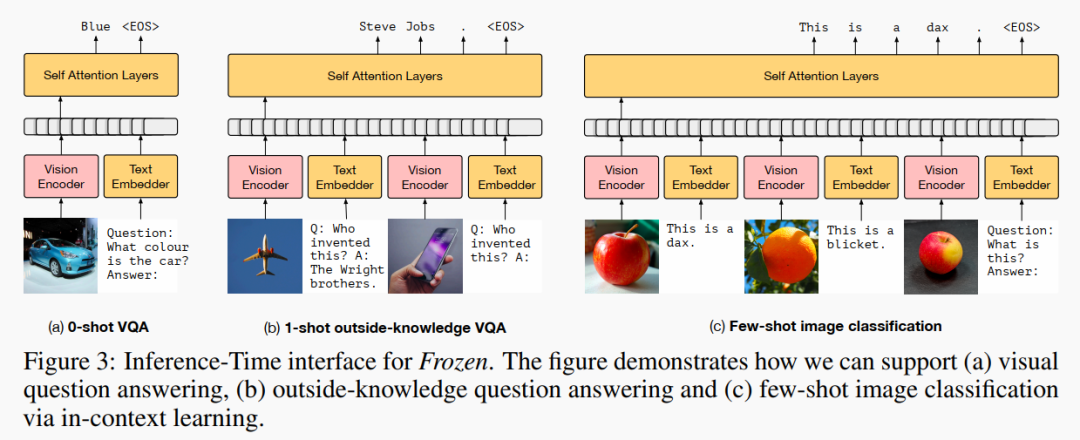
实验表明,这个模型在 zero/one/few-shot 三种 Setting 下都能有比较好的效果。虽然不是 SOTA,但是思想非常有开创性!
另一个有意思的结论是:仅用语言训练的 Transformer 所含的知识可以迁移到其他模态任务中。
3.KPT (08/04)
论文标题:
Knowledgeable Prompt-tuning : Incorporating Knowledge into Prompt Verbalizer for Text Classification
论文链接:
https://arxiv.org/abs/2108.02035
Motivation
主要解决 Verbalizer 的构建问题(不清楚 verbalizer 是什么的同学,可以参考开头“prompt 概述部分”)。人工构建映射表肯定麻烦,也不是很够用,所以就要引入外部知识库来构建啦。
Method
分为三步:
Verbalizer Construction:
使用 ConceptNet 或者 WordNet 等知识图谱,以目前的标签词为锚点,寻找其相邻节点的标签词作为 answer mapping 的 candidates。
Verbalizer Refinement:
上一步的 candidates 噪声还很多,分两种情况解决。
1、zero-shot setting :
- KB 中的词汇在 PLM 的 OOV 中:对该词的各个 token 计算平均概率作为词的概率,然后使用阈值清理
- PLM 中的稀有词概率不稳定,如何去掉:计算上下文先验(contextualized prior)。(公式见下)这里 是句子, 是 template, 表示一个人为定义的小的未标注的 support set. 然后使用阈值清理。
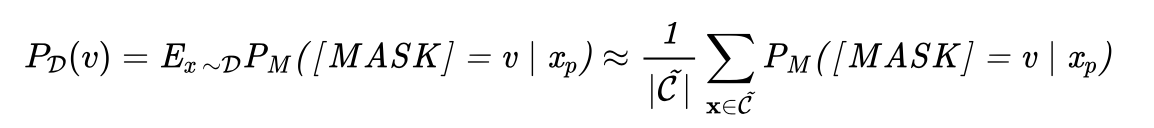
由于 KB 中词汇的先验分布不同,一些词汇天然地更不可能被预测到:使用上下文校正(contextualized calibration, CC)
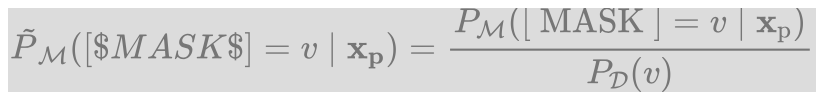
2、few-shot setting :
- 因为有少量数据可以用来训练,所以去噪更简单一些
- 直接使用每个候选词归一化后的权重:
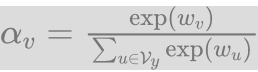
, 这里 w是可以训练的
Verbalizer Utilization:
得到了去噪的候选词列表之后,下面就要决定怎么把 label words 映射为 class label 啦!
zero-shot setting 用平均:
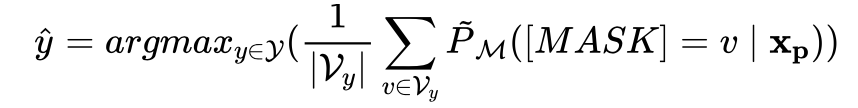
few-shot setting 用加权平均(in log-space):
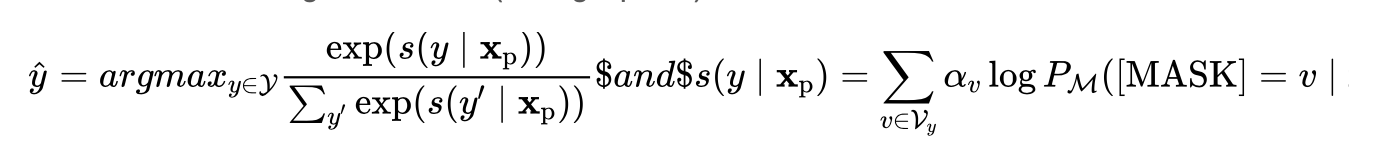
4.soft prompt (09/02)
论文标题:
The Power of Scale for Parameter-Efficient Prompt Tuning
论文链接:
https://arxiv.org/abs/2104.08691
这篇工作有两种常用的简称 : soft prompt/prompt tuning, 鉴于后者容易和广义的 Prompt Tuning 混淆,我们使用第一种 —— soft prompt。
Motivation
对 prefix tuning 的进一步简化 : prefix tuning 会训练所有与 prefix prompt 相关的层。而这篇文章 : 针对每个下游任务,只调输入文本前面的一些 tokens (soft prompt)。另外,这篇文章还提出了 Prompt Ensembling。
Method
- prompt tuning : 输入头部新加了一些 tokens 作为 soft prompt, 它以
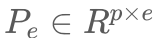
表示 (p 是 prompt length, e是 embedding space 的维度),然后输入这么整 :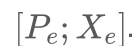
. 我们在 tuning 时,只能动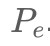
. - prompt 的长度和初始化 : 初始化的话一般使用 PLM vocabulary 的 embedding, 对于 CLS 任务也可以直接使用 class label 的 embedding,长度的话建议看原文的实验数据。
- prompt ensembling : 这个概念也是这篇论文首次提出来的。简单来说,就是使用多个 prompt 集成学习。
Comparison
- v.s. prefix tuning : prefix tuning 会训练所有与 prefix prompt 相关的层,而本文只训练
; prefix tuning 基于 GPT-2 和 BART,主要考虑生成任务,本文基于 T5. - v.s. WARP [7]: WARP 对 MLM 的 prompt 相关的输入层和输出层进行精调。
- v.s. P-tuning [4]: P-tuning 使用人工设计的 template, 然后对穿插在 input 各个位置的 continuous prompt 进行微调;P-tuning 提供的是 Tuning-free Prompting 和 LM+Prompt Tuning,而本文提供的是 fixed-LM prompt tuning.
- v.s. Adapter [8]: Adapter 不动 input representation, 动的是作用在 input representation 上的函数(神经网络);而本文不动作用在之上的函数,动的是 input representation (soft prompt
).
还有另外一些对比,感兴趣的看原文哦~
5.rFT (09/09)
论文标题:
Avoiding Inference Heuristics in Few-shot Prompt-based Finetuning
论文链接:
https://arxiv.org/abs/2109.04144
Motivation
在进行 sentence pair classification 的时候,如果是 few-shot setting, 使用 prompt-based finetuning 很容易产生启发式推理(Inference Heuristics)的问题(即:模型假设具有相同单词集合的句子会带有相同的意思), 然而这个问题在 zero-shot setting 下不会出现,所以可以说 finetuning 对 PLM 中的知识产生了很大的负面影响(灾难性遗忘),因此,作者旨在解决 few-shot setting 下 prompt-based finetuning 的上述问题。
Method
总的来说就是,基于弹性权重巩固 (EWC) [2] 对 prompt-based finetuning 进行正则化。熟悉终身学习的应该对 EWC 不会陌生,它建立在 Fisher 矩阵之上专门用来解决灾难性遗忘问题。当然,Fisher 矩阵的计算需要一部分预训练数据,为了躲开这个,我们假定 Fisher 信息和对应的权重具有很强的独立性,这样,总的损失函数就变成了:
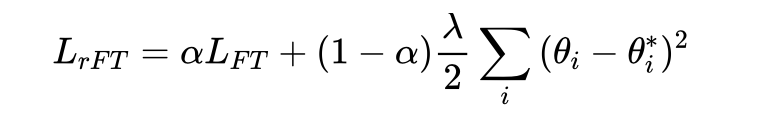
(FT=finetuning,=标准交叉熵损失)。优化器的实现使用的是 RecAdam[3].
Experiments
1.在 in-distribution 的结果上,finetuning 要优于 rFT, 并且大幅优于 zero-shot (使用 prompt, 但不进行 finetuning).
2.但在避免 Inference Heuristics 上,rFT 的效果比 finetuning 好,当然,还不及 zero-shot.
3.所有 Prompt-based Finetuning 方法,都要好于单纯的 finetuning 方法(即使用 classification head).
6.PPT (09/14)
论文标题:
PPT: Pre-trained Prompt Tuning for Few-shot Learning
论文链接:
https://arxiv.org/abs/2109.04332
Motivation
在数据足够的情况下,Prompt Tuning 和 Finetuning 效果差不多,但是在 few-shot setting 下,prompt 的表现很不好,作者认为是因为 soft prompt initialization 的问题,因此,如果把 soft prompt 也放在 pre-training stage 里面,以获得一个更好的 initialization, 是不是更好一点?
Pilot Experiments
主要是四点结论:
1.Verbalizer 的选择很重要
2.使用词向量初始化 soft prompt 没啥用
3.hard prompt + soft prompt 很有用
4.上面三种,在 few-shot setting 下都完蛋
Method

Experiments
1.finetuning 的性能随着参数量提升。
2.PPT 在大部分数据集下比 prompt tuning 和 LM adaption 性能要好,基本在所有任务上优于 finetuning。
3.虽然 few-shot learning 的方法方差一般都很大,但 PPT 显著减小了方差。
4.Hybrid PPT 和 PPT 效果差不多,但 Unified PPT 比另外两种要稍微好一点。
7.PTR (09/15)
论文标题:
PTR: Prompt Tuning with Rules for Text Classification
论文链接:
https://arxiv.org/abs/2105.11259
Motivation
人工构造 pattern 太繁琐,自动构造的话,一方面效果比不上人工构造,另一方面还引入了额外的计算(生成+有效性验证)……
那能不能使用规则给 prompt 的构建加入一些先验知识呢?
Method

然后为每一个 conditional function 设计一个 sub-prompt, 老规矩,它由 template 和 verbalizer 构成:
例如:

Experiments
PLMs 中蕴含的知识非常重要。
引入知识的方式也很重要,例如在 finetuning 阶段引入的知识比在预训练阶段引入的更容易被提取利用出来。
所有里面,PTR 是 SOTA。
总之,预训练可以给 PLM 引入很多任务特定的知识,但是如何激发他们很重要!这里,PTR 的方式比 finetuning 方式更加有用!
8.CPT (09/24)
论文标题:
CPT: Colorful Prompt Tuning For Pre-Trained Vision-Language Models
论文链接:
https://arxiv.org/abs/2109.11797
Motivation
视觉-语言预训练模型 (VL-PTMs) 也存在和 PLMs 一样的问题:预训练任务和下游任务的 gaps. 能不能把 prompting 引入 VL-PTMs 里面呢?
Method
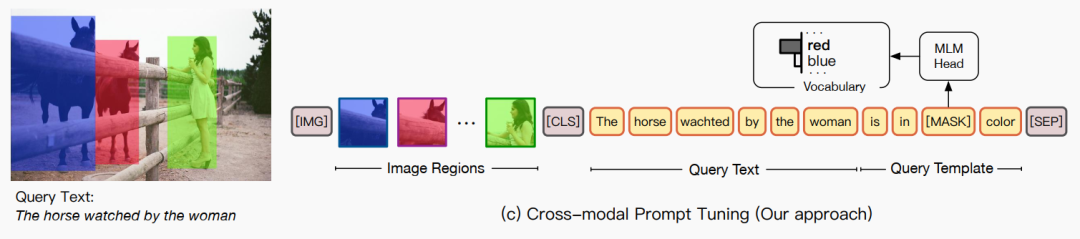
prompt design 的核心问题是:如何用语言描述图像?

在实现细节上,一方面需要考虑选取哪些颜色,所以需要用候选集做一个 prompt search;另一方面,需要考虑怎么划分 region,所以需要把 image region 划分成一些 batch 处理…… 更详细的建议看开源代码。
Experiments
1.CPT 在 zero-shot setting 和 few-shot setting 下效果提升明显
2.CPT 比 finetuning (vanilla) 的方差要小得多
3.在 full-data setting 下,CPT 和 vanilla funetuning 的效果不相伯仲
9.SFLM (10/04)
论文标题:
Revisiting Self-Training for Few-Shot Learning of Language Model
论文链接:
https://arxiv.org/abs/2110.01256
Motivation
就是题目中的设定,怎么在 few-shot 下提取 PLM 中蕴含的海量 unlabeled data 的信息(知识)。
Method
为了解决这个问题,作者设计了一种基于自训练 (self-training) 的 prompt 方法。

监督损失(针对已标注数据)就是以前的 prompt-based tuning 那一套(即 template + verbalizer 等等),这篇论文的新颖点主要是后面两项(针对未标注数据):
- 自训练损失:首先用简单的 dropout 对未标注的数据做一个弱数据增强(weakly-augmented), 训练一下模型, 然后再用训练好的模型跑出未标注数据的伪标签(作为下一步的监督信息),然后对未标注数据做一个强数据增强 (15% mask 概率 + dropout),最后将其输入模型并以伪标签作为监督信息进行损失计算与训练。
- 自监督损失:最最传统的 MLM. 这一项主要是为了作为正则化。
Experiments
1.在 few-shot setting 下,自训练机制可以大幅增进传统 prompt-based finetuning 的性能。
2.对部分任务而言,未标注数据对半监督学习方法很是关键。
3.SFLM 的方差很小。
4.本文中的提出的那两种文本数据增强的方法(强/弱数据增强)也很棒!
5.自训练机制的性能增益与未标注数据的总量并不成严格正比。
10.FLAN (10/05)
论文标题:
Finetuned Language Models are Zero-Shot Learners
论文链接:
https://arxiv.org/abs/2109.01652
往期推文:
《别再Prompt了!谷歌提出tuning新方法,强力释放GPT-3潜力!》
另简称 : Instruction Tuning
Motivation
改善语言模型的 zero-shot 学习的能力。
Method
作者先收集整理了一系列任务集合(task cluster),每个任务集合包含若干特定的数据集,有 NLU,也有 NLG,之后的 instruction tuning 就是在若干 task clusters 上训练的。
tuning 方法有点像 GPT-3 的那种 prompting, 但是又有区别:
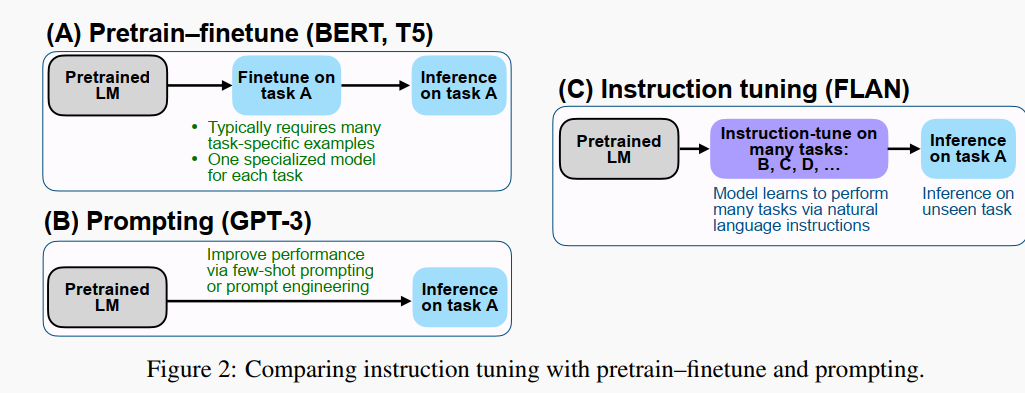
1.众所周知,GPT-3 不做进一步地精调,只是在 inference 时候,在开头提供一些 examples (instructions) 和 prompt,称作 in-context learning;但是这篇工作是要做精调的,把类似的 instruction 作为 tuning 时候的训练数据。
2.GPT-3 是单任务的,而这篇工作在 tuning 阶段使用多任务,每个任务都人工设计了一个 instruction template,把 template 填充之后就变成了 tuning 时候用的训练 examples。
3.tuning 完成之后,把模型用于全新的 (unseen) 任务进行 inference, 这一次,不用 instructions (GPT-3), 就能达到很好的效果。
Experiments
1.在大多数任务上超越了 zero-shot GPT-3。
2.间接表明,任务特定的训练是对通用语言模型的一个补充。
3.在很多数据集上,BERT/T5 仍然保持着最好的效果。
4.更多实验结论与发现建议阅读原论文。
11.DART (10/06)
论文标题:
Differentiable Prompt Makes Pre-trained Language Models Better Few-shot Learners
论文链接:
https://arxiv.org/abs/2108.13161
Motivation
是面向工业界的一个改进。在工业落地上,主要有两个问题:一方面模型规模太大了,部署成本太高;另一方面 prompt design 的成本也太高了。因此,作者设计了 DifferentiAble pRompT (DART),具备 pluggable、extensible、efficient 的特点,并且在不需要 prompt engineering 的情况下,也能增强小规模语言模型的小样本学习能力。
Method
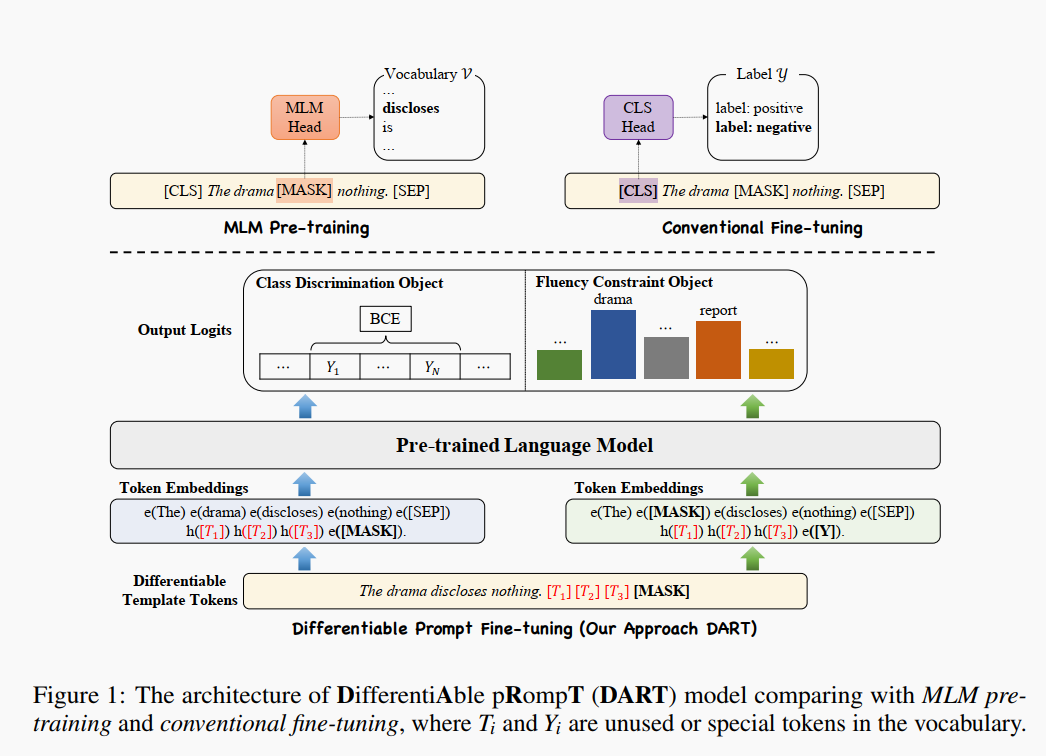

第一个损失函数是 label optimization 的过程,这在之前已有的 prompt tuning 方法中也不常见,因为这里的 answer 相当于也是在一个连续的空间里面。
第二个损失函数的设置主要是为了保证 template token embedding (可训练)与其上下文的相关性,这在 P-tuning 方法中通过双向 LSTM 解决,而本文的方法,没有引入额外的参数与模型,单使用一个损失函数,就解决了问题。另外,这里使用的是 ground-truth label…… (感觉是不是会泄露一部分标签信息啊?)
Experiments
1.对于 BERT-style 模型,比传统的精调范式的效果要好很多。
2.除了 BERT-style 的模型外,GPT-style 也能使用,而且效果也比原来的模型要好。
3.比 P-tuning 还好一点,看来 label optimization 是有用的。
4.这个模型可以 plug 到其他的语言模型,也可以 extend 到其他的任务上。
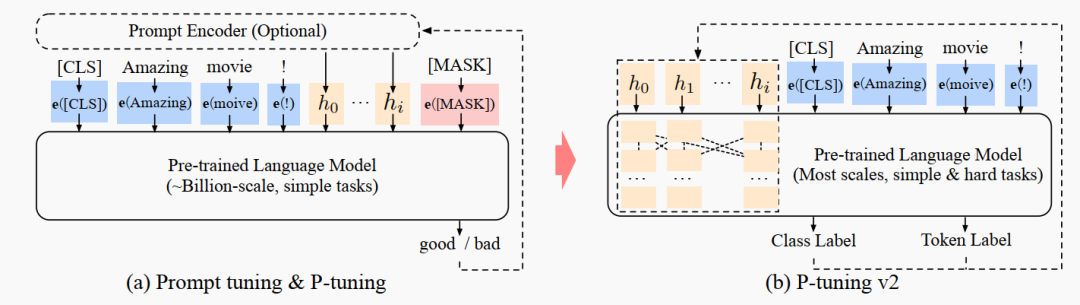
12.P-Tuning v2 (10/14)
论文标题:
P-Tuning v2: Prompt Tuning Can Be Comparable to Finetuning Universally Across Scales and Tasks
论文链接:
https://arxiv.org/abs/2110.07602
Motivation
之前的 soft prompt (google) 和 P-tuning [4] 只对大模型有效,而且也仅仅用于解决一些简单的 NLU 任务。
因此这个工作主要是扩展之前的 P-Tuning:适配小模型,适配复杂的 NLU 任务 (如序列标注等)。
Method
其实比起 P-tuning 或者 Google 的 soft prompt 的方式,这个更类似于 prefix tuning, 即和 prefix prompt 相关联的一系列层都能调。一图胜千言:
另外几点考虑是:
1.去掉了重参数化:比如 prefix tuning [1] 中的 MLP 以及 P-tuning 中的 LSTM,都不要了,因为这东西对效果提升不大。
2.多任务学习:这个挺有必要的,一方面可以减小 prompt 随机初始化的压力,另一方面可以更好地搞到跨任务/数据集的知识。
3.不用 verbalizer 了 : 其实对于复杂的 NLU 任务来说,verbalizer 的设计很不直观,那么就返璞归真,沿用原始的 [CLS]/token (hidden state) + MLP 就好。
Experiments
无论是大模型还是小模型,P-Tuning v2 的效果都很可观,而且对超参更鲁棒更稳定一些。
soft prompt (google) 和 P-Tuning 在复杂的 NLU 任务上不好看,尤其是 QA. 但是,P-Tuning v2 就好很多。
值得一提的是,除了 QA 外,多任务机制对 P-Tuning v2 的效果提升很是显著,所以它真的能很好地减轻随机初始化的压力?
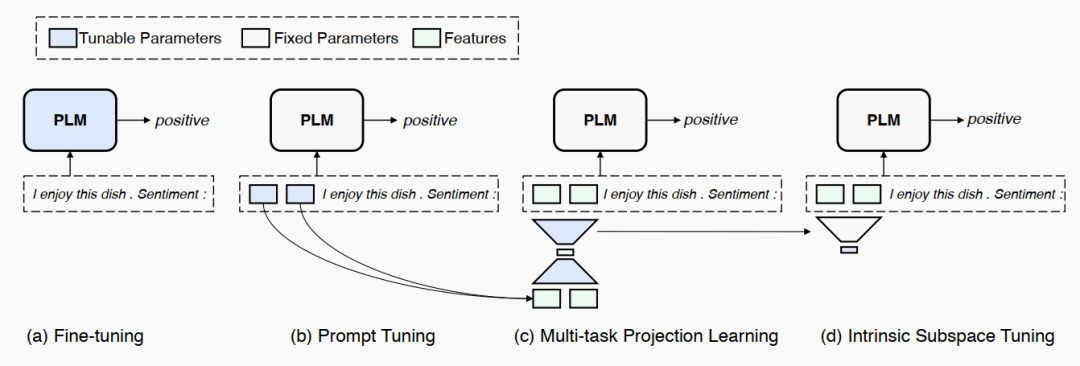
13.IPT (10/15)
论文标题:
Exploring Low-dimensional Intrinsic Task Subspace via Prompt Tuning
论文链接:
https://arxiv.org/abs/2110.07867
IPT = intrinsic prompt tuning.
Motivation
为什么 PLM 可以做好多好多不同的下游任务?这篇文章旨在探索每个下游任务的低维本征子空间 (intrinsic task subspace).
Method
这个问题的一个解释是:PLM 对一个特定任务的适配可以重参数化为一个低维的任务特定的优化子空间,只需要优化这一部分参数,就能够适配下游任务。这样的话,PLM 就是一个通用的压缩框架,把不同任务的学习复杂度从一个高维的空间压缩到了一个低维的空间。
怎么做实验呢?用 prompt tuning !
为了简化实验,将所有的任务都用一个 seq2seq 的形式表示 [5][6]。
Multi-task Subspace Finding : 将训练好的 prefix prompt feature 保留下来,经过一层投影降维,再经过一层投影恢复维度。这个步骤的损失函数包括原本 LM 的损失函数以及 prompt feature 的重构损失。
Intrinsic Subspace Tuning : 我们看看这个子空间能不能泛化到 unseen 的数据与任务上,如果可以的话,就说明我们找到了 intrinsic task subspace. 这一步的损失只保留 LM 的损失。
Experiments
1.在 few-shot setting 下,大模型对各种任务的适配过程确实可以通过一个低维子空间刻画,这个子空间仅用很小的维度(仅仅为 5) 就能在 unseen 的数据和任务上分别达到 prompt tuning 87% 和 65% 的性能。
2.非分类任务 (non-cls) 比分类任务 (cls) 的本征子空间维度要小,这个结论挺反直觉的。
3.更多结论建议详读原论文。
14.SPoT (10/15)
论文标题:
SPoT: Better Frozen Model Adaptation through Soft Prompt Transfer
论文链接:
https://arxiv.org/abs/2110.07904
Motivation
还是为了增强模型在不同任务上的泛化性能,不过是基于 Prompt Tuning.
换句话说:Transfer Learning + Prompt Tuning.
Method
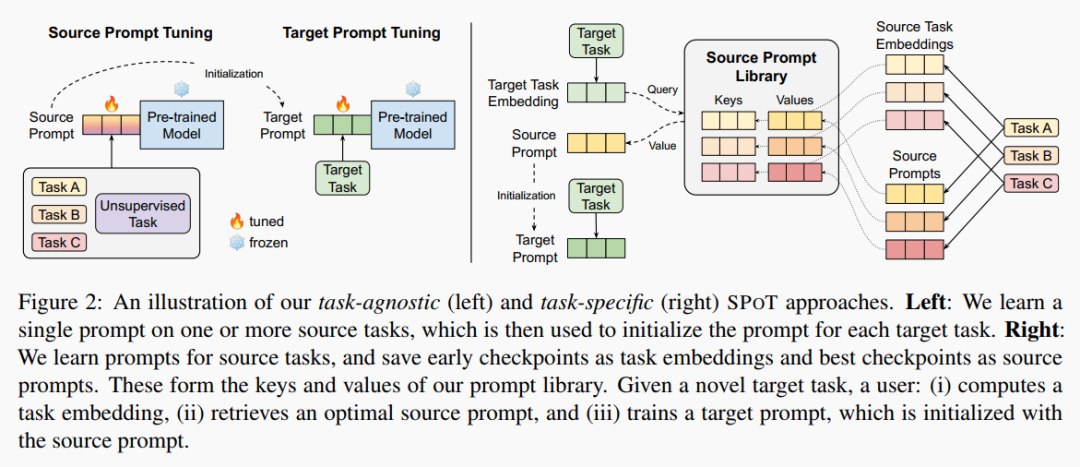
Task-Agnostic Approach : 先使用 multi-task training 得到一个 soft prompt, 用其作为目标任务的初始化。
Task-Specific Approach : 为了进一步提高效率,作者做了一个 prompt library. 先在一系列源任务上进行学习,取早期的 embedding 作为键,相应的最优 soft prompt 作为值。当我们需要解决目标任务时,把目标任务的早期 embedding 作为 query,与库中的键计算余弦相似度,从而检索到相应的值 (soft prompt) 作为初始化,再对 target prompt 进行进一步的优化。
Experiments
在 GLUE 和 SuperGLUE 上,SPoT 的性能和稳定性都要显著优于以往的 Prompt Tuning 算法。
源任务的混合 (multi-task) 可以提升性能。
无论模型大小如何,SPoT 都能够让 Prompt Tuning 范式达到与 Finetuning 范式差不多的效果。
另外,在 task embedding 上也有一些有意思的结论:
1.通过 prompt transfer, 各任务之间可以互相促进。
2.task embedding 捕捉了任务间的相关性信息。
3.task embedding 的相似性与任务间的可迁移性具有正相关关系。
15.T0 (10/15)
论文标题:
Multitask Prompted Training Enables Zero-Shot Task Generalization
论文链接:
https://arxiv.org/abs/2110.08207
快去打开 arxiv,感受一下什么叫做:鸿篇巨制……
Motivation
大模型具有很好的零样本泛化能力 (zero-shot generalization),这取决于它隐式的多任务学习机制(也就是 GPT-3 的那种外循环机制)。
那么能不能通过显式的多任务学习机制(即带有 prompt engineering) 来激发大模型的零样本泛化能力呢?
Method
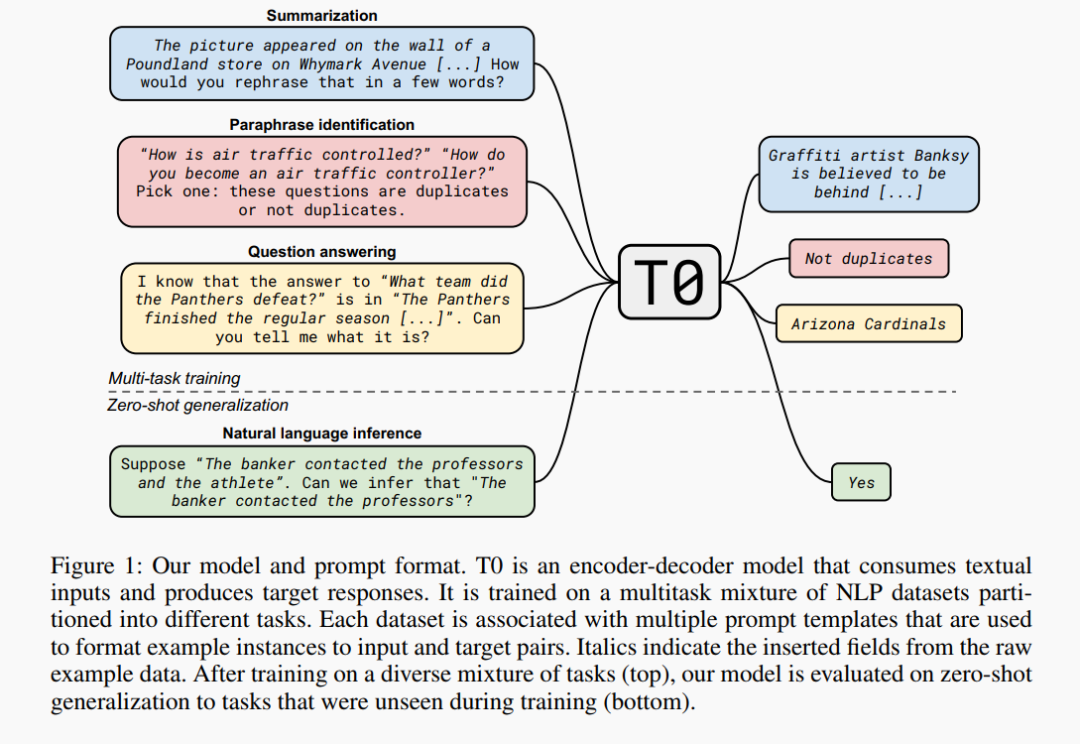
这张图就是 T0 的基本思想,然后具体的实现方法上,讲求两个关键:粗暴!协作!
Prompt 设计:类似于 FLAN 的 instruction,具体的例子可以看图。
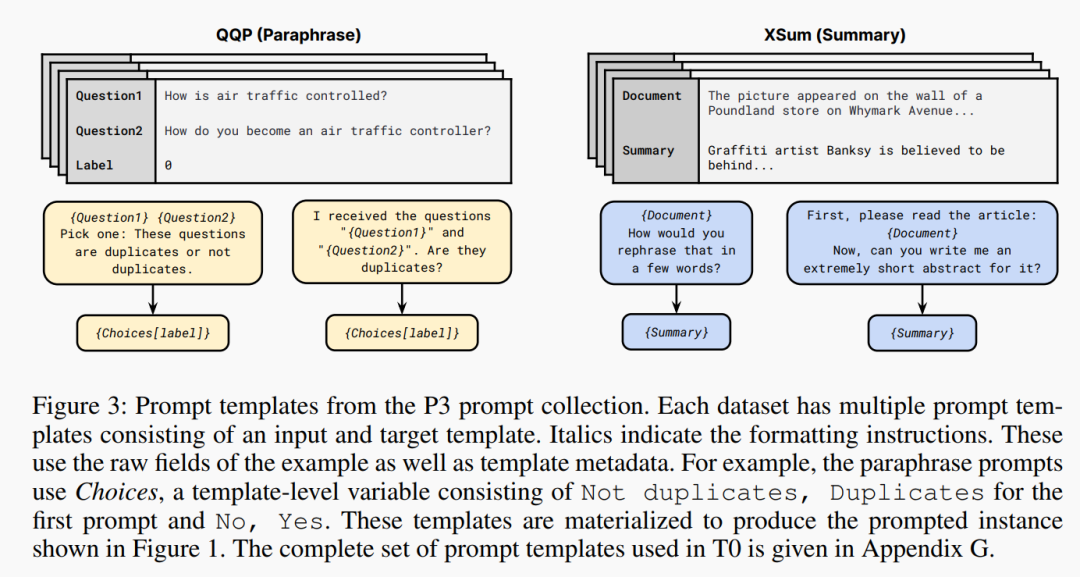
BIG-Bench : 新的 benchmark,收集了好多好多任务,一部分混合起来用来训练,留一部分用来做 zero-shot 的测试。
先说怎么个粗暴法:多任务数据集达 171 个,Prompt 达 1939 个,模型也是超大的(T5, 11B)!
当然,粗暴这一点咱们见怪不怪,毕竟前面已经有 GPT-3 啦~
但是这个协作方式感觉更有意思:42 位作者来自于 20 多家不同的机构,甚至来自于将近 10 个不同的国家!
据小编调查,这些大牛们是通过 Github、Notion 等等进行协作的,定期还要开个视频会议什么的,在 BigScience 的 notion 上可以看到他们的一些管理条例等等。
属实一番科幻片里面才有的协作方式哇!
Experiments
1.与 GPT-3 相比,zero-shot 性能提升显著,参数量缩减至 1/16.
2.与 FLAN 相比,zero-shot 性能非常能打,参数量缩减至 1/10.
3当增加训练数据集数量:性能的中位数会有所提升,但是性能的极差不会减小。
4.当增加 prompt 数量:泛化性能会有所提升。
** 最后的话
Prompt 作为热点,学术界工业界都在讨论。感觉 prompt 的贡献主要在于三点:低资源场景 (few-shot/zero-shot),低算力场景 (parameter-efficient) 以及统一场景(把各种各样的问题统一成一套 prompt). 然后根据上文按照时间顺序的详细梳理,不难发现 prompt 的发展趋势:多任务、多 prompt、任务 specialization 以及各种各样的锦上添花。当然,prompt 还方兴未艾,仍然有很多疑问需要探索:在学术界,prompt 究竟告诉了我们什么,PLM 到底蕴含着怎样的力量,如何彻底激发出来,或者 PLM 本身路在何方?在工业界,prompt 究竟该如何落地,相比于 finetuning 是否真正具有决定性的优势?希望这篇长文能够带给你更多的思考……
**参考文献**
[1] Li, X., & Liang, P. (2021). Prefix-Tuning: Optimizing Continuous Prompts for Generation. ArXiv, abs/2101.00190.
[2] Kirkpatrick, J., Pascanu, R., Rabinowitz, N.C., Veness, J., Desjardins, G., Rusu, A.A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., Hassabis, D., Clopath, C., Kumaran, D., & Hadsell, R. (2017). Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences, 114, 3521 - 3526.
[3] Chen, S., Hou, Y., Cui, Y., Che, W., Liu, T., & Yu, X. (2020). Recall and Learn: Fine-tuning Deep Pretrained Language Models with Less Forgetting. EMNLP.
[4] Liu, X., Zheng, Y., Du, Z., Ding, M., Qian, Y., Yang, Z., & Tang, J. (2021). GPT Understands, Too. ArXiv, abs/2103.10385.
[5] Raffel, C., Shazeer, N.M., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., & Liu, P.J. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. ArXiv, abs/1910.10683.
[6] Khashabi, D., Min, S., Khot, T., Sabharwal, A., Tafjord, O., Clark, P.E., & Hajishirzi, H. (2020). UnifiedQA: Crossing Format Boundaries With a Single QA System. FINDINGS.
[7] Hambardzumyan, K., Khachatrian, H., & May, J. (2021). WARP: Word-level Adversarial ReProgramming. ACL/IJCNLP.
[8] Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., Laroussilhe, Q.D., Gesmundo, A., Attariyan, M., & Gelly, S. (2019). Parameter-Efficient Transfer Learning for NLP. ICML.

发表评论
登录后可评论,请前往 登录 或 注册