基于飞桨实现的“太空保卫战士”——地球同步静止轨道空间目标检测系统
2022.02.21 14:35浏览量:350简介:基于飞桨实现的''太空保卫战士''——地球同步静止轨道空间目标检测系统

项目背景及赛题介绍
卫星的应用十分广泛,许多行业每天都依赖其运作。我们通常会根据高度把人造地球卫星运行的轨道简单地分类为低轨道(200千米~2000千米)、中轨道(2000千米~20000千米)和高轨道(20000千米以上)。
地球同步静止轨道属于高轨道,与赤道平面成0度角,静止轨道卫星运行方向与地球自转方向相同,运行周期与地球同步,和地球上的我们保持相对静止,上面运行着很多国家的大型通信卫星。有限的地球同步静止轨道资源珍贵,因此,为使运行中的卫星免受可能的碰撞,对运行空间内空间碎片和自然天体等未知空间目标进行及时的检测、跟踪、预警和编目是“太空保卫战士”保障卫星活动正常健康的一项重要工作。

本项目基于2020年欧空局联合阿德莱德大学举办的地球同步静止轨道及附近的目标检测SpotGEO Challenge竞赛,实现“太空保卫战士”——太空空间目标检测系统,从而检测低成本望远镜采集图像中的微弱空间目标,包括空间碎片、非合作飞行器等等。
项目链接:
https://aistudio.baidu.com/aistudio/projectdetail/2285947?shared=1
数据集介绍
目前,国际上用于空间目标探测识别的系统一般包括地基系统和天基系统两部分,观测设备包括巡天望远镜和CCD摄像机等等。本比赛提供的数据集是由搭载在地基望远镜上的低成本CMOS相机在夜间拍摄得到,相机曝光时间为40s,连续拍摄5帧成为一个序列。
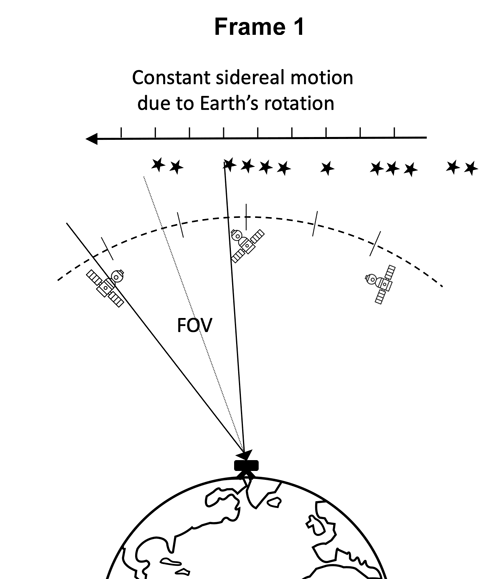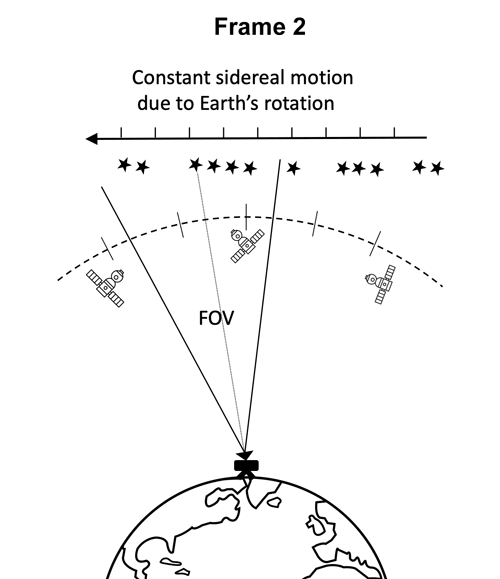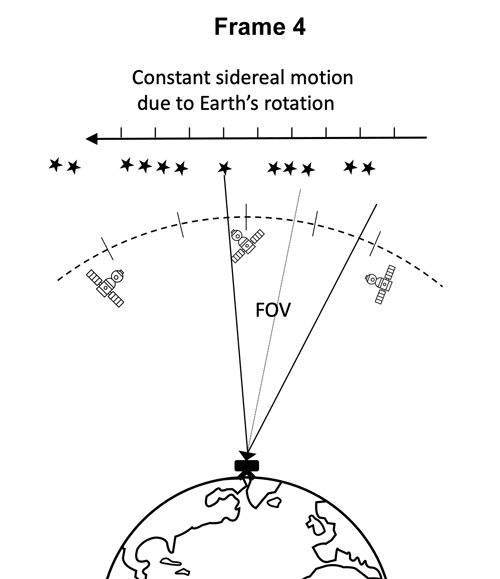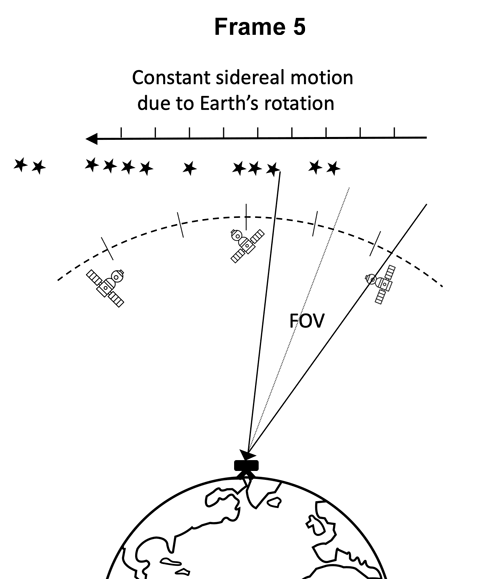
地基望远镜数据采集示意图
在相机曝光时间内,除了地球静止轨道附近的目标或天体之外的其他背景恒星与地球存在相对速度,所以在图片中背景恒星呈现条纹状。而GEO目标保持相对静止,在图像中大多以斑点或短条纹的形态出现。帧序列拍摄过程中,相机所在的望远镜做匀速转动,所以空间目标的运动轨迹为直线。

数据集示例
这是比赛提供的数据集的结构组成,解压后的数据集同级目录下包括train和test两个文件夹以及对应的两个标注文件。训练集和测试集分别包含若干序列以及组成序列的帧图像组成的两级目录。图片格式为PNG格式,尺寸大小是640x480,整个数据集的图片总数量为 32000张,其中训练集包含1280个序列6400张,测试集5120个序列25600张。
标注文件格式:每幅图像的标注包括四组值,分别为是帧序列号、帧图像序号、目标数量以及对应位置坐标(x,y)。

数据集组成示例
目标特性
我们把需要解决的问题进一步具体化,概括起来就是星空背景下的序列图像小目标检测。
目标特性:在图像中,我们关注的目标在图像里大多以斑点或短条纹的形态出现,而非完全以点目标的形式存在,目标整体亮度也较暗,这是由于较长的曝光时间和大气畸变、传感器缺陷等原因产生的像素弥散现象。而且除此之外,由于云层覆盖、大气/天气影响、光污染、恒星遮挡(背景恒星碰巧越过轨道物体位置)等各项状况因素也增加了问题的难度。数据集中会存在异常高亮的伪目标、或者目标对象只出现在序列内5帧图像中的某几帧中等等问题。
目标运动特性:我们利用标注信息将一个序列内的5帧图像的目标位置匹配在一幅图中,呈现明显的匀速直线运动轨迹。

问题解析
问题转化
结合目标特性,我们将数据集中的标注点位置视为bbox标记框的中心位置,取中心点上下左右宽度为3个像素,得到目标标注框。左上角的坐标和右下角的坐标值根据长宽偏移量计算得到,这样将问题转化为类别数为2的目标检测问题。
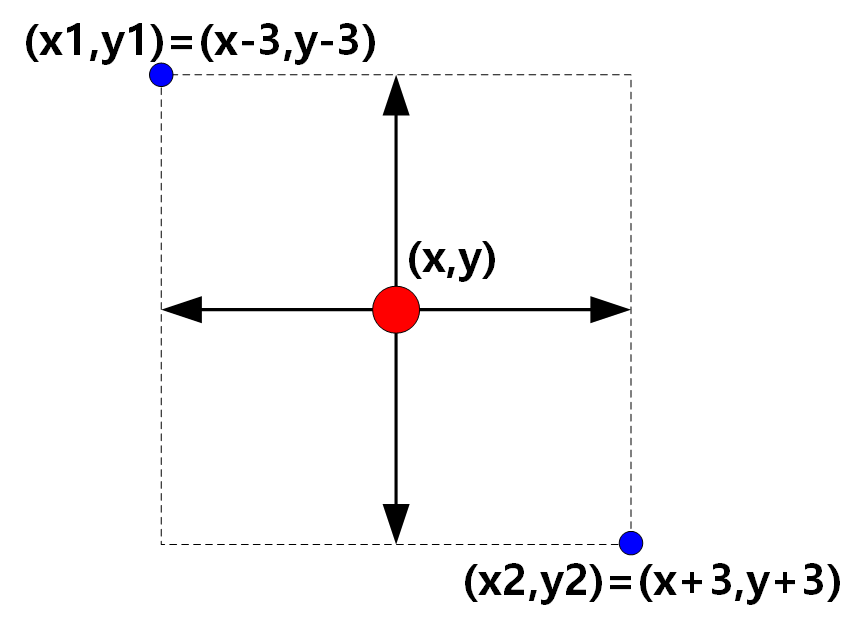
标注图示
整体开发流程
本项目使用飞桨全流程开发工具PaddleX。整个项目工作主要包括数据预处理、模型训练及导出以及模型部署三部分:

开发流程
数据预处理过程的工作主要包括:
1.数据清洗
首先将不存在任何目标的帧序列删除;
数据清洗
import json
def read_annotation_file(path):
annotation_list = json.load(open(path))
# Transform list of annotations into dictionary
annotation_dict = {}
for annotation in annotation_list:
sequence_id = annotation['sequence_id']
if sequence_id not in annotation_dict:
annotation_dict[sequence_id] = {}
annotation_dict[sequence_id][annotation['frame']] = annotation['object_coords'] #just pull out the object_coords
return annotation_dict
anopath = ‘work/train_anno.json’
train_annotation= read_annotation_file(anopath)
ori_seq = len(train_annotation)
print(‘\n原始序列数量:’, ori_seq)
根据num_objects字段删除训练无效序列
for i in range(1, ori_seq):
if len(train_annotation[i][1]) == 0:
del train_annotation[i]
train_annotation is data numpy
real_seq = len(train_annotation)
print(‘\n有效序列数量:’, real_seq)
2.数据集标注格式转换
为方便使用PaddleX数据接口,将原始的标注文件重新转换为VOC格式
from pycocotools.coco import COCO
import os, cv2, shutil
from lxml import etree, objectify
from tqdm import tqdm
from PIL import Image
CKimg_dir = ‘./SpotGEOvoc/VOCImages’
CKanno_dir = ‘./SpotGEOvoc/VOCAnnotations’
def catid2name(coco): # 将名字和id号建立一个字典
classes = dict()
for cat in coco.dataset[‘categories’]:
classes[cat[‘id’]] = cat[‘name’]
# print(str(cat['id'])+":"+cat['name'])
return classes
def get_CK5(origin_anno_dir, origin_image_dir, verbose=False):
dataTypes = [‘train’]
for dataType in dataTypes:
annFile = ‘{}_anno.json’.format(dataType)
annpath = os.path.join(origin_anno_dir, annFile)
print(annpath)
coco = COCO(annpath)
classes = catid2name(coco)
imgIds = coco.getImgIds()
# imgIds=imgIds[0:1000]#测试用,抽取10张图片,看下存储效果
for imgId in tqdm(imgIds):
img = coco.loadImgs(imgId)[0]
showbycv(coco, dataType, img, classes, origin_image_dir, verbose=False)
def main():
base_dir = ‘./SpotGEOvoc’ # step1 这里是一个新的文件夹,存放转换后的图片和标注
image_dir = os.path.join(base_dir, ‘VOCImages’) # 在上述文件夹中生成images,annotations两个子文件夹
anno_dir = os.path.join(base_dir, ‘VOCAnnotations’)
mkr(image_dir)
mkr(anno_dir )
origin_image_dir = ‘./SpotGEOv2’ # step 2原始的coco的图像存放位置
origin_anno_dir = ‘./SpotGEOv2’ # step 3 原始的coco的标注存放位置
verbose = True # 是否需要看下标记是否正确的开关标记,若是true,就会把标记展示到图片上
get_CK5(origin_anno_dir, origin_image_dir, verbose)
3.将原始训练数据进行训练集和验证集划分
!paddlex —split_dataset —format VOC —dataset_dir MyDataset —val_value 0.2 —test_value 0
对于模型的选择和开发:因为项目最终面向端侧部署,所以轻量高效的检测模型是首选。这里我使用的是飞桨特色模型PP-YOLOv2,该模型由百度飞桨团队基于PP-YOLO模型进行优化改进和升级,网络结构如下图所示。Baseline Model为PP-YOLO,骨干网络为ResNet50-vd,组合添加优化组件包含Deformable Conv、SSLD、CoordConv、DropBlock、SPP、Larger Batch Size、EMA、IoU Loss、IoU Aware、Grid Sensitive等10个Tricks。

模型训练主体只需要这些代码,配置好数据集格式和路径,然后修改num_classes参数,类别数是除去背景类,也就是总类别数-1。调整设置好一系列训练参数,然后就开始模型训练。
num_classes = 1
model = pdx.det.PPYOLOv2(num_classes=num_classes, backbone=’ResNet50_vd_dcn’)
model.train(
num_epochs=3600,
train_dataset=train_dataset,
train_batch_size=4,
eval_dataset=eval_dataset,
learning_rate=0.001 / 8,
warmup_steps=1000,
warmup_start_lr=0.0,
save_interval_epochs=36,
lr_decay_epochs=[216, 243],
save_dir=’output/PPyolov2_r50vd_dcn’)
然后等待模型训练完评估好结果之后再进行模型导出及部署。
!paddlex —export_inference —model_dir=/home/aistudio/output/PPyolov2_r50vd_dcn/best_model —save_dir=/home/aistudio/inference
最后,本项目基于 Nvidia Jetson Nano平台实现了一套实际的演示系统。

在Jetson NANO开发板上进行飞桨模型部署,从前期准备到推理程序验证的全流程主要包括以下几部分。


软件部分,端侧推理程序主要是以下三部分,不得不再次赞叹API是真香!

具体的推理代码如下:
python部署流程
import glob
import numpy as np
import threading
import time
import random
import os
import base64
import cv2
import json
import paddlex as pdx
os.environ[‘CUDA_VISIBLE_DEVICES’]=’0’
predictor = pdx.deploy.Predictor(model_dir=’./infer’, use_gpu=True, gpu_id=0, use_trt=True)
def get_images(image_path, support_ext=”.jpg|.jpeg|.png”):
if not os.path.exists(image_path):
raise Exception(f”Image path {image_path} invalid”)
if os.path.isfile(image_path):
return [image_path]
imgs = []
for item in os.listdir(image_path):
ext = os.path.splitext(item)[1][1:].strip().lower()
if (len(ext) > 0 and ext in support_ext):
item_path = os.path.join(image_path, item)
imgs.append(item_path)
return imgs
def crest_dir_not_exist(path):
if not os.path.exists(path):
os.mkdir(path)
def run(img_path,img_name,save_path):
result = predictor.predict(img_file=img_name, warmup_iters=100, repeats=100)
time2= time.time()
pdx.det.visualize(img_name, result, threshold=0.5, save_dir=save_path)
time3 = time.time()
print(“Visual Time: {}s”.format(time3-time2))
if name == “main“:
test_path = ‘visual/‘
save_path = ‘output/visual/‘
crest_dir_not_exist(save_path)
L = get_images(test_path)
N = len(L)
print(N)
for i in range(N):
print(L[i])
run(test_path, L[i],save_path)
实际的结果演示动图如下所示。


发表评论
登录后可评论,请前往 登录 或 注册